八、性能测试
8.1 性能测试代码
#include"ConcurrentAlloc.h"
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(malloc(16));
v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
//printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
//nworks, rounds, ntimes, malloc_costtime);
cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次malloc"
<< ntimes << "次:" << "花费:" << malloc_costtime << "ms" << endl;
//printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
// nworks, rounds, ntimes, free_costtime);
cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次free"
<< ntimes << "次:" << "花费:" << free_costtime << "ms" << endl;
//printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
// nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
cout << nworks << "个线程并发malloc&free" << nworks * rounds * ntimes
<< "次,总计花费:" << malloc_costtime + free_costtime << "ms" << endl;
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(ConcurrentAlloc(16));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
//printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
// nworks, rounds, ntimes, malloc_costtime);
cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次concurrent alloc"
<< ntimes << "次:" << "花费:" << malloc_costtime << "ms" << endl;
//printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
// nworks, rounds, ntimes, free_costtime);
cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次concurrent dealloc"
<< ntimes << "次:" << "花费:" << free_costtime << "ms" << endl;
//printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",
// nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
cout << nworks << "个线程并发concurrent alloc&dealloc" << nworks * rounds * ntimes
<< "次,总计花费:" << malloc_costtime + free_costtime << "ms" << endl;
}
int main()
{
size_t n = 1000;
cout << "==========================================================" << endl;
BenchmarkConcurrentMalloc(n, 4, 10);
cout << endl << endl;
BenchmarkMalloc(n, 4, 10);
cout << "==========================================================" << endl;
return 0;
}
8.2 性能瓶颈分析
现在的内存池运行以上代码的时间:

现阶段我们写的内存池的性能还比不上malloc,所以这样的内存池也将毫无意义,所以我们要进一步分析一下我们的内存池究竟慢在哪里?
利用VS2019编译器自带的在调试按钮下的性能探查器可以获取我们的高并发内存池的性能分析结果,具体操作如下:
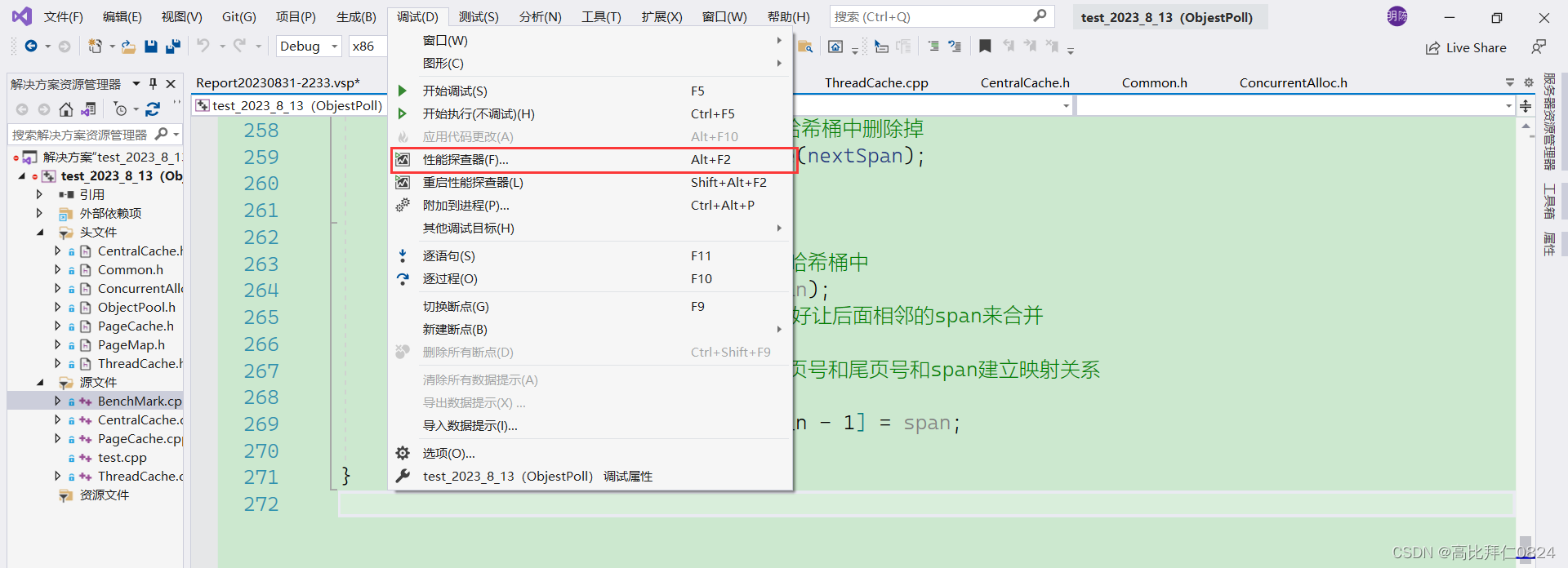
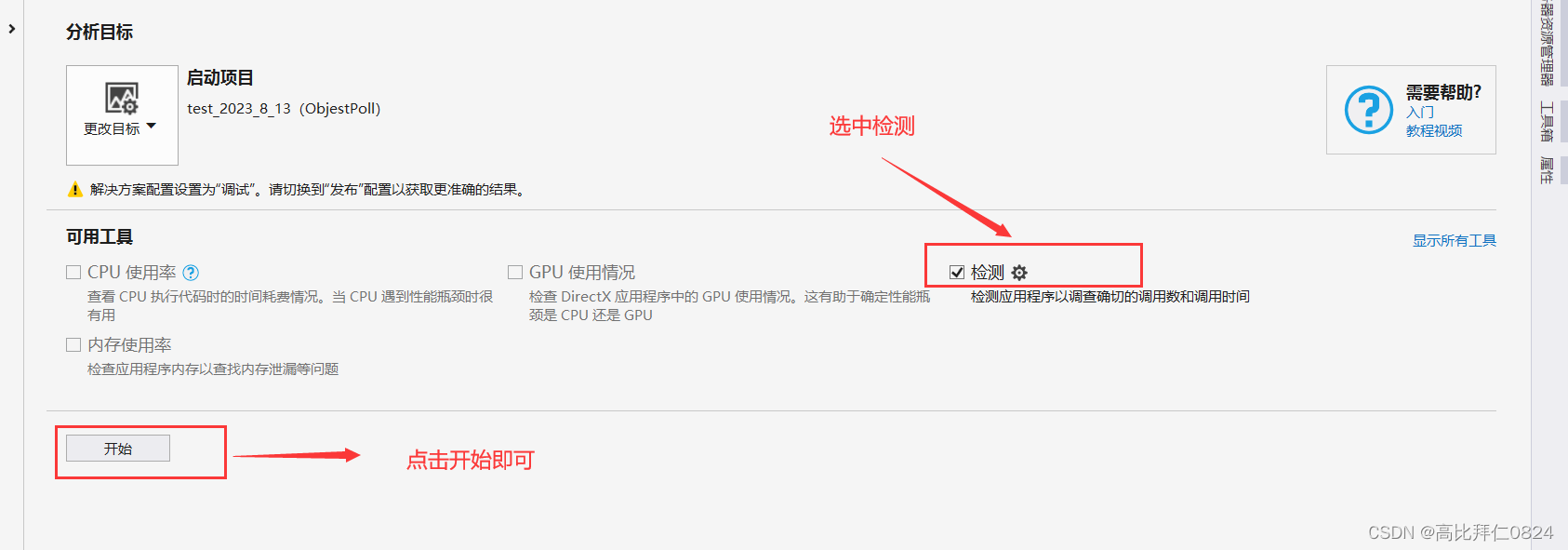
点击开始之后稍等一下就能得到以下的性能分析报告:
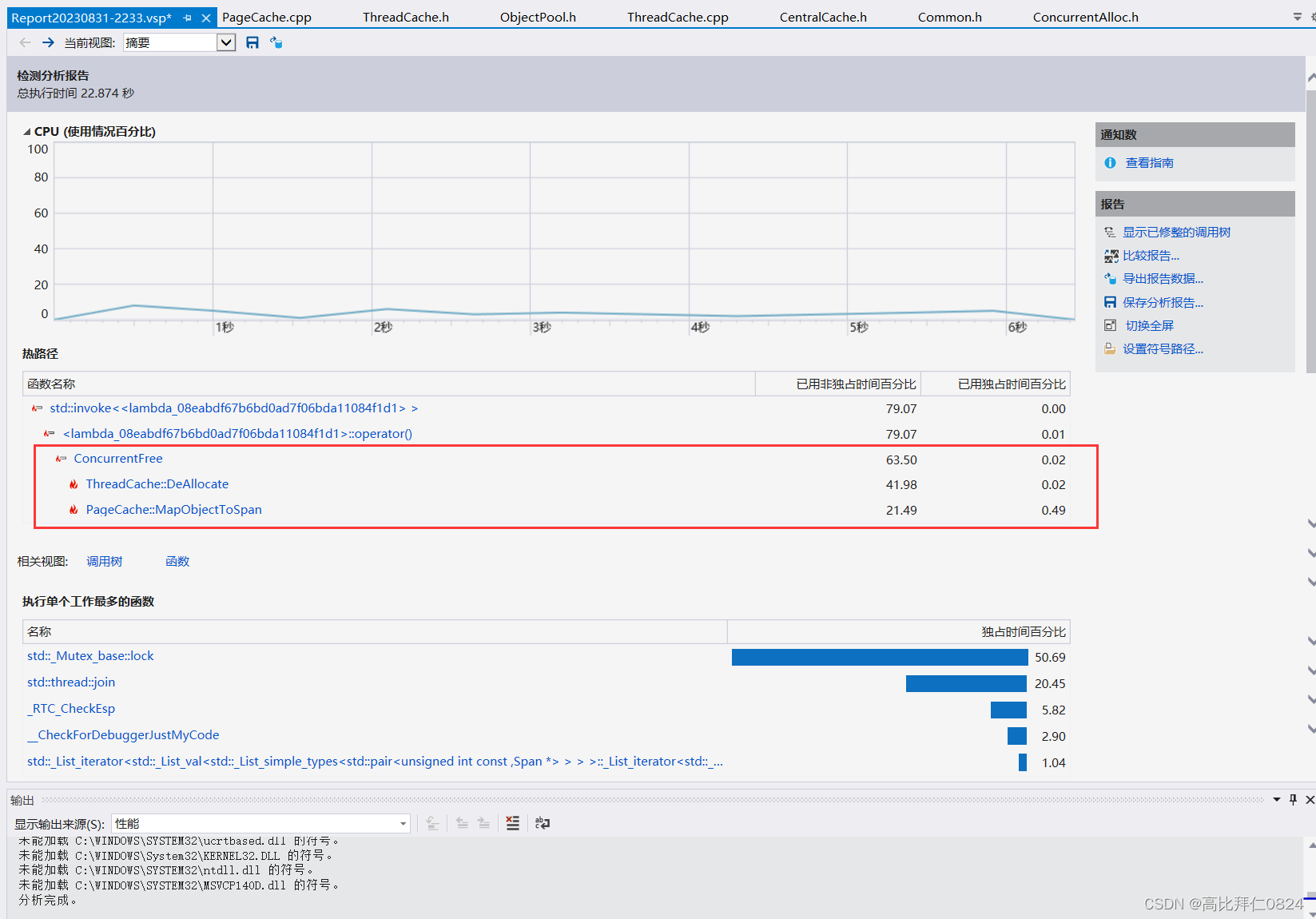
通过性能分析报告可知性能的瓶颈点主要在于ConcurrentFree函数的调用,耗时的占比最高。
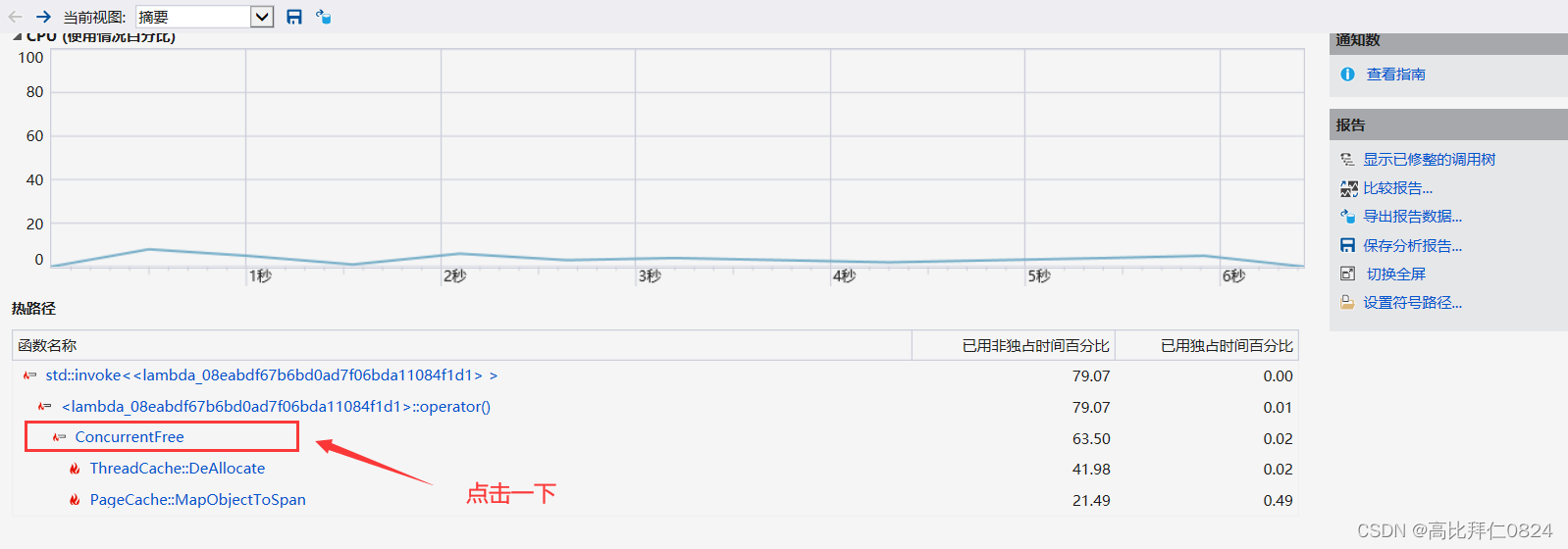



一路点进去就会发现最终的耗时多的罪魁祸首就是在锁的竞争上,因为锁竞争本来在时间成本上就是最多的,所以我们要想提高内存池的性能就应该思考我们该如何减少锁竞争的问题。