前言:Hello大家好,我是小哥谈。ShuffleNetV2 是一种轻量级的神经网络架构,适用于移动设备和嵌入式设备等资源受限的场景,旨在在计算资源有限的设备上提供高效的计算和推理能力,它通过引入通道重排操作和逐点组卷积来减少计算量和参数量。YOLOv5是一种目标检测算法,可以快速准确地检测图像或视频中的目标物体。将ShuffleNetv2和YOLOv5结合起来,可以实现在资源受限的设备上进行高效的目标检测。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
YOLOv5算法改进(5)— 添加ECA注意力机制
YOLOv5算法改进(6)— 添加SOCA注意力机制
YOLOv5算法改进(7)— 添加SimAM注意力机制
YOLOv5算法改进(8)— 替换主干网络之MobileNetV3
目录
🚀1.论文
🚀2.ShuffleNetV2网络架构
🚀3.YOLOv5结合ShuffleNetV2
💥💥步骤1:在common.py中添加ShuffleNetV2模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.论文
旷视科技提出针对移动端深度学习的第二代卷积神经网络 ShuffleNetV2。研究者指出,过去在网络架构设计上仅注重间接指标 FLOPs 的不足,并提出两个基本原则和四项准则来指导网络架构设计,最终得到了无论在速度还是精度上都超越先前最佳网络(例如 ShuffleNetV1、MobileNet 等)的 ShuffleNetV2。在综合实验评估中,ShuffleNetV2 也在速度和精度之间实现了最佳权衡。研究者认为,高效的网络架构设计应该遵循本文提出的四项准则。🌴
ShuffleNetV2 是由国产旷视科技团队在 2018 年提出的,发表在了 ECCV,这篇文章非常硬核,实验非常全面。一些网络模型如MobileNetv1/v2、ShuffleNetv1、Xception等采用了分组卷积、深度可分离卷积等操作,这些操作在一定程度上大大减少了FLOPs,但FLOPs并不是一个直接衡量模型速度或者大小的指标,它只是通过理论上的计算量来衡量模型,然而在实际设备上,由于各种各样的优化计算操作,导致计算量并不能准确地衡量模型的速度。🌴
作者首先分析了现有的很多轻量级网络,例如MobileNetV2,ShuffleNetV1等,认为这些网络模型在设计和评估测试阶段,过于迷信FLOPs(每秒浮点计算量)这个指标,而对于一个网络模型的评估,单单只看这一个指标,很容易导致一个次优化设计的产生。作者认为,现有的FLOPs是一个间接评估准则,与直接评估准则速度(Speed)之间还存在很多不协调、不一致的地方,而导致这点不一致的原因主要有两个:👇
💞很多对速度有重要影响的因素都不在FLOPs的考虑范围之内
比如Memory access cost(MAC),内存访问成本,这个因素对速度的影响很大,而恰恰很多能大幅度降低FLOPs的设计会很大程度上提高MAC的数值,最典型的例子就是Group Convolution,分组卷积。再比如degree of parallelism,并行度,在同等FLOPs的条件下,具有高并行度的网络会拥有更快的运行速度。
💞具有相同FLOPs的操作在不同的环境配置下有着不同的运行时间
通常来说,3x3的卷积层要比1x1的卷积层花费更多的计算时间,但在最新版本的CUDNN库的环境下,由于专门对3x3的卷积操作进行了优化,实际运行速度并不比1x1的卷积层慢上多少。
针对以上两点,对于一个高效率网络模型的设计,作者提出了两个应该考虑的准则:
🍀(1)应该用直接的评估标准(Speed)替代间接的评估标准(FLOPs)
🍀(2)应该根据所配置的目标环境,对网络模型进行评估
论文亮点:♨️♨️♨️
(1)计算量复杂度不能只看FLOPs指标;
(2)提出了4条设计高效网络的准则(guidelines) ;
(3)在shufflenet v1的block上提出了新的block设计。
作者使用MobileNetV2和ShuffleNetV1,在GPU和ARM两个设备上进行了实验,并根据网络模型各个操作的运行时间,绘制出了比例图:👇
从下图中可以发现,即便是同一网络模型,在不同设备中的运行时间都有着非常明显的差异,这里,作者认为FLOPs主要可以用Conv代表,大部分计算都发生在Conv中,可以很清楚地看出Conv,也就是FLOPs,在GPU上所占的运行时间比例不过是50%到54%,而剩下近一半对运行时间、运行速度有影响的因素(例如数据输入输出,数据洗牌,逐元素操作等等),都无法用FLOPs这个指标去衡量,所以作者认为,对于网络模型的运行时间来说,FLOPs并不是一个足够准确的度量标准。🐳
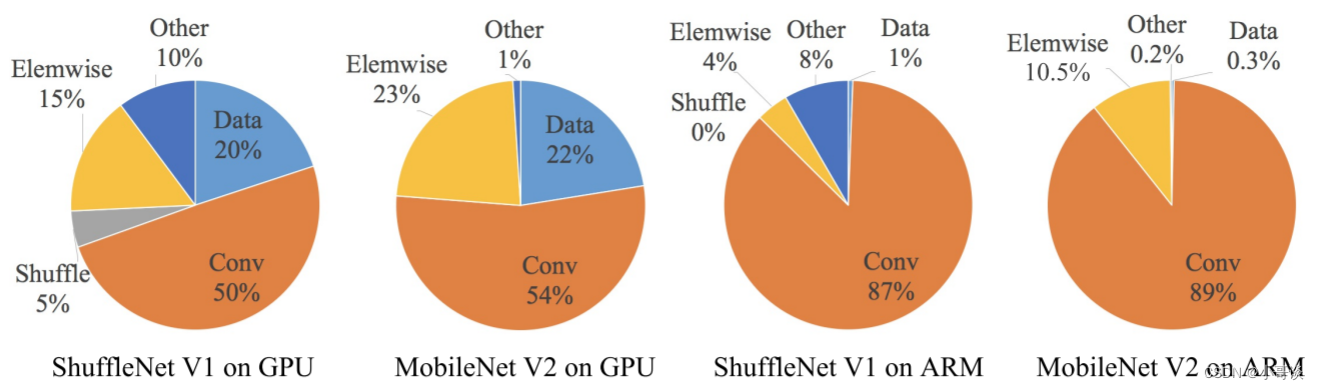
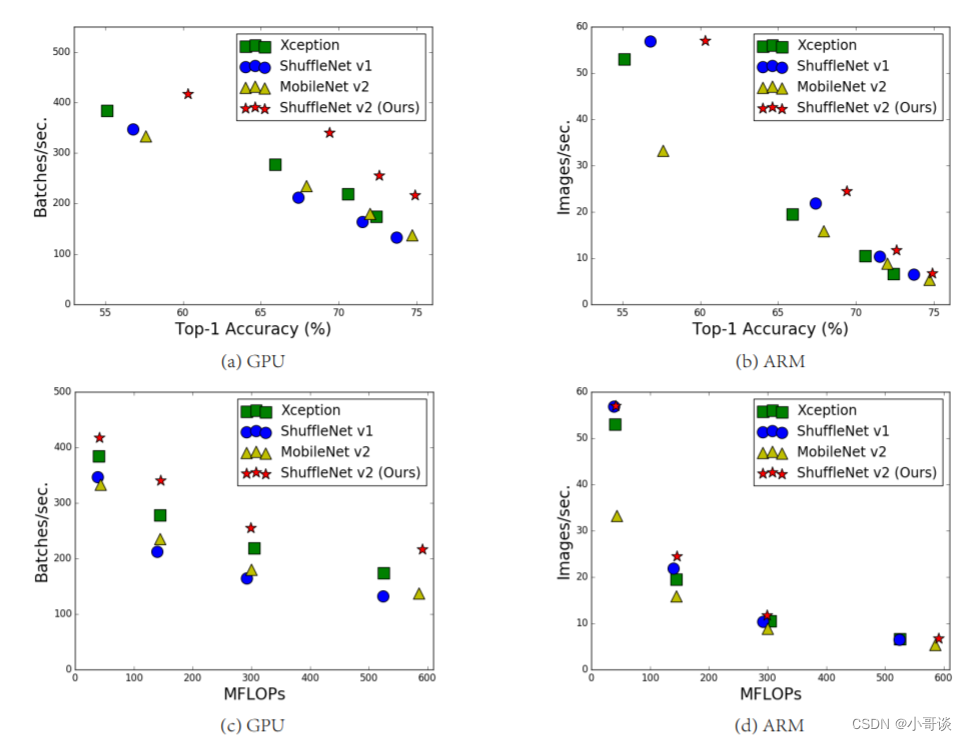
从上图的(c)、(d)能发现,对于一个相同的FLOPs,不同模型间的数据处理速度可以说是天差地别。💣
基于以上观察,为了设计出一个高效率的轻量级网络模型,作者提出了四点不应违反的设计准则:
G1:输入输出通道相同时内存访问量最小: 对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。
G2:过量使用组卷积会增加MAC:组卷积(group convolution)是常用的设计组件,因为它可以减少复杂度却不损失模型容量。但是这里发现,分组过多会增加MAC。
G3:网络碎片化会降低并行度:一些网络如Inception,以及Auto ML自动产生的网络NASNET-A,它们倾向于采用“多路”结构,即存在一个block中很多不同的小卷积或者pooling,这很容易造成网络碎片化,减低模型的并行度,相应速度会慢,这也可以通过实验得到证明。
G4:不能忽略元素级操作:对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。

基本概念:♨️♨️♨️
FLOPS(S大写): 指每秒浮点运算次数,可以理解为计算的速度,是衡量硬件性能的一个指标。
FLOPs(s小写):指浮点运算数即网络中的乘法和加法操作的数量,理解为计算量。可以用来衡量算法/模型的复杂度。在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)。
MAC(内存访问成本):计算机在进行计算时候要加载到缓存中,然后再计算,这个加载过程是需要时间的。其中,分组卷积(group convolution)是对MAC消耗比较多的操作。
并行度:在相同的FLOPs下,具有高并行度的模型可能比具有低并行度的另一个模型快得多。如果网络的并行度较高,那么速度就会有显著的提升。
论文题目:《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
论文地址: https://arxiv.org/pdf/1807.11164.pdf
代码实现: https://github.com/megvii-model/ShuffleNet-Series/blob/master/ShuffleNetV2/blocks.py
YOLOv5: GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
🚀2.ShuffleNetV2网络架构
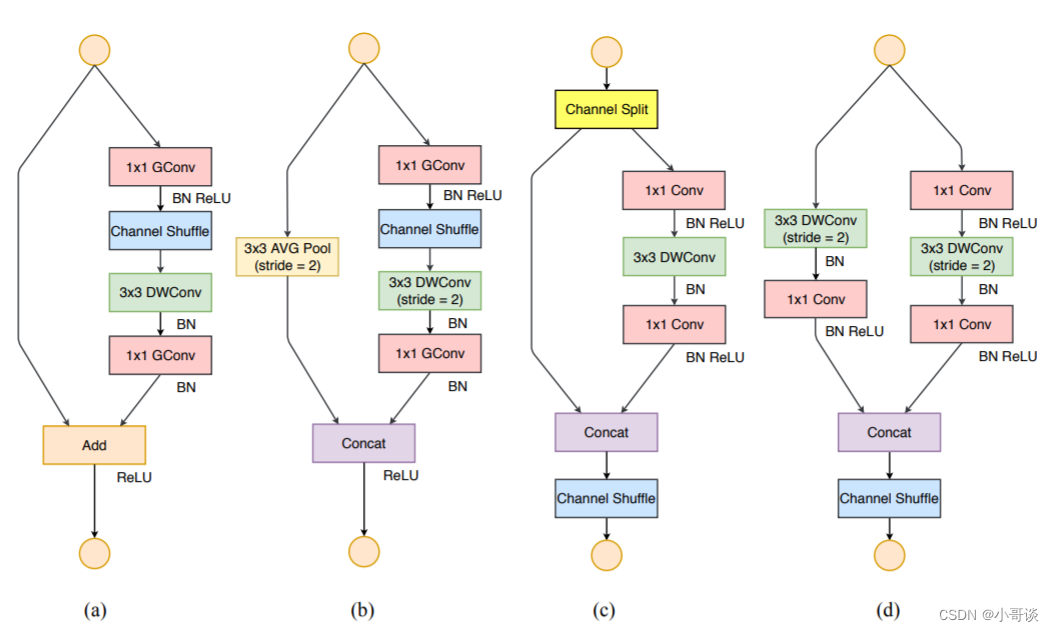
如上图(a)、(b),在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。 🍄
为了改善v1的缺陷,v2版本引入了一种新的运算:channel split。具体来说,在开始时先将输入特征图在通道维度分成两个分支:通道数分别为和
,实际实现时
。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。对于下采样模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。✅
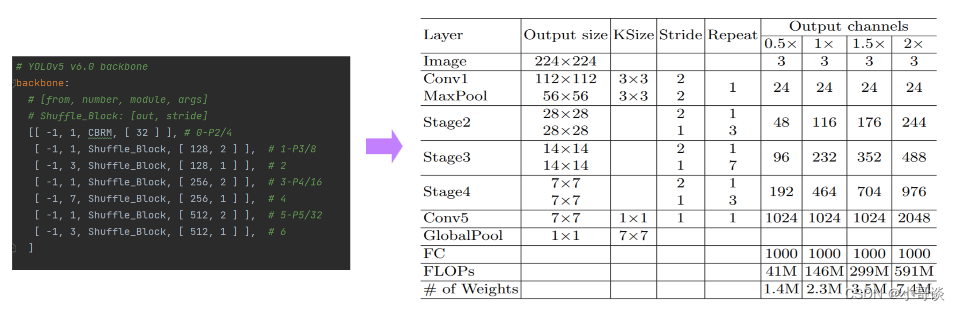
ShuffleNetv2的整体结构如下表所示,基本与v1类似,其中设定每个block的channel数,如0.5x,1x,可以调整模型的复杂度。
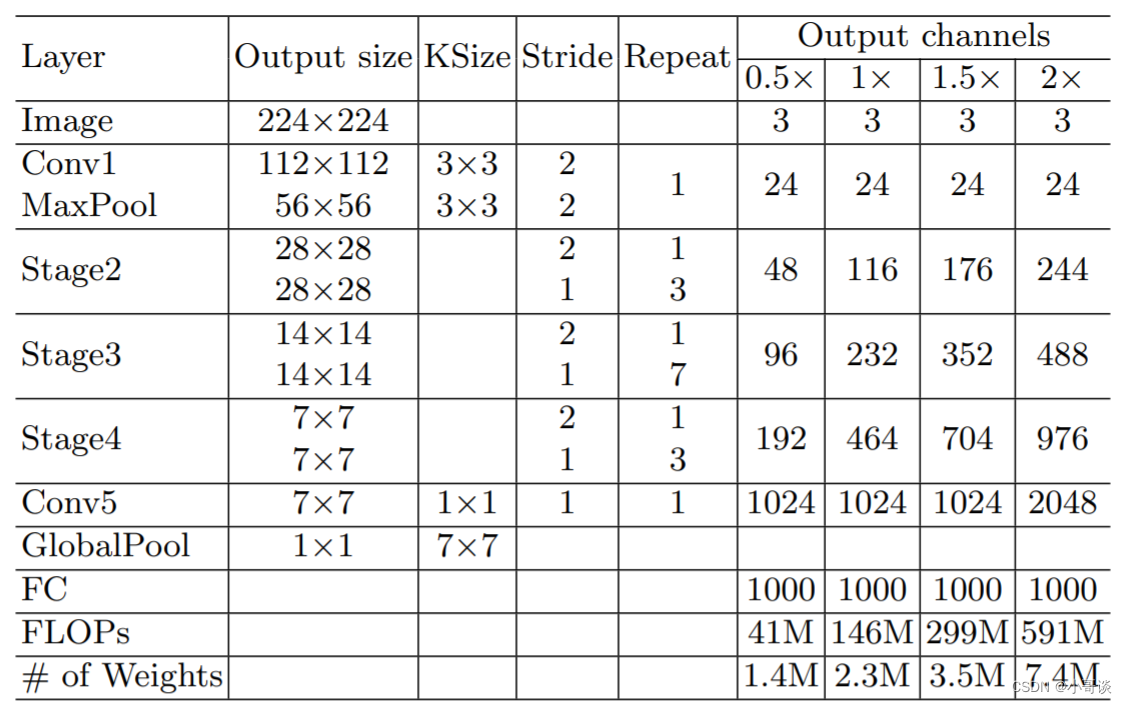
ShuffleNetV2相较于ShuffleNetV1进行了以下改进:👇
(1)使用更高效的通道重排方式:ShuffleNetV2中使用了一种称为"channel split"的方式,将输入通道分为两部分,并将它们分别用于不同的分支中,然后再将它们重新组合。这种方式相较于ShuffleNet V1中的"channel shuffle"方式更加高效。
(2)增加了更多的组卷积层:ShuffleNetV2中引入了更多的组卷积层,以进一步减少模型的计算量和参数量。
(3)引入了新的stage结构:ShuffleNetV2中增加了一种新的stage结构,以进一步提高模型的性能。
(4)采用更加精细的网络设计:ShuffleNetV2中对网络的设计进行了更加精细的调整,以进一步提高模型的性能和效率。
综上所述,ShuffleNetV2相较于ShuffleNetV1在模型性能和计算效率方面都有较大的提升。 💫 💫 💫
🚀3.YOLOv5结合ShuffleNetV2
💥💥步骤1:在common.py中添加ShuffleNetV2模块
将下面ShuffleNetV2模块的代码复制粘贴到common.py文件的末尾。
# 通道重排,跨group信息交流
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class CBRM(nn.Module): #conv BN ReLU Maxpool2d
def __init__(self, c1, c2): # ch_in, ch_out
super(CBRM, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class Shuffle_Block(nn.Module):
def __init__(self, ch_in, ch_out, stride):
super(Shuffle_Block, self).__init__()
if not (1 <= stride <= 2):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = ch_out // 2
assert (self.stride != 1) or (ch_in == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(ch_in, ch_in, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(ch_in),
nn.Conv2d(ch_in, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(ch_in if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 按照维度1进行split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
具体如下图所示:

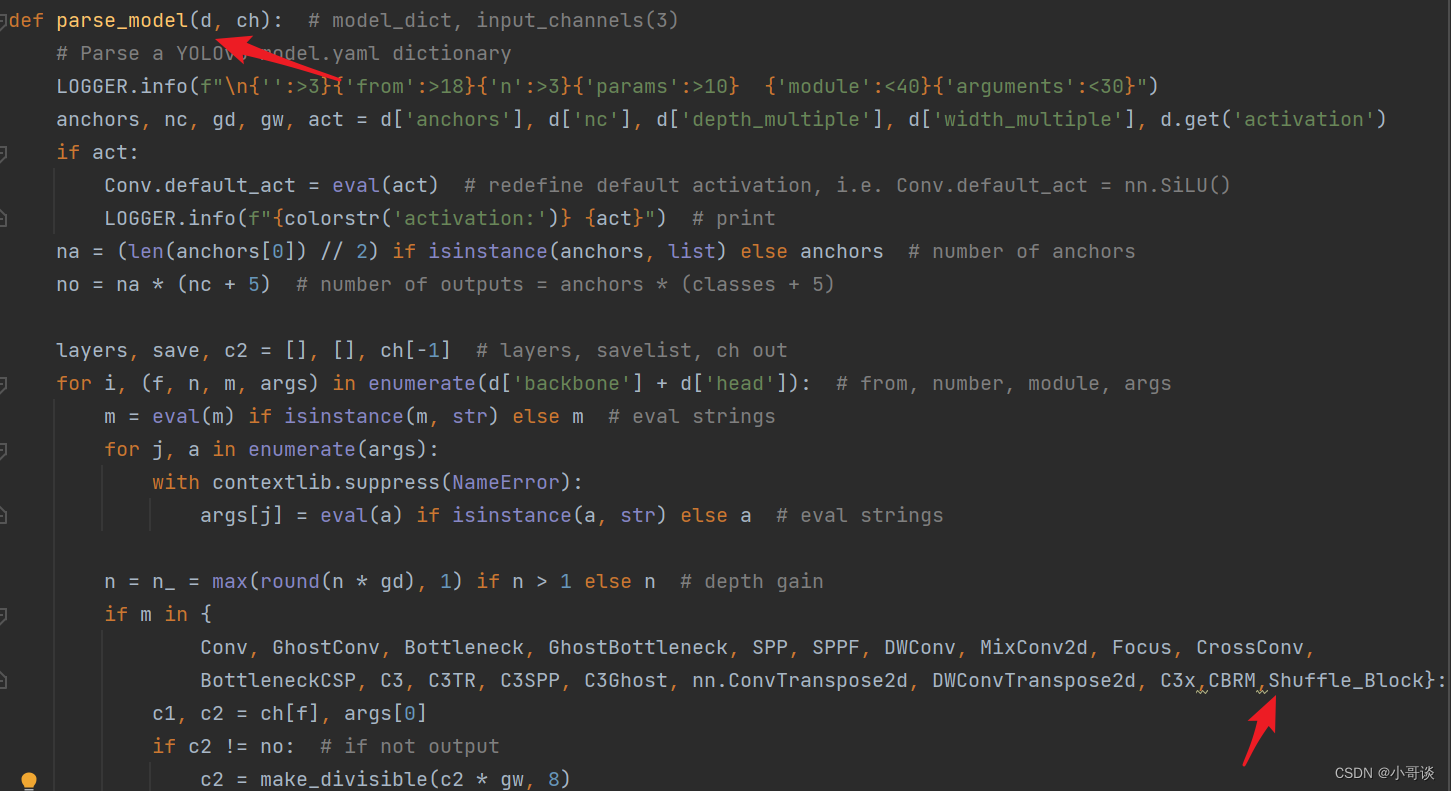
💥💥步骤2:在yolo.py文件中加入类名
首先在yolo.py文件中找到parse_model函数这一行,加入 CBRM 和 Shuffle_Block 。
💥💥步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_ShuffleNetV2.yaml。
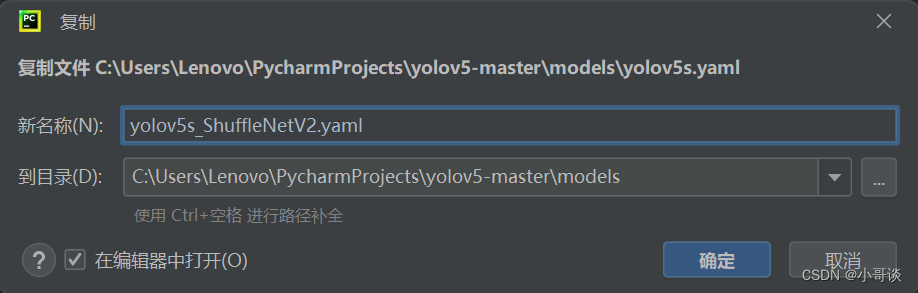
然后根据ShuffleNetV2的网络架构来修改配置文件。
yaml文件修改后的完整代码如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 20 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# Shuffle_Block: [out, stride]
[[ -1, 1, CBRM, [ 32 ] ], # 0-P2/4
[ -1, 1, Shuffle_Block, [ 128, 2 ] ], # 1-P3/8
[ -1, 3, Shuffle_Block, [ 128, 1 ] ], # 2
[ -1, 1, Shuffle_Block, [ 256, 2 ] ], # 3-P4/16
[ -1, 7, Shuffle_Block, [ 256, 1 ] ], # 4
[ -1, 1, Shuffle_Block, [ 512, 2 ] ], # 5-P5/32
[ -1, 3, Shuffle_Block, [ 512, 1 ] ], # 6
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 10
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 14 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 17 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 7], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 20 (P5/32-large)
[[14, 17, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
💥💥步骤4:验证是否加入成功
在yolo.py文件里,配置我们刚才自定义的yolov5s_ShuffleNetV2.yaml。
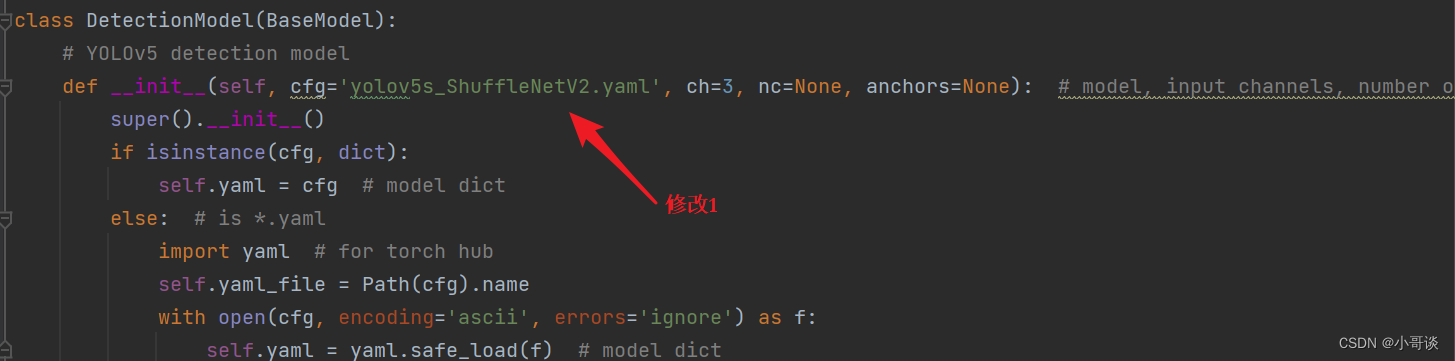
然后运行yolo.py,得到结果。
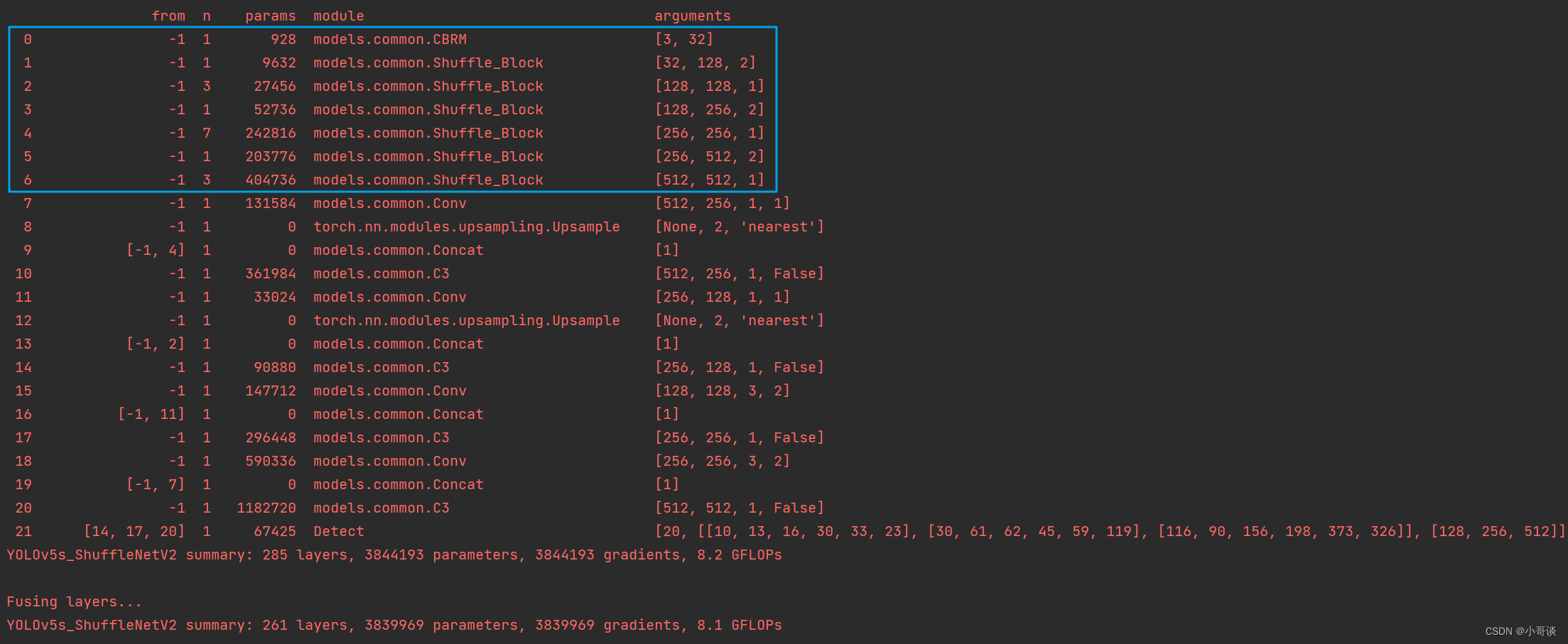
这样说明我们添加成功了。🎉🎉🎉
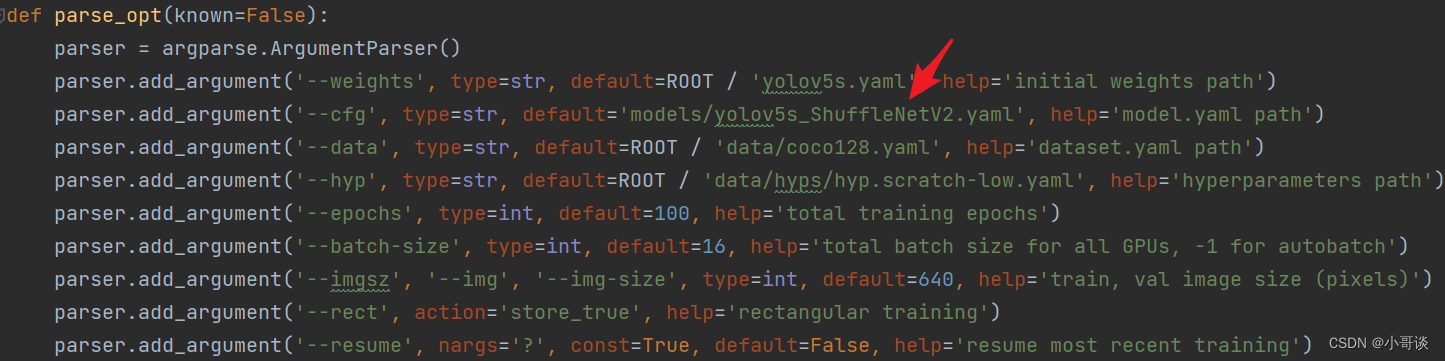
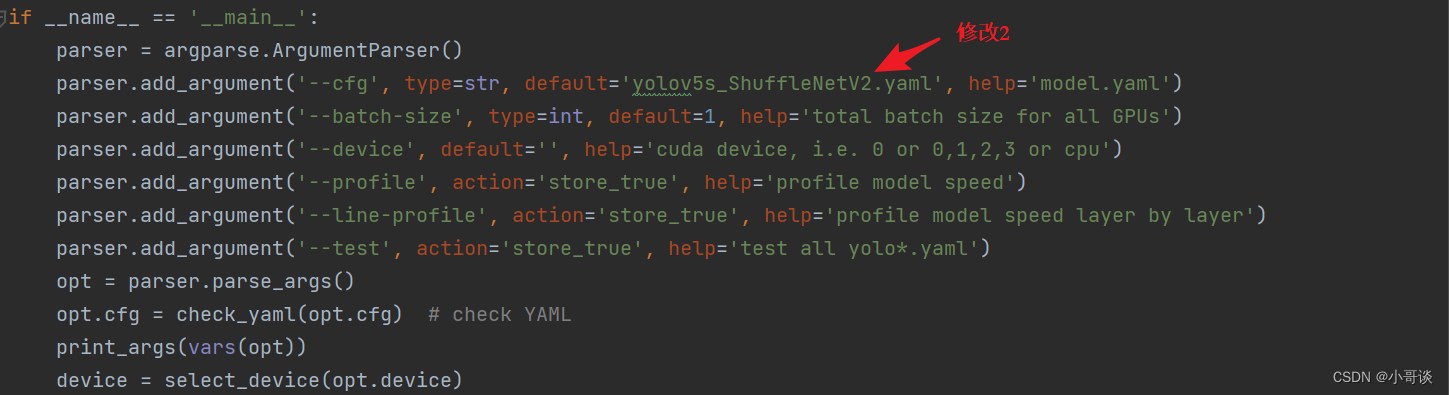
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行' --cfg' 的default改为 'models/yolov5s_ShuffleNetV2.yaml',然后就可以开始进行训练了。🎈🎈🎈