本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 约束
- 优势
- 数据模型
- 写路径
- 查询路径
- Field Hints Index
- 可靠性
- 其他
- 总结
引言
Monarch这篇文章的重点不在于In-Memory的存储引擎,而在于其新颖的数据模型,路由方式,查询下推和FHI,其中提出的不少点值得学习。
约束
谷歌的监控老系统Borgmon存在如下局限性:
- 维护问题,鼓励每个团队维护一个自己的实例,实际操作十分费人费力
- 缺乏measurement dimensions and metric values模式化,导致查询的语义模糊
- 不支持直方图类型
- 全球化服务用户需要手动管理多个区域的多个borgmon实例
这是Monarch的架构图:
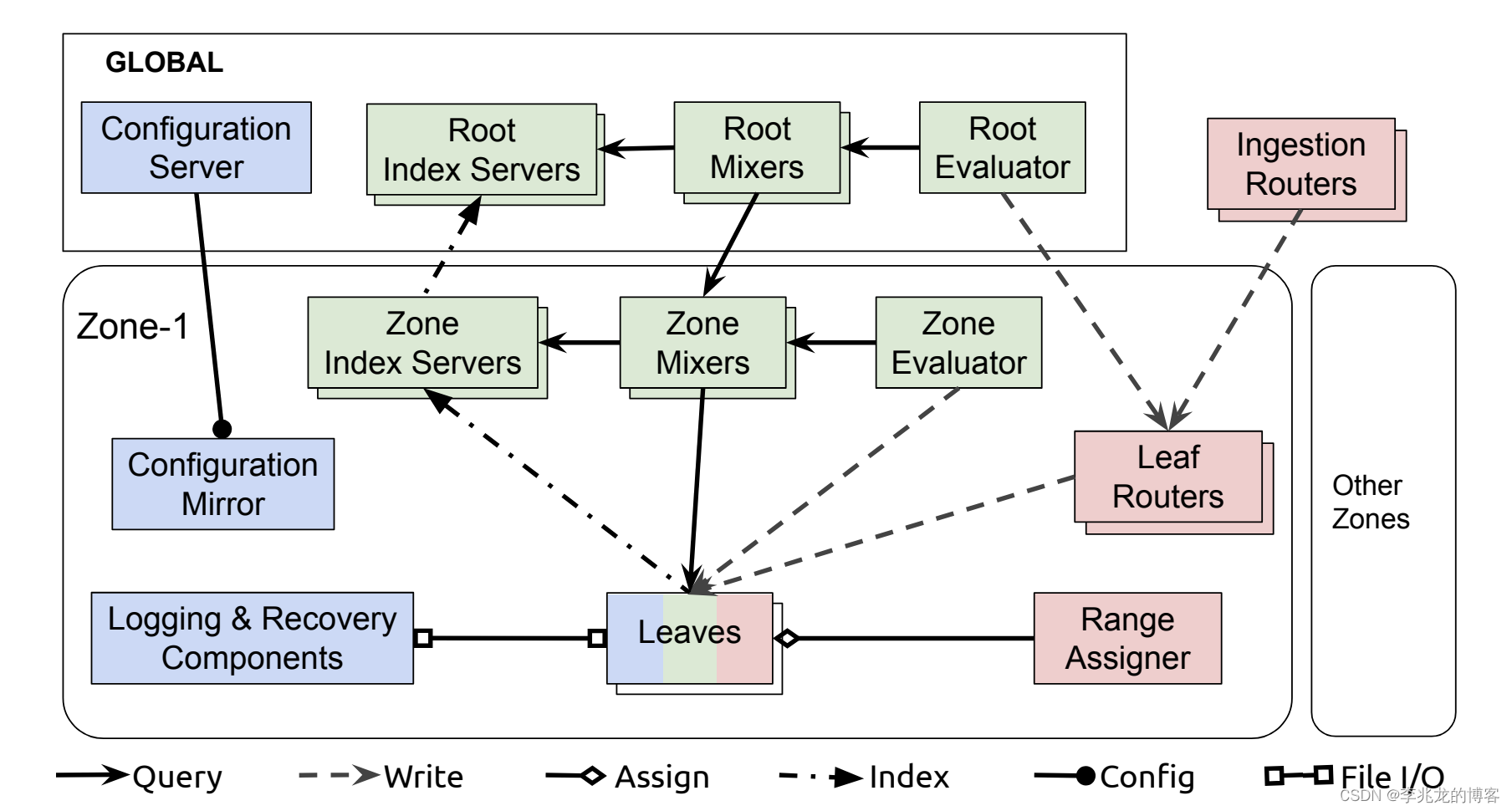
- Monarch主要用于监控和告警,允许用一致性来换取高可用性和分区容错性;为了及时发出告警,允许放弃延迟写入,并在必要时返回部分数据,保证及时提供最新数据。
- 为了降低告警关键路径上的延迟,必须最大限度减小延迟,这也是数据存储在内存中的原因
- 告警路径上减少外部依赖,因为外部系统的告警依赖于监控
- 主要组织原则是zone内的本地监控数据与全球查询相结合,每个zone都是一个独立故障域,zone内保存的是数据收集地附近的监控数据,降低传输成本,延迟和可靠性问题;全局查询允许提供整个系统的统一视图。
优势
- 采用区域化架构,允许全局查询合并,提供全局控制面,将各区域整合为一个统一的系统
- 新颖的数据模型,这也决定了路由的流程
- 可扩展的写流程,自动负载均衡
- 数据分布模型带来高效分布式查询子系统
- 高效的Field Hints Index,减少大量向leaf发起的查询操作
数据模型
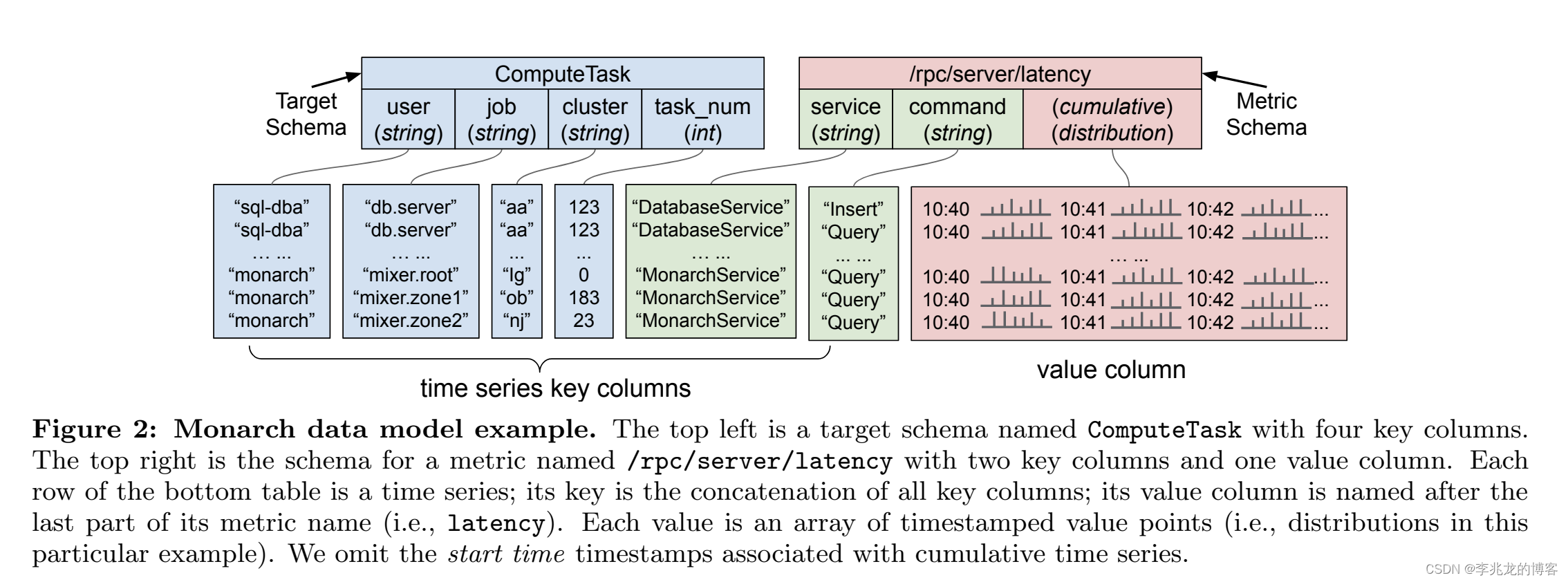
所有的时序数据模型最终都会抽象为time series key+fields,Monarch也不例外,不过Monarch最大的变化为将一个time series分割成两个schema,成为Target Schema和Metric Schema。
Target Schema:每个Target代表一个受监控的实体Metric Schema:每个Metric代表一个监控目标的一个方面,也就是说一个Target允许有多个metric
Target有一个被注释的特殊字段location,该字段决定数据被路由到哪一个zone。其次单个target到数据会被存储到同一个leaf中,因为他们更可能在查询时被聚合在一起。
其次每一个leaf被组织为不相交的区间[Sstart, Send),称为Target ranges ,其中Sstart和Send 是schema name 和 Target schema的field values排序构成的字符串,这个概念用于sharding 和 load balancing,而且这也让邻居Target的查询变的高效,因为分布在一个leaf的概率变高了,这里也可以看出Monarch是一个全局的范围路由分布。
其次Metric支持如下类型boolean, int64, double, string, distribution, or tuple of other types;其次不仅支持测量值,也支持累计值。
写路径
写入流程中的关键是Ingestion Router和Leaf Router两个router,分别执行分而治之,Ingestion Router根据location将数据发往一个zone,Leaf Router根据Range Assigner的信息将数据路由到leaf,
- 客户将数据发送到附近的一个
Ingestion Router Ingestion Router根据location将数据发往一个zone,这个映射在配置中指定,可以动态更新Leaf Router根据Range Assigner的信息将数据路由到leaf,一个Target ranges映射一个leaf,Leaf Router中维护着一个持续更新的range mapleaf中写入内存和recovery logging组件(写入recovery log的流程无需等待确认,数据被写入分布式文件系统,并通过探测健康状态切换实例,即使所有的实例都不可用系统也要继续运行)
其次因为leaf节点的区间有且只取决于Target ranges,所以属于一个Target的上百个mertic最多只需要发送到三个leaf副本节点上,这不仅运行写入的横向扩展,还能将大多数查询限制在同一个leaf上,其次Target内的join操作可以下放到leaf节点上,使得查询更快,开销更小。
负载均衡的流程则是一个典型的双写range分裂流程,和我在公司内部负责维护一个Range KV老系统非常相似,这个流程中最大的麻烦论文没有提,就是多个Leaf Router的路由更新同步,当然是已经解决的问题了,内部已经稳定跑了好多年了:
- 选择源和目的,通知
Leaf Router,双写读旧 - 等待源数据落盘1s后,目的从日志中倒序恢复旧数据
- 完全恢复后通知
Leaf Router双写读新,路由同步后最后单写读新
最后值得一提的是所谓的Collection Aggregation,其实本质是为了减小leaf节点的压力,在客户端或者在Leaf Router中做汇聚,一个窗口内只需要向leaf写入一次,这里会有一个Admission window的概念,整个流程其实和一般时序数据库预降采样的流程差不多,所以窗口区间多大,接纳窗口时间多长,本质上就是内存,准确性,实时性的权衡。
查询路径
前面提到Monarch是一个统一的系统,其查询路径中最重要的模块是Root mixers和Zone mixers;查询分为ad hoc queries 和 standing queries,前者由用户直接发起,后者类似于流式查询,用于降采样数据,这部分数据一般生命周期会长一些。查询简易流程如下:
- A root mixerreceives the query and fans out to zone mixers,
- each of which fans out to leaves in that zone.
- The zonal standing queries are sent directly to zone mixers.
这里有这么几个关键点:
Replica resolution:Monarch的一致性不高,目前来看是写三份,读一份,线上系统的运营经验告诉我这种情况下很容易出现三副本不一致,kv遇到这种情况是完全没办法,恢复都不知道怎么恢复;时序则可以通过时间界限,数据完整性等指标选择最完整的副本执行读取,这也意味着正常查询前需要多执行一步。User isolation:我曾在[2]中阐述过时序数据库做隔离的难点,即单次查询粒度过高,必须大刀阔斧的改造引擎才可以相对完美解决这个问题;Monarch直接Cgroup隔离CPU肉眼可见的小用户基本没法玩了,这也许是Monarch不上公有云的原因。Query Pushdown: 原始数据的摄取在leaf,在leaf,Root mixers和Zone mixers都允许执行数据的聚合,数据的聚合越靠下,意味着更好的并发性(以我们公司的时序数据库来说,一般底层可以每个field一个线程的计算,而上层的迭代器是行级别的)和负载分布的负载,其次意味上上层传输数据量的减小**。这样的缺陷其实非常明显,即存储和计算没有分离,在云上很难把价格打下去。**
Field Hints Index
个人认为这是Monarch最大的杀器。它允许FHI通过分析查询中的谓词来跳过不相关的分片,并在不迭代确切字段值的情况下有效地处理正则表达式,同时可以内存中处理万亿级别series key。它的缺陷是不是百分百准确的,即可能出现像布隆过滤器一样的行为,但是后续的查询会为空,保证最终的正确性。
field hint是Target schema中field value的excerpt,文章中列举了如下hint都称为monarch 的trigram hints,其中^和$分别代表一个字符串的开始和末尾。
^^m, ^mo, mon, ona, nar, arc, rch, ch$, and h$$
A field hint index本质上是一个map<fingerprint, vector< leaf>> ,fingerprint of a field hint 映射这一个leaf的列表。而fingerprint文中的描述如下:
A fingerprint is an int64 generated deterministically from three inputs of a hint: the schema name, the field name, and the excerpt (i.e., trigrams).
一个schema name+ the field name 可能存在多个fingerprint。
在执行查询时,可以从条件中找到一个谓词,通过FHI查询这个谓词所指的数据可能存在在哪个节点上。
其次FHI非常小,如果仅仅以字符来看,且hints最长为3的话,其实最多也只有256^3的可能性。这是的FHI的实现很简单,完全不需要考虑大于内存的情况,即不需要做数据持久化,FHI启动时从活的leaf中建立起来就可以,随后index server订阅leaf的变更流,更新FHI。
可靠性
Zone pruning:保护全局查询不受zone级别故障的影响,文中提到99.998%的成功查询会在查询结束前一半时间开始数据传输,所以一旦在规定时间没有返回可以认为这个区域故障,并在查询汇总告知用户Hedged reads:一个查询可能覆盖成千上万个leaf,此时尾延非常明显,所以查询存在一个主节点和后背节点,在主节点响应缓慢或者故障时查询后背节点,其实理解成主节点超时/故障后的重试就可以了,起个这么高级的名字。
其他
-
部署分为internal, external, and meta.Internal and external are for customers inside and outside
Google; meta runs a proven-stable older version of Monarch and monitors all other Monarch deployments. 这在我们的时序系统的运营中来看非常重要,不然每次有损更新meta集群监控就要断几分钟。 -
查询下推和FHI是Monarch每秒支持百万次查询的重点
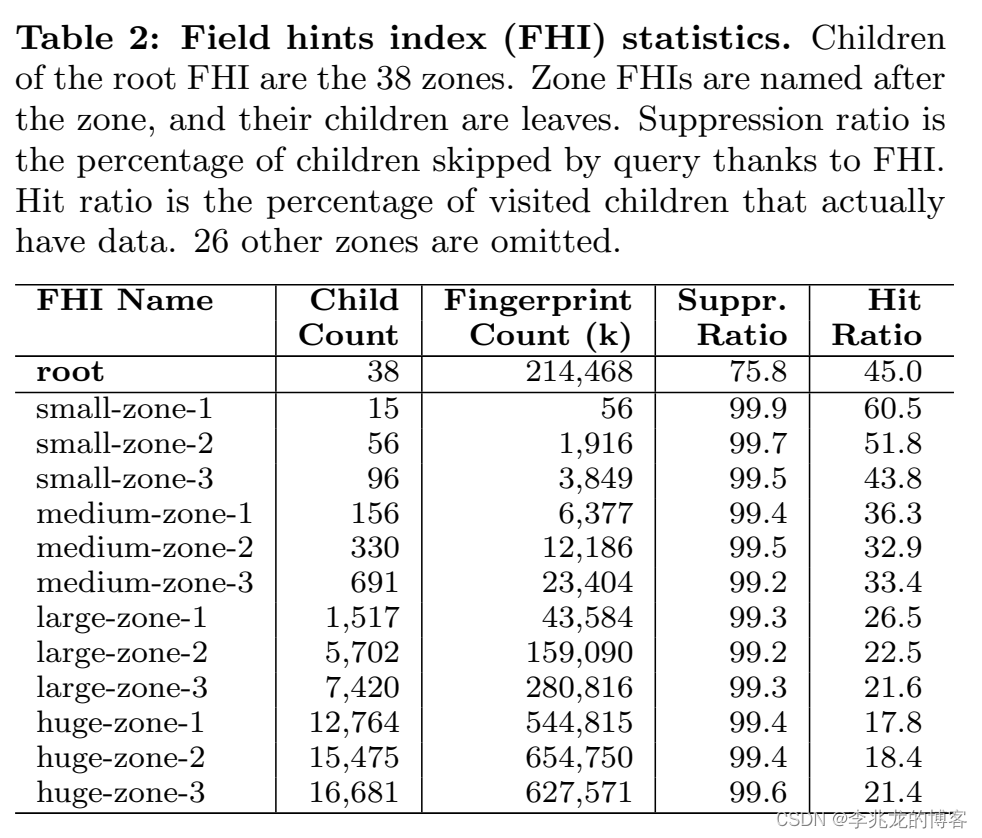
其实FHI的效果从测试来看简直是好的奇怪,不禁让人觉得有美化的嫌疑,因为Monarch的路由策略是基于Target schema的 target range,这以为这较后路径的field分布其实是完全随机的,举个简单的例子: -
aaa::bbb::111::ddd
-
aaa::bbb::222::ddd
-
aaa::bbb::333::ddd
假设这三个series key分属于三个不同leaf,这三个leaf的range都是aaa::bbb::xxx,此时一个查询如果携带field_name=ddd,这就导致所有的leaf还是需要被查询,其次范围操作比如>/<其实也很难做。
总结
在RELATED WORK中作者提到
the use of secondary storage makes them less desirable for critical monitoring. They support distributed deployment by scaling horizontally similar to a Monarch zone, but they lack the global configuration management and query aggregation that Monarch provides.
从内部系统运营的角度来看:
其实第一个观点批评的是,目前关键路径上确实存在延迟,对于告警来说是比较不能接受的,但是这部分延迟目前来看基本来源于kafka,内部系统并不是瓶颈;
第二个点我们做的还是不错的,我们的系统系统控制面非常完善,其次数据面允许查询下推,且存在聚合节点,这个架构最大的问题是计算存储不分离,公有云难运营,其次租户隔离很难解决。
参考:
- Monarch: Google’s Planet-Scale In-Memory Time Series Database vldb2020
- 从一到无穷大 #7 Database-as-a-Service租户隔离挑战与解决措施