由于cpu cache line机制在共享原子数据操作上带来的硬件干扰会对对多线程性能造成影响。例如不同的原子数据,位于同一个cpu cache line,这时候一个处理器读取这个cpu cache line这段数据的时候,就会控制这段数据的所有权,其他想要读写这段数据的处理器就会处于等等状态。这种情况就是通常说的数据伪共享。因为等待阻塞,所以影响性能。再延伸到cpu cache硬件的数据存取机制,这种影响会导致严重中的并行性能下降,大幅削弱多核优势。
cppreference中的相关代码如下:
namespace hardware_p01
{
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 在 x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │ ... 上为 64 字节
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
std::mutex cout_mutex;
constexpr int max_write_iterations{10'000'000}; // 性能评估时间调节
struct alignas(hardware_constructive_interference_size)
OneCacheLiner
{ // 两个原子变量总共占据一条缓存线(cpu cache line)
std::atomic_uint64_t x{};
std::atomic_uint64_t y{};
} oneCacheLiner;
struct TwoCacheLiner
{ // 两个原子变量各自独立占据一条缓存线,总共使用了两条缓存线(cpu cache line)
alignas(hardware_destructive_interference_size) std::atomic_uint64_t x{};
alignas(hardware_destructive_interference_size) std::atomic_uint64_t y{};
} twoCacheLiner;
inline auto now() noexcept { return std::chrono::high_resolution_clock::now(); }
template <bool xy>
void oneCacheLinerThread()
{
const auto start{now()};
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
oneCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else
oneCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed{now() - start};
std::lock_guard lk{cout_mutex};
std::cout << "oneCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
oneCacheLiner.x = elapsed.count();
else
oneCacheLiner.y = elapsed.count();
}
template <bool xy>
void twoCacheLinerThread()
{
const auto start{now()};
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
twoCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else
twoCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed{now() - start};
std::lock_guard lk{cout_mutex};
std::cout << "twoCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
twoCacheLiner.x = elapsed.count();
else
twoCacheLiner.y = elapsed.count();
}
void testMain()
{
std::atomic_uint64_t ap_01{};
std::cout << "sizeof(int): " << sizeof(int) << " bytes\n";
std::cout << "sizeof(long): " << sizeof(long) << " bytes\n";
std::cout << "sizeof(long long): " << sizeof(long long) << " bytes\n";
std::cout << "sizeof(std::atomic_uint64_t): " << sizeof(std::atomic_uint64_t) << " bytes\n";
std::cout << "\n";
std::cout << "sizeof(oneCacheLiner.x): " << sizeof(oneCacheLiner.x) << " bytes\n";
std::cout << "sizeof(oneCacheLiner.y): " << sizeof(oneCacheLiner.y) << " bytes\n";
std::cout << "sizeof(oneCacheLiner): " << sizeof(oneCacheLiner) << " bytes\n";
std::cout << "\n";
std::cout << "sizeof(twoCacheLiner.x): " << sizeof(twoCacheLiner.x) << " bytes\n";
std::cout << "sizeof(twoCacheLiner.y): " << sizeof(twoCacheLiner.y) << " bytes\n";
std::cout << "sizeof(twoCacheLiner): " << sizeof(twoCacheLiner) << " bytes\n";
std::cout << "\n";
// 获得当前系统cpu核心数量
auto cupCount = std::thread::hardware_concurrency();
std::cout << "cpu核心数量: " << cupCount << "\n";
std::cout << "\n";
std::cout << "__cpp_lib_hardware_interference_size "
#ifdef __cpp_lib_hardware_interference_size
" = "
<< __cpp_lib_hardware_interference_size << "\n";
#else
"is not defined, use 64 as fallback\n";
#endif
std::cout
<< "hardware_destructive_interference_size == "
<< hardware_destructive_interference_size << '\n'
<< "hardware_constructive_interference_size == "
<< hardware_constructive_interference_size << "\n\n";
std::cout
<< std::fixed << std::setprecision(2)
<< "sizeof( OneCacheLiner ) == " << sizeof(OneCacheLiner) << '\n'
<< "sizeof( TwoCacheLiner ) == " << sizeof(TwoCacheLiner) << "\n\n";
constexpr int max_runs{4};
int oneCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{oneCacheLinerThread<0>};
std::thread th2{oneCacheLinerThread<1>};
th1.join();
th2.join();
oneCacheLiner_average += oneCacheLiner.x + oneCacheLiner.y;
}
std::cout << "Average time: " << (oneCacheLiner_average / max_runs / 2) << " ms\n\n";
int twoCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{twoCacheLinerThread<0>};
std::thread th2{twoCacheLinerThread<1>};
th1.join();
th2.join();
twoCacheLiner_average += twoCacheLiner.x + twoCacheLiner.y;
}
std::cout << "Average time: " << (twoCacheLiner_average / max_runs / 2) << " ms\n\n";
}
} // namespace hardware_p01运行上述代码中的 testMain函数,控制台输出如下:
sizeof(int): 4 bytes
sizeof(long): 4 bytes
sizeof(long long): 8 bytes
sizeof(std::atomic_uint64_t): 8 bytes
sizeof(oneCacheLiner.x): 8 bytes
sizeof(oneCacheLiner.y): 8 bytes
sizeof(oneCacheLiner): 64 bytes
sizeof(twoCacheLiner.x): 8 bytes
sizeof(twoCacheLiner.y): 8 bytes
sizeof(twoCacheLiner): 128 bytes
cpu核心数量: 16
__cpp_lib_hardware_interference_size = 201703
hardware_destructive_interference_size == 64
hardware_constructive_interference_size == 64
sizeof( OneCacheLiner ) == 64
sizeof( TwoCacheLiner ) == 128
oneCacheLinerThread() spent 206.88 ms
oneCacheLinerThread() spent 208.91 ms
oneCacheLinerThread() spent 256.23 ms
oneCacheLinerThread() spent 264.54 ms
oneCacheLinerThread() spent 167.86 ms
oneCacheLinerThread() spent 173.16 ms
oneCacheLinerThread() spent 198.84 ms
oneCacheLinerThread() spent 207.99 ms
Average time: 209 ms
twoCacheLinerThread() spent 59.24 ms
twoCacheLinerThread() spent 59.37 ms
twoCacheLinerThread() spent 61.98 ms
twoCacheLinerThread() spent 66.52 ms
twoCacheLinerThread() spent 65.99 ms
twoCacheLinerThread() spent 68.66 ms
twoCacheLinerThread() spent 59.04 ms
twoCacheLinerThread() spent 63.32 ms
Average time: 62 ms由上述代码可以看出,当两个原子变量的数据位于同一个cpu cache line的时候(oneCacheLiner中的x和y)访问耗时,是位于各自独立的cpu cache line的数据(twoCacheLiner中的x和y)访问耗时的3倍多。
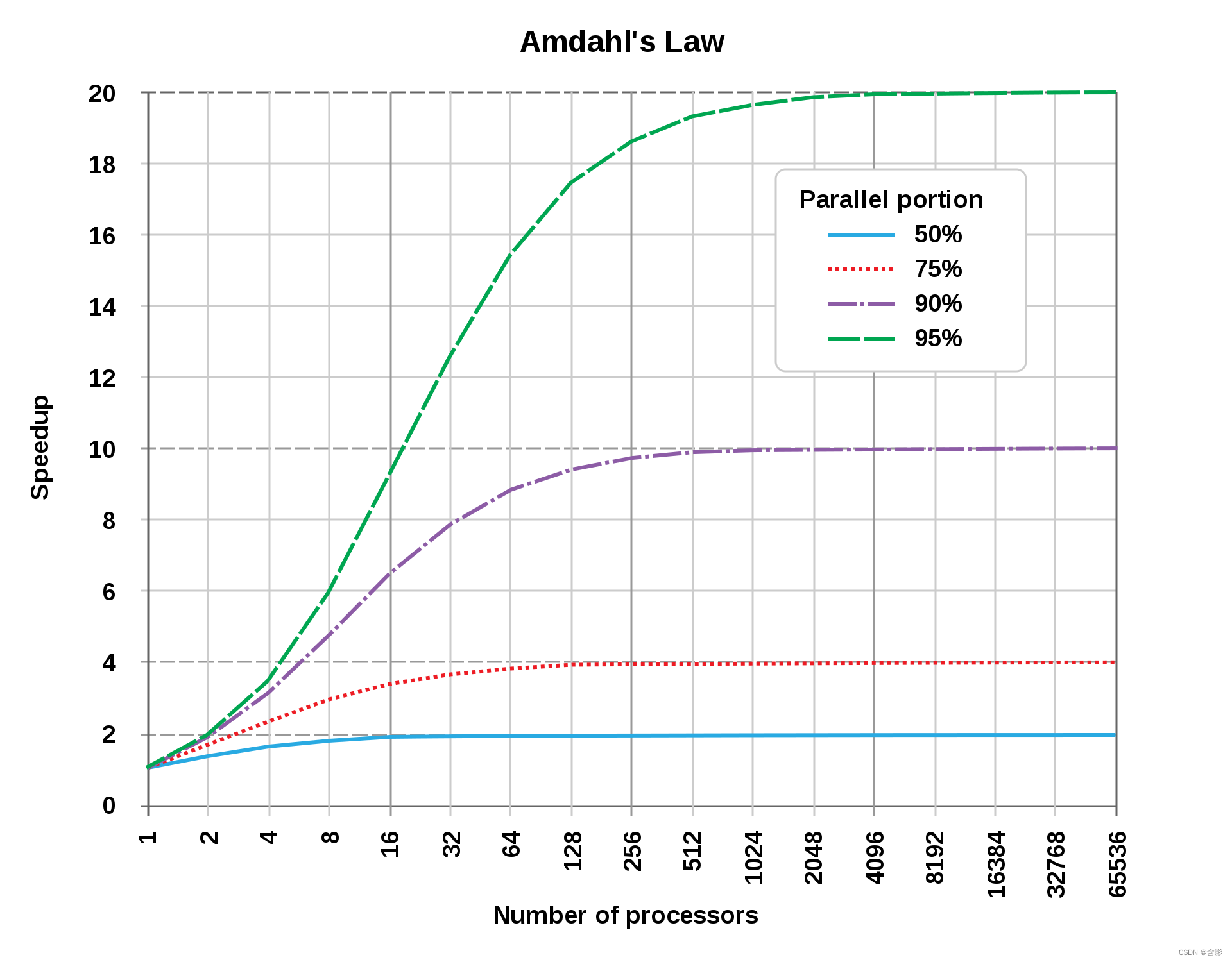
顺带提一下阿姆达尔定律(Amdahl's law,Amdahl's argument),这是一个计算机科学界的经验法则,因吉恩·阿姆达尔而得名。它代表了处理器并行运算之后效率提升的能力。

上图公式的含义是: 当程序“串行”部分的耗时用fs来表示的时候,那么性能增益(P)就可以通过处理器数量(N)进行估计。