目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- node.js前端环境
- MySQL数据库
- 模块实现
- 1. 数据预处理
- 2. 热度值计算
- 3. 相似度计算
- 1)新闻分词处理
- 2)计算相似度
- 4. 新闻统计
- 5. API接口开发
- 6. 前端界面实现
- 1)运行逻辑
- 2)前端界面的数据配置
- 3)前端界面配置
- 系统测试
- 1. 产生用户行为时的推荐
- 2. 用户浏览新闻时的推荐
- 3. 新用户的冷启动推荐
- 4. 新用户自选标签的推荐
- 工程源代码下载
- 其它资料下载

前言
项目基于中文分词库jieba的技术基础上构建,用于提取新闻文章中的关键词,然后根据这些关键词来获取相关的新闻内容。项目还使用了杰卡德相似系数来计算不同新闻文章之间的相似度。当用户浏览某一篇新闻时,系统能够智能地推荐与该新闻相关的其他新闻。
首先,我们使用jieba分词库对新闻文章进行分词处理,将文章拆分成词语,识别其中的关键词。这些关键词代表了文章的主题和重点内容。
接下来,我们根据提取出的关键词来检索其他新闻文章,寻找包含相似关键词的文章。这可以通过计算不同文章之间的杰卡德相似系数来实现,该系数可以度量两个集合的相似程度。
当用户正在浏览某一篇新闻时,系统会根据该新闻的关键词和内容,推荐与之相关的其他新闻。这种推荐系统可以提供更多深入的信息,帮助用户更好地了解相关主题和事件。
总的来说,这个项目基于jieba的分词技术和杰卡德相似系数的计算,实现了一种智能的新闻推荐系统。这对于新闻阅读者来说,可以提供更丰富的新闻体验,帮助他们更全面地了解感兴趣的主题和新闻事件。
总体设计
本部分包括系统整体结构图和系统流程图。
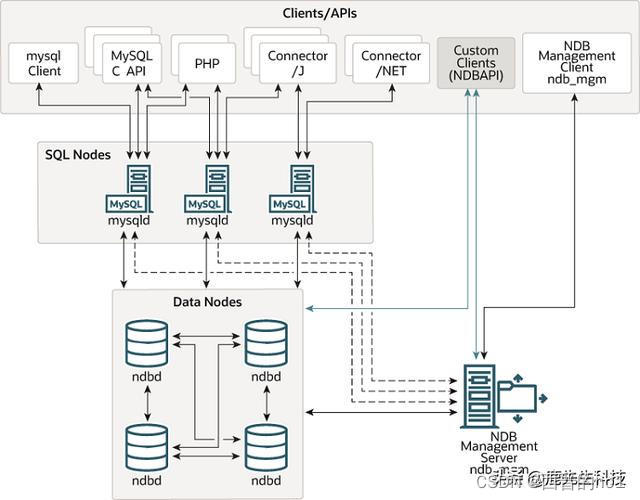
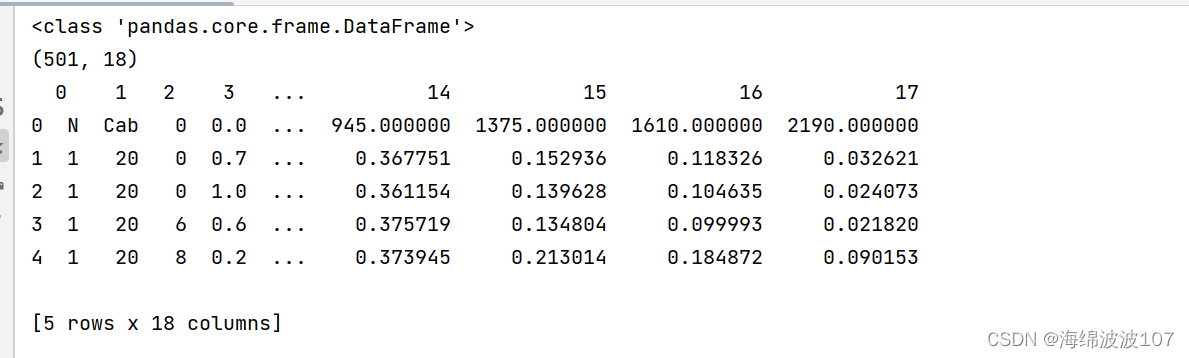
系统整体结构图
系统整体结构如图所示。
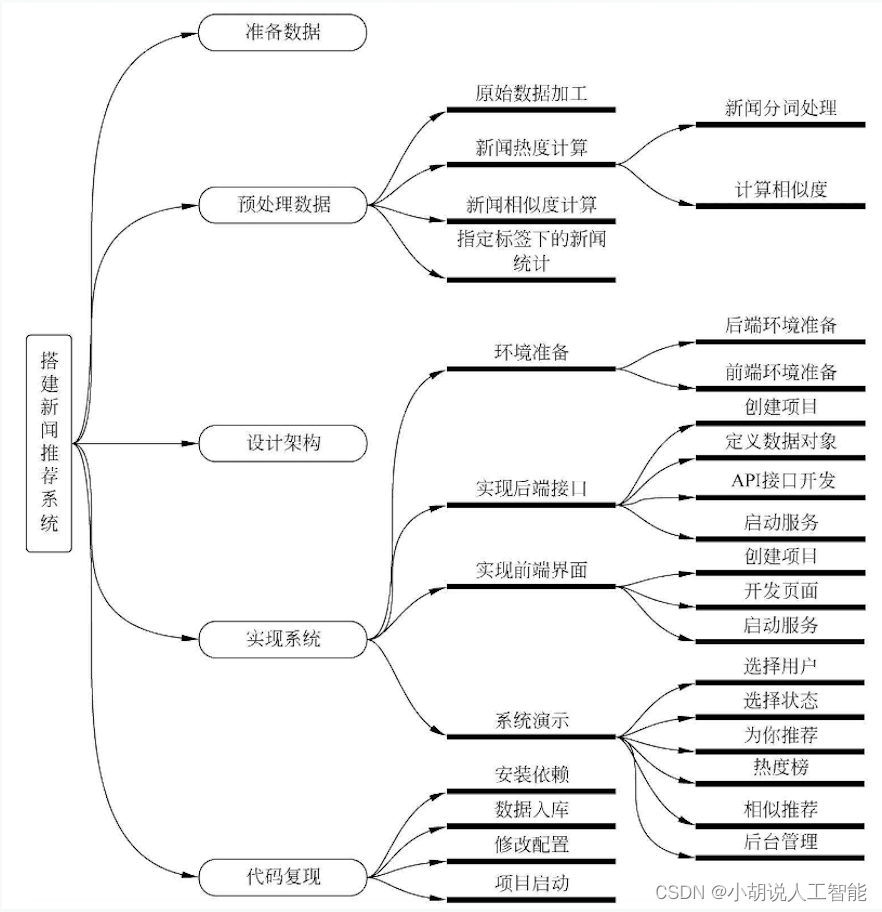
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、node.js前端环境和MySQL数据库。
Python 环境
本项目需要Python 3.6及以上版本,在Windows环境下推荐下载Anaconda完成Python所需的配置,下载地址为https://www.anaconda.com/。其中使用的包为: Django==2.1、PyMySQL==0.9.2、jieba==0.39、xlrd==1.1.0、 gensim==3.6.0。
在命令行窗口输入以下命令并运行,即可下载对应版本的gensim包:
pip install gensim==3.6.0
其他包按类似的方式完成安装。
node.js前端环境
前端开发依赖于node.js环境,使用Vue.js框架,node.js对应的版本是10.13,可在node.js官网选择相应系统和版本进行安装,并依据教程完成Vue框架的搭建。下载地址为https://nodejs.org/en/download/。
安装完成后,对npm的全局模块所在路径以及缓存路径,进行环境配置,并创建两个子文件夹node_cache和node_global。
在命令行窗口输入以下命令并运行(记得将路径改为本地的安装路径) :
npm config set prefix "D:\program files \nodejs\node_global"
npm config set cache "D:\program files\nodejs\node_cache"
单击“我的电脑”→“属性”→“高级系统设置”,进入系统设置界面后,单击“高级”→“环境变量”进入配置界面。
为用户变量path添加node_global文件夹路径。为系统变量添加一个NODE_PATH,将输入node_cache 文件夹的路径。
基于node.js利用npm安装相关依赖,此处建议使用国内的淘宝镜像npm。
安装全局vue-cli脚手架,用于帮助搭建所需要的模板框架,在命令行输入:
cnpm install -g vue-cli
安装完成后命令行窗口输入vue (小写),如命令行窗口显示vue的信息,则表明安装成功,可输入vue-V查看版本。
MySQL数据库
数据存入MySQL数据库,为前端提供内容以及后端的计算提供依据。本项目使用数据库服务器MySQL Community Server (GPL) - 5.6.39,可以前往MySQL选择对应的版本进行下载,官网地址为https://www.mysql.com/downloads/。如node.js中一样,为MySQL配置环境变量,在系统变量中选择path,将MySQL文件下的bin文件路径输入即可。
以管理员身份运行命令行窗口,输入以下命令进入MySQL的bin文件下:
cd D:\program files\MySQL\mysql-5.6.39-winx64\bin
输入以下命令(一定是管理员权限,否则会报错):
mysqld - install
启动服务,输入以下命令:
net start mysql
服务启动成功之后,进入MySQL数据库,输入以下命令(第一次进入无须密码,后续可进行添加密码) :
mysql -u root -P
进入数据库时,无须再输入net start mysql命令,直接在命令行状态进入bin文件夹下,输入mysql -u root -p命令再输入密码即可进入数据库。
模块实现
本项目包括6个模块:数据预处理、热度值计算、相似度计算、新闻统计、API接口开发、前端界面实现,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
数据来自网站的早年新闻,爬取时,源数据仅有新闻题目、正文和发帖时间,为方便计算新闻的热度值,给新闻添加了随机的浏览次数和评论数。
新闻数据的Excel链接https://pan.baidu.com/s/1HRYvHmxIrGT7pmoizRe2cA,提取码: wezi;用SQL语句将处理过的数据导入MySQI数据库。
2. 热度值计算
每个新闻计算一个热度值,为后续的热度榜和为你推荐模块做新闻排序使用。新闻热度、浏览次数和评论次数有着紧密的联系,但是在排除不确定因素下,评论次数提供了更高的权重,同时,随着时间的推移,越旧的新闻热度越下降。热度值=某则新闻被浏览的次数X 0.4+某则新闻被评论的次数X0.5-新闻发布日期和目前日期的时间差(以天为单位) X0.1。
新闻热度值计算对应的函数代码如下:
def calHotValue(self):
base_time = datetime.now()
sql = "select new_id, new_cate_id, new_seenum, new_disnum, new_time from new"
self.cursor.execute(sql)
result_list = self.cursor.fetchall()
result = list()
for row in result_list:
diff=base_time-datetime.strptime(str(row[4].date()),'%Y-%m-%d')
hot_value = row[2] * 0.4 + row[3] * 0.5 - diff.days * 0.1
result.append((row[0],row[1],hot_value))
return result
3. 相似度计算
新闻相似度是本项目进行推荐的基础,使用新闻主题词的重合度考量新闻相似度。
1)新闻分词处理
实现思路:使用Python的jieba分词包对每则新闻的标题做分词处理,选用新闻的标题做分词处理是因为新闻题材的特殊性。看一篇新闻的第一-切入点便 是新闻标题,标题是整篇新闻的高度概括,当两则新闻的标题重合度越高,新闻本身的内容相似度也就越大。
使用Python的xlrd.open_work()函数加载Excel文件。加载原始数据对应的函数实现为:
#加载数据
def loadData(self):
news_dict = dict()
#使用xlrd加载xlsx格式文件,返回一个table对象
table = xlrd.open_workbook(self.file).sheets()[0]
#遍历每一行
for row in range(1,table.nrows):
#将每一列返回为一个数组
line = table.row_values(row, start_colx=0, end_colx=None)
new_id = int(line[0])
news_dict.setdefault(new_id,{})
news_dict[new_id]["tag"]= line[1]
news_dict[new_id]["title"] = line[5]
news_dict[new_id]["content"] = line[-1]
return news_dict
原始数据加载之后保存在变量news_dict中,在文章标题分词时使用,分词使用的是jieba.analyse.extract_tags()函数。句子中的大量单音节词、标点符号等,在分词时要去掉这些词语或标点符号,实现方法是加载停用词表(本项目中的stop_words.txt文件)进行过滤,提取新闻标题的关键词对应的函数实现代码如下:
#调用jieba分词获取每篇文章的关键词
def getKeyWords(self):
news_key_words = list()
#加载停用词表
stop_words_list=[line.strip()for line in open
("./../files/stop_words.txt").readlines()]
for new_id in self.news_dict.keys():
if self._type == 1:
#allowPOS 提取地名、名词、动名词、动词
keywords = jieba.analyse.extract_tags(
self.news_dict[new_id]["title"]
+self.news_dict[new_id]["content"],
topK=10,
withWeight=False,
allowPOS=('ns', 'n', 'vn', 'v')
)
news_key_words.append(str(new_id)+'\t'+",".join(keywords))
elif self._type == 2:
#cut_all :False 表示精确模式
keywords=jieba.cut(self.news_dict[new_id]["title"],cut_all=False)
kws = list()
for kw in keywords:
if kw not in stop_words_list and kw != " " and kw != " ":
kws.append(kw)
news_key_words.append(str(new_id)+'\t'+",".join(kws))
else:
print("请指定获取关键词的方法类型<1:TF-IDF 2:标题分词法>")
return news_key_words
例如,标题《知识就是力量》第一季完美收官爱奇艺打造全民解忧综艺的分词结果为:知识、力量、第一季、完美、收官、爱奇艺、打造、全民、解忧、综艺。
2)计算相似度
新闻相似度的计算采用杰卡德相似系数,其对应函数为:
def getCorrelation(self):
news_cor_list = list()
for newid1 in self.news_tags.keys():
id1_tags = set(self.news_tags[newid1].split(","))
for newid2 in self.news_tags.keys():
id2_tags = set(self.news_tags[newid2].split(","))
if newid1 != newid2:
print( newid1 + "\t" + newid2 + "\t" + str(id1_tags & id2_tags) )
cor = ( len(id1_tags & id2_tags) ) / len (id1_tags | id2_tags)
if cor > 0.0:
news_cor_list.append([newid1,newid2,format(cor,".2f")])
return news_cor_list
4. 新闻统计
统计指定标签下的新闻是为用户选择标签后生成“为你推荐”模块内容做准备,这里指定用户可以选择的标签有:峰会、AI、技术、百度、互联网等。相关代码如下:
#获取每个标签下对应的文章
def getNewsTags(self):
result = dict()
for file in os.listdir(self.kw_path):
path = self.kw_path + file
for line in open(path, encoding= "utf-8").readlines():
try:
newid, tags = line.strip().split("\t")
except:
print("%s 下无对应标签" % newid)
for tag in tags.split(","):
if tag in ALLOW_TAGS:
sql = "select new_hot from newhot where new_id=%s" % newid
self.cursor.execute(sql)
hot_value = self.cursor.fetchone()
result.setdefault(tag,{})
result[tag][newid]=hot_value[0]
return result
#对每个标签下的新闻进行排序,并写入mysql
def writeToMySQL(self):
for tag in self.result.keys():
for newid in self.result[tag].keys():
sql_w = "insert into newtag( new_tag,new_id,new_hot ) values('%s', '%s' ,%s)" % (tag, newid, self.result[tag][newid])
try:
self.cursor.execute(sql_w)
self.db.commit()
except:
print("rollback", tag,newid,self.result[tag][newid])
self.db.rollback()
5. API接口开发
API接口即与前端进行交互的函数,新闻类别表中定义的类别包括为你推荐(cateid=1) 、热度榜(cateid=2)和其他正常类别的新闻数据,当用户进行访问时,调用home()函数,代码中会根据前端传入的cateid参数决定选择哪部分数据处理逻辑,相关代码如下:
def home(request):
#从前端请求中获取cateid
_cate = request.GET.get("cateid")
if "username" not in request.session.keys():
return JsonResponse({ "code":0 })
total = 0 #总页数
#如果cate 是为你推荐,走该部分逻辑tag_flag = 0表示不是从标签召回数据
if _cate == "1":
news, news_hot_value = getRecNews(request)
#如果cate 是热度榜,走该部分逻辑
elif _cate == "2":
news,news_hot_value = getHotNews()
#其他正常的请求获取
else:
_page_id = int(request.GET.get("pageid"))
news = new.objects.filter(new_cate=_cate).order_by("-new_time")
total = news.__len__()
news = news[_page_id * 10:(_page_id+1) * 10]
#数据拼接
result = dict()
result["code"] = 2
result["total"] = total
result["cate_id"] = _cate
result["cate_name"] = str(cate.objects.get(cate_id=_cate))
result["news"] = list()
for one in news:
result["news"].append({
"new_id":one.new_id,
"new_title":str(one.new_title),
"new_time": one.new_time,
"new_cate": one.new_cate.cate_name,
"new_hot_value": news_hot_value[one.new_id] if _cate == "2" or _cate == "1" else 0 ,
"new_content": str(one.new_content[:100])
})
return JsonResponse(result)
如果cateid为1,表示用户请求的是“为你推荐”模块;如果cateid为2,表示用户请求的是‘热度榜模块;如果cateid为3,表示用户请求的是其他新闻所属类别下的数据。
当catied为1时,home ()函数中调用getRecNews ()函数。getRecNews用来处理“为你推荐”的具体逻辑,此时需要判断用户是首次登录还是在系统内产生行为之后再次返回“为你推荐模块,这里使用参数tag_Aag来表示,tag_Aag的值不同表示获取数据的逻辑不同,相关函数如下:
# 热度榜排序逻辑:new_seenum*0.3+new_disnum*0.5+(new_date-base_data)* 0.2
def getHotNews():
# 从新闻热度表中取top 20数据
all_news = newhot.objects.order_by("new_hot").values("new_id", "new_hot")[:20]
all_news_id = [one["new_id"] for one in all_news]
all_news_hot_value = {one["new_id"]: one["new_hot"] for one in all_news}
# 返回热度榜单数据
return new.objects.filter(new_id__in=all_news_id), all_news_hot_value
# 为你推荐的数据获取逻辑
def getRecNews(request):
tags = request.GET.get('tags')
baseclick = request.GET.get("baseclick")
tag_flag = 0 if tags == "" else 1
tags_list = tags.split(",")
uname = request.session["username"]
# 标签召回逻辑
if tag_flag == 1 and int(baseclick) == 0:
num = (20 / len(tags_list)) + 1
news_id_list = list()
news_id_hot_dict = dict()
for tag in tags_list:
result = newtag.objects.filter(new_tag=tag).values("new_id", "new_hot")[:num]
for one in result:
news_id_list.append(one["new_id"])
news_id_hot_dict[one["new_id"]] = one["new_hot"]
return new.objects.filter(new_id__in=news_id_list)[:20], news_id_hot_dict
# 正常排序逻辑
elif tag_flag == 0:
# 首先判断用户是否有浏览记录
# 如果有该用户的浏览记录,则从浏览的新闻获取相似的新闻返回
if newbrowse.objects.filter(user_name=uname).exists():
# 判断用户浏览的新闻是否够10个,如果够每个取两个相似,不够则每个取20/真实个数+1相似
num = 0
browse_dict = newbrowse.objects.filter(user_name=uname).order_by("new_browse_time").values("new_id")[:10]
if browse_dict.__len__() < 10:
num = (20 / browse_dict.__len__()) + 1
else:
num = 2
news_id_list = list()
all_news_hot_value = dict()
# 遍历最近浏览的N篇新闻,每篇新闻取num篇相似新闻
for browse_one in browse_dict:
for one in newsim.objects.filter(new_id_base=browse_one["new_id"]).order_by("-new_correlation")[:num]:
news_id_list.append(one.new_id_sim)
all_news_hot_value[one.new_id_sim] = (newhot.objects.filter(new_id=browse_one["new_id"])[0]).new_hot
return new.objects.filter(new_id__in=news_id_list)[:20], all_news_hot_value
# 如果该用户没有浏览记录,第一次进入系统且没有选择任何标签,返回热度榜单数据的20~40
else:
# 从新闻热度表中取top20 新闻数据
all_news = newhot.objects.order_by("-new_hot").values("new_id", "new_hot")[20:40]
all_news_id = [one["new_id"] for one in all_news]
all_news_hot_value = {one["new_id"]: one["new_hot"] for one in all_news}
print(all_news_hot_value)
# 返回热度榜单数据
return new.objects.filter(new_id__in=all_news_id), all_news_hot_value
6. 前端界面实现
前端界面直接操作前端与后端交互,完成整个推荐过程。
1)运行逻辑
表现:用户登录后进入标签选择界面,选择标签(或者直接跳过)后进入主页(包含推荐页面和热度榜),同时也可以选择切换用户进行更换操作。
#选择用户登录
def login(request):
if request.method == "GET":
result = dict()
result["users"]=ALLOW_USERS
result["tags"]=ALLOW_TAGS
return JsonResponse(result)
elif request.method == "POST":
#从前端获取用户名并写入 session
uname = request.POST.get('username')
request.session["username"]=uname
#前端将标签以逗号拼接的字符串形式返回
tags= request.POST.get('tags')
return JsonResponse({"username": uname,
"tags": tags,"baseclick":0 , "code": 1})
#主页
def home(request):
#从前端请求中获取cate
_cate = request.GET.get("cateid")
if "username" not in request.session.keys():
return JsonResponse({ "code":0 })
total = 0 #总页数
#如果cate 是推荐页面,走该部分逻辑tag_flag = 0表示不是从标签召回数据
if _cate == "1":
news, news_hot_value = getRecNews(request)
#如果cate 是热度榜,走该部分逻辑
elif _cate == "2":
news,news_hot_value = getHotNews()
#其他正常的请求获取
else:
_page_id = int(request.GET.get("pageid"))
news = new.objects.filter(new_cate=_cate).order_by("-new_time")
total = news.__len__()
news = news[_page_id * 10:(_page_id+1) * 10]
#切换用户
def switchuser(request):
if "username" in request.session.keys():
uname = request.session["username"]
#删除新闻浏览表中的记录
newbrowse.objects.filter(user_name=uname).delete()
print("删除用户: %s 的新闻浏览记录 ..." % uname)
#删除session值
del request.session["username"]
print("用户: %s 执行了切换用户动作,删除其对应的session值 ..." % uname)
return JsonResponse({"code":1})
#return HttpResponseRedirect("/index/login/")
2)前端界面的数据配置
设置本地IP地址为: ALLOWED_HOSTS = ['192.168.43.155','127.0.0.1'],设置数据库配置及密码验证部分,确保前端能够有权限获取数据库的内容:
#数据库
#mysql配置
DB_HOST = "127.0.0.1"
DB_PORT = 3306
DB_USER = "root"
DB_PASSWD = "12345678"
DB_NAME = "newsrec"
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': DB_NAME,
'USER': DB_USER,
'PASSWORD': DB_PASSWD,
'HOST': DB_HOST,
'PORT': DB_PORT
}
}
#密码验证
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
#配置可使用的用户,以便完善整个界面的应用演示
ALLOW_USERS = ["张三","李四","王五"]
#配置选择用户进入下一页可被显示的标签
ALLOW_TAGS = ["峰会","AI","技术","百度","互联网","金融","旅游","扶贫","改革开放","战区","公益","中国","脱贫","经济","慈善","文化","文学","国风","音乐","综艺","101"]
3)前端界面配置
前端界面配置利用JavaScript语言和Vue脚手架以及HTML语言。
import Vue from 'vue'
import App from './App'
import router from './router'
import animate from 'animate.css'
import './assets/style/common.less'
import commontool from './assets/js/tool'
import store from './store'
import layer from 'vue-layer'
Vue.prototype.$layer = layer(Vue)
Vue.use(commontool)
Vue.config.productionTip = false
new Vue({
el: '#app',
router,
store,
components: { App },
template: '<App/>'
})
//此处为“主页(Home)”、“新闻页面(News)”、“登陆页面(Login)”三种页面提供了路由
import Vue from 'vue'
import Router from 'vue-router'
import store from '../store'
import home from '@/pages/Home'
import news from '@/pages/News'
import login from '@/pages/Login'
Vue.use(Router)
const router = new Router({
routes: [
{
path: '/',
name: 'home',
component: home,
meta: {
needLogin: true
}
},
{
path: '/news',
name: 'news',
component: news,
meta: {
needLogin: true
}
},
{
path: '/login',
name: 'login',
component: login,
meta: {
needLogin: false
}
}
]
})
router.beforeEach((to, from, next) => {
if (to.meta.needLogin) {
if (store.state.vuexlogin.isLogin || localStorage.getItem('username')) {
next()
} else {
next({
path: '/login',
query: {redirect: to.fullPath}
})
}
} else {
next()
}
})
export default router
#JavaScript语言三种Vue构架(Home.vue,Login.vue,News.vue)
#前端是一个网页界面,用到了HTML语言。主要涉及一点界面属性(例如界面文字编码格式)的配置
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<title>Recommon</title>
<link href="./static/style/reset.css" rel="stylesheet" />
</head>
<body style="margin:0">
<div id="app"></div>
</body>
</html>
系统测试
启动项目过程如下:在命令行窗口,进入后端文件目录(NewsRecSys/NewsRec)下 运行以下命令:
python manage.py runserver 0.0.0.0:8000
出现如图所示的结果,说明后端服务启动成功。
打开新的命令行窗口,进入前端文件目录下(NewsRecSys/NewsRec-Vue),依次运行以下两条命令:
cnpm install
使用淘宝在国内的镜像cnpm可以避免由于被限速部分组件加载不完整而导致的错误,如图所示。
npm run dev

出现如图所示的结果,说明前端服务启动成功。

在浏览器输入网址为: http://127.0.0.1:8001, 访问项目服务,选择登录用户,进入标签选择界面,如图所示。

用户选择具体标签,单击“进入系统按钮传达对标签涉及内容的喜好,也可以不选择标签单击“跳过”按钮,直接进入系统,如图所示。

在界面上方是不同的栏目,“ 为你推荐栏目会随着用户行为不断的更新,展示当前的推荐情况。其他栏目(诸如国际要闻、互联网等)下的内容则对应不同类别的新闻。选择‘进入后台”栏目,也可以通过输入网址http://127.0.0.1:8000/admin/进入后台 (账号、密码均为admin)。主页界面如图所示。

在界面的左侧是当前选定栏目下的内容,单击内容进入新闻详情页。在界面的右侧是随日期更新的热度榜,反映当前时刻下的新闻热度情况。
单击新闻标题,界面如下图所示。内容详情页面中,界面的上方依然是栏目,左侧是新闻内容详情,包含日期、类别、浏览次数及正文;界面右侧是“相似推荐”推荐了5篇与本新闻相似的其他新闻。

1. 产生用户行为时的推荐
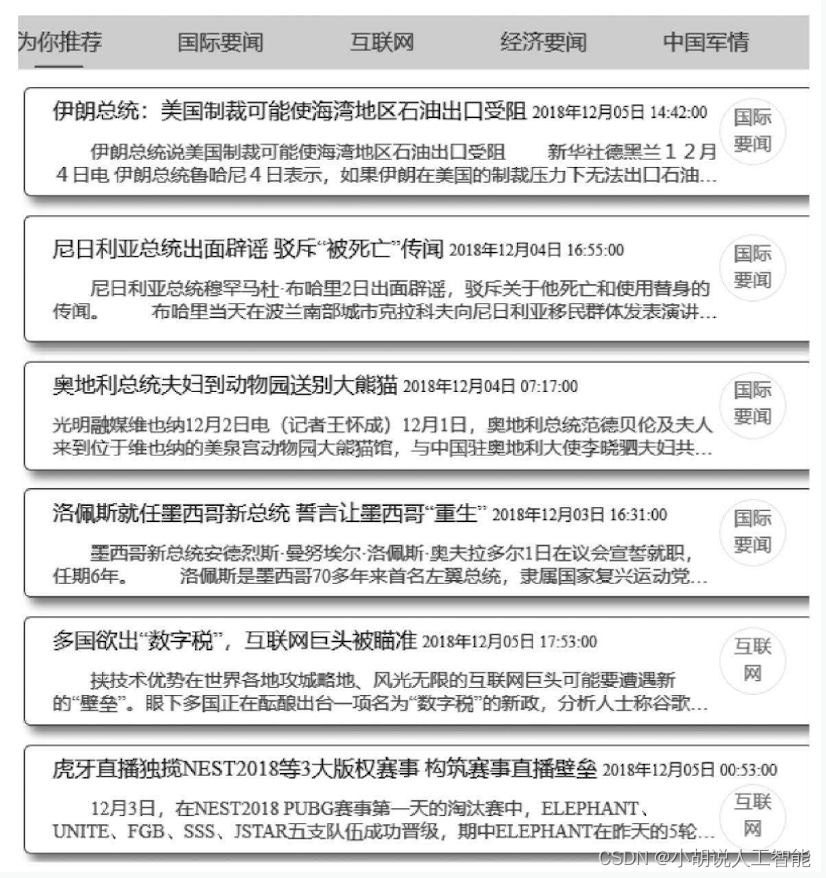
用户查看过一些新闻后,“为你推荐”栏目下的推荐情况如下图所示,“张三”的用户下,查看若干条“国际要闻”、“互联网”消息,在“为你推荐”栏目下,出现相同栏目下的相关新闻。
2. 用户浏览新闻时的推荐
当用户查看新闻时,在右侧会提供与该新闻相似的5篇新闻,作为类似“你可能还喜欢”的推荐,如图所示。

3. 新用户的冷启动推荐
新进入的用户,会推荐来自当前热度榜的新闻。如果该用户没有浏览记录,第一次进入系统且没有选择任何标签,返回热度榜单数据的20~40位,结果如图所示。

没有推荐热度榜单的前几位,是推荐系统为了给用户提供个性化服务,而不是为了重新塑造一个“其他用户的复制”,所以既要参考热度榜,又不能过度依靠热度榜。具体原因可以思考长尾效应。
长尾效应的根本是强调“个性化”“客户力量”和“小利润大市场”。要将市场细分到很细很小时,会发现这些细小市场的累计会带来明显的长尾效应。以图书为例: Barnes&Noble的平均上架书目为13万种。而Amazon有超过一半的销售量来自在它排行榜上位于13万名开外的图书。
4. 新用户自选标签的推荐
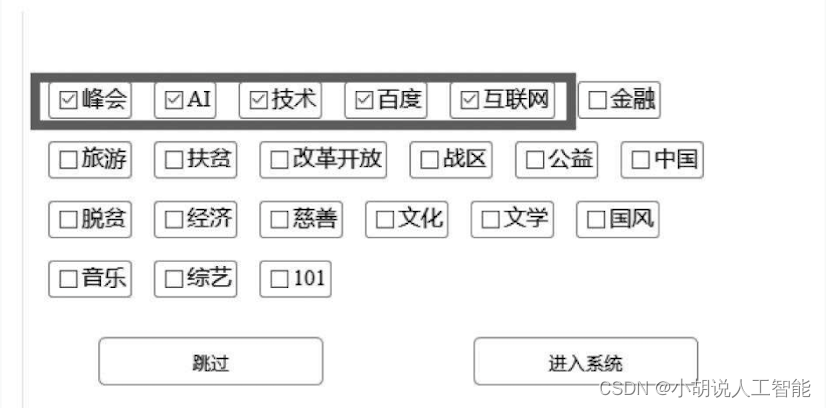
选择用户,进入标签选择界面。在此选择“峰会”、“AI”、“技术”、“百度”、“互联网”5个标签,如图所示 。
进入系统主页界面后,可以看到,“为你推荐”栏目下推荐“峰会”“AI”“互联网”相关内容,如图所示。

工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。