Databend Cluster Key 是指 Databend 可以按声明的 key 排序存储,主要用于用户对时间响应比较高,同时愿意为这个 cluster key 进行额排序操作的用户。 Databend 只支持一个 Cluster key,Cluster key中可以包含多列及表达式。
基本语法
-- 语法:
alter table T cluster by(c1, fun(c2));
-- 例如:
alter table T cluster by(user_id); -- 指定数据按 user_id 排序存储
-- 日志场景 按 msg_id, 小时 排序存储
alter table T cluster by(msg_id, to_yyyymmddhh(c_timestamp));
-- 强制数据排序
optimize table T compact;
alter table T recluster final; -- 全局排序, 建议第一次创建 Cluster key 后使用,后期如果遇到性能退化,也可以再次使用更多关于 Databend Cluster key 语法参考:
Understanding Cluster Key | Databend
使用注意事项
目前 Databend 在表有 cluster key 的情况下,使用
- copy into
- replace into
这两种方式写入数据时,会自动执行 compact 和 recluster 操作。
关于 Databend Cluster Key 你需要了解的:
- Databend 中数据分区按: block_size_threshold (default: 100M ) or row_per_block(default 100万) 组织,两者任意达到之一就会生成新的 Block
- 新生成的 Block 中会按定义的 cluster key 排序存储,当该key的 min = max 时,该 block 为 constant_block, 同时 cluster key 不保证全局有序
- 多个 block 之间可能有重叠区间,如,cluster by (age)
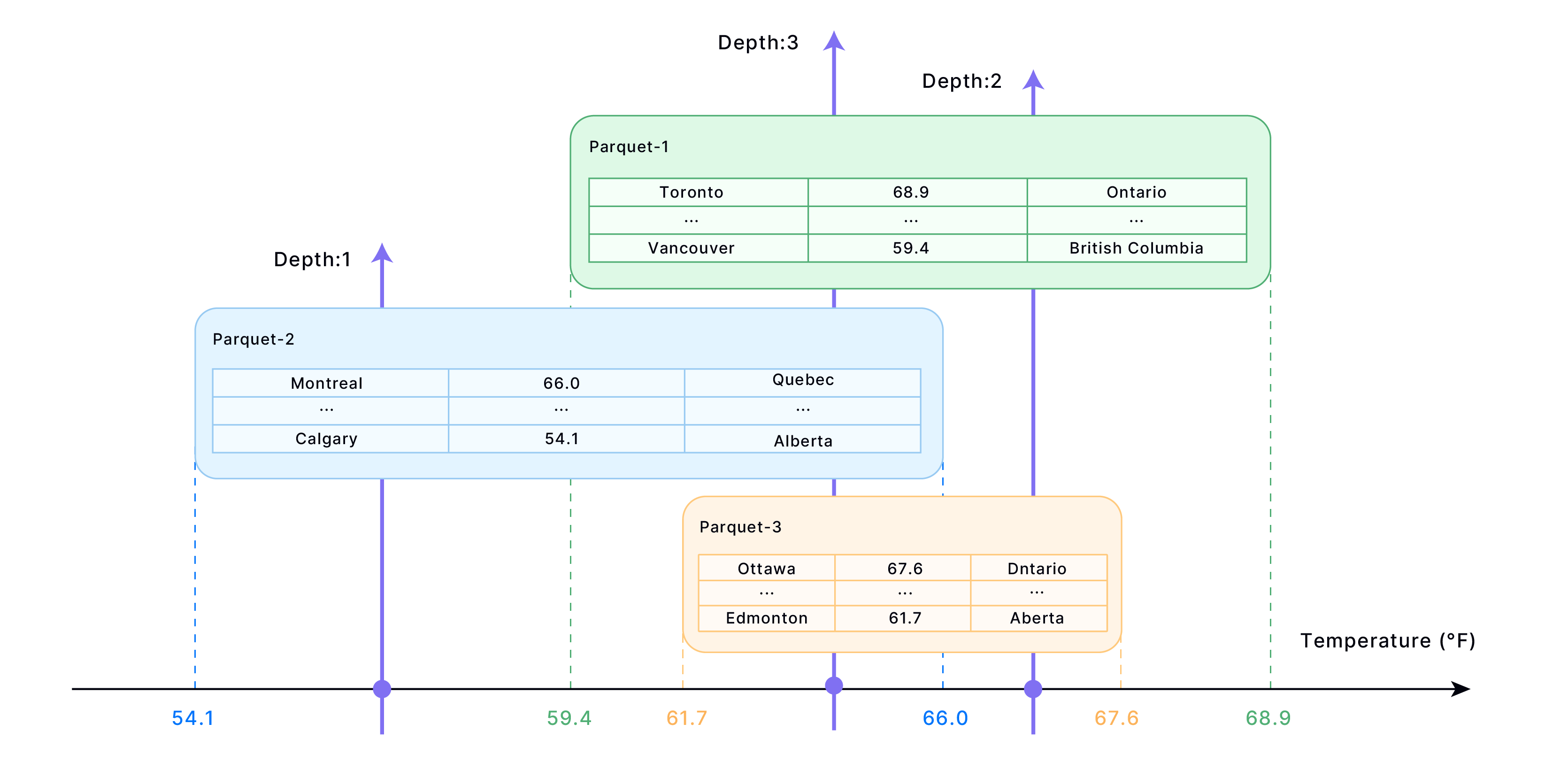
不同区间的重叠形成了不同的深度,例如上图:
select * from T where age >30 and age <35; 这样一个查询,需要查找到的深度为 3 ,即为 3 个 Block。
所以表中指定列的重叠block-partitions的平均深度,越小越好。如下所示:
-- 可以通过 clustering_information('db','tbname') 查看该表的 Cluster 信息
select * from clustering_information('wubx','sbtest10w')\G;
*************************** 1. row ***************************
cluster_by_keys: (id) -- 定义的 Cluster key
total_block_count: 451 -- 当前有多少的 block
constant_block_count: 0 -- min/max 相等 block, 也就说 block 中只包括一个(组) cluster_key 的值
unclustered_block_count: 0 -- 还没 Cluster 的 Block
average_overlaps: 2.1774 -- 在一个 Range 范围内,有多少个 block有重叠比率
average_depth: 2.4612 -- cluster key 在分区的重叠分区数的平均深度
block_depth_histogram: {"00001":32,"00002":217,"00003":164,"00004":38}
1 row in set (0.02 sec)
Read 1 rows, 448.00 B in 0.015 sec., 67.92 rows/sec., 29.71 KiB/sec.结果中最重要信息是“average_depth”,数字越小, 表的clustering效果越好,上图为: 2.46,属于比较好的状态(小于 total_block_count * 0.1 ) 。block_depth_histogram 告诉更多关于每个深度有多少个分区的详细信息。 如果在较低深度中的分区数更多,则表的聚类效果更好。 例如"00004" :38 表示 (3,4] 有 38 个 block 有 4 个深度。
其它优化建议
- 一般来讲声明 Cluster key 后对于区间查询和点查都有较大的优化
- 如果声明 cluster key 后,还想进一步的提升点查或是区间查询的能力,可以通过调整 block 大小
-- 把 Block 的大小修改为压缩前 50M ,行数不超过 10 万行
alter table T set options(row_per_block=100000,block_size_threshold=52428800);关于 options 查看: Fuse Engine | Databend
默认数据分布:
优化数据在 Block 中的分布
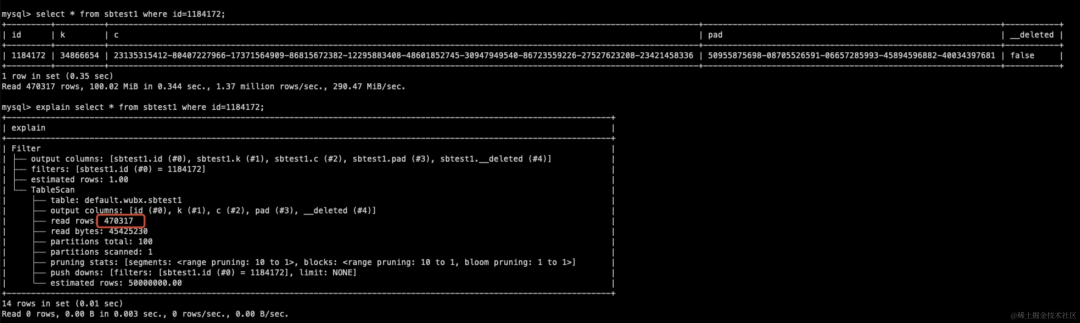
create table sbtest10w like sbtest1;
alter table sbtest10w set options(row_per_block=100000,block_size_threshold=52428800);
insert into sbtest10w select * from sbtest1;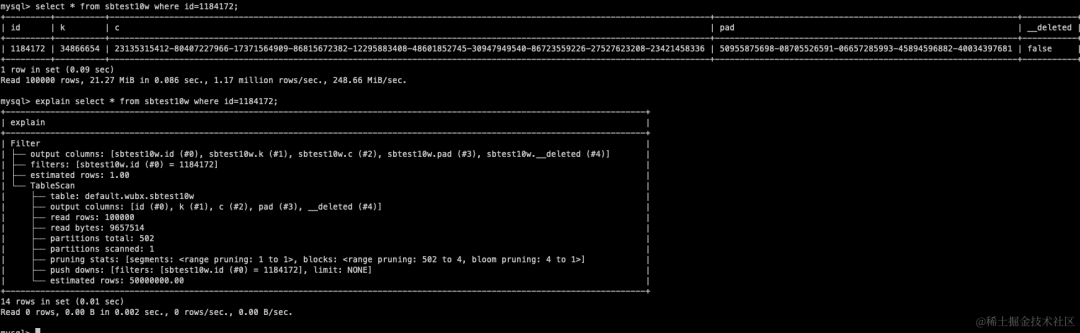
- 对于特别宽的表,建议查询中只访问需要的列来减少时间开销

- 对于复杂的 SQL 里面有大量聚合的操作还是推荐大一点的 Block 及行数
参考
- CLUSTERING_INFORMATION | Databend
- RECLUSTER TABLE | Databend