当涉及到处理文本数据时,正则表达式是一个非常有用的工具。它可以用于在字符串中进行模式匹配、搜索、替换等操作。以下是一个简单的Python正则表达式教程,从基础开始介绍如何使用正则表达式。
什么是正则表达式?
正则表达式(Regular Expression,简称Regex或RegExp)是一种用来描述、匹配一系列字符串的模式。它由一些特殊字符和普通字符组成,可以用来进行字符串匹配、搜索和替换等操作。
在Python中使用正则表达式
Python标准库中内置了re模块,它提供了正则表达式的支持。以下是一些常用的re模块函数:
re.search(pattern, string): 在给定的字符串中搜索匹配给定模式的第一个位置。re.match(pattern, string): 从字符串的开头开始匹配给定模式。re.findall(pattern, string): 返回所有匹配给定模式的非重叠子字符串的列表。re.finditer(pattern, string): 返回一个迭代器,产生所有匹配给定模式的非重叠子字符串的匹配对象。re.sub(pattern, replacement, string): 将给定模式匹配的字符串替换为指定的字符串。
常用的正则表达式元字符
.: 匹配任意字符,除了换行符。*: 匹配前一个字符0次或多次。+: 匹配前一个字符1次或多次。?: 匹配前一个字符0次或1次,使其变为可选。\d: 匹配任意数字字符。\w: 匹配任意字母、数字或下划线字符。\s: 匹配任意空白字符(空格、制表符、换行等)。^: 匹配字符串的开头。$: 匹配字符串的结尾。[...]: 匹配方括号中的任意字符。|: 逻辑或,用于在模式中指定多个可选项。
示例
以下是一些正则表达式在Python中的使用示例:
import re
# 搜索匹配的字符串
text = "Hello, my email is example@example.com"
pattern = r'\w+@\w+\.\w+'
match = re.search(pattern, text)
if match:
print("Email found:", match.group())
# 查找所有匹配的字符串
text = "apple, banana, cherry, date"
pattern = r'\w+'
matches = re.findall(pattern, text)
print("Matches:", matches)
# 替换字符串
text = "Hello, my name is Alice."
pattern = r'Alice'
replacement = "Bob"
new_text = re.sub(pattern, replacement, text)
print("New text:", new_text)
请注意,正则表达式中的反斜杠在字符串中需要进行转义,因此我们使用原始字符串(以r开头)来避免不必要的转义。
这只是一个入门级的教程,正则表达式在复杂的文本处理中可以发挥更大的作用。如果您想深入了解正则表达式的更多内容,可以查阅官方文档或其他教程资源。
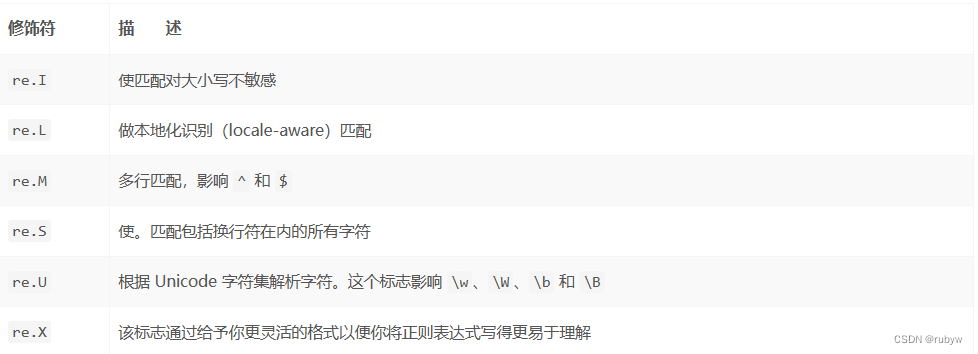
正则表达式匹配规则
\w 匹配字母、数字及下划线
\W 匹配不是字母、数字及下划线的字符
\s 匹配任意空白字符,等价于 [\t\n\r\f]
\S 匹配任意非空字符
\d 匹配任意数字,等价于 [0-9]
\D 匹配任意非数字的字符
\A 匹配字符串开头
\Z 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串
\z 匹配字符串结尾,如果存在换行,同时还会匹配换行符
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配一行字符串的开头
$ 匹配一行字符串的结尾
. 匹配任意字符,除了换行符,当 re.DOTALL 标记被指定时,则可以匹配包括换行符的任意字符
[…] 用来表示一组字符,单独列出,比如 [amk] 匹配 a、m 或 k
[^…] 不在 [] 中的字符,比如 匹配除了 a、b、c 之外的字符
- 匹配 0 个或多个表达式
- 匹配 1 个或多个表达式
? 匹配 0 个或 1 个前面的正则表达式定义的片段,非贪婪方式
{n} 精确匹配 n 个前面的表达式
{n, m} 匹配 n 到 m 次由前面正则表达式定义的片段,贪婪方式
a b匹配 a 或 b
() 匹配括号内的表达式,也表示一个组