文章目录
- 1、简介
- 2、安装
- 2.1 安装nltk库
- 2.2 安装nltk语料库
- 3、测试
- 3.1 分句分词
- 3.2 停用词过滤
- 3.3 词干提取
- 3.4 词形/词干还原
- 3.5 同义词与反义词
- 3.6 语义相关性
- 3.7 词性标注
- 3.8 Text对象
- 结语
1、简介
NLTK - 自然语言工具包 - 是一套开源Python。 支持自然研究和开发的模块、数据集和教程 语言处理。NLTK 需要 Python 版本 3.7、3.8、3.9、3.10 或 3.11。
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。它提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet),还有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库,以及工业级NLP库的封装器和一个活跃的讨论论坛。

2、安装
2.1 安装nltk库
The Natural Language Toolkit (NLTK) is a Python package for natural language processing. NLTK requires Python 3.7, 3.8, 3.9, 3.10 or 3.11.
pip install nltk
# or
pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
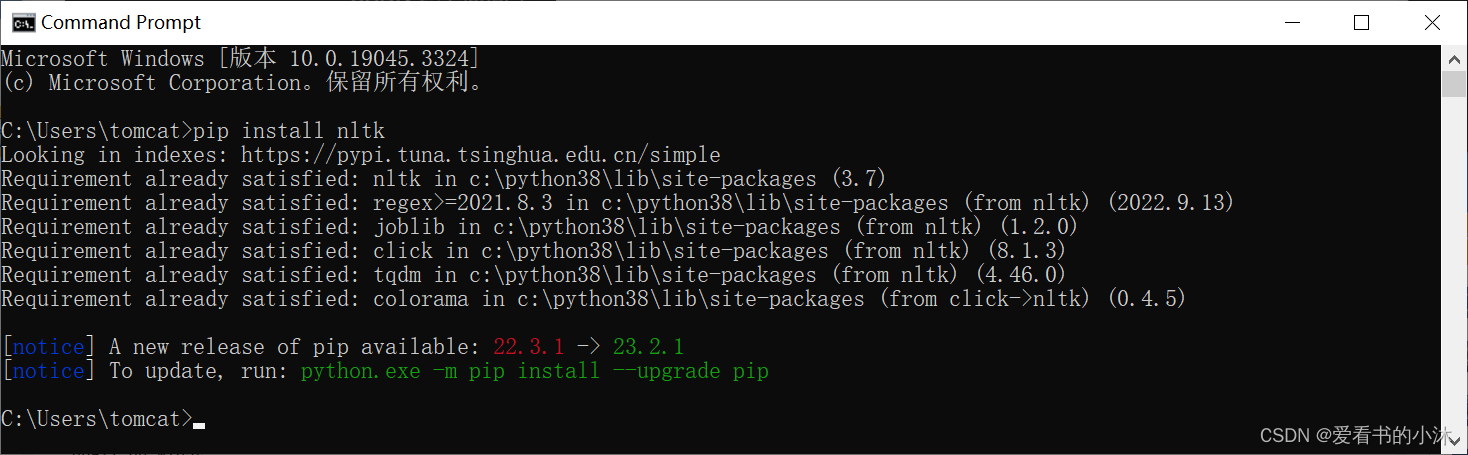
可以用以下代码测试nltk分词的功能:
2.2 安装nltk语料库
在NLTK模块中包含数十种完整的语料库,可用来练习使用,如下所示:
古腾堡语料库:gutenberg,包含古藤堡项目电子文档的一小部分文本,约有36000本免费电子书。
网络聊天语料库:webtext、nps_chat
布朗语料库:brown
路透社语料库:reuters
影评语料库:movie_reviews,拥有评论、被标记为正面或负面的语料库;
就职演讲语料库:inaugural,有55个文本的集合,每个文本是某个总统在不同时间的演说.
- 方法1:在线下载
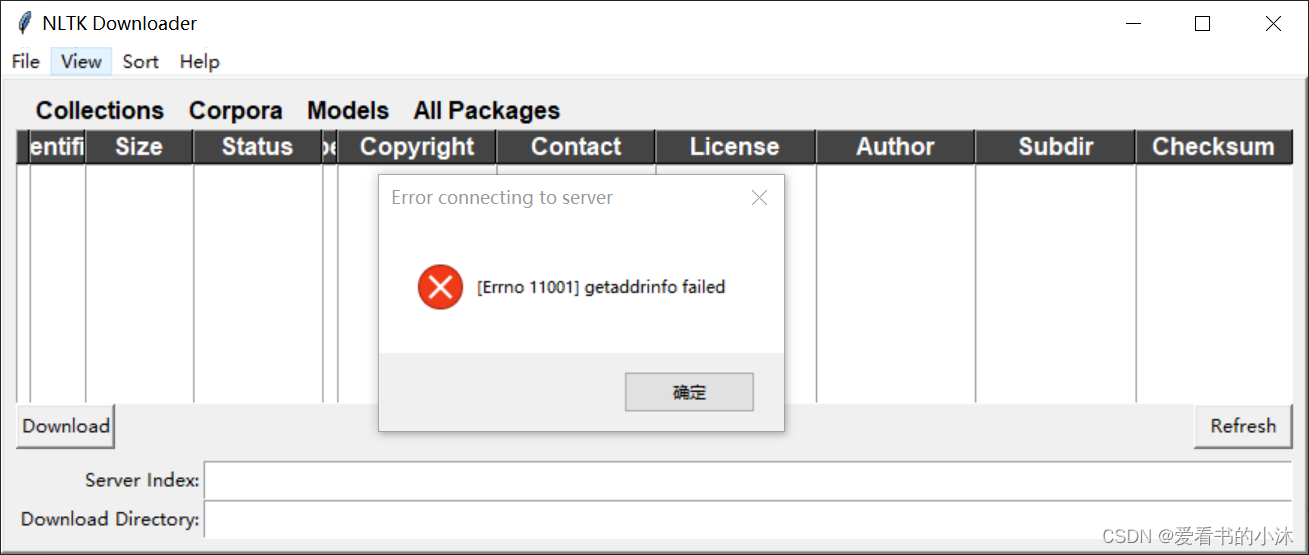
import nltk
nltk.download()
通过上面命令代码下载,大概率是失败的。
-
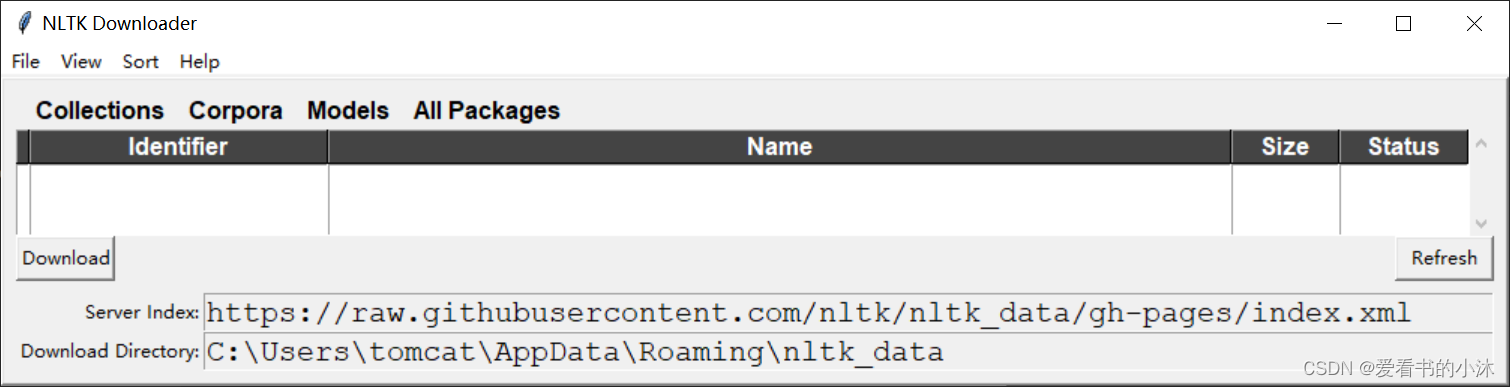
方法2:手动下载,离线安装
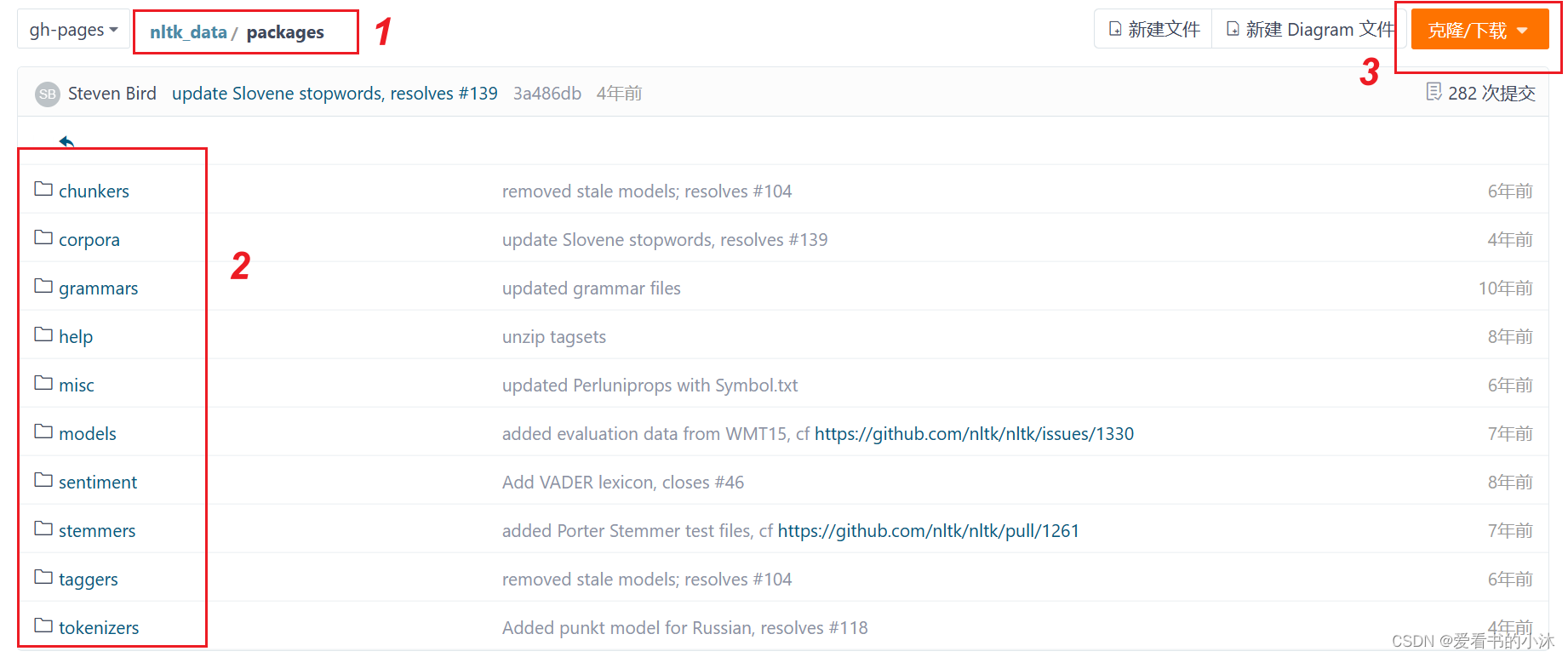
github:https://github.com/nltk/nltk_data/tree/gh-pages
gitee:https://gitee.com/qwererer2/nltk_data/tree/gh-pages
-
查看packages文件夹应该放在哪个路径下
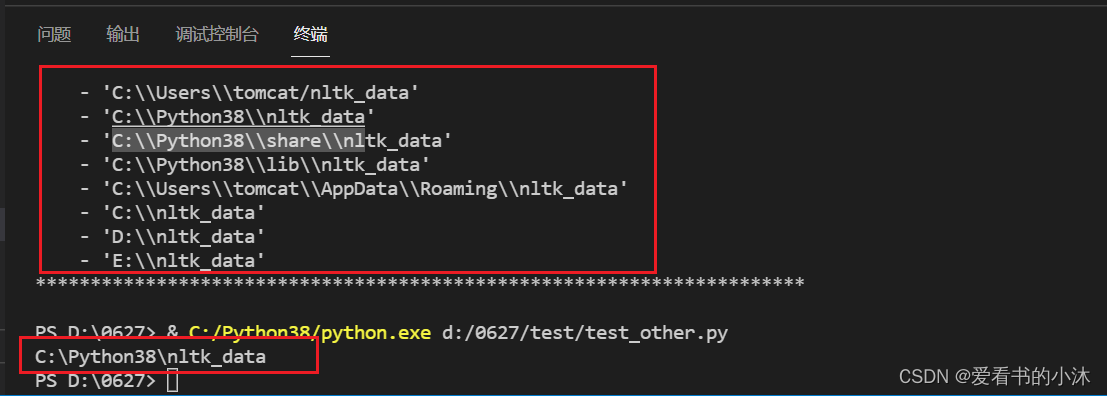
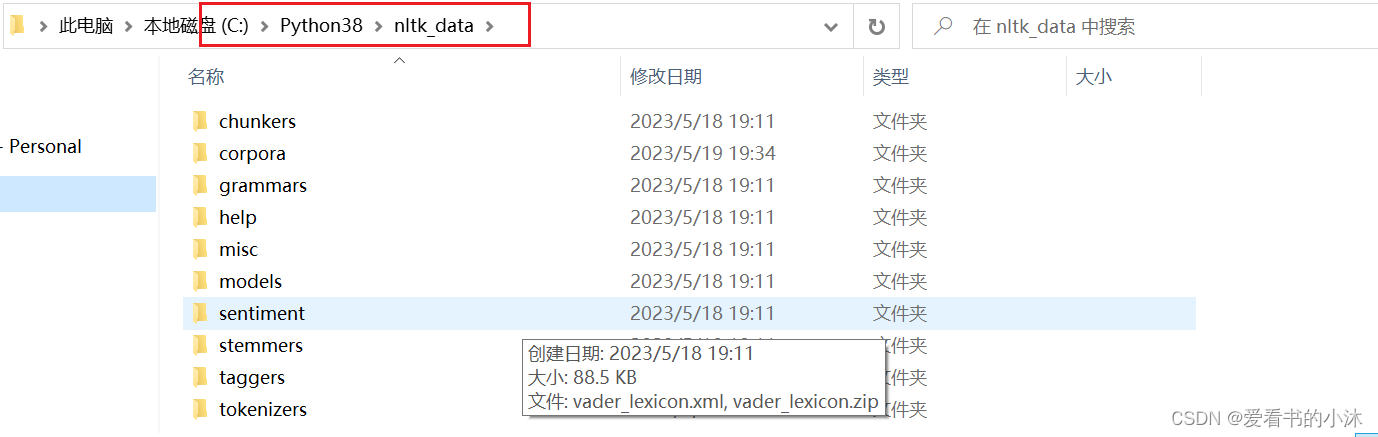
将下载的packages文件夹改名为nltk_data,放在如下文件夹:
-
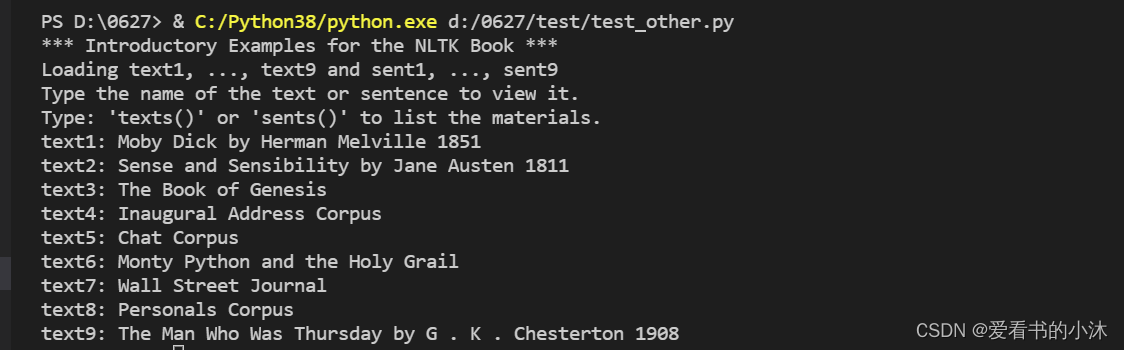
验证是否安装成功
from nltk.book import *
- 分词测试
import nltk
ret = nltk.word_tokenize("A pivot is the pin or the central point on which something balances or turns")
print(ret)

- wordnet词库测试
WordNet是一个在20世纪80年代由Princeton大学的著名认知心理学家George Miller团队构建的一个大型的英文词汇数据库。名词、动词、形容词和副词以同义词集合(synsets)的形式存储在这个数据库中。
import nltk
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
from nltk.corpus import brown
print(brown.words())

3、测试
3.1 分句分词
英文分句:nltk.sent_tokenize :对文本按照句子进行分割
英文分词:nltk.word_tokenize:将句子按照单词进行分隔,返回一个列表
from nltk.tokenize import sent_tokenize, word_tokenize
EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."
print(sent_tokenize(EXAMPLE_TEXT))
print(word_tokenize(EXAMPLE_TEXT))
from nltk.corpus import stopwords
stop_word = set(stopwords.words('english')) # 获取所有的英文停止词
word_tokens = word_tokenize(EXAMPLE_TEXT) # 获取所有分词词语
filtered_sentence = [w for w in word_tokens if not w in stop_word] #获取案例文本中的非停止词
print(filtered_sentence)

3.2 停用词过滤
停止词:nltk.corpus的 stopwords:查看英文中的停止词表。
定义了一个过滤英文停用词的函数,将文本中的词汇归一化处理为小写并提取。从停用词语料库中提取出英语停用词,将文本进行区分。
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
from nltk.corpus import stopwords #导入停止词模块
def remove_stopwords(text):
text_lower=[w.lower() for w in text if w.isalpha()]
stopword_set =set(stopwords.words('english'))
result = [w for w in text_lower if w not in stopword_set]
return result
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
print(remove_stopwords(word_tokens))

from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
from nltk.corpus import stopwords
test_words = [word.lower() for word in word_tokens]
test_words_set = set(test_words)
test_words_set.intersection(set(stopwords.words('english')))
filtered = [w for w in test_words_set if(w not in stopwords.words('english'))]
print(filtered)
3.3 词干提取
词干提取:是去除词缀得到词根的过程,例如:fishing、fished,为同一个词干 fish。Nltk,提供PorterStemmer进行词干提取。
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize,word_tokenize
ps = PorterStemmer()
example_words = ['python','pythoner','pythoning']
print(example_words)
for w in example_words:
print(ps.stem(w),end=' ')

3.4 词形/词干还原
与词干提取类似,词干提取包含被创造出的不存在的词汇,而词形还原的是实际的词汇。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print('cats\t',lemmatizer.lemmatize('cats'))
print('better\t',lemmatizer.lemmatize('better',pos='a'))

3.5 同义词与反义词
nltk提供了WordNet进行定义同义词、反义词等词汇数据库的集合。
- 同义词
from nltk.corpus import wordnet
# 单词boy寻找同义词
syns = wordnet.synsets('girl')
print(syns[0].name())
# 只是单词
print(syns[0].lemmas()[0].name())
# 第一个同义词的定义
print(syns[0].definition())
# 单词boy的使用示例
print(syns[0].examples())

- 近义词与反义词
from nltk.corpus import wordnet
synonyms = [] # 定义近义词存储空间
antonyms = [] # 定义反义词存储空间
for syn in wordnet.synsets('bad'):
for i in syn.lemmas():
synonyms.append(i.name())
if i.antonyms():
antonyms.append(i.antonyms()[0].name())
print(set(synonyms))
print(set(antonyms))

3.6 语义相关性
wordnet的wup_similarity() 方法用于语义相关性。
from nltk.corpus import wordnet
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('boat.n.01')
print(w1.wup_similarity(w2))
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('car.n.01')
print(w1.wup_similarity(w2))
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('cat.n.01')
print(w1.wup_similarity(w2))

3.7 词性标注
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
from nltk import pos_tag
tags = pos_tag(word_tokens)
print(tags)

- 标注释义如下
| POS Tag |指代 |
| --- | --- |
| CC | 并列连词 |
| CD | 基数词 |
| DT | 限定符|
| EX | 存在词|
| FW |外来词 |
| IN | 介词或从属连词|
| JJ | 形容词 |
| JJR | 比较级的形容词 |
| JJS | 最高级的形容词 |
| LS | 列表项标记 |
| MD | 情态动词 |
| NN |名词单数|
| NNS | 名词复数 |
| NNP |专有名词|
| PDT | 前置限定词 |
| POS | 所有格结尾|
| PRP | 人称代词 |
| PRP$ | 所有格代词 |
| RB |副词 |
| RBR | 副词比较级 |
| RBS | 副词最高级 |
| RP | 小品词 |
| UH | 感叹词 |
| VB |动词原型 |
| VBD | 动词过去式 |
| VBG |动名词或现在分词 |
| VBN |动词过去分词|
| VBP |非第三人称单数的现在时|
| VBZ | 第三人称单数的现在时 |
| WDT |以wh开头的限定词 |
3.8 Text对象
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
word_tokens = [word.lower() for word in word_tokens]
from nltk.text import Text
t = Text(word_tokens)
print(t.count('and') )
print(t.index('and') )
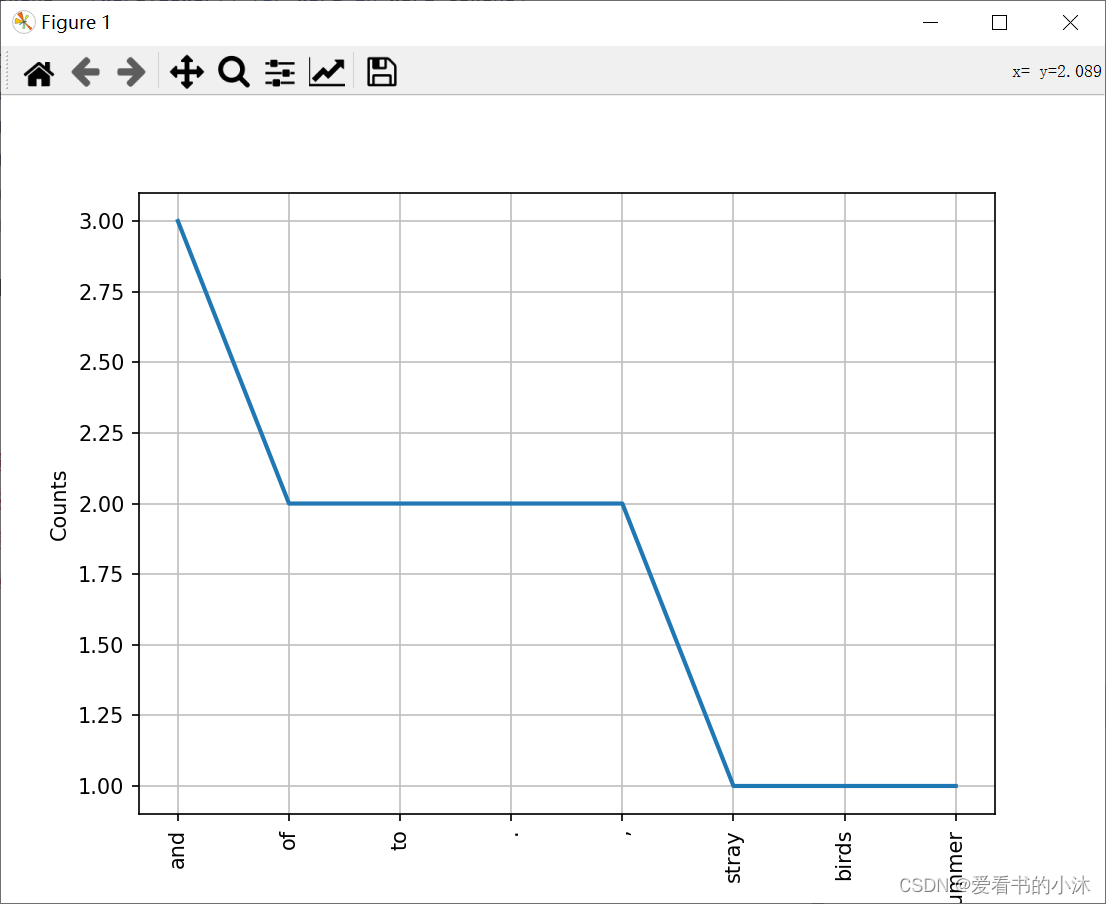
t.plot(8)
除了NLTK,这几年spaCy的应用也非常广泛,功能与nltk类似,但是功能更强,更新也快,语言处理上也具有很大的优势。
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!