什么是原子操作?如何实现原子操作?
什么是原子性?
事务的一大特性就是原子性(事务具有ACID四大特性),一个事务包含多个操作,这些操作要么全部执行,要么全都不执行
并发里的原子性和原子操作是一样的内涵和概念,假定有两个操作A和B都包含多个步骤,如果从执行A的线程来看,当另一个线程执行B时,要么将B全部执行完,要么完全不执行B,执行B的线程看A的操作也是一样的,那么A和B对彼此来说是原子的。
实现原子操作可以使用锁,锁机制,满足基本的需求是没有问题的了,但是有的时候我们的需求并非这么简单,我们需要更有效,更加灵活的机制,synchronized关键字是基于阻塞的锁机制,也就是说当一个线程拥有锁的时候,访问同一资源的其它线程需要等待,直到该线程释放锁,
这里会有些问题:首先,如果被阻塞的线程优先级很高很重要怎么办?其次,如果获得锁的线程一直不释放锁怎么办?同时,还有可能出现一些例如死锁之类的情况,最后,其实锁机制是一种比较粗糙,粒度比较大的机制,相对于像计数器这样的需求有点儿过于笨重。为了解决这个问题,Java提供了Atomic系列的原子操作类。
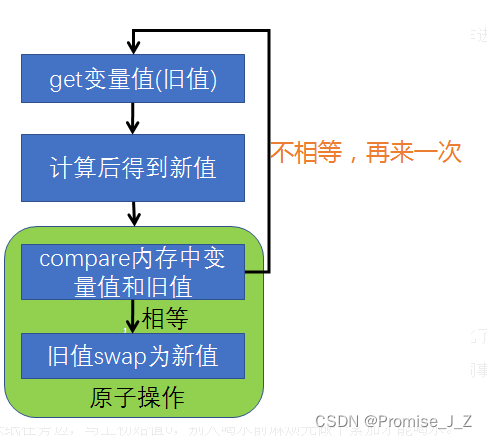
这些原子操作类其实是使用当前的处理器基本都支持CAS的指令,比如Intel的汇编指令cmpxchg,每个厂家所实现的具体算法并不一样,但是原理基本一样。每一个CAS操作过程都包含三个运算符:一个内存地址V,一个期望的值A和一个新值B,操作的时候如果这个地址上存放的值等于这个期望的值A,则将地址上的值赋为新值B,否则不做任何操作
CAS的基本思路 :如果这个地址上的值和期望的值相等,则给其赋予新值,否则不做任何事儿,但是要返回原值是多少。自然CAS操作执行完成时,在业务上不一定完成了,这个时候我们就会对CAS操作进行反复重试,于是就有了循环CAS。很明显,循环CAS就是在一个循环里不断的做cas操作,直到成功为止。Java中的Atomic系列的原子操作类的实现则是利用了循环CAS来实现
CAS实现原子操作的三大问题
ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A→B→A就会变成1A→2B→3A。举个通俗点的例子,你倒了一杯水放桌子上,干了点别的事,然后同事把你水喝了又给你重新倒了一杯水,你回来看水还在,拿起来就喝,如果你不管水中间被人喝过,只关心水还在,这就是ABA问题。
循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
只能保证一个共享变量的原子操作
对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
Atomic系列
概述:java从JDK1.5开始提供了java.util.concurrent.atomic包(简称Atomic包),这个包中的原子操作类提供了一种用法简单,性能高效,线程安全地更新一个变量的方式。因为变量的类型有很多种,所以在Atomic包里一共提供了13个类,属于4种类型的原子更新方式,分别是原子更新基本类型、原子更新数组、原子更新引用和原子更新属性(字段)。本次我们只讲解
原理:
有3个操作数(内存值V, 旧的预期值A,要修改的值B)
当旧的预期值A == 内存值 此时修改成功,将V改为B
当旧的预期值A!=内存值 此时修改失败,不做任何操作并重新获取现在的最新值,再重复之前的方法(这个重新获取的动作就是自旋)
使用原子的方式更新基本类型,使用原子的方式更新基本类型Atomic包提供了以下3个类:
- AtomicBoolean: 原子更新布尔类型
- AtomicInteger: 原子更新整型
- AtomicLong: 原子更新长整型
以上3个类提供的方法几乎一模一样,所以本节仅以AtomicInteger为例进行讲解,AtomicInteger的常用方法如下:
- public AtomicInteger(): 初始化一个默认值为0的原子型Integer
- public AtomicInteger(int initialValue): 初始化一个指定值的原子型Integer
- int get(): 获取值
- int getAndIncrement(): 以原子方式将当前值加1,注意,这里返回的是自增前的值。
- int incrementAndGet(): 以原子方式将当前值加1,注意,这里返回的是自增后的值。
- int addAndGet(int data): 以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果。
- int getAndSet(int value): 以原子方式设置为newValue的值,并返回旧值。
- boolean compareAndSet(int expect, int update) 于传入的expect值进行比较,如果当前值等于expect值,则更新为update。
代码实现:
package com.itheima.threadatom3;
import java.util.concurrent.atomic.AtomicInteger;
public class MyAtomIntergerDemo1 {
// public AtomicInteger(): 初始化一个默认值为0的原子型Integer
// public AtomicInteger(int initialValue): 初始化一个指定值的原子型Integer
public static void main(String[] args) {
AtomicInteger ac = new AtomicInteger();
System.out.println(ac);
AtomicInteger ac2 = new AtomicInteger(10);
System.out.println(ac2);
}
}
package com.itheima.threadatom3;
import java.lang.reflect.Field;
import java.util.concurrent.atomic.AtomicInteger;
public class MyAtomIntergerDemo2 {
// int get(): 获取值
// int getAndIncrement(): 以原子方式将当前值加1,注意,这里返回的是自增前的值。
// int incrementAndGet(): 以原子方式将当前值加1,注意,这里返回的是自增后的值。
// int addAndGet(int data): 以原子方式将参数与对象中的值相加,并返回结果。
// int getAndSet(int value): 以原子方式设置为newValue的值,并返回旧值。
public static void main(String[] args) {
// AtomicInteger ac1 = new AtomicInteger(10);
// System.out.println(ac1.get());
// AtomicInteger ac2 = new AtomicInteger(10);
// int andIncrement = ac2.getAndIncrement();
// System.out.println(andIncrement);
// System.out.println(ac2.get());
// AtomicInteger ac3 = new AtomicInteger(10);
// int i = ac3.incrementAndGet();
// System.out.println(i);//自增后的值
// System.out.println(ac3.get());
// AtomicInteger ac4 = new AtomicInteger(10);
// int i = ac4.addAndGet(20);
// System.out.println(i);
// System.out.println(ac4.get());
AtomicInteger ac5 = new AtomicInteger(100);
int andSet = ac5.getAndSet(20);
System.out.println(andSet);
System.out.println(ac5.get());
}
}对于非基本类型可以使用 AtomicReference
代码演示:
public static void main(String[] args) {
StudentDemo studentDemo = new StudentDemo();
studentDemo.setName("张三");
studentDemo.setAge(18);
studentDemo.setSco(100f);
AtomicReference atomicReference = new AtomicReference(studentDemo);
StudentDemo studentDemo2 = new StudentDemo();
studentDemo2.setName("李四");
Object o = atomicReference.get();
studentDemo2.setName("王五");
atomicReference.compareAndSet(o,studentDemo2);
}正如前面所讲过的aba问题,Atomic还提供了区别版本号的方法类
AtomicStampedReference代码演示
public static void main(String[] args) throws InterruptedException {
AtomicStampedReference<BigDecimal> bigDecimalAtomicReference = new AtomicStampedReference<>(new BigDecimal("10000"), 0);
for (int i = 0; i < 1000; i++) {
Thread x = new Thread(() -> {
while (true) {
BigDecimal bigDecimal = bigDecimalAtomicReference.getReference();
BigDecimal subtract = bigDecimal.subtract(BigDecimal.TEN);
int stamp = bigDecimalAtomicReference.getStamp();
if (bigDecimalAtomicReference.compareAndSet(bigDecimal, subtract, stamp, stamp + 1)) {
System.out.println(bigDecimalAtomicReference.getReference());
break;
}
}
});
x.start();
x.join();
}
} AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如:
A - > B - > A - > C ,通过 AtomicStampedReference ,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心 是否更改过 ,所以就有了AtomicMarkableReference
AtomicMarkableReference代码演示
AtomicMarkableReference<BigDecimal> bigDecimalAtomicReference = new AtomicMarkableReference<>(new BigDecimal("10000"), true);
for (int i = 0; i < 1000; i++) {
Thread x = new Thread(() -> {
while (true) {
BigDecimal bigDecimal = bigDecimalAtomicReference.getReference();
BigDecimal subtract = bigDecimal.subtract(BigDecimal.TEN);
if (bigDecimalAtomicReference.compareAndSet(bigDecimal, subtract, true, false)) {
System.out.println(bigDecimalAtomicReference.getReference());
break;
}
}
});
x.start();
x.join();
}
}AtomicMarkableReference 提供了一个标记,在修改成功的时候把标记也一起修改,待到下一次变更的时候,如果标记改变了,则说明已经变化过值。
LongAdder
LongAdder 是并发大师 @author Doug Lea (大哥李)的作品,设计的非常精巧
LongAdder 类有几个关键域
// 累加单元数组 , 懒惰初始化
transient volatile Cell [] cells ;
// 基础值 , 如果没有竞争 , 则用 cas 累加这个域
transient volatile long base ;
// 在 cells 创建或扩容时 , 置为 1, 表示加锁
transient volatile int cellsBusy ;
伪共享原理
// 防止缓存行伪共享
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 最重要的方法, 用来 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}
cell为累加单元,而方法上的@sun.misc.Contended 的作用在下面介绍
需要重缓存说起,在操作系统种由以下几中数据读取放方式,从cpu内部寄存器、一级缓存、二级缓存、三级缓存、内存

现在比较以下内存与缓存的数据差别

因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte ( 8 个 long )
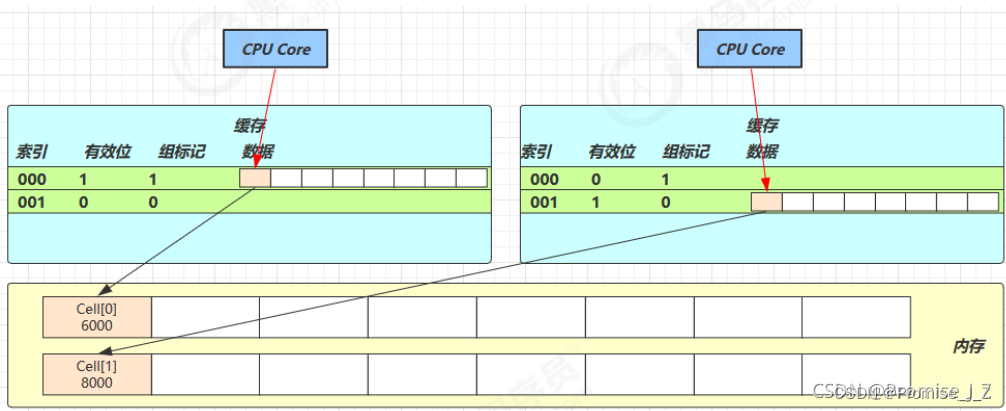
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效

因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节( 16 字节的对象头和 8 字节的 value ),因
此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
Core-0 要修改 Cell[0]
Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加
Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的
padding ,从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
对于LongAdder来说,内部有一个base变量,一个Cell[]数组。
在实际运用的时候,只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作都只针对Cell[]数组中的单元Cell。

而LongAdder最终结果的求和(如上图),并没有使用全局锁,返回值不是绝对准确的,因为调用这个方法时还有其他线程可能正在进行计数累加,所以只能得到某个时刻的近似值,这也就是LongAdder并不能完全替代LongAtomic的原因之一。
而且从测试情况来看,线程数越多,并发操作数越大,LongAdder的优势越大,线程数较小时,AtomicLong的性能还超过了LongAdder。