【自然语言处理(NLP)】基于BiLSTM+CRF的事件抽取

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于BiLSTM+CRF的事件抽取
- 前言
- (一)、任务描述
- (二)、环境配置
- 一、数据准备
- (一)、导入相关包
- (二)、数据集加载
- 二、定义LSTM模型
- 三、定义训练框架
- 评价指标
- 四、模型训练及预测1
- 五、模型训练及预测2
- 总结
前言
(一)、任务描述
事件抽取技术是从非结构化信息中抽取出用户感兴趣的事件,并以结构化呈现给用户。
事件抽取任务可分解为4个子任务:触发词识别、事件类型分类、论元识别和角色分类任务,其中,触发词识别和事件类型分类可合并成事件识别任务。
(二)、环境配置
本示例使用BiLSTM实现两个子任务中的分类,代码运行的环境配置如下:Python版本为3.7,PaddlePaddle版本为2.0.0,操作平台为AI Studio。
import paddle
import numpy as np
import matplotlib.pyplot as plt
print(paddle.__version__)
输出结果如下图1所示:

一、数据准备
(一)、导入相关包
import os
import json
import paddle.fluid as fluid
import ast
import hashlib
import warnings
import argparse
from functools import partial
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification, LinearDecayWithWarmup
from paddlenlp.metrics import ChunkEvaluator
warnings.filterwarnings('ignore')
(二)、数据集加载
''' ------------------ 1.数据预处理及加载 -------------------'''
def cal_md5(str):
"""calculate string md5"""
str = str.decode("utf-8", "ignore").encode("utf-8", "ignore")
return hashlib.md5(str).hexdigest()
def read_by_lines(path):
"""read the data by line"""
result = list()
with open(path, "r") as infile:
for line in infile:
result.append(line.strip())
return result
def write_by_lines(path, data):
"""write the data"""
with open(path, "w") as outfile:
[outfile.write(d + "\n") for d in data]
def text_to_sents(text):
"""text_to_sents"""
deliniter_symbols = [u"。", u"?", u"!"]
paragraphs = text.split("\n")
ret = []
for para in paragraphs:
if para == u"":
continue
sents = [u""]
for s in para:
sents[-1] += s
if s in deliniter_symbols:
sents.append(u"")
if sents[-1] == u"":
sents = sents[:-1]
ret.extend(sents)
return ret
def load_dict(dict_path):
"""load_dict"""
vocab = {}
for line in open(dict_path, 'r', encoding='utf-8'):
value, key = line.strip('\n').split('\t')
vocab[key] = int(value)
return vocab
def extract_result(text, labels):
"""extract_result"""
ret, is_start, cur_type = [], False, None
if len(text) != len(labels):
labels = labels[:len(text)]
for i, label in enumerate(labels):
if label != u"O":
_type = label[2:]
if label.startswith(u"B-"):
is_start = True
cur_type = _type
ret.append({"start": i, "text": [text[i]], "type": _type})
elif _type != cur_type:
"""
# 如果是没有B-开头的,则不要这部分数据
cur_type = None
is_start = False
"""
cur_type = _type
is_start = True
ret.append({"start": i, "text": [text[i]], "type": _type})
elif is_start:
ret[-1]["text"].append(text[i])
else:
cur_type = None
is_start = False
else:
cur_type = None
is_start = False
return ret
def data_process(path, model="trigger", is_predict=False):
"""data_process"""
def label_data(data, start, l, _type):
"""label_data"""
for i in range(start, start + l):
suffix = "B-" if i == start else "I-"
data[i] = "{}{}".format(suffix, _type)
return data
sentences = []
output = ["text_a"] if is_predict else ["text_a\tlabel"]
with open(path) as f:
for line in f:
d_json = json.loads(line.strip())
_id = d_json["id"]
text_a = [
"," if t == " " or t == "\n" or t == "\t" else t
for t in list(d_json["text"].lower())
]
if is_predict:
sentences.append({"text": d_json["text"], "id": _id})
output.append('\002'.join(text_a))
else:
if model == "trigger":
labels = ["O"] * len(text_a)
for event in d_json.get("event_list", []):
event_type = event["event_type"]
start = event["trigger_start_index"]
trigger = event["trigger"]
labels = label_data(labels, start,
len(trigger), event_type)
output.append("{}\t{}".format('\002'.join(text_a),
'\002'.join(labels)))
elif model == "role":
for event in d_json.get("event_list", []):
labels = ["O"] * len(text_a)
for arg in event["arguments"]:
role_type = arg["role"]
argument = arg["argument"]
start = arg["argument_start_index"]
labels = label_data(labels, start,
len(argument), role_type)
output.append("{}\t{}".format('\002'.join(text_a),
'\002'.join(labels)))
return output
def schema_process(path, model="trigger"):
"""schema_process"""
def label_add(labels, _type):
"""label_add"""
if "B-{}".format(_type) not in labels:
labels.extend(["B-{}".format(_type), "I-{}".format(_type)])
return labels
labels = []
for line in read_by_lines(path):
d_json = json.loads(line.strip())
if model == "trigger":
labels = label_add(labels, d_json["event_type"])
elif model == "role":
for role in d_json["role_list"]:
labels = label_add(labels, role["role"])
labels.append("O")
tags = []
for index, label in enumerate(labels):
tags.append("{}\t{}".format(index, label))
return tags
def word2id_(lines,vocab,max_len=145):
# 144 21 0.9505796670630202
res = []
lens = []
for line in lines:
r = []
for c in line:
if c not in vocab:
r.append(vocab['<pad>'])
else:
r.append(vocab[c])
r =r[:max_len]
lens.append(len(r))
r = r+[0]*(max_len-len(r))
res.append(r)
return r,lens
def get_vocab():
train_lines = open('data/DuEE_1_0/train.json','r',encoding='utf-8').readlines()
dev_lines = open('data/DuEE_1_0/dev.json','r',encoding='utf-8').readlines()
lines = train_lines + dev_lines
vocab = set()
# dic = {}
for line in lines:
ll = json.loads(line.strip())
for c in ll['text']:
vocab.add(c)
vocab = {c:i+2 for i,c in enumerate(list(vocab))}
vocab['<pad>'],vocab['<unk>']=0,1
return vocab
print("\n================= DUEE 1.0 DATASET ==============")
conf_dir = "./data/DuEE_1_0"
schema_path = "{}/event_schema.json".format(conf_dir)
tags_trigger_path = "{}/trigger_tag.dict".format(conf_dir)
tags_role_path = "{}/role_tag.dict".format(conf_dir)
print("\n=================start schema process==============")
print('input path {}'.format(schema_path))
tags_trigger = schema_process(schema_path, "trigger")
write_by_lines(tags_trigger_path, tags_trigger)
print("save trigger tag {} at {}".format(
len(tags_trigger), tags_trigger_path))
tags_role = schema_process(schema_path, "role")
write_by_lines(tags_role_path, tags_role)
print("save trigger tag {} at {}".format(len(tags_role), tags_role_path))
print("=================end schema process===============")
# data process
data_dir = "./data/DuEE_1_0"
trigger_save_dir = "{}/trigger".format(data_dir)
role_save_dir = "{}/role".format(data_dir)
print("\n=================start schema process==============")
if not os.path.exists(trigger_save_dir):
os.makedirs(trigger_save_dir)
if not os.path.exists(role_save_dir):
os.makedirs(role_save_dir)
print("\n----trigger------for dir {} to {}".format(data_dir,
trigger_save_dir))
train_tri = data_process("{}/train.json".format(data_dir), "trigger")
write_by_lines("{}/train.tsv".format(trigger_save_dir), train_tri)
dev_tri = data_process("{}/dev.json".format(data_dir), "trigger")
write_by_lines("{}/dev.tsv".format(trigger_save_dir), dev_tri)
test_tri = data_process("{}/test.json".format(data_dir), "trigger")
write_by_lines("{}/test.tsv".format(trigger_save_dir), test_tri)
print("train {} dev {} test {}".format(
len(train_tri), len(dev_tri), len(test_tri)))
print("\n----role------for dir {} to {}".format(data_dir, role_save_dir))
train_role = data_process("{}/train.json".format(data_dir), "role")
write_by_lines("{}/train.tsv".format(role_save_dir), train_role)
dev_role = data_process("{}/dev.json".format(data_dir), "role")
write_by_lines("{}/dev.tsv".format(role_save_dir), dev_role)
test_role = data_process("{}/test.json".format(data_dir), "role")
write_by_lines("{}/test.tsv".format(role_save_dir), test_role)
print("train {} dev {} test {}".format(
len(train_role), len(dev_role), len(test_role)))
print("=================end schema process==============")
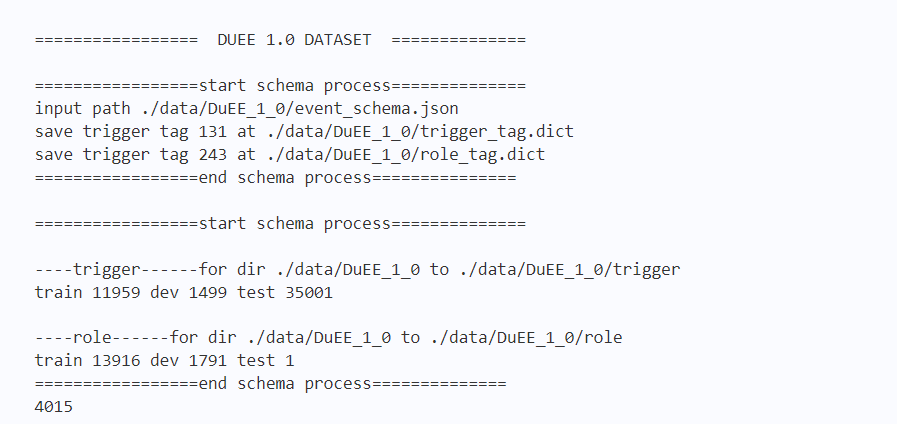
vocab = get_vocab()
vocab_size = len(list(vocab))
# print(vocab)
print(vocab_size)
输出结果如下图2所示:
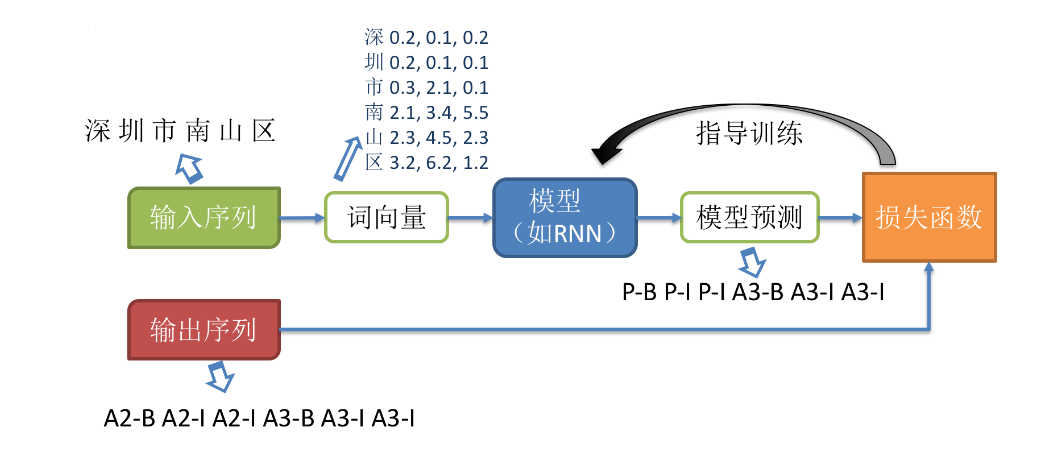
二、定义LSTM模型
随着深度学习的发展,目前主流的序列化标注任务基于词向量(word embedding)进行表示学习。下面介绍模型的整体训练流程如下:
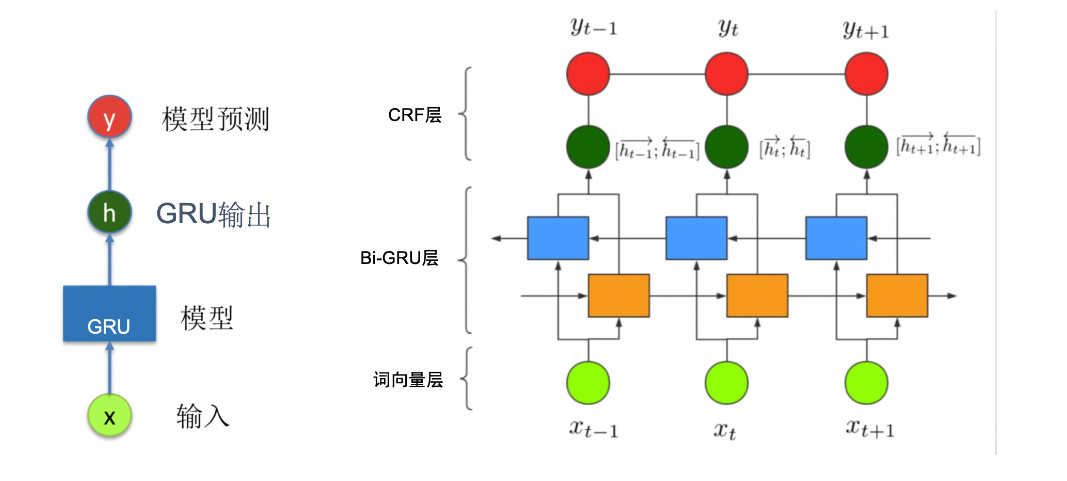
序列标注任务常用的模型是RNN+CRF。GRU和LSTM都是常用的RNN单元。这里我们以Bi-LSTM+CRF模型为例,介绍如何使用 PaddlePaddle 定义序列化标注任务的网络结构。如下图所示,LSTM的输出可以作为 CRF 的输入,最后 CRF 的输出作为模型整体的预测结果。
class LSTM_Model(nn.Layer):
def __init__(self,vocab_num, emb_size, hidden_size, num_layers, num_labels, dropout):
super(LSTM_Model, self).__init__()
self.embedding = nn.Embedding(vocab_num, emb_size)
self.lstm = nn.LSTM(emb_size, hidden_size, num_layers=num_layers, direction='bidirect', dropout=dropout)
self.attention_linear = nn.Linear(hidden_size * 2, hidden_size)
self.linear = nn.Linear(hidden_size * 2, num_labels)
self.dropout = nn.Dropout(dropout)
def forward(self,input_ids,target=None):
token_emb = self.embedding(input_ids)
sequence_output, (hidden, cell) = self.lstm(token_emb) # [batch_size,time_steps,num_directions * hidden_size]
sequence_output = self.dropout(sequence_output)
logits = self.linear(sequence_output)
# feature_out = fluid.layers.fc(input=hidden_1, size=len(label_dict), act='tanh')
# 调用内置 CRF 函数并做状态转换解码.
# if target is not None:
# crf_cost = fluid.layers.linear_chain_crf(
# input=paddle.reshape(logits,[-1,logits.shape[-1]]), label=paddle.reshape(target,[-1,1]),
# param_attr=fluid.ParamAttr(name='crfw1', learning_rate=0.0001))
# avg_cost = fluid.layers.mean(crf_cost)
# else:
# avg_cost = 0
avg_cost = 0
return logits, avg_cost
三、定义训练框架
定义网络结构后,需要配置优化器、损失函数、评价指标。
评价指标
针对每条序列样本的预测结果,序列标注任务将预测结果按照语块(chunk)进行结合并进行评价。评价指标通常有 Precision、Recall 和 F1。
- Precision,精确率,也叫查准率,由模型预测正确的个数除以模型总的预测的个数得到,关注模型预测出来的结果准不准
- Recall,召回率,又叫查全率, 由模型预测正确的个数除以真实标签的个数得到,关注模型漏了哪些东西
- F1,综合评价指标,计算公式如下, F 1 = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F1 = \frac{2*Precision*Recall}{Precision+Recall} F1=Precision+Recall2∗Precision∗Recall,同时考虑 Precision 和 Recall ,是 Precision 和 Recall 的折中。
paddlenlp.metrics中集成了ChunkEvaluator评价指标,并逐步丰富中,
# 定义训练框架
num_epoch = 10
learning_rate=0.0001
tag_path = './data/DuEE_1_0/'
data_dir = './data/DuEE_1_0/trigger'
train_data = './data/DuEE_1_0/trigger/train.tsv'
dev_data = './data/DuEE_1_0/trigger/dev.tsv'
test_data = './data/DuEE_1_0/trigger/test.tsv'
predict_data = './data/DuEE_1_0/duee_test.json'
checkpoints = './data/DuEE_1_0/trigger/'
init_ckpt = './data/DuEE_1_0/trigger/best.pdparams'
weight_decay=0.01
warmup_proportion=0.1
max_seq_len=145
valid_step=100
skip_step=50
batch_size=32
predict_save_path=None
seed=1000
@paddle.no_grad()
def evaluate(model, criterion, metric, num_label, data_loader):
"""evaluate"""
model.eval()
metric.reset()
losses = []
for input_ids, labels, seq_lens in data_loader:
logits,_ = model(input_ids,labels)
loss = paddle.mean(criterion(logits.reshape([-1, num_label]), labels.reshape([-1])))
losses.append(loss.numpy())
preds = paddle.argmax(logits, axis=-1)
n_infer, n_label, n_correct = metric.compute(None, seq_lens, preds, labels) # metric.compute(None, seq_lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
precision, recall, f1_score = metric.accumulate()
avg_loss = np.mean(losses)
model.train()
return precision, recall, f1_score, avg_loss
def word2id(line,vocab,max_len=145):
r = []
for c in line:
if c not in vocab:
r.append(vocab['<unk>'])
else:
r.append(vocab[c])
r =r[:max_len]
lens = len(r)
r = r+[0]*(max_len-len(r))
# print('----------------')
# print(line,r)
return r,lens
def convert_example_to_feature(example, label_vocab=None, max_seq_len=145, no_entity_label="O",
ignore_label=-1, is_test=False):
tokens, labels, seq_len = example
input_ids,seq_lens = word2id(tokens,vocab)
if is_test:
return input_ids,seq_lens
elif label_vocab is not None:
encoded_label = labels[:seq_lens]
encoded_label = [label_vocab[x] for x in encoded_label]
encoded_label = encoded_label + [-1]*(max_seq_len-min(seq_lens,145) )
# print('++++++++++++++++++++++++++++')
# print(labels,encoded_label)
# print('++++++++++++++++++++++++++++')
return input_ids, encoded_label, seq_lens
class DuEventExtraction(paddle.io.Dataset):
"""DuEventExtraction"""
def __init__(self, data_path, tag_path):
self.label_vocab = load_dict(tag_path)
self.word_ids = []
self.label_ids = []
self.seq_lens = []
with open(data_path, 'r', encoding='utf-8') as fp:
# skip the head line
next(fp)
for line in fp.readlines():
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
self.word_ids.append(words)
self.label_ids.append(labels)
self.seq_lens.append(len(words[:145]))
self.label_num = max(self.label_vocab.values()) + 1
def __len__(self):
return len(self.word_ids)
def __getitem__(self, index):
return self.word_ids[index], self.label_ids[index], self.seq_lens[index]
def do_train():
paddle.set_device('cpu')
no_entity_label = "O"
ignore_label = -1
label_map = load_dict(tag_path)
id2label = {val: key for key, val in label_map.items()}
vocab_num, emb_size, hidden_size, num_layers, num_labels, dropout = \
vocab_size,256,256,2,len(list(id2label)),0.1
model = LSTM_Model(vocab_num, emb_size, hidden_size, num_layers, num_labels, dropout)
print("============start train==========")
train_ds = DuEventExtraction(train_data, tag_path)
dev_ds = DuEventExtraction(dev_data, tag_path)
test_ds = DuEventExtraction(test_data, tag_path)
trans_func = partial(
convert_example_to_feature,
label_vocab=train_ds.label_vocab,
max_seq_len=max_seq_len,
no_entity_label=no_entity_label,
ignore_label=ignore_label,
is_test=False)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=0), # input ids
Pad(axis=0, pad_val=ignore_label), # labels
Stack() # seq_lens
): fn(list(map(trans_func, samples)))
batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=batch_size, shuffle=True)
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=batch_sampler,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=batch_size,
collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_size=batch_size,
collate_fn=batchify_fn)
num_training_steps = len(train_loader) * num_epoch
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=learning_rate,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
metric = ChunkEvaluator(label_list=train_ds.label_vocab.keys(), suffix=False)
criterion = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
# print(ignore_label)
step, best_f1 = 0, 0.0
model.train()
for epoch in range(num_epoch):
for idx, (input_ids,labels,seq_lens) in enumerate(train_loader):
# print(input_ids[0],labels[0])
logits,_= model(input_ids,labels)
probs_ids = paddle.argmax(logits, -1).numpy()
# print(logits.shape,labels.shape)
logits = logits.reshape([-1, train_ds.label_num])
loss = paddle.mean(criterion(logits, labels.reshape([-1])))
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_item = loss.numpy().item()
if step > 0 and step % skip_step == 0:
# print(probs_ids )
print(f'train epoch: {epoch} - step: {step} (total: {num_training_steps}) - loss: {loss_item:.6f}')
if step > 0 and step % valid_step == 0:
p, r, f1, avg_loss = evaluate(model, criterion, metric, len(label_map), dev_loader)
print(f'dev step: {step} - loss: {avg_loss:.5f}, precision: {p:.5f}, recall: {r:.5f}, ' \
f'f1: {f1:.5f} current best {best_f1:.5f}')
if f1 > best_f1:
best_f1 = f1
print(f'==============================================save best model ' \
f'best performerence {best_f1:5f}')
paddle.save(model.state_dict(), '{}/best.pdparams'.format(checkpoints))
step += 1
# save the final model
paddle.save(model.state_dict(), '{}/final.pdparams'.format(checkpoints))
def do_predict():
paddle.set_device('cpu')
no_entity_label = "O"
ignore_label = -1
label_map = load_dict(tag_path)
id2label = {val: key for key, val in label_map.items()}
vocab_num, emb_size, hidden_size, num_layers, num_labels, dropout = \
vocab_size,256,256,2,len(list(id2label)),0.1
model = LSTM_Model(vocab_num, emb_size, hidden_size, num_layers, num_labels, dropout)
print("============start predict==========")
if not init_ckpt or not os.path.isfile(init_ckpt):
raise Exception("init checkpoints {} not exist".format(init_ckpt))
else:
state_dict = paddle.load(init_ckpt)
model.set_dict(state_dict)
print("Loaded parameters from %s" % init_ckpt)
# load data from predict file
sentences = read_by_lines(predict_data) # origin data format
sentences = [json.loads(sent) for sent in sentences]
encoded_inputs_list = []
for sent in sentences:
sent = sent["text"].replace(" ", "\002")
input_ids = convert_example_to_feature([list(sent), [],len(sent)], max_seq_len=max_seq_len, is_test=True)
encoded_inputs_list.append((input_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=0), # input_ids
Stack()
): fn(samples)
# Seperates data into some batches.
batch_encoded_inputs = [encoded_inputs_list[i: i + batch_size]
for i in range(0, len(encoded_inputs_list),batch_size)]
results = []
model.eval()
for batch in batch_encoded_inputs:
input_ids,seq_lens= batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
# token_type_ids = paddle.to_tensor(token_type_ids)
logits,_ = model(input_ids)
probs = F.softmax(logits, axis=-1)
probs_ids = paddle.argmax(probs, -1).numpy()
probs = probs.numpy()
for p_list, p_ids, seq_len in zip(probs.tolist(), probs_ids.tolist(), seq_lens.tolist()):
prob_one = [p_list[index][pid] for index, pid in enumerate(p_ids[1: seq_len - 1])]
label_one = [id2label[pid] for pid in p_ids[1: seq_len - 1]]
results.append({"probs": prob_one, "labels": label_one})
assert len(results) == len(sentences)
print(results[:10])
for sent, ret in zip(sentences, results):
sent["pred"] = ret
sentences = [json.dumps(sent, ensure_ascii=False) for sent in sentences]
print(sentences[:10])
# write_by_lines(predict_save_path, sentences)
# print("save data {} to {}".format(len(sentences), predict_save_path))
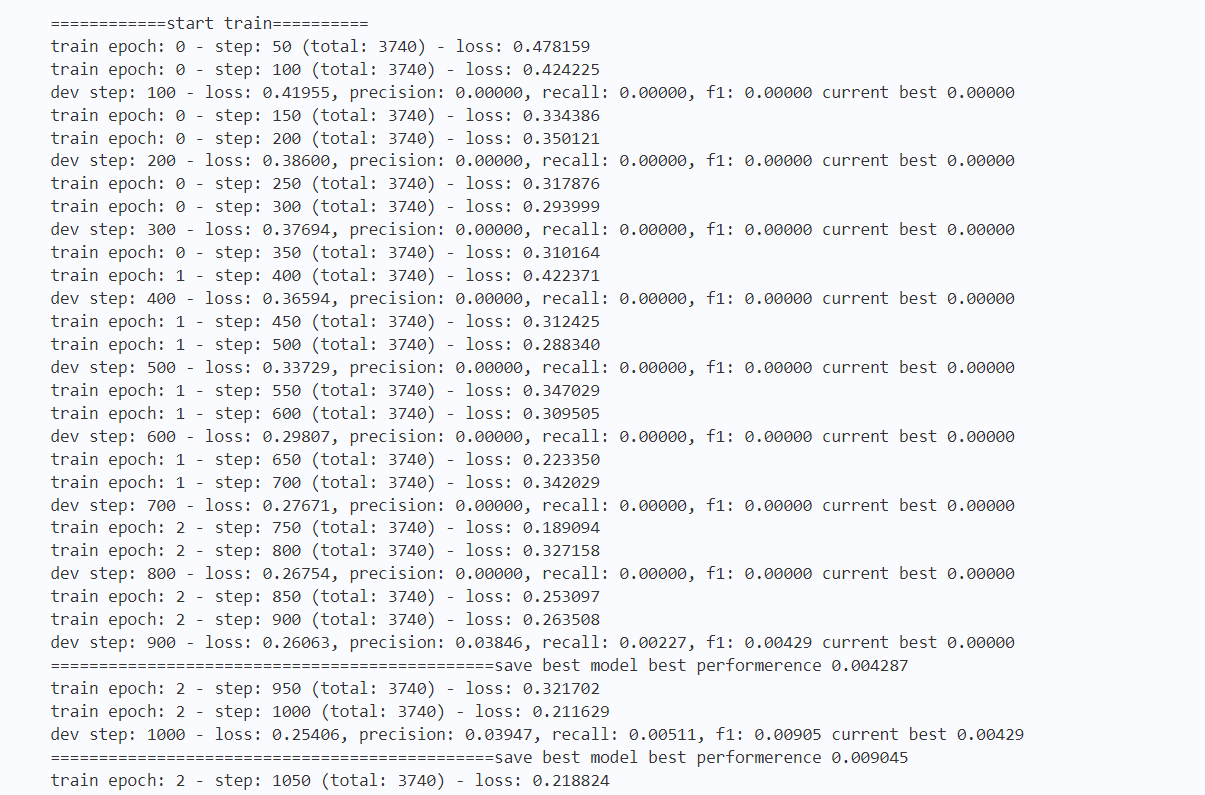
四、模型训练及预测1
## 训练ner
num_epoch = 10
base_dir = 'DuEE_1_0'
tag_path = './data/{}/trigger_tag.dict'.format(base_dir)
data_dir = './data/{}/trigger'.format(base_dir)
train_data = './data/{}/trigger/train.tsv'.format(base_dir)
dev_data = './data/{}/trigger/dev.tsv'.format(base_dir)
test_data = './data/{}/trigger/test.tsv'.format(base_dir)
predict_data = './data/{}/test.json'.format(base_dir)
checkpoints = './data/{}/trigger/'.format(base_dir)
init_ckpt = './data/{}/trigger/final.pdparams'.format(base_dir)
do_train()
do_predict()
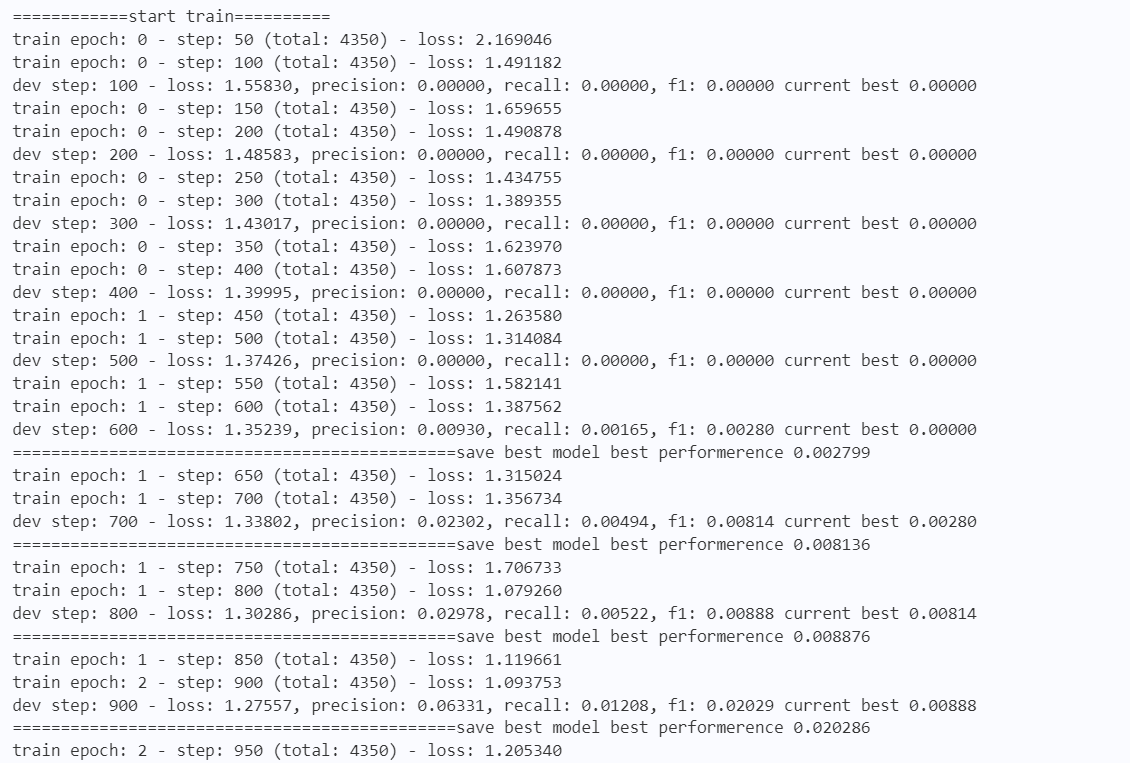
输出结果如下图4所示:
五、模型训练及预测2
代码如下:
## 训练ee
num_epoch = 10
tag_path = './data/{}/role_tag.dict'.format(base_dir)
data_dir = './data/{}/role'.format(base_dir)
train_data = './data/{}/role/train.tsv'.format(base_dir)
dev_data = './data/{}/role/dev.tsv'.format(base_dir)
test_data = './data/{}/role/test.tsv'.format(base_dir)
predict_data = './data/{}/test.json'.format(base_dir)
checkpoints = './data/{}/role/'.format(base_dir)
init_ckpt = './data/{}/role/final.pdparams'.format(base_dir)
do_train()
do_predict()
输出结果如下图5所示:
总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~