使用多线程std::thread发挥多核计算优势(题目)
单核无能为力
如果我们的电脑只有一个核,那么我们没有什么更好的办法可以让我们的程序更快。
因为这个作业限制了你修改算法函数。你唯一能做的就是利用你电脑的多核。
使用多线程
由于我们的电脑有多个内核,所以,我们可以创建多线程来把任务“平均”分配给多个核来计算。
这样多个核在“同时”运算的时候就可以加速程序的执行。
多核的细节
关于我们创建多少个线程比较合适,多个线程真的可以各自分配到多个核而“同时”运行吗?
试一下就知道了。
双线程的效果
我们先用两个线程,把任务固定的分配给这两个线程,看看完成任务总的执行时间是不是变短了。
代码如下:
#include <iostream>
#include <cmath>//sqrt
#include <iostream>
#include <iomanip>//format output
#include <chrono>
#include <thread>//for faster code
#include <mutex>//for faster code
#include <sstream>//stringstream
using namespace std::chrono;//time_piont duration
using namespace std;
//test helper function begin 测试辅助代码开始
void check_do(bool b, int line = __LINE__)
{
if (b) { cout << "line:" << line << " Pass" << endl; }
else { cout << "line:" << line << " Ohh! not passed!!!!!!!!!!!!!!!!!!!!!!!!!!!" << " " << endl; exit(0); }
}
#define check(msg) check_do(msg, __LINE__);
//test helper function end 测试辅助代码结束
//do not change this function! 不要修改这个函数
//if you want to check a number is prime number or not, you can use this function only.
//判断素数只能用这个函数
bool is_number_prime(int n)
{
if (n == 2 || n == 3)//prime less than 5
{
return true;//is prime
}
if (n % 6 != 5 && n % 6 != 1)//is not prime
{
return false;
}
int cmb = (int)std::sqrt(n);
for (int i = 5; i <= cmb; i += 6)
{
if (n % i == 0 || n % (i + 2) == 0)
{
return false;//is not prime
}
}
return true;//is prime
}
/*
100以内的素数 primes within 100
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
*/
//测试判断素数的函数是否正确
void test_is_prime_number(void)
{
stringstream ss;
for (int i = 2; i < 100; i++)
{
if (is_number_prime(i))
{
ss << i << " ";
}
}
check(ss.str() == "2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 ");
}
//do not change this function!
//不要修改此函数
long long test_the_sum_of_all_primes_within(long long scale)
{
auto start = system_clock::now();
long long sum = 0;
for (int n = 2; n <= scale; n++) {
if (is_number_prime(n)) {
sum += n;
}
}
cout << "the sum of all primes from 2~"<< setw(10) << scale << " is : " << setw(15) << sum
<< ", elapled " << setw(10) << static_cast<long long>(duration<double, milli>(system_clock::now() - start).count()) << " milliseconds"
<< endl;
return sum;
}
//please change this function to let your program faster by use multi core in your CPU.
//请重新实现此函数以让你的CPU多核优势得到发挥
//hint: maybe you can use multi thread technology to let your code faster.
//提示:你可以使用多线程来发挥多核的计算优势从而让你的程序跑的更快
long long faster_test_the_sum_of_all_primes_within(long long scale)
{
auto start = system_clock::now();
long long sum = 0;
std::mutex sum_mutex;
auto fun = [&sum, &sum_mutex](long long scaleStart, long long scaleLast) {
for (int n = scaleStart; n <= scaleLast; n++) {
if (is_number_prime(n)) {
std::lock_guard<std::mutex> lock(sum_mutex);//如果没有多线程互斥访问sum,那么sum的值就可能是错的。
sum += n;
}
}
};
//区间平分,这样后面的第二个线程的计算量还是偏大,因为都是在处理更大的数字
std::thread t1(fun, 2, scale / 2);
std::thread t2(fun, scale / 2 + 1, scale);
t1.join();//线程开始运行直到结束
t2.join();//线程开始运行直到结束
cout << "the sum of all primes from 2~" << setw(10) << scale << " is : " << setw(15) << sum
<< ", elapled " << setw(10) << static_cast<long long>(duration<double, milli>(system_clock::now() - start).count()) << " milliseconds"
<< endl;
return sum;
}
//do not change the code in this function
//不要修改此函数中的内容
int main()
{
test_is_prime_number();
long long sum = 0;
cout << "base slow version:" << endl;
sum = test_the_sum_of_all_primes_within(10000 * 10);
check(sum == 454396537);
sum = test_the_sum_of_all_primes_within(10000 * 100);
check(sum == 37550402023);
sum = test_the_sum_of_all_primes_within(10000 * 1000);
check(sum == 3203324994356);
sum = test_the_sum_of_all_primes_within(10000 * 10000);
check(sum == 279209790387276);
cout << endl << "my faster version:" << endl;
sum = faster_test_the_sum_of_all_primes_within(10000 * 10);
check(sum == 454396537);
sum = faster_test_the_sum_of_all_primes_within(10000 * 100);
check(sum == 37550402023);
sum = faster_test_the_sum_of_all_primes_within(10000 * 1000);
check(sum == 3203324994356);
sum = faster_test_the_sum_of_all_primes_within(10000 * 10000);
check(sum == 279209790387276);
cout << "please enter enter for exit." << endl;
cin.get();
return 0;
}
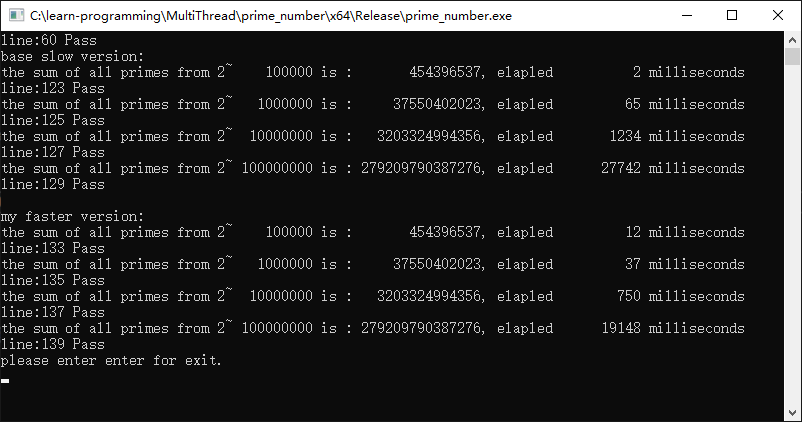
运行结果:
代码分析
如同代码注释中所说,我们把求解区间一分为二,后面的一个线程整体上任务还是偏重。因为处理的都是大数据。
但即便这样简单的划分,两个线程比一个线程耗时还是大幅度降低的。
在一百万个整数求解的时候时间降低了50%;
在一千万个整数求解的时候时间降低了50%;
在一亿个整数求解的时候时间降低了30%;这是因为后面一个线程的计算量过大,两个线程的任务没有起到平分导致的。
可以预见,随着数据量的继续增大,这种平分区间的算法,会导致第二个线程完全占据计算量的大头。这时候会导致这种算法的优势降低,甚至减少的时间可以忽略不计。
但是我们的目的达到了。那就是我们已经验证了多线程多核在计算速度上的确是可以完胜单线程的,只要我们合理分配计算任务给多个线程。
继续增加线程数量
下面我们把区间3等分,创建3个线程,看看是不是耗时会不会继续降低:
long long faster_test_the_sum_of_all_primes_within(long long scale)
{
auto start = system_clock::now();
long long sum = 0;
std::mutex sum_mutex;
auto fun = [&sum, &sum_mutex](long long scaleStart, long long scaleLast) {
for (int n = scaleStart; n <= scaleLast; n++) {
if (is_number_prime(n)) {
std::lock_guard<std::mutex> lock(sum_mutex);//如果没有多线程互斥访问sum,那么sum的值就可能是错的。
sum += n;
}
}
};
//区间平分,这样后面的第二个线程的计算量还是偏大,因为都是在处理更大的数字
std::thread t1(fun, 2, scale / 3);
std::thread t2(fun, scale / 3 + 1, scale / 3 * 2);
std::thread t3(fun, scale / 3 * 2 + 1, scale);
t1.join();//线程开始运行直到结束
t2.join();//线程开始运行直到结束
t3.join();//线程开始运行直到结束
cout << "the sum of all primes from 2~" << setw(10) << scale << " is : " << setw(15) << sum
<< ", elapled " << setw(10) << static_cast<long long>(duration<double, milli>(system_clock::now() - start).count()) << " milliseconds"
<< endl;
return sum;
}
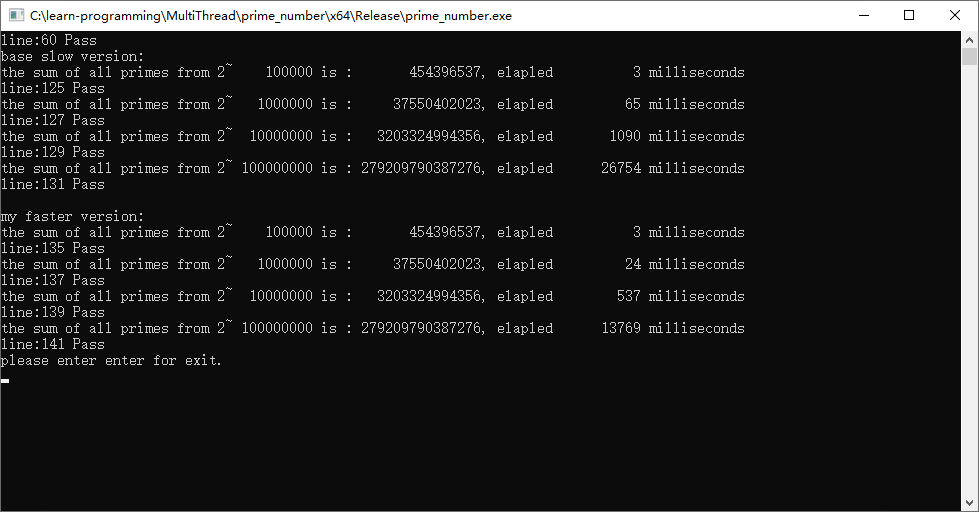
运行输出:
代码分析2
正如我们预期,时间继续下降,尤其是数据量达到一亿的时候,总耗时再次变为了原来的一半。
至此,多线程多核可以降低计算总时长已经被我们验证完毕。
怎么样?你学到了吗?
欢迎点赞收藏转发。让其他感兴趣的人也可以看到。






![[国产MCU]-W801开发实例-用户报文协议(UDP)数据接收和发送](https://img-blog.csdnimg.cn/eabfef81b3ba4aaf89bf563ffdfad44b.png#pic_center)
![串行协议——USB驱动[基础]](https://img-blog.csdnimg.cn/1ad1a35a30a0484d95e3a624dd3da9c5.png)