Go实现LogAgent:海量日志收集系统【下篇】
0 前置文章
Go实现LogAgent:海量日志收集系统【上篇——LogAgent实现】
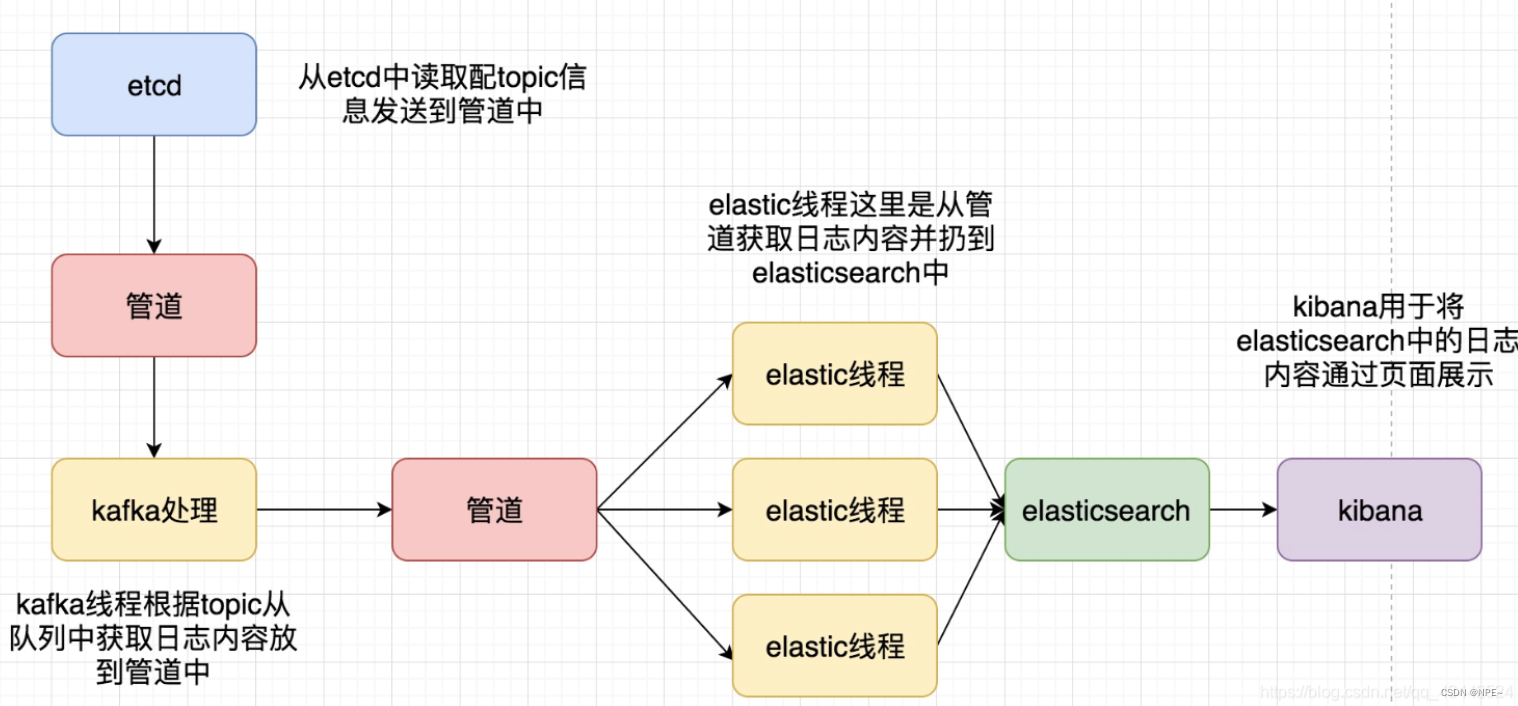
前面的章节我们已经完成了日志收集(LogAgent),接下来我们需要将日志写入到kafka中,然后将数据落地到Elasticsearch中。
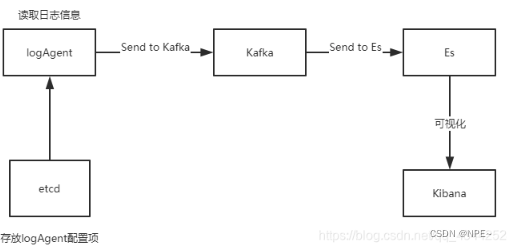
项目架构图:
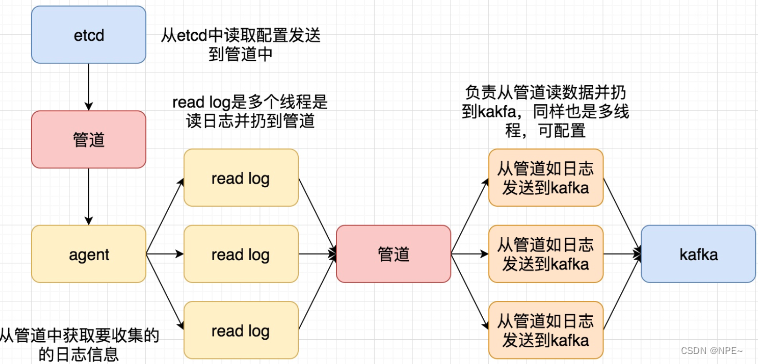
项目逻辑图:
1 docker搭建Elasticsearcsh、Kibana
如果没有docker环境的,可以在本机安装
docker desktop
# 1 创建一个docker网络
docker network create es-net
# 查看本机网络
docker network ls
# 删除一个网络
docker network rm es-net
# 2 拉取es、kibana镜像
docker pull elasticsearch:7.17.4
docker pull kibana:7.17.4
# 3 创建es容器并挂在数据卷
mkdir -p /Users/xxx/docker-home/es-data/_data
mkdir -p /Users/xxx/docker-home/es-plugins
mkdir -p /Users/xxx/docker-home/es-config
mkdir -p /Users/xxx/docker-home/kibana-config
touch elasticsearch.yml
touch kibana.yml
1.需要保证要挂载的目录有读写权限,包括要挂载的配置文件。如果没有则用chmod 777命令
2.如果要挂载配置文件,则需要提前把配置文件内容写好,不能为空,否则可能会影响es和kibana运行。
3.如果只挂载到配置文件目录,不准备配置文件,会导致创建容器后没有配置文件。报错
elasticsearch.yml:
cluster.name: "docker-cluster"
network.host: 0.0.0.0
kibana.yml:
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
启动es:
docker run -d \
--name es7.17.4 -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /Users/xxx/docker-home/es-data/_data:/usr/share/elasticsearch/data \
-v /Users/xxx/docker-home/es-plugins:/usr/share/elasticsearch/plugins \
-v /Users/xxx/docker-home/es-config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
--privileged \
--network es-net \
elasticsearch:7.17.4
启动Kibana:
docker run -d \
--name kibana17 \
--network=es-net \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://es7.17.4:9200 \
kibana:7.17.4
-e ELASTICSEARCH_HOSTS=http://es7.17.4:9200 \ 其中,es7.17.4的名称为上面es容器的名称
结果:
2 golang操作es
执行下面代码在es中添加索引,然后到kibana页面创建索引
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
type Tweet struct {
User string
Message string
}
func main() {
client, err := elastic.NewClient(elastic.SetSniff(false), elastic.SetURL("http://localhost:9200/"))
if err != nil {
fmt.Println("connect es error", err)
return
}
fmt.Println("conn es succ")
tweet := Tweet{User: "haohan", Message: "This is a test"}
_, err = client.Index().
Index("twitter").
Id("1").
BodyJson(tweet).
Do(context.Background())
if err != nil {
// Handle error
panic(err)
return
}
fmt.Println("insert succ")
}
# 执行上面的go代码执行,控制台输出如下表明插入成功
conn es succ
insert succ
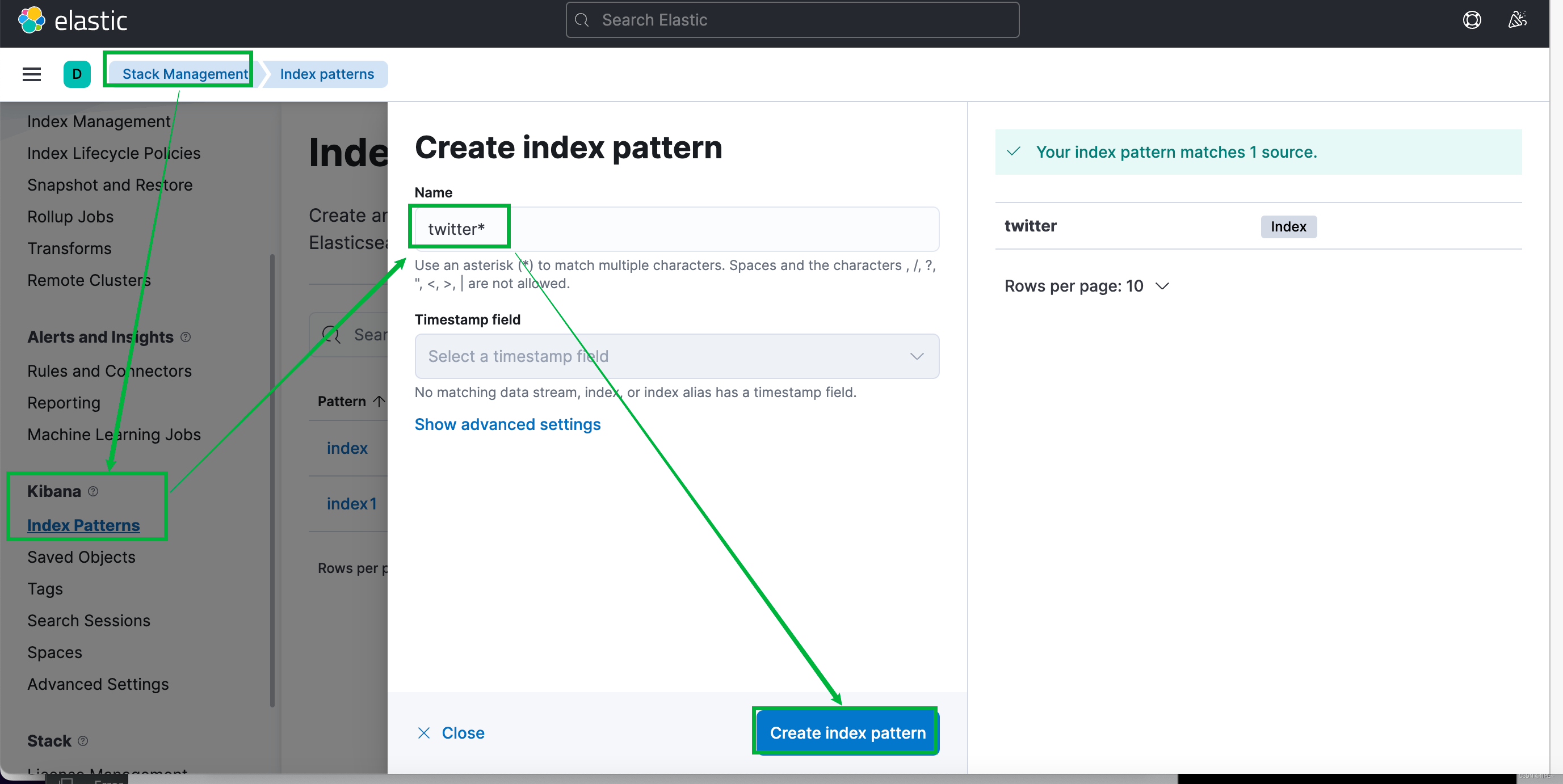
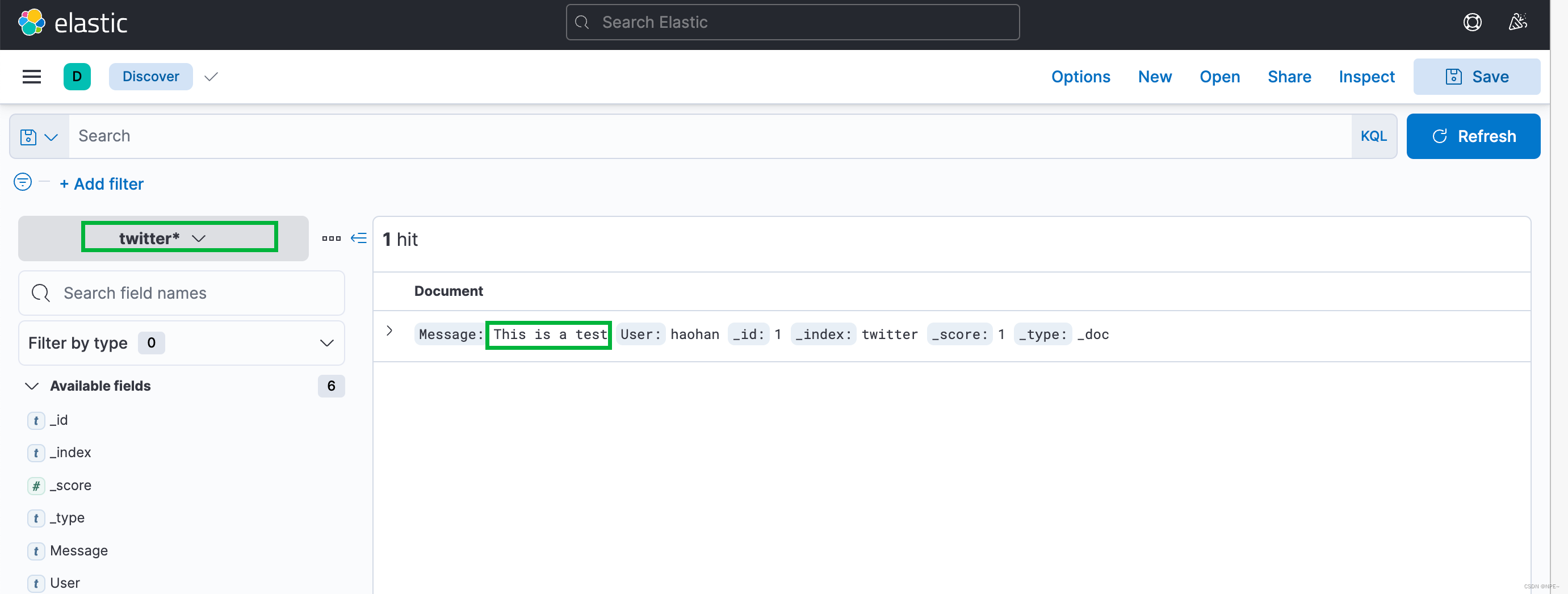
然后我们手动到kibana中添加对应的index即可搜索出对应数据
3 开发LogTransfer:从kafka中读取数据并写入es
在前面的开发中,我们已经将日志写入到了kafka。接下来我们要做的就是从kafka中消费数据,然后写入到es中。LogTransfer做的就是这个工作。
3.1 项目结构
├─config
│ logTransfer.conf
│
├─es
│ elasticsearch.go
│
├─logs
│ my.log
│
└─main
kafka.go
config.go
log.go
main.go

3.2 项目代码
①LogTransfer/main/main.go
package main
import (
"github.com/astaxie/beego/logs"
)
func main() {
// 初始化配置
err := InitConfig("ini", "/Users/xxx/GolandProjects/LogCollect/LogTransfer/config/log_transfer.conf")
if err != nil {
panic(err)
return
}
logs.Debug("初始化配置成功")
//初始化日志模块
err = initLogger(logConfig.LogPath, logConfig.LogLevel)
if err != nil {
panic(err)
return
}
logs.Debug("初始化日志模块成功")
// 初始化Kafka
err = InitKafka(logConfig.KafkaAddr, logConfig.KafkaTopic)
if err != nil {
logs.Error("初始化Kafka失败, err:", err)
return
}
logs.Debug("初始化Kafka成功")
}
②LogTransfer/main/log.go
package main
import (
"encoding/json"
"fmt"
"github.com/astaxie/beego/logs"
)
func convertLogLevel(level string) int {
switch level {
case "debug":
return logs.LevelDebug
case "warn":
return logs.LevelWarn
case "info":
return logs.LevelInfo
case "trace":
return logs.LevelTrace
}
return logs.LevelDebug
}
func initLogger(logPath string, logLevel string) (err error) {
config := make(map[string]interface{})
config["filename"] = logPath
config["level"] = convertLogLevel(logLevel)
configStr, err := json.Marshal(config)
if err != nil {
fmt.Println("初始化日志, 序列化失败:", err)
return
}
_ = logs.SetLogger(logs.AdapterFile, string(configStr))
return
}
③LogTransfer/main/kafka.go
package main
import (
"github.com/IBM/sarama"
"github.com/astaxie/beego/logs"
"strings"
)
type KafkaClient struct {
client sarama.Consumer
addr string
topic string
}
var (
kafkaClient *KafkaClient
)
func InitKafka(addr string, topic string) (err error) {
kafkaClient = &KafkaClient{}
consumer, err := sarama.NewConsumer(strings.Split(addr, ","), nil)
if err != nil {
logs.Error("启动Kafka消费者错误: %s", err)
return nil
}
kafkaClient.client = consumer
kafkaClient.addr = addr
kafkaClient.topic = topic
return
}
④LogTransfer/main/config.go
package main
import (
"fmt"
"github.com/astaxie/beego/config"
)
type LogConfig struct {
KafkaAddr string
KafkaTopic string
EsAddr string
LogPath string
LogLevel string
}
var (
logConfig *LogConfig
)
func InitConfig(confType string, filename string) (err error) {
conf, err := config.NewConfig(confType, filename)
if err != nil {
fmt.Printf("初始化配置文件出错:%v\n", err)
return
}
// 导入配置信息
logConfig = &LogConfig{}
// 日志级别
logConfig.LogLevel = conf.String("logs::log_level")
if len(logConfig.LogLevel) == 0 {
logConfig.LogLevel = "debug"
}
// 日志输出路径
logConfig.LogPath = conf.String("logs::log_path")
if len(logConfig.LogPath) == 0 {
logConfig.LogPath = "/Users/xxx/GolandProjects/LogCollect/LogTransfer/logs/log_transfer.log"
}
// Kafka
logConfig.KafkaAddr = conf.String("kafka::server_addr")
if len(logConfig.KafkaAddr) == 0 {
err = fmt.Errorf("初识化Kafka addr失败")
return
}
logConfig.KafkaTopic = conf.String("kafka::topic")
if len(logConfig.KafkaAddr) == 0 {
err = fmt.Errorf("初识化Kafka topic失败")
return
}
// Es
logConfig.EsAddr = conf.String("elasticsearch::addr")
if len(logConfig.EsAddr) == 0 {
err = fmt.Errorf("初识化Es addr失败")
return
}
return
}
④LogTransfer/config/log_transfer.conf
[logs]
log_level = debug
log_path = "/Users/xxx/GolandProjects/LogCollect/LogTransfer/logs/log_transfer.log"
[kafka]
server_addr = localhost:9092
topic = nginx_log
[elasticsearch]
addr = http://localhost:9200/
⑤LogTransfer/es/es.go
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
type Tweet struct {
User string
Message string
}
func main() {
client, err := elastic.NewClient(elastic.SetSniff(false), elastic.SetURL("http://localhost:9200/"))
if err != nil {
fmt.Println("connect es error", err)
return
}
fmt.Println("conn es succ")
tweet := Tweet{User: "haohan", Message: "This is a test"}
_, err = client.Index().
Index("twitter").
Id("1").
BodyJson(tweet).
Do(context.Background())
if err != nil {
// Handle error
panic(err)
return
}
fmt.Println("insert succ")
}
结果
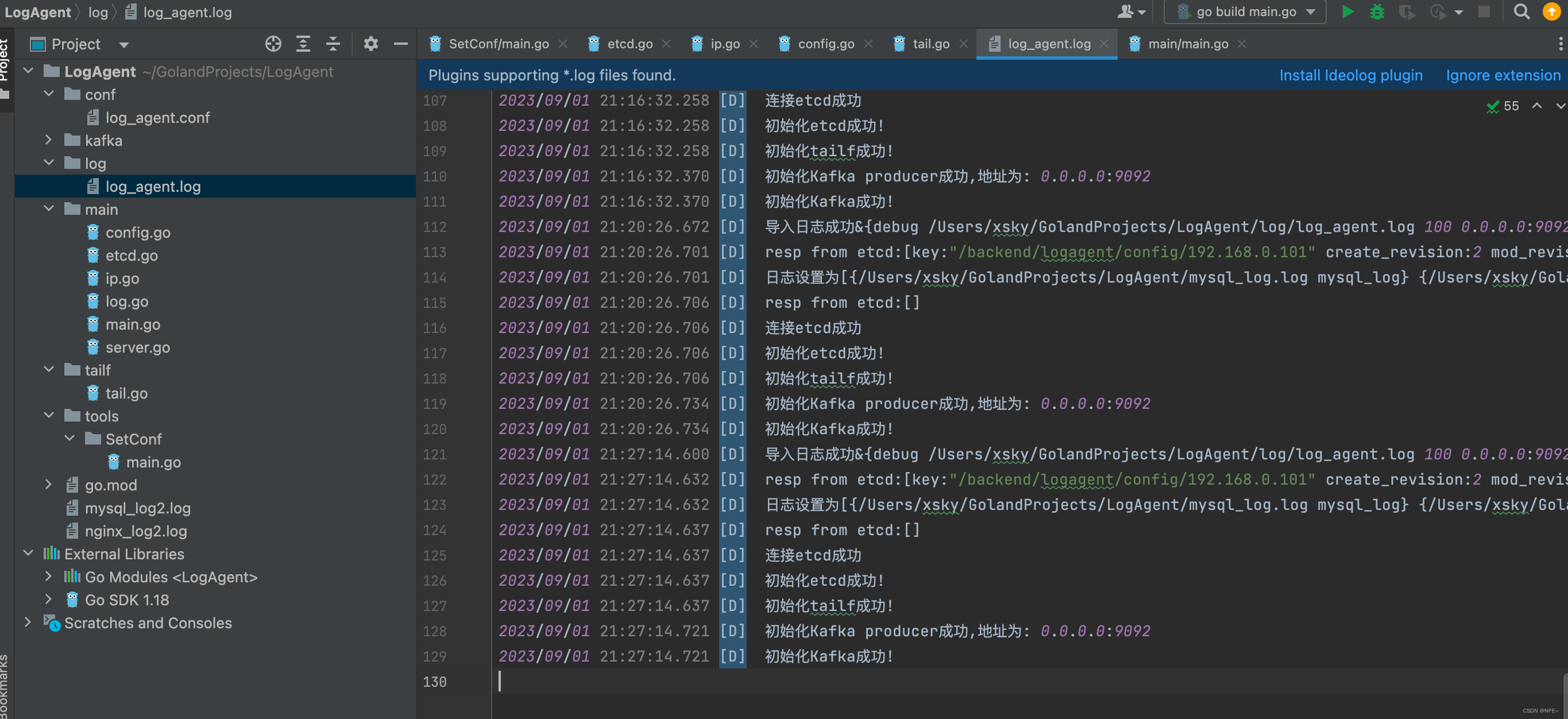
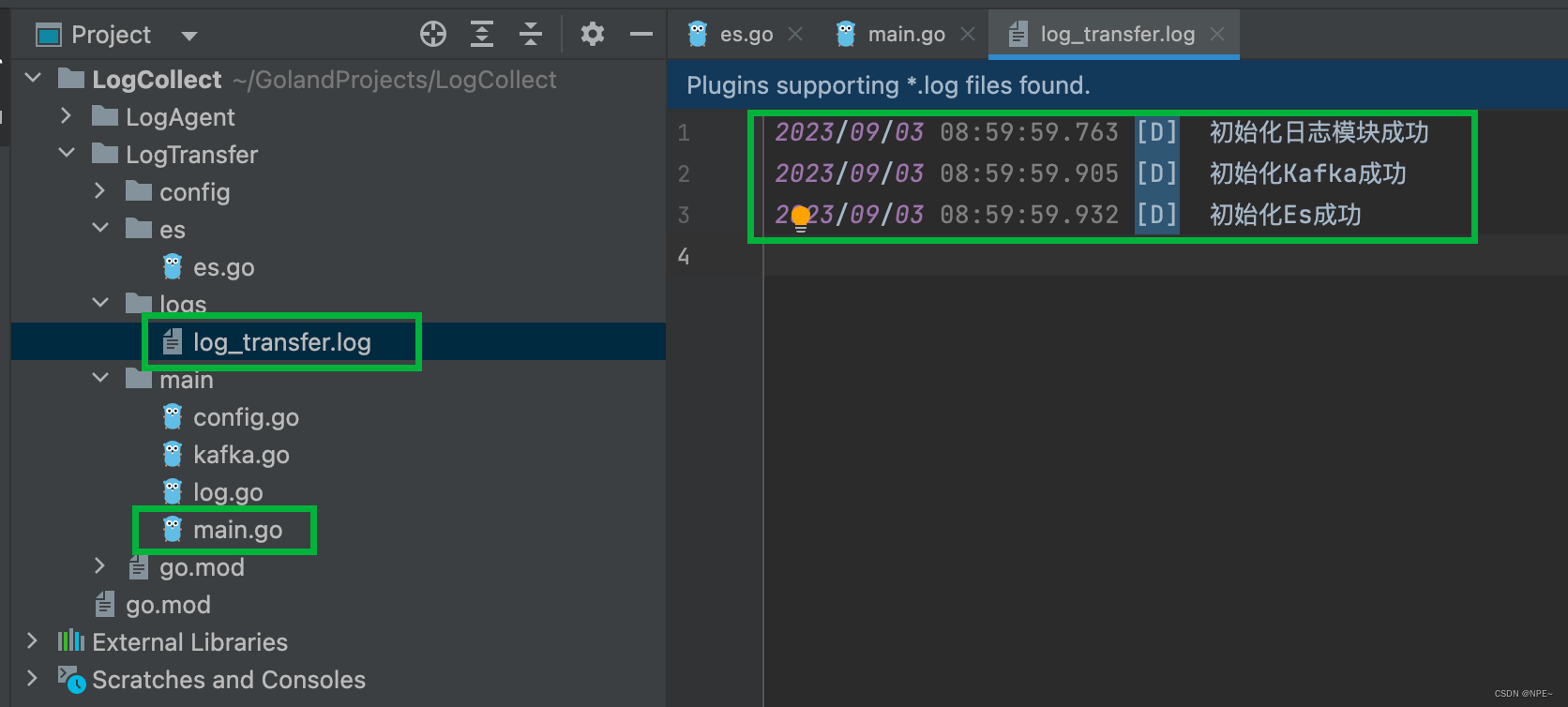
LogTransfer的运行日志在LogTransfer/logs/log_transfer.log中
logs/log_transfer.log:
2023/09/02 19:55:29.037 [D] 初始化日志模块成功
2023/09/02 19:55:29.074 [D] 初始化Kafka成功
4 完成LogTransfer:将日志入库到es并通过kibana展示
前面我们将LogTransfer的配置初始化成功了,下面我们将从Kafka中消费数据,然后将日志入库到es,最后通过kibana展示。
4.1 将日志保存到es
在LogTransfer/main/main.go中添加初始化InitEs函数
①main.go中添加InitEs函数
LogTransfer/main/main.go:
package main
import (
"github.com/astaxie/beego/logs"
"logtransfer.com/es"
)
func main() {
// 初始化配置
err := InitConfig("ini", "/Users/xxx/GolandProjects/LogCollect/LogTransfer/config/log_transfer.conf")
if err != nil {
panic(err)
return
}
logs.Debug("初始化配置成功")
//初始化日志模块
err = initLogger(logConfig.LogPath, logConfig.LogLevel)
if err != nil {
panic(err)
return
}
logs.Debug("初始化日志模块成功")
// 初始化Kafka
err = InitKafka(logConfig.KafkaAddr, logConfig.KafkaTopic)
if err != nil {
logs.Error("初始化Kafka失败, err:", err)
return
}
logs.Debug("初始化Kafka成功")
// 初始化Es
err = es.InitEs(logConfig.EsAddr)
if err != nil {
logs.Error("初始化Elasticsearch失败, err:", err)
return
}
logs.Debug("初始化Es成功")
}
运行LogTransfer下的main.go可以发现log_transfer.log中输出的日志信息
②LogTransfer/es/es.go
package es
import (
"fmt"
"github.com/olivere/elastic/v7"
)
type Tweet struct {
User string
Message string
}
var (
esClient *elastic.Client
)
func InitEs(addr string) (err error) {
client, err := elastic.NewClient(elastic.SetSniff(false), elastic.SetURL(addr))
if err != nil {
fmt.Println("connect es error", err)
return nil
}
esClient = client
return
}
运行LogTransfer/main下的main函数
- 可以从logs/log_transfer.log中看到打印初始化es、kafka等成功
③添加run.go:消费kafka中的数据
在main函数中添加run函数, 用于运行kafka消费数据到Es
package main
import (
"github.com/Shopify/sarama"
"github.com/astaxie/beego/logs"
)
func run() (err error) {
partitionList, err := kafkaClient.Client.Partitions(kafkaClient.Topic)
if err != nil {
logs.Error("Failed to get the list of partitions: ", err)
return
}
for partition := range partitionList {
pc, errRet := kafkaClient.Client.ConsumePartition(kafkaClient.Topic, int32(partition), sarama.OffsetNewest)
if errRet != nil {
err = errRet
logs.Error("Failed to start consumer for partition %d: %s\n", partition, err)
return
}
defer pc.AsyncClose()
kafkaClient.wg.Add(1)
go func(pc sarama.PartitionConsumer) {
for msg := range pc.Messages() {
logs.Debug("Partition:%d, Offset:%d, Key:%s, Value:%s", msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
err = es.SendToES(kafkaClient.topic, msg.Value)
if err != nil {
logs.Warn("send to es failed, err:%v", err)
}
}
kafkaClient.wg.Done()
}(pc)
}
kafkaClient.wg.Wait()
return
}
④main.go中添加SendToES函数
package main
import (
"github.com/astaxie/beego/logs"
"logtransfer.com/es"
)
func main() {
// 初始化配置
err := InitConfig("ini", "/Users/xxx/GolandProjects/LogCollect/LogTransfer/config/log_transfer.conf")
if err != nil {
panic(err)
return
}
logs.Debug("初始化配置成功")
//初始化日志模块
err = initLogger(logConfig.LogPath, logConfig.LogLevel)
if err != nil {
panic(err)
return
}
logs.Debug("初始化日志模块成功")
// 初始化Kafka
err = InitKafka(logConfig.KafkaAddr, logConfig.KafkaTopic)
if err != nil {
logs.Error("初始化Kafka失败, err:", err)
return
}
logs.Debug("初始化Kafka成功")
// 初始化Es
err = es.InitEs(logConfig.EsAddr)
if err != nil {
logs.Error("初始化Elasticsearch失败, err:", err)
return
}
logs.Debug("初始化Es成功")
// 运行
err = run()
if err != nil {
logs.Error("运行错误, err:", err)
return
}
select {}
}
5 联调
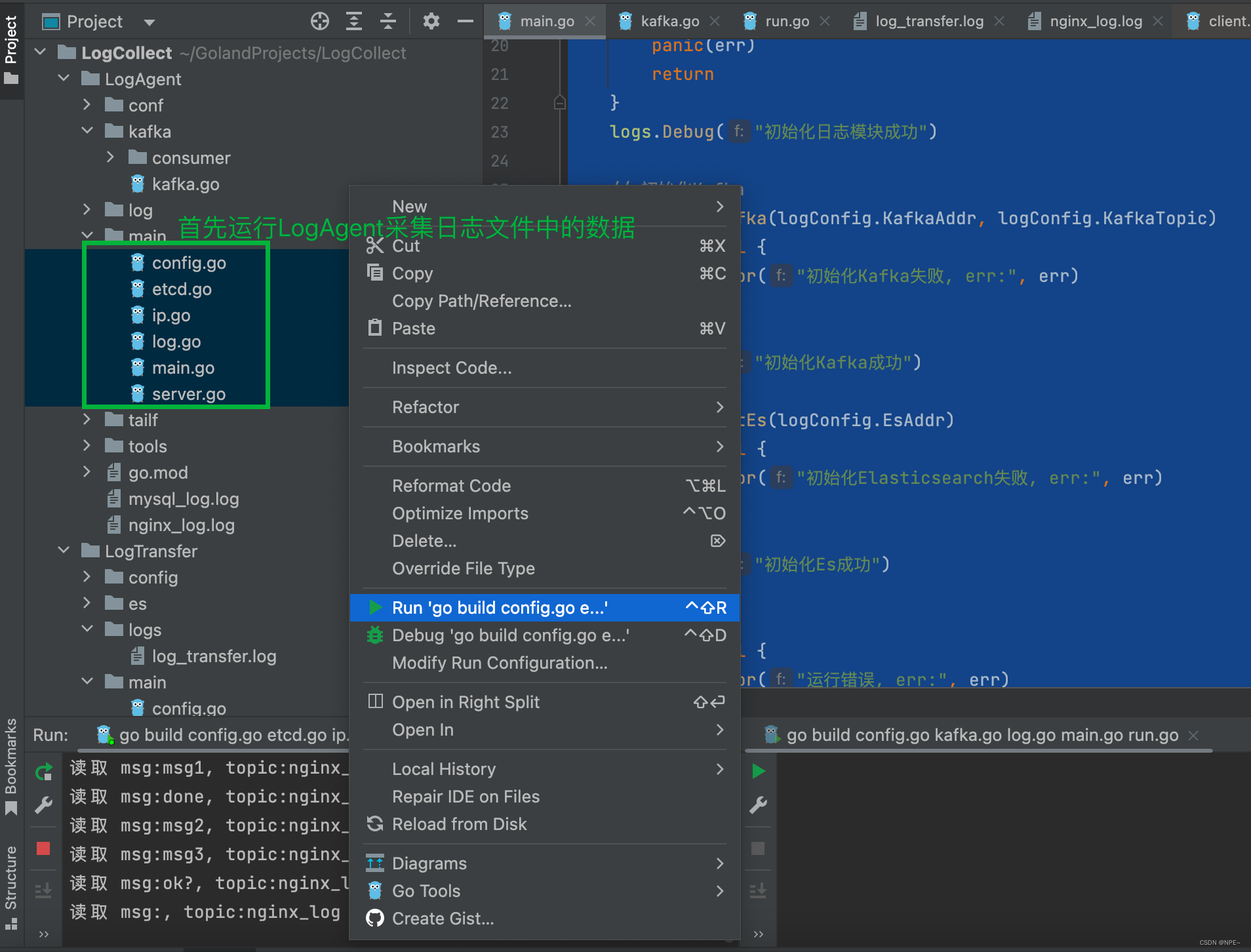
5.1 运行LogAgent:采集数据并存储到kafka
# 用于向docker中的etcd写入对应key
docker exec etcd1 etcdctl put /backend/logagent/config/192.168.0.103 "[{\"logpath\":\"/Users/xxx/GolandProjects/LogCollect/LogAgent/mysql_log.log\",\"topic\":\"mysql_log\"},{\"logpath\":\"/Users/xxx/GolandProjects/LogCollect/LogAgent/nginx_log.log\",\"topic\":\"nginx_log\"}]"
通过上面的命令,用于向etcd中写入对应key,etcd的watcher监视到后会对应更新配置
查看LogAgent的运行日志:
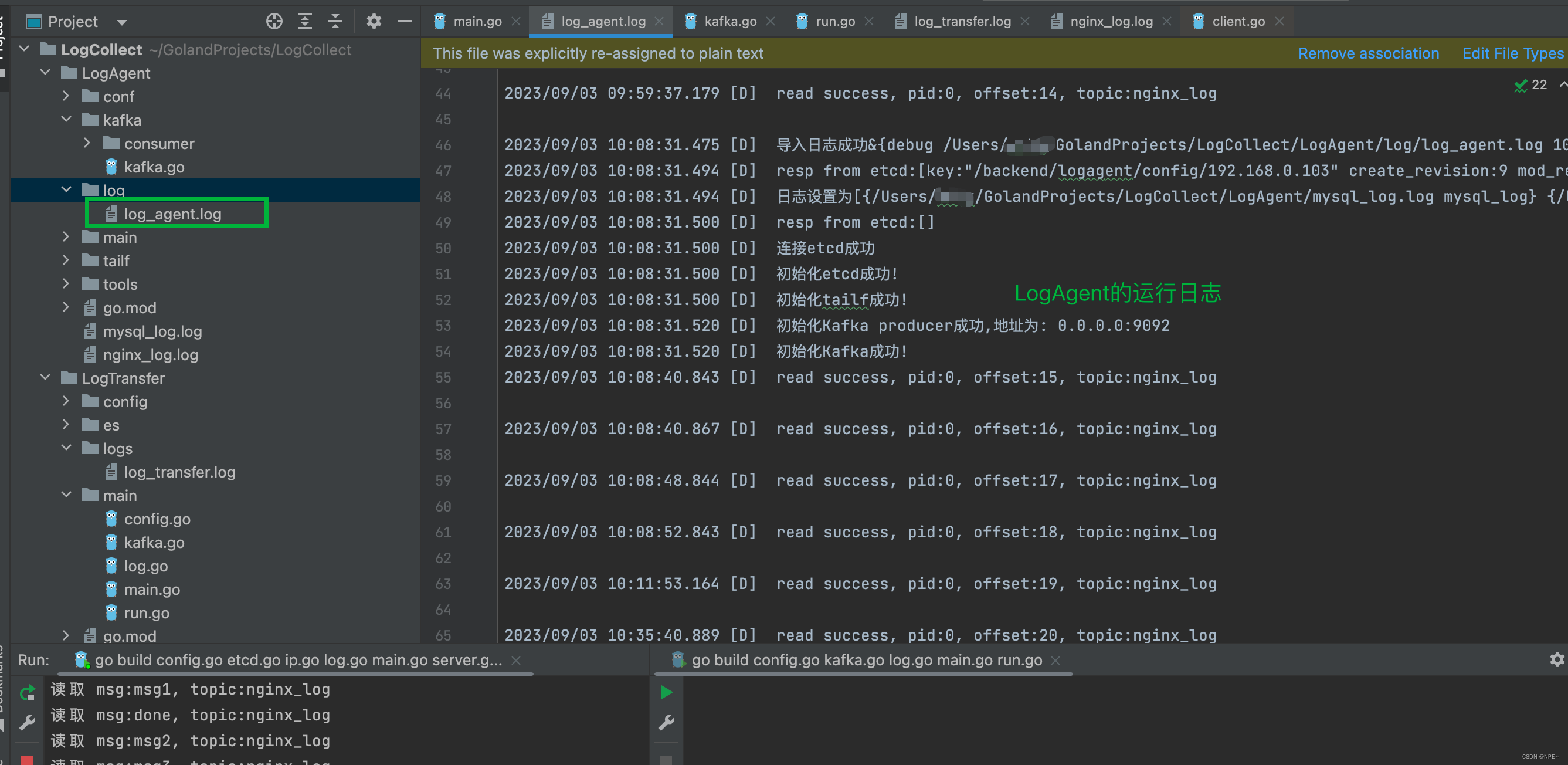
5.2 运行LogTransfer:消费kafka数据并存到es
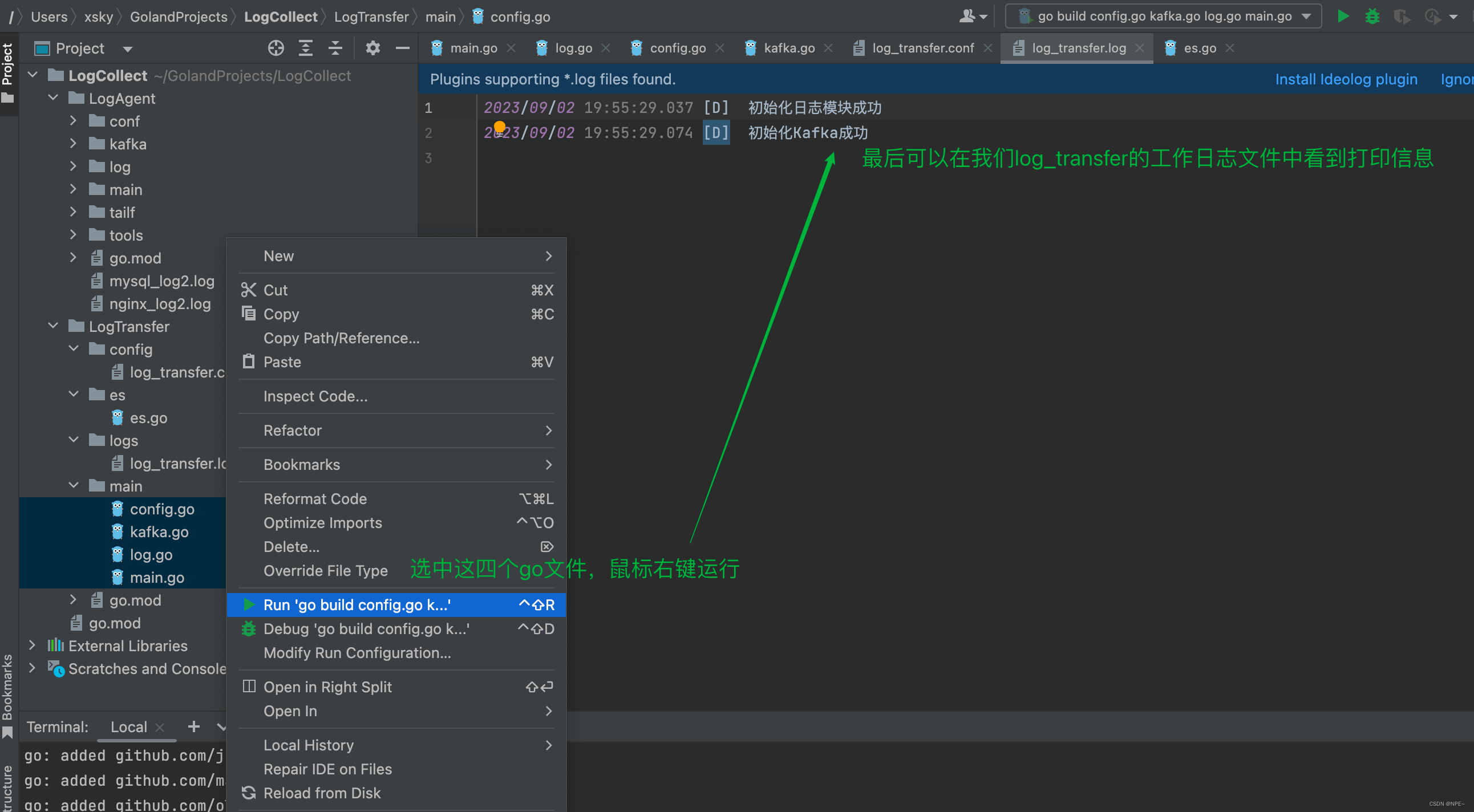
选中LogTransfer下main文件夹下的所有go文件,鼠标右击运行,查看控制台输出
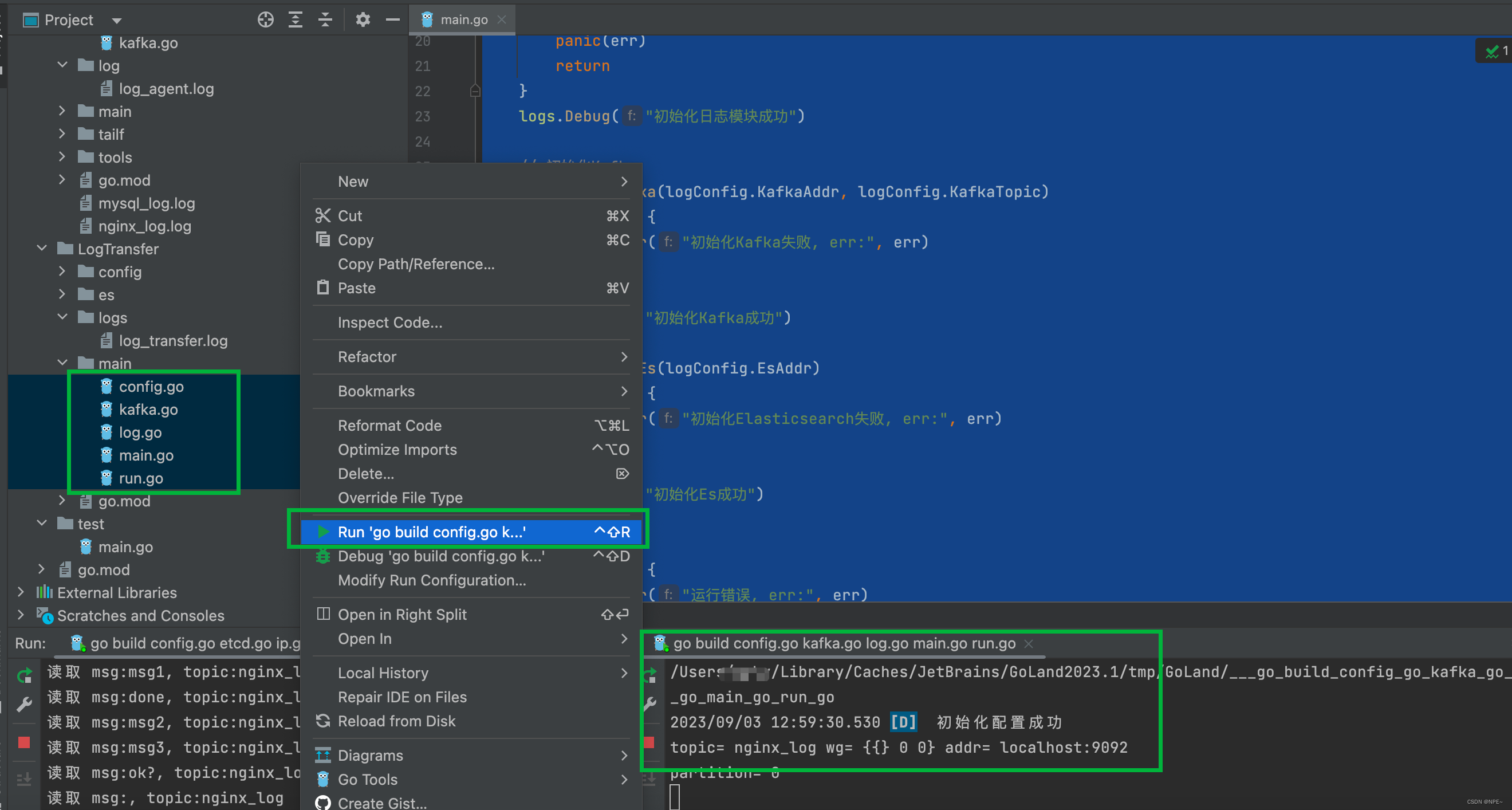
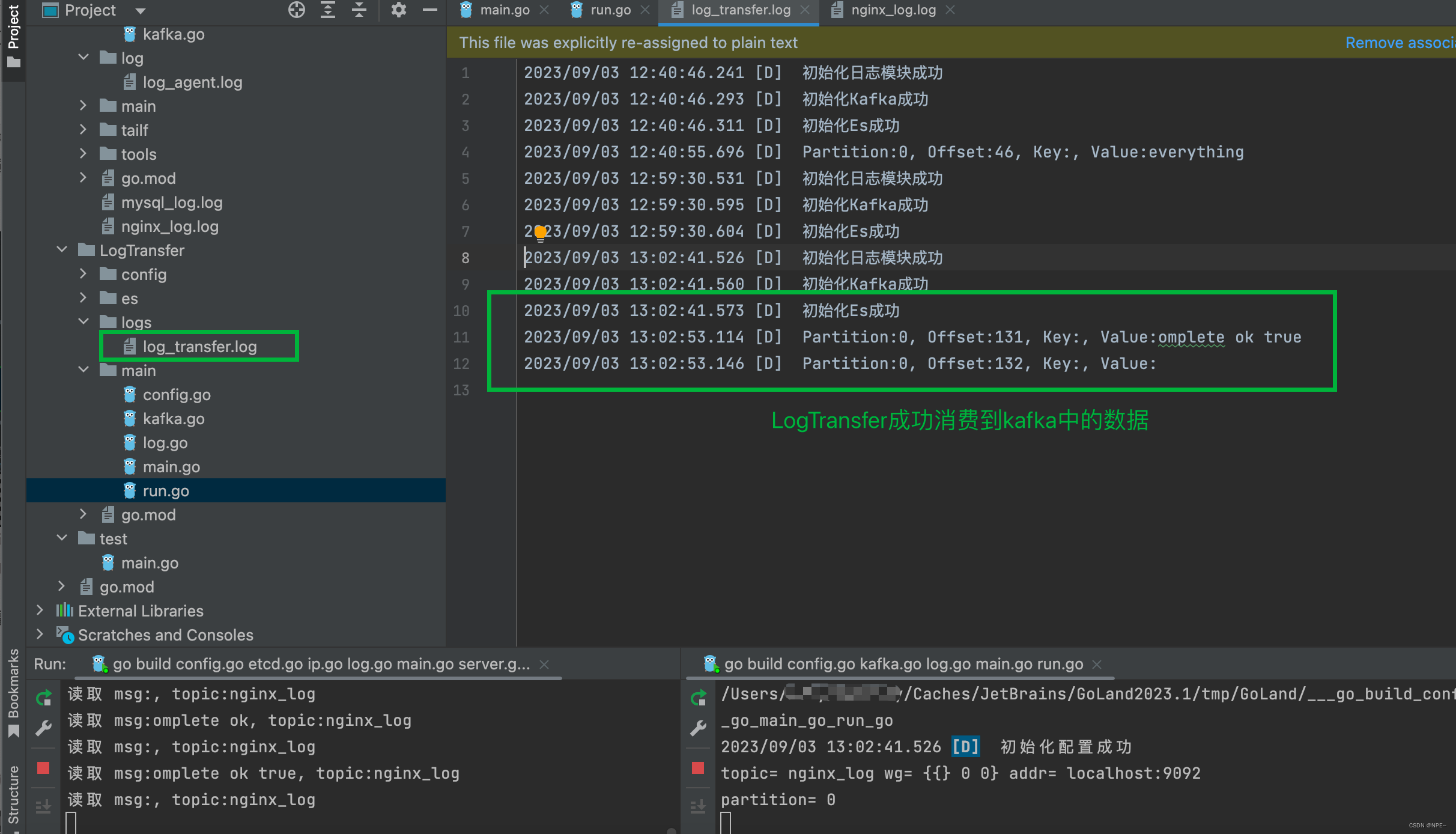
查看LogTransfer的运行日志:
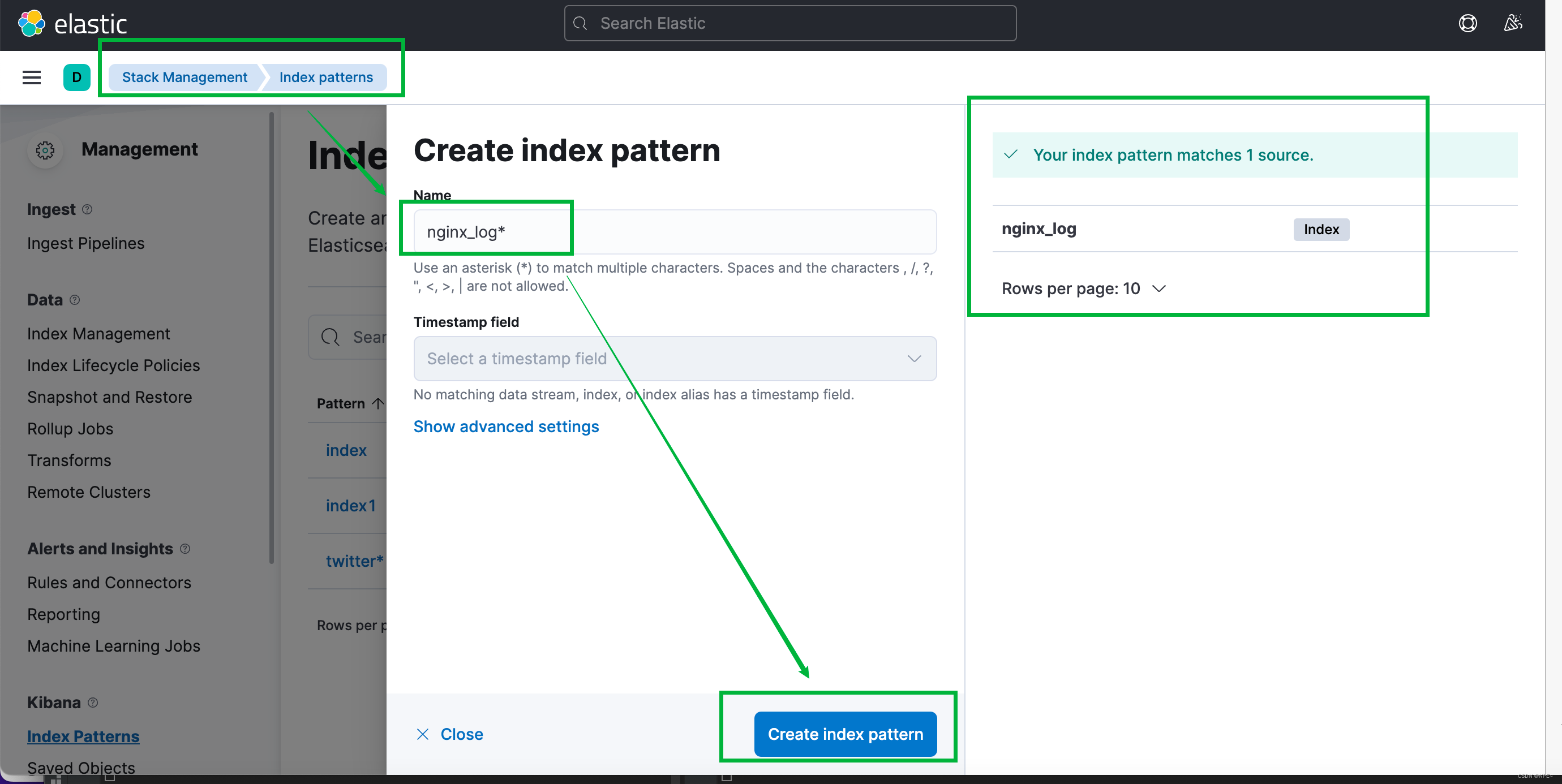
5.3 在kibana创建index并查看
Management - Stack Management - Kibana - Index Patterns ,根据kafka中的topic创建对应的索引。以nginx_log为例:
回到overview,根据nginx_log这个index搜索信息:
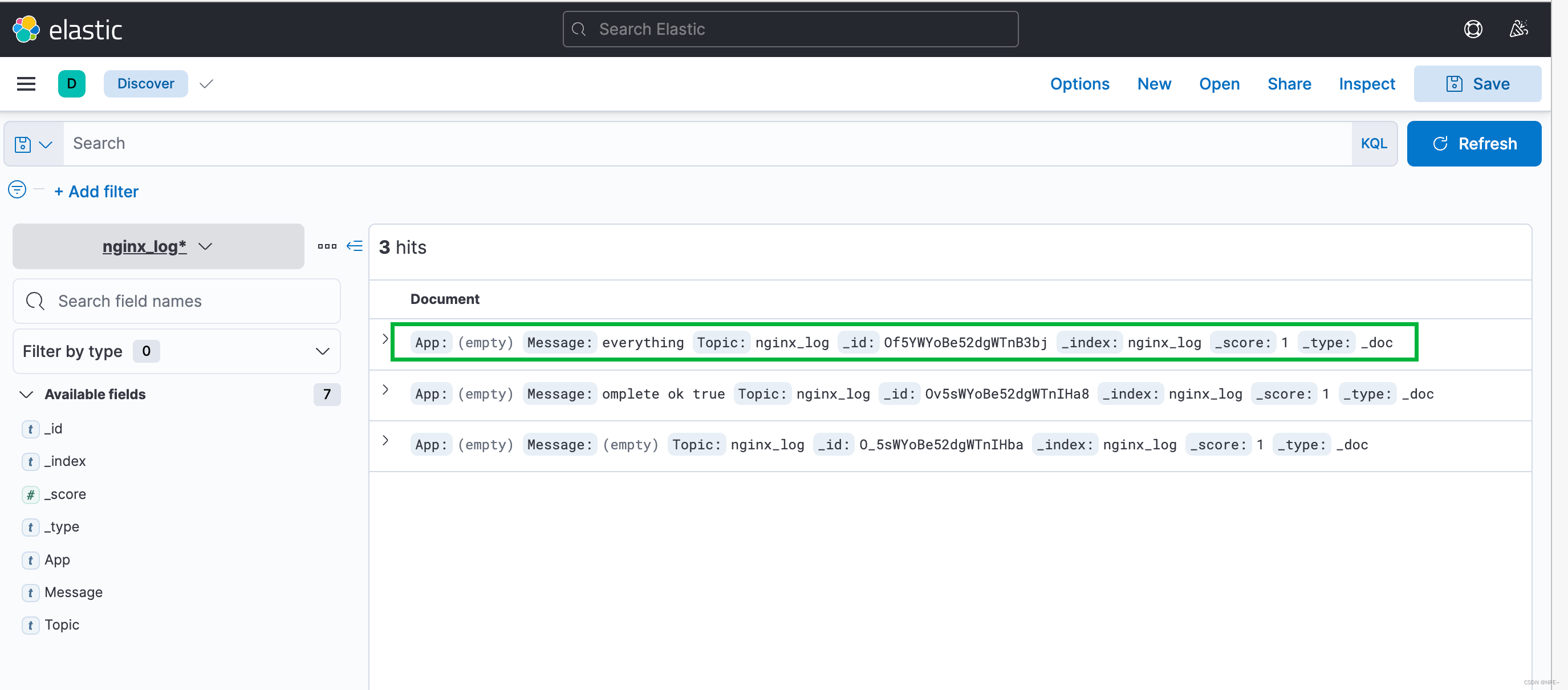
可以看到成功读取到日志信息,至此该项目已开发完成
参考文章:https://blog.csdn.net/qq_43442524/article/details/105072952