前言:
- 本期,我们将要讲解的是有关python中函数的相关知识!!!
目录
(一)函数是什么
(二)语法格式
(三)函数参数
(四)函数返回值
(五)变量作用域
(六)函数执行过程
(七)链式调用
(八)嵌套调用
(九)函数递归
(十)参数默认值
(十一)关键字参数
总结
(一)函数是什么
编程中的函数和数学中的函数有一定的相似之处
数学上的函数, 比如 y = sin x , x 取不同的值, y 就会得到不同的结果.
- 编程中的函数, 是一段 可以被重复使用的代码片段 .
接下来,我以几个简单的代码为例带大家认识函数:
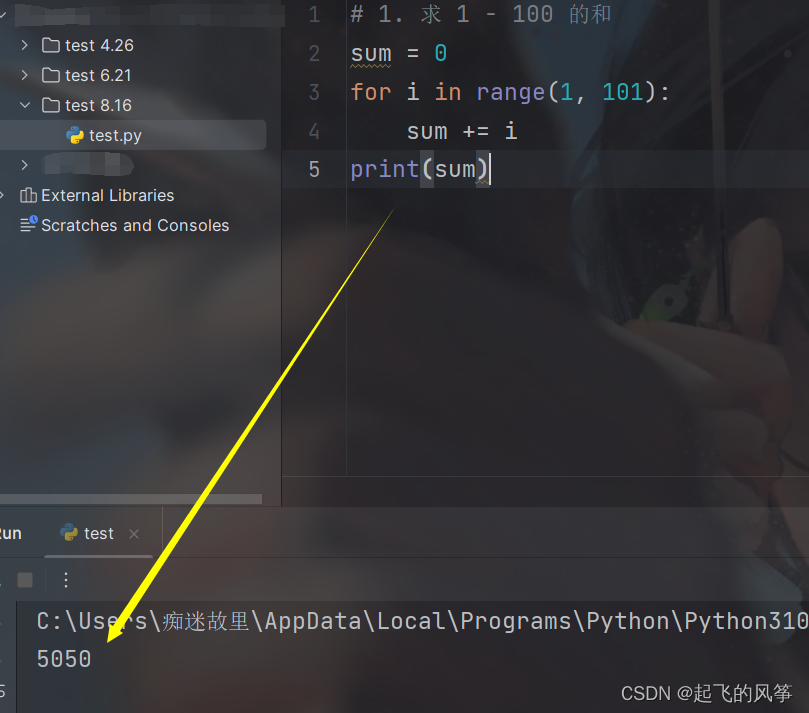
- ① 求 1 - 100 的和
- ② 2. 求 300 - 400 的和
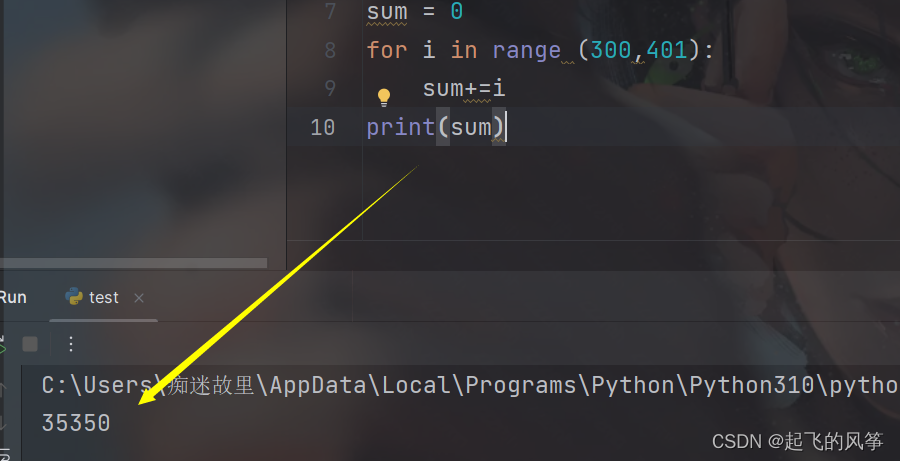
③ 求 1 - 1000 的和
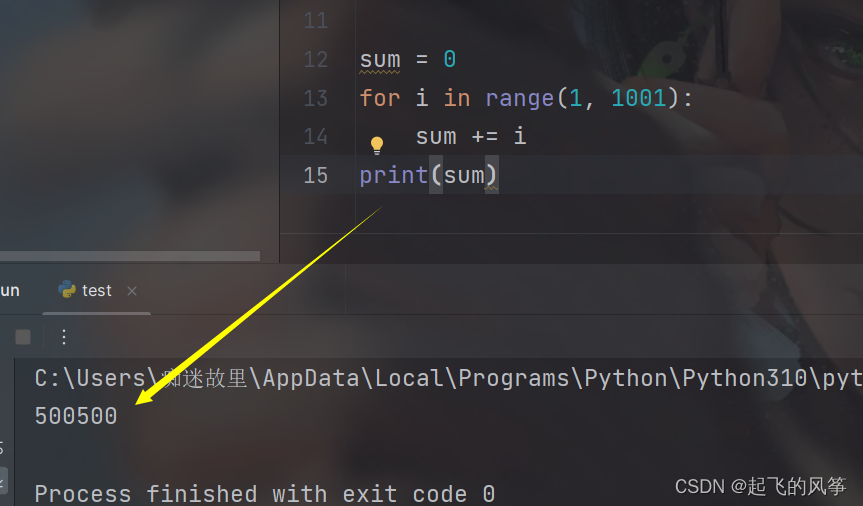
可以发现, 这几组代码基本是相似的, 只有一点点差异. 可以把重复代码提取出来, 做成一个函数
实际开发中, 复制粘贴是一种不太好的策略. 实际开发的重复代码可能存在几十份甚至上百份.
一旦这个重复代码需要被修改, 那就得改几十次, 非常不便于维护
💨 代码示例: 求 数列 的和, 使用函数
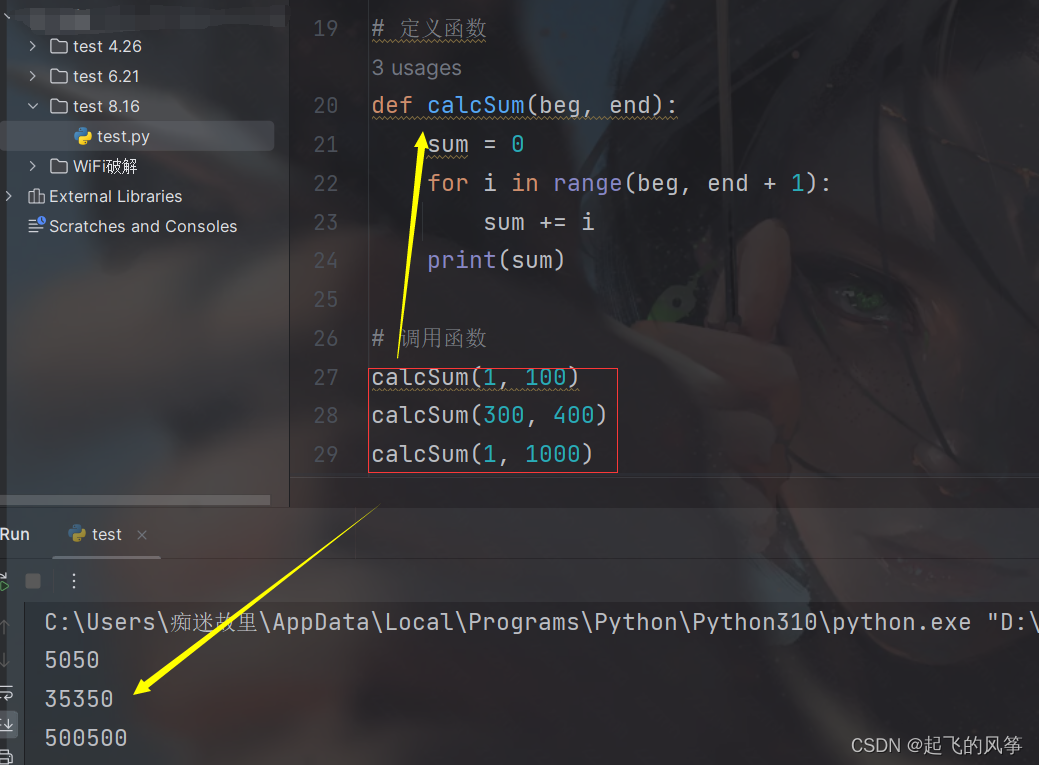
【说明】
- 在给出的代码中,有一个函数定义
calcSum(beg, end),该函数计算从beg到end范围内所有整数的总和,并将结果打印出来; - 可以明显看到, 重复的代码已经被消除了
(二)语法格式
函数是用于封装可重用代码块的基本编程概念。在Python中,函数可以接收输入参数并返回一个或多个值。函数的定义使用 def 关键字,后跟函数名、参数列表和冒号,然后是函数体。
- 创建函数/定义函数
def 函数名(形参列表):
函数体
return 返回值
- 调用函数/使用函数
函数名(实参列表)
返回值 = 函数名(实参列表)// 不考虑返回值
// 考虑返回值
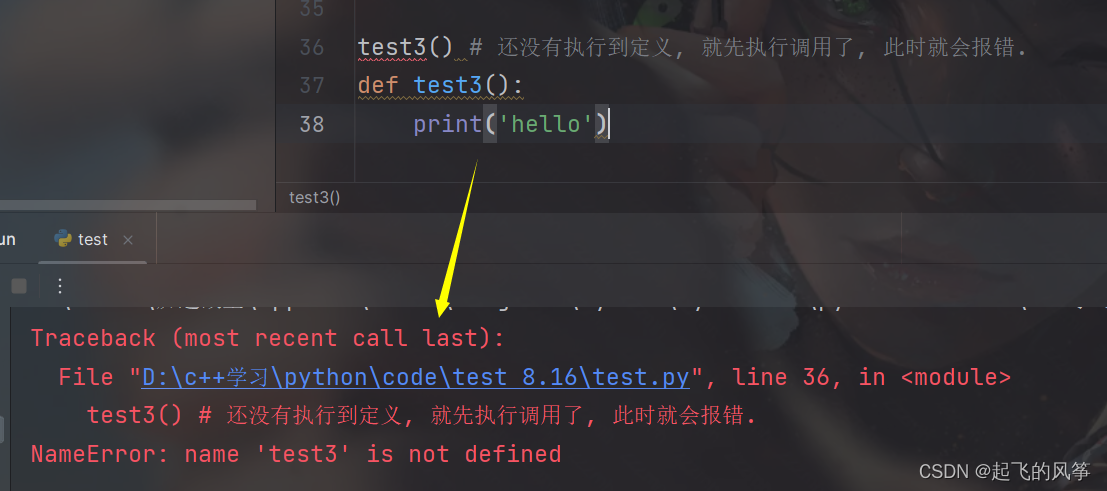
- 函数定义并不会执行函数体内容, 必须要调用才会执行. 调用几次就会执行几次

- 函数必须先定义, 再使用
(三)函数参数
在函数定义的时候, 可以在 ( ) 中指定 "形式参数" (简称 形参), 然后在调用的时候, 由调用者把 "实际参数"(简称 实参) 传递进去.
这样就可以做到一份函数, 针对不同的数据进行计算处理.
考虑前面的代码案例:
def calcSum(beg, end):
sum = 0
for i in range(beg, end + 1):
sum += i
print(sum)
# 调用函数
calcSum(1, 100)
calcSum(300, 400)
calcSum(1, 1000)【说明】
- 上面的代码中, beg, end 就是函数的形参. 1, 100 / 300, 400 就是函数的实参;
- 在执行 sum(1, 100) 的时候, 就相当于 beg = 1, end = 100 , 然后在函数内部就可以针对 1-100 进行运算.
- 在执行 sum(300, 400) 的时候, 就相当于 beg = 300, end = 400 , 然后在函数内部就可以针对300-400 进行运算.
实参和形参之间的关系, 就像签合同一样.

甲方, 乙方 这就相当于形参.张三, 李四 就是实参
def 签合同(甲方, 乙方):
合同内容....
签合同('张三', '李四')
签合同('张三', '王五')
签合同('张三', '赵六')注意:
- 一个函数可以有一个形参, 也可以有多个形参, 也可以没有形参.
- 一个函数的形参有几个, 那么传递实参的时候也得传几个. 保证个数要匹配.
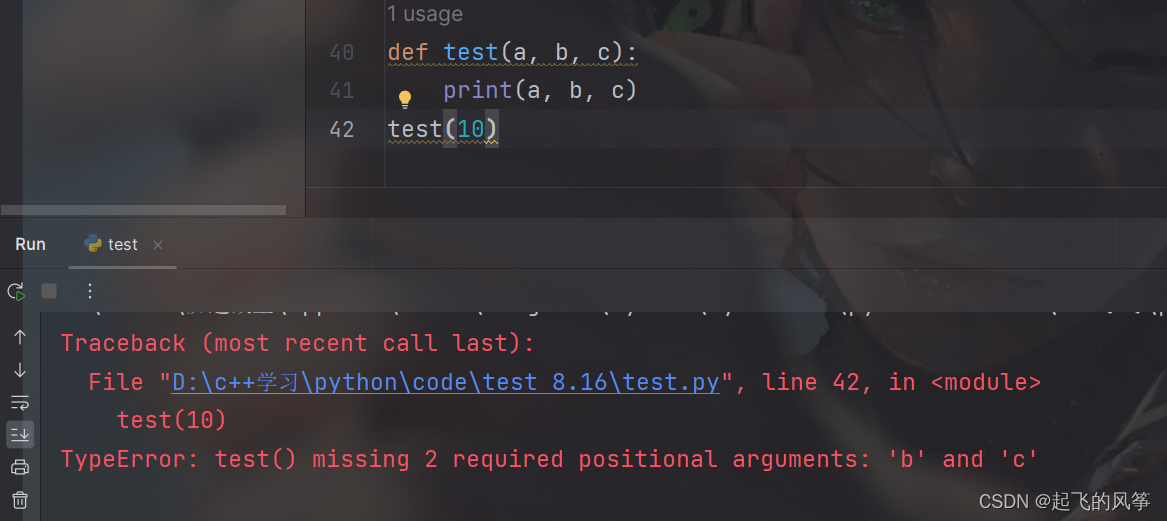
- 和 C++ / Java 不同, Python 是动态类型的编程语言, 函数的形参不必指定参数类型. 换句话说, 一个函数可以支持多种不同类型的参数
(四)函数返回值
函数的参数可以视为是函数的 " 输入 ", 则函数的返回值 , 就可以视为是函数的 " 输出 " .
- 此处的 "输入", "输出" 是更广义的输入输出, 不是单纯指通过控制台输入输出.
- 我们可以把函数想象成一个 "工厂". 工厂需要买入原材料, 进行加工, 并生产出产品.
- 函数的参数就是原材料, 函数的返回值就是生产出的产品.
def calcSum(begin ,end):
sum = 0
for i in range (begin ,end+1):
sum += i
print(sum)
calcSum(1,100)【解释说嘛】
- 这段代码是一个计算从begin到end之间所有整数的和的函数。它使用一个for循环来遍历从begin到end之间的整数,并将它们累加到变量sum中。最后,通过print函数打印出累加结果。
- 在这个例子中,调用
calcSum(1, 100)会计算从1到100的所有整数的和,并将结果打印出来。
上述代码可以转换成 下述这样:
def calcSum(begin ,end):
sum = 0
for i in range (begin ,end+1):
sum += i
return sum
result = calcSum(1,100)
print(result)【解释说明】
这两个代码的区别就在于 , 前者直接在函数内部进行了打印, 后者则使用 return 语句把结果返回给函数调用者, 再由调用者负责打印 .
- 我们一般倾向于第二种写法.
- 实际开发中我们的一个通常的编程原则, 是 "逻辑和用户交互分离". 而第一种写法的函数中, 既包含 了计算逻辑, 又包含了和用户交互(打印到控制台上). 这种写法是不太好的, 如果后续我们需要的是把计算结果保存到文件中, 或者通过网络发送, 或者展示到图形化界面里, 那么第一种写法的函数,就难以胜任了.
- 而第二种写法则专注于做计算逻辑, 不负责和用户交互. 那么就很容易把这个逻辑搭配不同的用户交互代码, 来实现不同的效果.
接下来,我在举几个例子带大家去瞧瞧:
- 一个函数中可以有多个 return 语句:
# 判定是否是奇数
def isOdd(num):
if num % 2 ==0:
return False
else:
return True
result = isOdd(10)
print(result)- 执行到 return 语句, 函数就会立即执行结束, 回到调用位置:
# 判定是否是奇数
def isOdd(num):
if num % 2 ==0:
return False
return True
result = isOdd(19)
print(result)【解释说明】
- 如果 num 是偶数, 则进入 if 之后, 就会触发 return False , 也就不会继续执行 return True
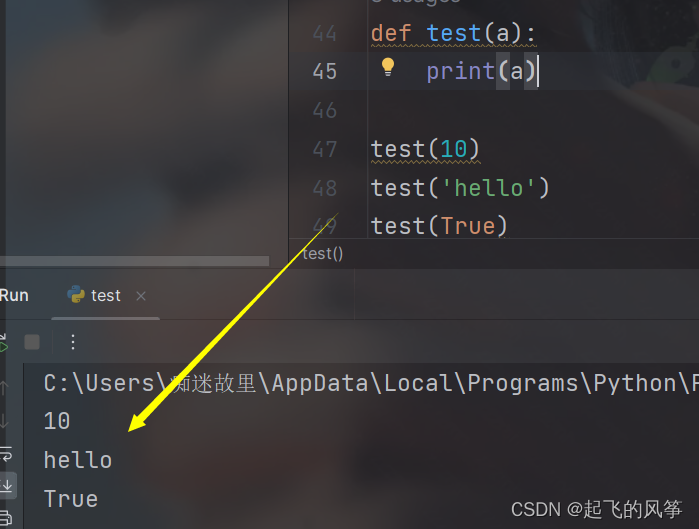
- 一个函数是可以一次返回多个返回值的. 使用 , 来分割多个返回值:
def getpoint():
x=10
y=20
return x, y
a ,b = getpoint()- 如果只想关注其中的部分返回值, 可以使用 _ 来忽略不想要的返回值.
def getPoint():
x = 10
y = 20
return x, y
_, b = getPoint()
(五)变量作用域
在Python中,变量的作用域指的是变量在程序中的可见性和访问范围。
Python中有以下几种变量作用域:
-
全局作用域:在函数外部定义的变量拥有全局作用域,可以在整个程序中的任何位置进行访问。这些变量通常被称为全局变量。
-
局部作用域:在函数内部定义的变量拥有局部作用域,只能在函数内部进行访问。这些变量通常被称为局部变量,它们的作用域限定在函数内部。
接下来,通过代码给大家演示一下:
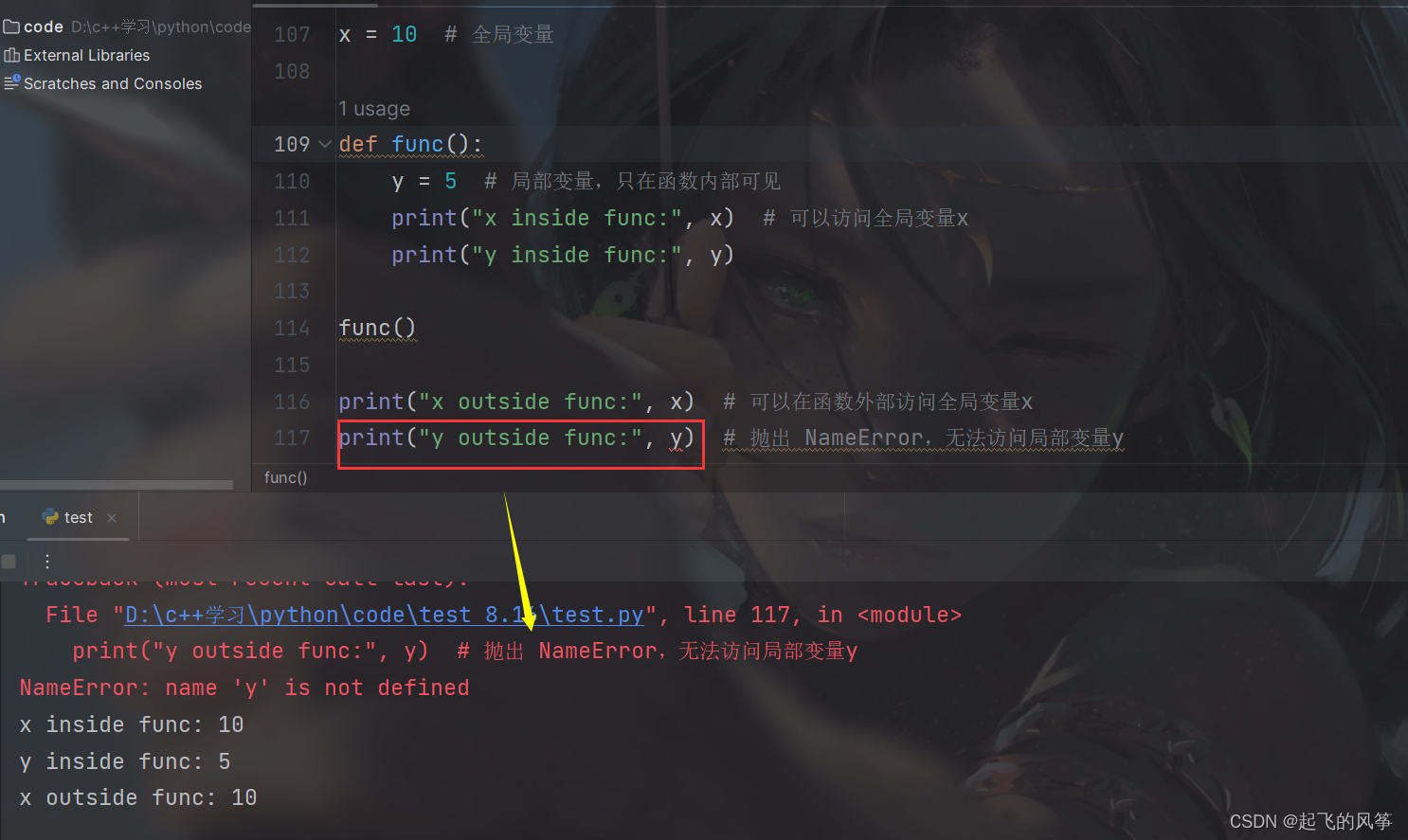
x = 10 # 全局变量
def func():
y = 5 # 局部变量,只在函数内部可见
print("x inside func:", x) # 可以访问全局变量x
print("y inside func:", y)
func()
print("x outside func:", x) # 可以在函数外部访问全局变量x
print("y outside func:", y) # 抛出 NameError,无法访问局部变量y输出展示:
【解释说明】
- 在这个例子中,函数
func()内部定义了一个局部变量y,它只能在函数内部访问。而全局变量x可以在函数内外访问。
-
嵌套作用域:当函数嵌套定义时,内部函数可以访问外部函数的变量,这些被内部函数访问的变量位于嵌套作用域中。
代码展示:
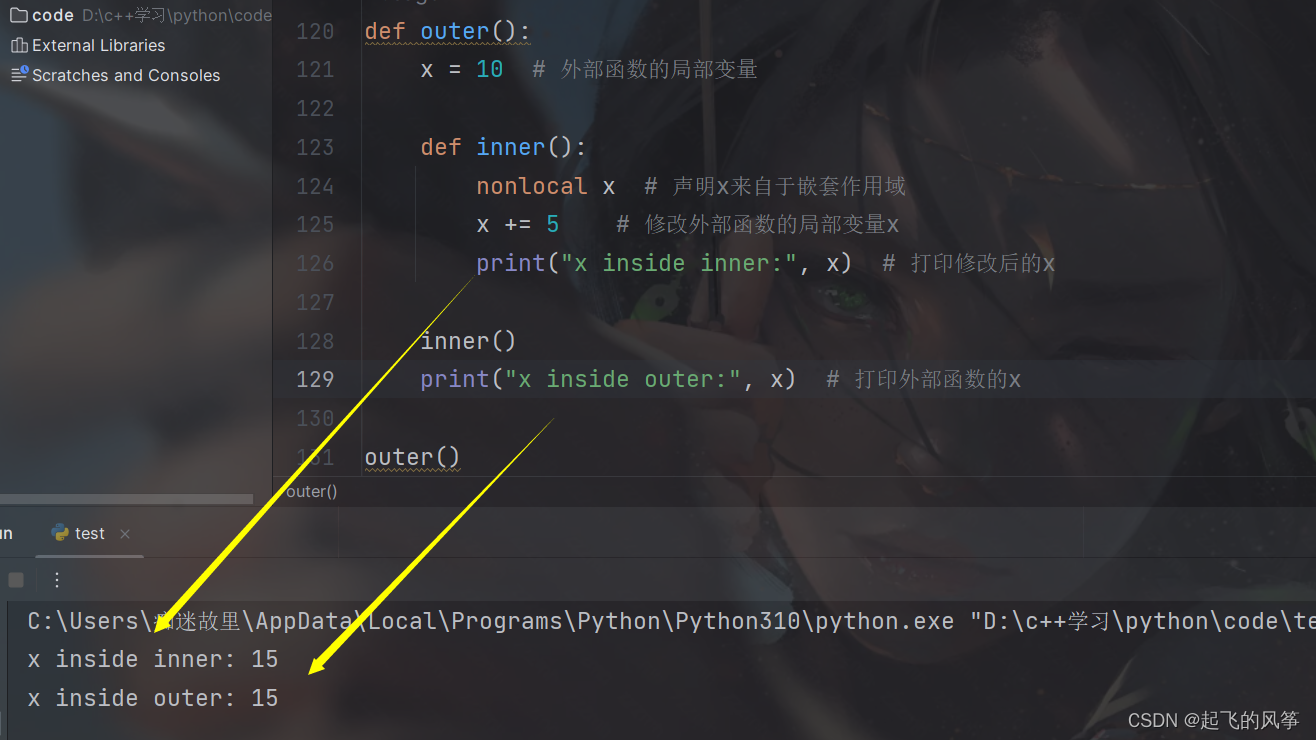
def outer():
x = 10 # 外部函数的局部变量
def inner():
nonlocal x # 声明x来自于嵌套作用域
x += 5 # 修改外部函数的局部变量x
print("x inside inner:", x) # 打印修改后的x
inner()
print("x inside outer:", x) # 打印外部函数的x
outer()输出展示:
【解释说明】
- 在这个例子中,内部函数
inner()可以访问外部函数outer()的局部变量x,通过使用nonlocal关键字可以在内部函数中修改外部函数的局部变量。
-
内置作用域:Python中有一些内置的名称,如
print、len等,它们存在于内置作用域中,可以在任何地方直接访问。
代码展示:
import math
def calculate_circle_area(radius):
area = math.pi * radius ** 2 # 内置函数math.pi处于内置作用域
return area
result = calculate_circle_area(10)
print("Circle area:", result)输出展示:
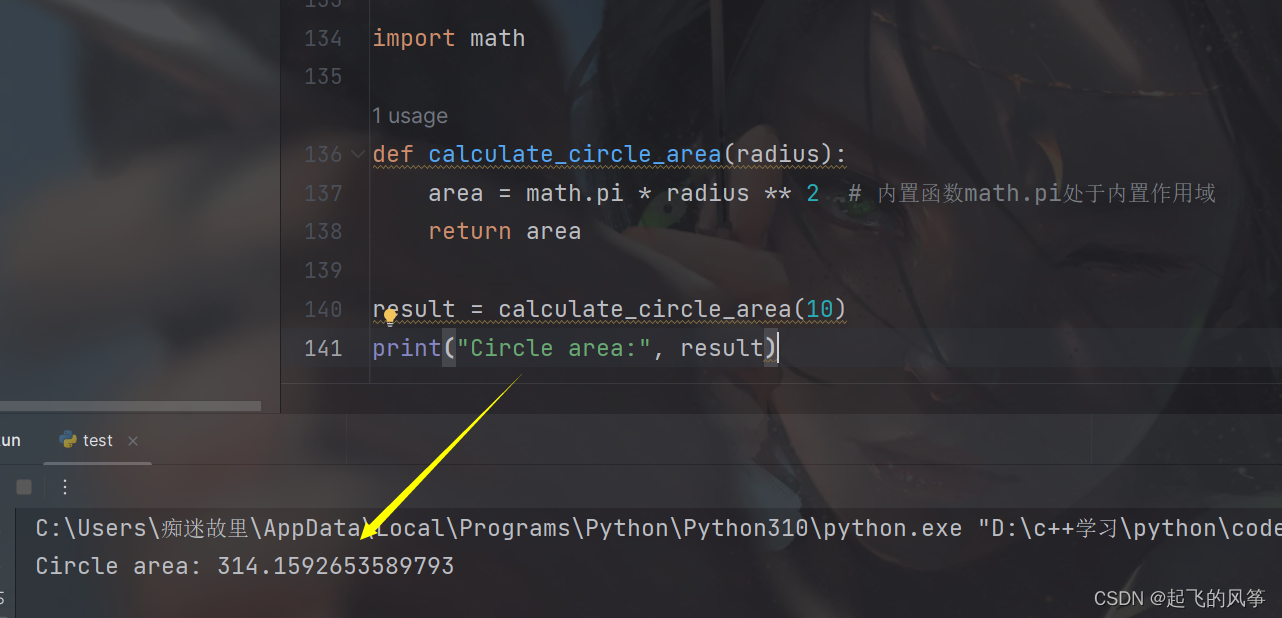
【解释说明】
- 在这个例子中,
math.pi是内置函数math提供的常量,它属于内置作用域,可以在任何地方直接访问和使用。
Python的变量作用域遵循以下规则:
- 当在函数内部访问一个变量时,首先会在局部作用域中查找该变量,如果找到则使用局部作用域中的值:
代码展示:
x = 20
def test():
x = 10
print(f'函数内部 x = {x}')
test()输出展示:
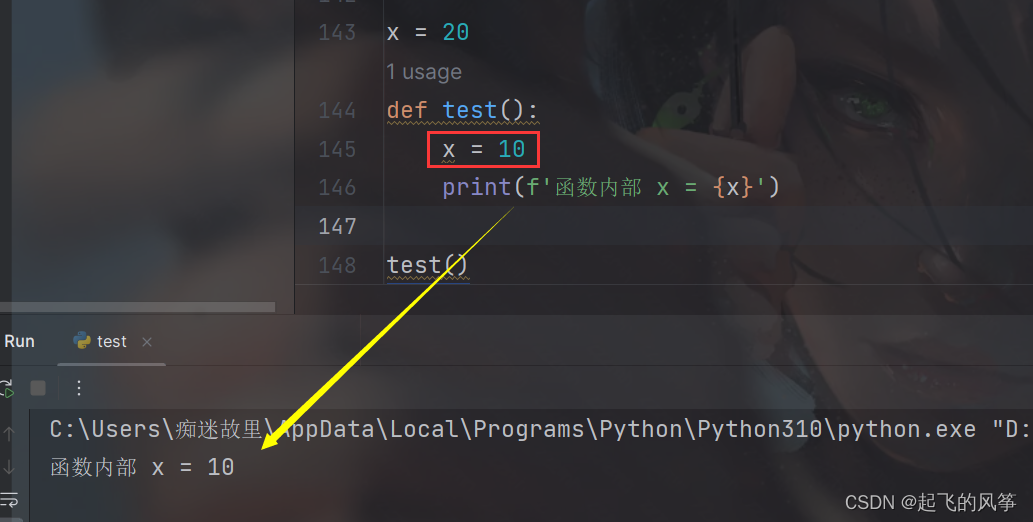
- 如果函数内部尝试访问的变量在局部不存在, 就会尝试去全局作用域中查找
代码展示:
x = 20
def test():
print(f'x = {x}')
test()输出展示:

- 如果需要在函数内部修改全局变量,可以使用
global关键字将变量声明为全局变量。例如:
代码展示:
x = 10 # 全局变量
def modify_global():
global x # 声明x为全局变量
x += 5 # 在函数内部修改全局变量
modify_global()
print(x) 输出展示:
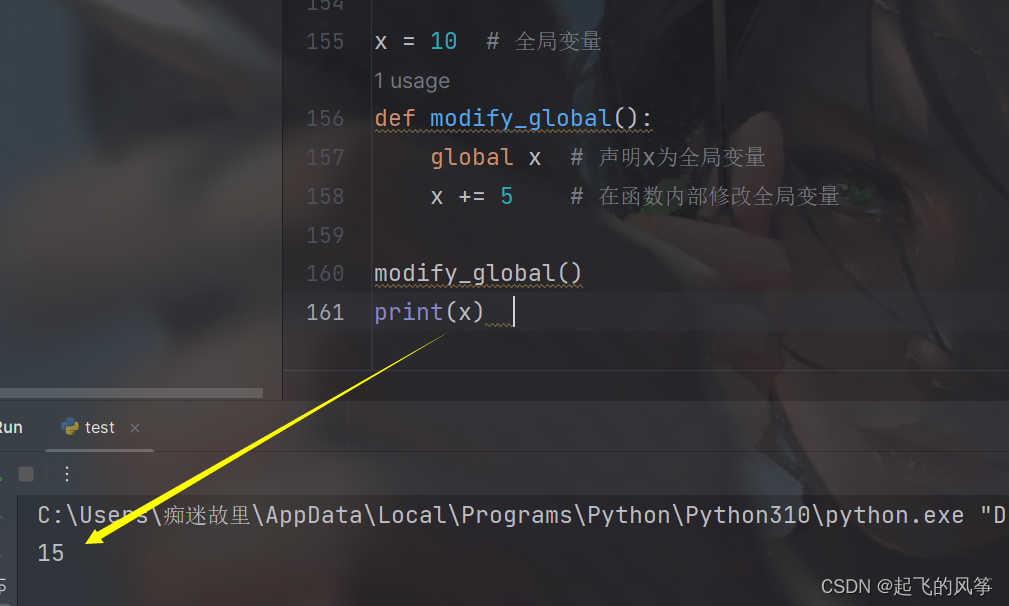
【解释说明】
- 需要注意的是,在函数内部修改全局变量可能会导致代码逻辑复杂化,建议谨慎使用全局变量,尽可能使用参数传递和返回值来实现数据的传递。
- if / while / for 等语句块不会影响到变量作用域
for i in range(1, 10):
print(f'函数内部 i = {i}')
print(f'函数外部 i = {i}')输出展示:
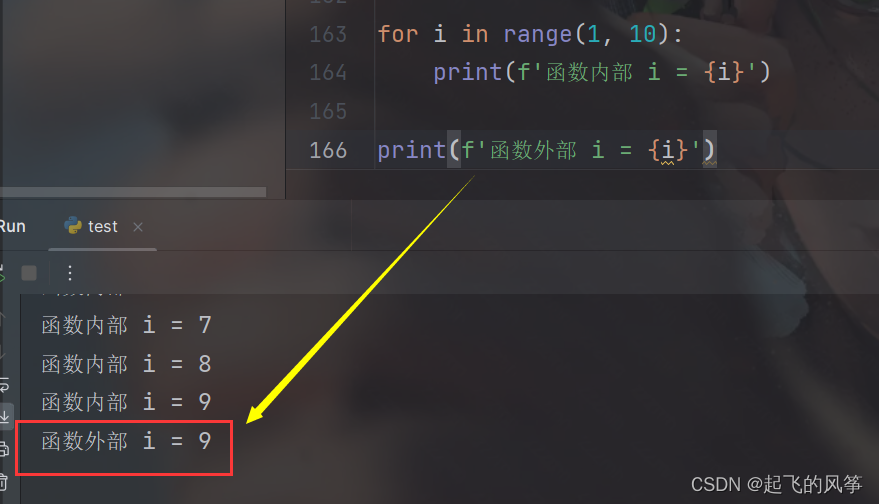
【解释说明】
- 需要注意的是,在 Python 中,循环变量
i在循环结束后仍然存在并保留其最后一次迭代的值; - 因此,在打印 "函数外部 i" 的第二个输出中,
i的值将是循环结束时的最后一个值,即 9。
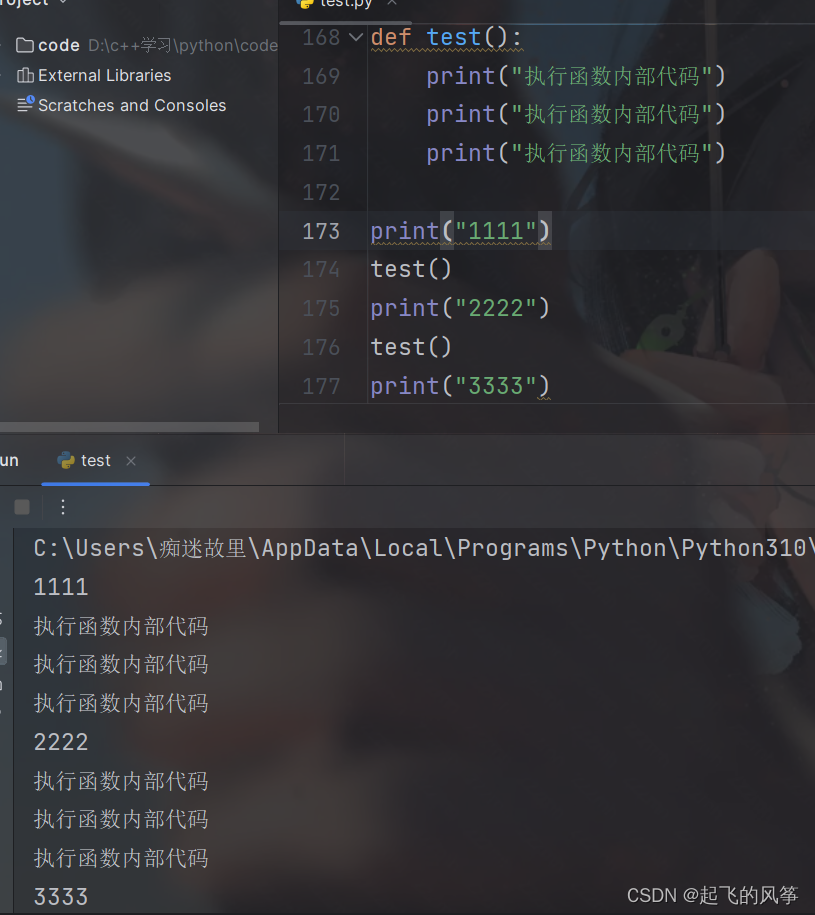
(六)函数执行过程
def test():
print("执行函数内部代码")
print("执行函数内部代码")
print("执行函数内部代码")
print("1111")
test()
print("2222")
test()
print("3333")输出展示:
- 点击行号右侧的空白, 可以在代码中插入 断点
- 右键, Debug, 可以按照调试模式执行代码. 每次执行到断点, 程序都会暂停下来.
- 使用 Step Into (F7) 功能可以逐行执行代码.
(七)链式调用
我们以上述判断奇偶数的代码为例:
- 上述代码时这样写的
# 判定是否是奇数
def isOdd(num):
if num % 2 == 0:
return False
else:
return True
result = isOdd(10)
print(result)- 实际上也可以简化写作
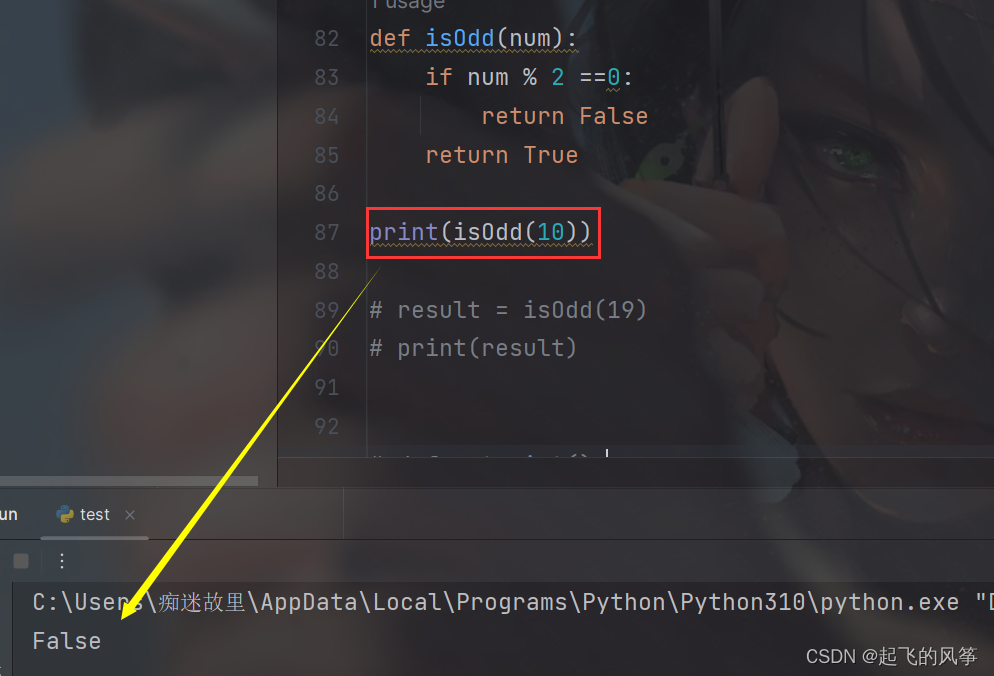
- 通过链式调用,我们可以在一行代码中依次执行多个操作,使代码更简洁、易读;
- 但需要注意的是,链式调用并不适用于所有情况,有时候将每个方法的返回值存储到变量中可能更加清晰明了。
(八)嵌套调用
def test():
print("执行函数内部代码")
print("执行函数内部代码")
print("执行函数内部代码")- test 函数内部调用了 print 函数, 这里就属于嵌套调用
💨 一个函数里面可以嵌套调用任意多个函数
函数嵌套的过程是非常灵活的。我们可以看以下代码示例:
def a():
print("函数 a")
def b():
print("函数 b")
a()
def c():
print("函数 c")
b()
def d():
print("函数 d")
c()
d()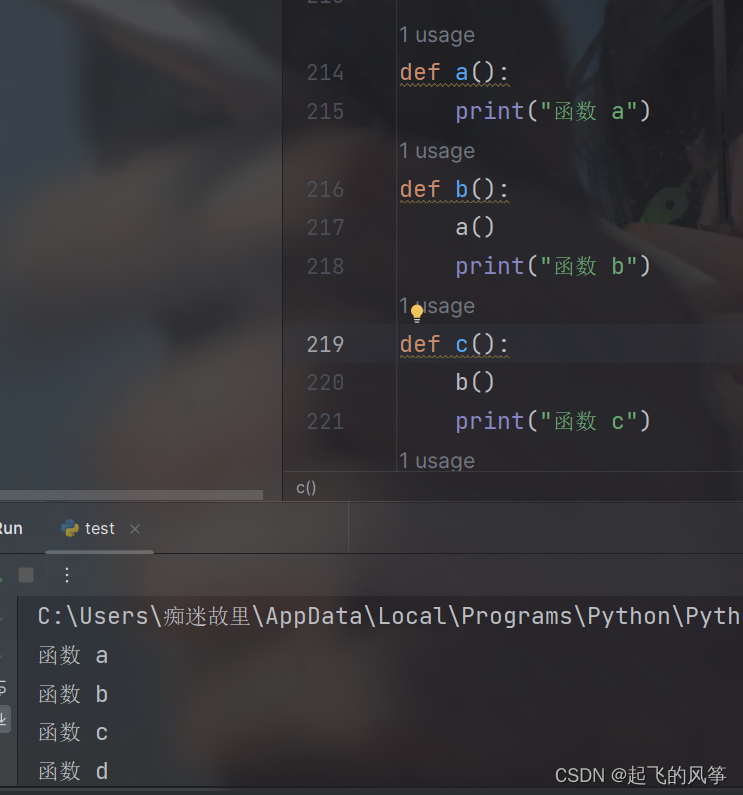
- 注意体会上述代码的执行顺序. 可以通过画图的方式来理解.
- 可以通过 PyCharm 调试器看到函数调用栈和栈帧.
- 在调试状态下, PyCharm 左下角一般就会显示出函数调用栈.
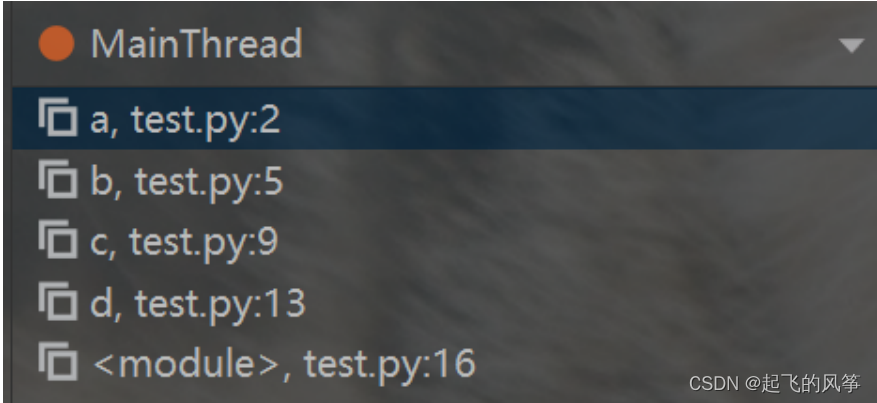
def a():
num1 = 10
print("函数 a")
def b():
num2 = 20
a()
print("函数 b")
def c():
num3 = 30
b()
print("函数 c")
def d():
num4 = 40
c()
print("函数 d")
d()- 选择不同的栈帧, 就可以看到各自栈帧中的局部变量.
(九)函数递归
嵌套调用是指在一个函数或方法的执行过程中,又调用了另一个函数或方法。嵌套调用可以允许我们在一个函数内部调用另一个函数来实现更复杂的功能。
下面是一个简单的示例来说明嵌套调用的概念:
def Func(n):
if n <= 0:
print("Countdown complete!")
else:
print(n)
Func(n - 1) # 在函数内部调用自身
Func(5)- 上述代码中, 就属于典型的递归操作. 在Func函数内部, 又调用了Func自身。
- 存在递归结束条件. 比如 if n <= 0 就是结束条件. 当 n 为 0 的时候, 递归就结束了.
- 每次递归的时候, 要保证函数的实参是逐渐逼近结束条件的
def Func(n):
print(n)
Func(n - 1) # 在函数内部调用自身
Func(5)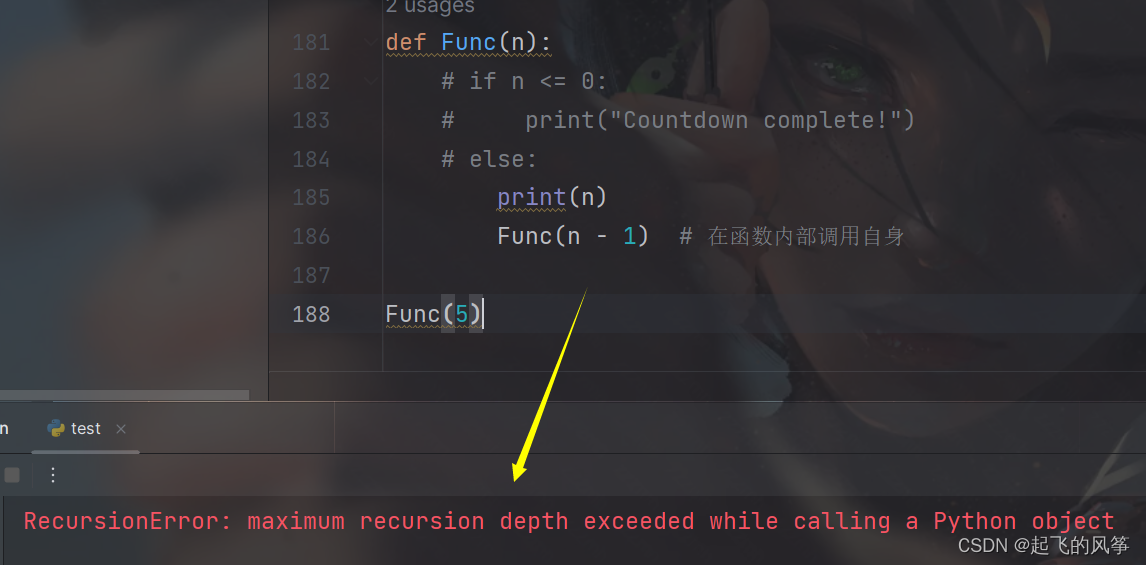
- 如前面所描述, 函数调用时会在函数调用栈中记录每一层函数调用的信息.
- 但是函数调用栈的空间不是无限大的. 如果调用层数太多, 就会超出栈的最大范围, 导致出现问题.
- 递归类似于 "数学归纳法" , 明确初始条件, 和递推公式, 就可以解决一系列的问题.
- 递归代码往往代码量非常少.
- 递归代码往往难以理解, 很容易超出掌控范围
- 递归代码容易出现栈溢出的情况
- 递归代码往往可以转换成等价的循环代码. 并且通常来说循环版本的代码执行效率要略高于递归版本
【小结】
- 函数递归在解决特定问题时可以提供简洁的解决方案,但需要小心使用,确保递归停止条件的正确性和递归调用的终止条件。
(十)参数默认值
参数默认值是指在定义函数时为函数参数设置的默认值。当调用函数时,如果没有为相应的参数提供值,那么该参数将使用默认值作为其值。参数默认值可以使函数在不同场景中更加灵活和易用。
以下是一个示例来说明参数默认值的使用:
def add(x, y, debug=False):
if debug:
print(f'调试信息: x={x}, y={y}')
return x + y
print(add(10, 20))
print(add(10, 20, True))输出展示:
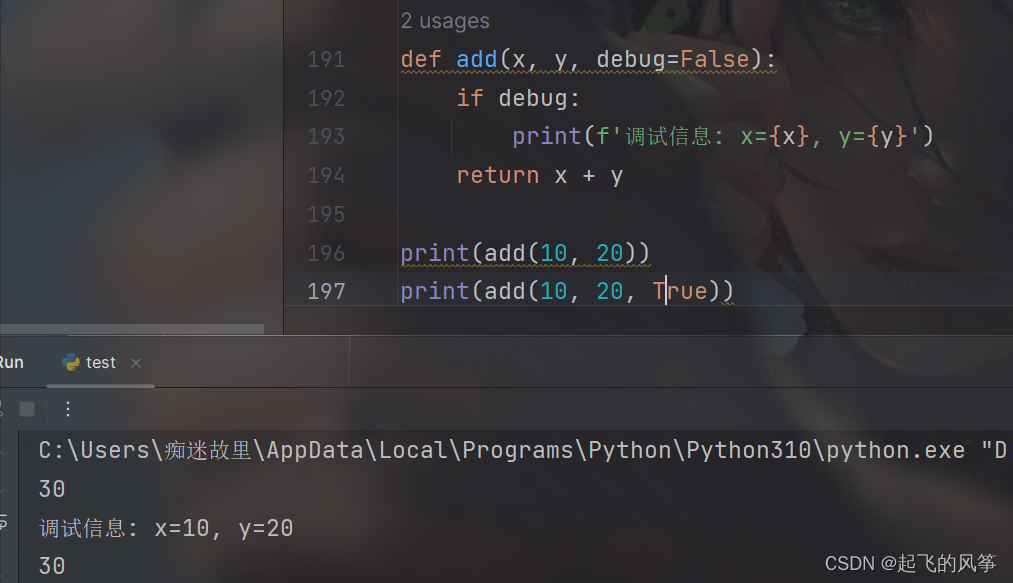
【解释说明】
- 此处 debug=False 即为参数默认值. 当我们不指定第三个参数的时候, 默认 debug 的取值即为 False.
- 带有默认值的参数需要放到没有默认值的参数的后面:
代码展示:
def add(x, debug=False, y):
if debug:
print(f'调试信息: x={x}, y={y}')
return x + y
print(add(10, 20))输出展示:
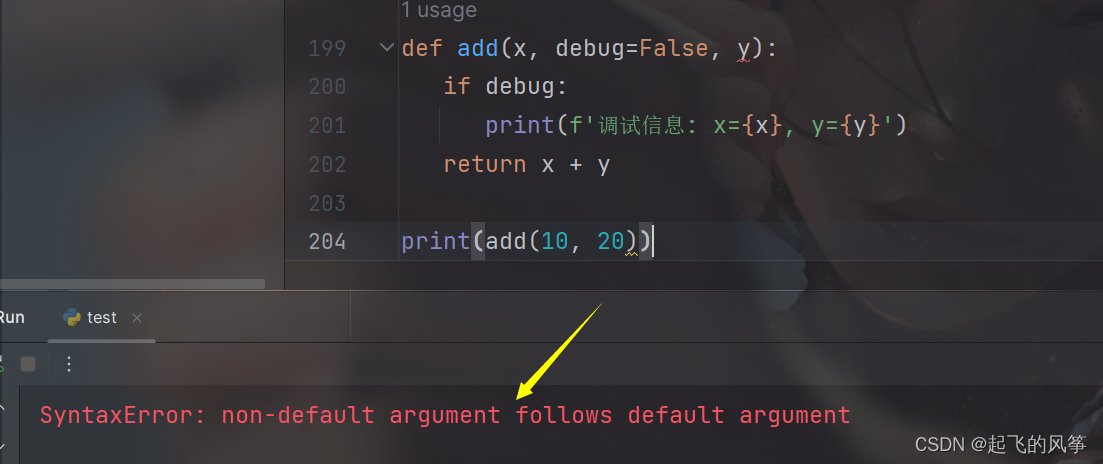
(十一)关键字参数
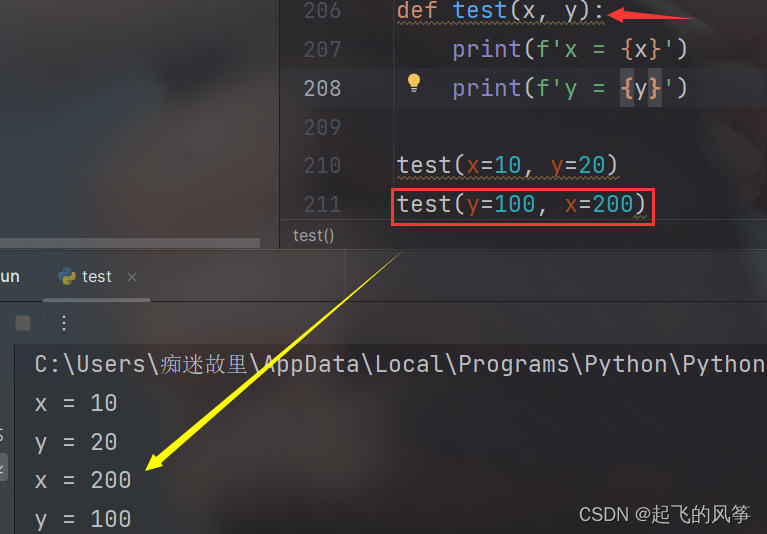
【解释说明】
- 形如上述 test(x=10, y=20) 这样的操作, 即为 关键字参数;
- 关键字参数允许我们在函数调用时不需要按照参数的位置顺序进行传递,而是使用参数名来明确指定每个参数的值;
总结
到此,关于python中函数的讲解便到此结束了。接下来,简单的回顾总结一下!!!
- 函数的定义
- 函数的调用
- 函数的参数传递
以上便是本期的全部内容,感谢大家的观看与支持!!!