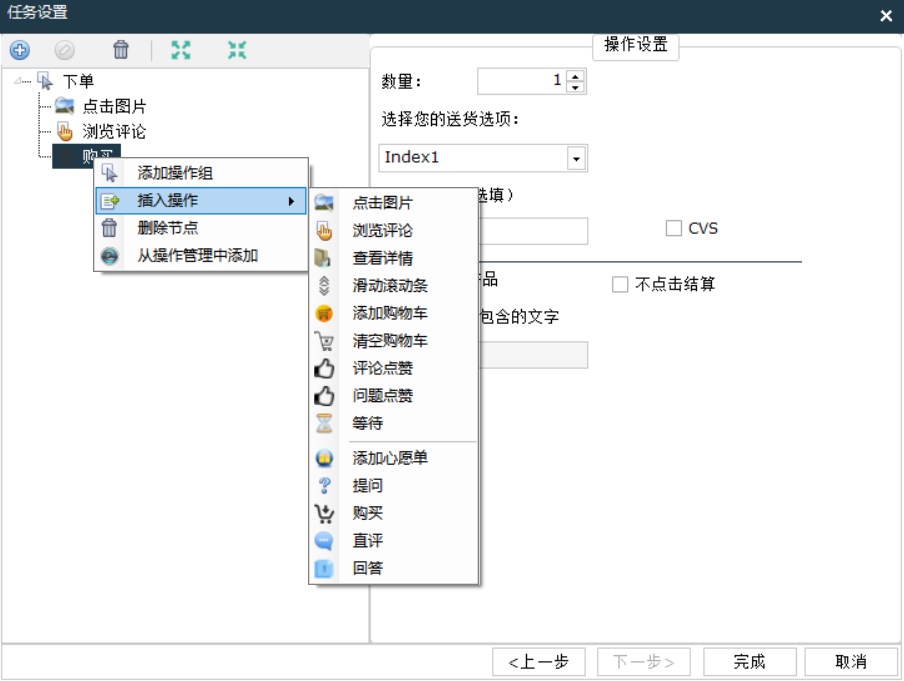
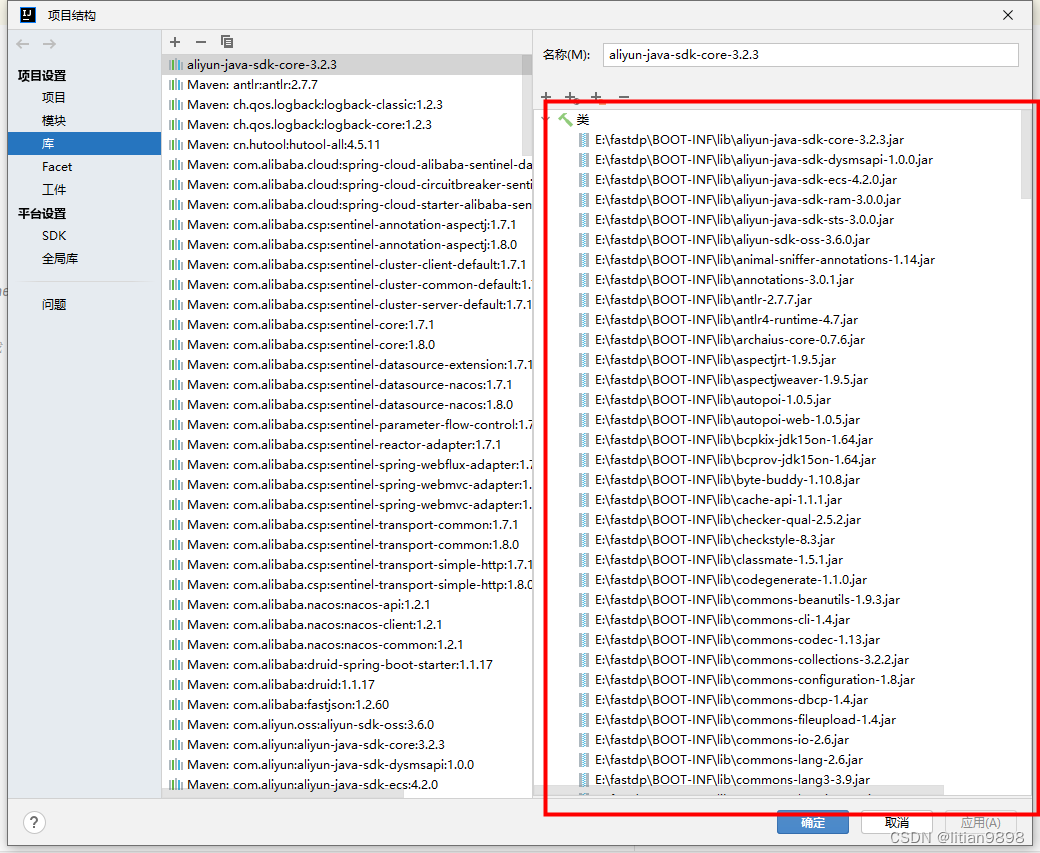
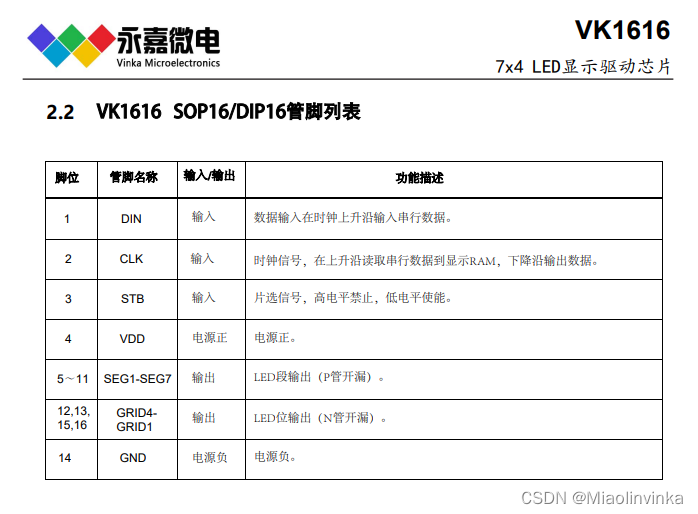
Embedding 向量适合作为一个中间结果,用于传统的机器学习场景,比如分类、聚类。
Completion 接口,一方面可以直接拿来作为一个聊天机器人,另一方面,你只要善用提示词,就能完成合理的文案撰写、文本摘要、机器翻译等一系列的工作。
我们之前都是网上查找数据集或者openAI提供的数据集进行处理,这里我们可以利用AI给我们生成数据,我们根据它生成的数据进行搜索,推荐等处理。
接下来让AI帮我们搜索给我们今天要测试的数据集
1 让 AI 生成实验数据
让它给我们淘宝网里商品的标题,要求每条名称30字左右,数码类产品,每行一条
! pip install openai
! pip install os
import openai,os
openai.api_key=''
COMPLETION_MODEL = "text-davinci-003"
# 调用openAI
def generate_data_by_prompt(prompt):
response=openai.Completion.create(
engine=COMPLETION_MODEL,
prompt=prompt,
temperature=0.5,
max_tokens=2048,
top_p=1,
)
return response.choices[0].text
prompt="""
请你生成50条淘宝网里的商品的标题,每条在30个字左右,品类是3C数码产品,标题里往往也会有一些促销类的信息,每行一条。
"""
data=generate_data_by_prompt(prompt)
print(data)反馈的结果:
1.【新品上市】Apple/苹果 iPhone 11 Pro Max 手机
2.【现货特价】华为Mate 30 Pro 5G手机
3.【抢购优惠】小米MIX Alpha智能折叠手机
4.【热卖爆款】三星Galaxy Note 10 Plus 旗舰手机
5.【限时促销】荣耀V30 Pro 5G超薄手机
6.【时尚潮流】OPPO Reno 10X Zoom双摄手机
7.【新品特惠】vivo NEX 3 5G超级旗舰手机
8.【超值优惠】联想Z6 Pro 5G游戏手机
9.【热销精品】金立S10 Pro 5G 全面屏手机
10.【抢购热卖】魅族16s Pro 全面屏手机
11.【热卖抢购】荣耀20 Pro 5G超薄手机
12.【爆款热销】Apple/苹果 iPhone 11 手机
13.【特价热卖】华为P30 Pro 全面屏手机
14.【新品优惠】三星Galaxy S10 Plus 旗舰手机
15.【限时特惠】OPPO Reno 10X 折叠手机
16.【时尚潮流】vivo iQOO Pro 5G超级旗舰手机
17.【新品特价】联想Z5 Pro 5G全面屏手机
18.【超值促销】金立S10 5G 全面屏手机
19.【抢购热卖】魅族16s 全面屏手机
20.【热销特惠】荣耀20 5G超薄手机
21.【爆款特价】Apple/苹果 iPhone XS Max 手机
22.【特价热卖】华为Mate 20 Pro 5G手机
23.【新品优惠】小米MIX 3 智能折叠手机
24.【热卖爆款】三星Galaxy Note 9 Plus 旗舰手机
25.【限时促销】荣耀V20 Pro 5G超薄手机
26.【时尚潮流】OPPO Reno 8X Zoom双摄手机
27.【新品特惠】vivo NEX 3S 5G超级旗舰手机
28.【超值优惠】联想Z6 5G游戏手机
29.【热销精品】金立S10 5G 全面屏手机
30.【抢购热卖】魅族16s Plus 全面屏手机
31.【热卖抢购】荣耀20 5G超薄手机
32.【爆款热销】Apple/苹果 iPhone XR 手机
33.【特价热卖】华为P20 Pro 全面屏手机
34.【新品优惠】三星Galaxy S9 Plus 旗舰手机
35.【限时特惠】OPPO Reno 8 折叠手机
36.【时尚潮流】vivo iQOO 5G超级旗舰手机
37.【新品特价】联想Z5 5G全面屏手机
38.【超值促销】金立S10 Pro 5G 全面屏手机
39.【抢购热卖】魅族16 Plus 全面屏手机
40.【热销特惠】荣耀20 Pro 5G超薄手机
41.【爆款特价】Apple/苹果 iPhone X 手机
42.【特价热卖】华为Mate 10 Pro 5G手机
43.【新品优惠】小米MIX 2S智能折叠手机
44.【热卖爆款】三星Galaxy Note 8 Plus 旗舰手机
45.【限时促销】荣耀V10 Pro 5G超薄手机
46.【时尚潮流】OPPO Reno 7X Zoom双摄手机
47.【新品特惠】vivo NEX 2 5G超级旗舰手机
48.【超值优惠】联想Z4 Pro 5G游戏手机
49.【热销精品】金立S10 Plus 5G 全面屏手机
50.【抢购热卖】魅族16 全面屏手机我们将给的数据处理下,改成我们能处理的数据,将数据转换为DataFrame,并起一个key名为product_name。
!pip install pandas
import pandas as pd
# 按行分割,strip()函数去掉两边的空白
product_names=data.strip().split("\n")
# 将数据存储成行列,列名为product_name
df=pd.DataFrame({'product_name':product_names})
# 显示前几行数据
df.head()结果如下:

我们看到它返回的数据都自带了编号,我们把编号去掉,不要它标题的编号:
# 去掉列里自带的编号,apply()函数用于对DataFrame的一列(Series)中的每个元素应用一个函数。然后匿名函数处理列里数据
# 列里根.字符进行分割,取索引1的数据就可。最后赋值给远列product_name
df.product_name=df.product_name.apply(lambda x: x.split('.')[1].strip())
df.head()结果:

我们再获取一些女装,也是用上边的方式,方便后面实验测试数据
clothes_prompt = """请你生成50条淘宝网里的商品的标题,每条在30个字左右,品类是女性的服饰箱包等等,标题里往往也会有一些促销类的信息,每行一条。"""
clothes_data = generate_data_by_prompt(clothes_prompt)
clothes_product_names=clothes_data.strip().split('\n')
clothes_df=pd.DataFrame({'product_name':clothes_product_names})
clothes_df.product_name= clothes_df.product_name.apply(lambda x: x.split('.')[1].strip())
clothes_df.head()查看结果:用head取出前5条数据

将上面得到的数码产品和女士服饰箱包这两种数据合并一起,方便后续搜索数据处理:
#把这两个 DataFrame 拼接在一起,就是我们接下来用于做搜索实验的数据。
# concat()此函数用来合并,方式为axis=0按行合并
df = pd.concat([df, clothes_df], axis=0)
# 重制索引。drop=True对原来的索引采取丢弃操作,保留重制后的索引
df=df.reset_index(drop=True)
display(df)得到结果:你会发现 AI 有时候返回的条数没有 50 条,不过没有关系,这个基本不影响我们使用这个数据源。你完全可以多运行几次,获得足够你需要的数据。

然后我们把这些数据通过Embedding转成向量,用于计算相似度搜索~
我们还是利用 backoff 和 batch 处理,让代码能够容错,并且快速处理完这些商品标题。
!pip install openai
!pip install os
!pip install backoff
import openai
import os
import backoff
import pandas as pd
from openai.embeddings_utils import get_embeddings
openai.api_key = ''
embedding_model = "text-embedding-ada-002"
batch_size = 100
# 在线colab加上此注解报错,所以在去掉了,你可以测试下你的环境可不可以
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def get_embeddings_with_backoff(prompts, engine):
print("len(prompts):",len(prompts))
embeddings = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
print("第二个batch数据:",batch)
embeddings += get_embeddings(list_of_text=batch, engine=engine)
return embeddings
prompts = df.product_name.tolist()
prompt_batches = [prompts[i:i+batch_size] for i in range(0, len(prompts), batch_size)]
print("prompt_batches:",prompt_batches)
embeddings = []
for batch in prompt_batches:
print("第一个batch数据:",batch)
batch_embeddings = get_embeddings_with_backoff(prompts=batch, engine=embedding_model)
embeddings += batch_embeddings
df["embedding"] = embeddings
df.to_parquet("taobao_product_title.parquet", index=False)将数据转换成向量数据完毕!
2 通过 Embedding 进行语义搜索
然后我们就可以写搜索产品的代码啦,主要通过关键字进行搜索,将关键搜索词转换成向量,因为我们的数据源已经转换成向量了,所以计算两个向量的相似度以后得到数据,并将数据返回即可。
# 搜索商品逻辑-----------------------------------------------------------------
from openai.embeddings_utils import get_embedding, cosine_similarity
# 第一个参数df代表要搜索的数据源,在colab有上下文的
# 第二个参数query代表是搜索关键词
# 第三个参数n代表返回多少条记录
# pprint 是一个布尔值,控制是否打印结果,默认为 True。
def search_product(df,query,n=3,pprint=True):
# 获取给定文本的嵌入向量,采用此模型计算查询
produce_embedding=get_embedding(
query,
engine=embedding_model,
)
# 计算embedding与produce_embedding相似度,采用余弦相似度来衡量查询与个产品之间的相似度,并把结果存储到df["similarity"]列中
df["similarity"]=df.embedding.apply(lambda x: cosine_similarity(x,produce_embedding))
# 按照相似度降序排列,然后选取前n个产品,并提他们的产品名称
# ascending是用于排序的,True为正序,False为倒序
# 它会根据"similarity"列的值找到相似度最高的n个产品,并返回它们的产品名称。
results=(
df.sort_values("similarity",ascending=False)
.head(n)
.product_name
)
# pprint为True,则会打印每个匹配结果的产品
if pprint:
for r in results:
print(r)
return results
results=search_product(df,"自然淡雅书包",n=3)结果内容:
【新款】时尚简约女士手提包,柔软质感更耐用!
【新款】简约时尚女士手提包,柔软质感更耐用!
【特惠】精致简约女士手提包,潮流时尚更显靓丽!我们可以试下搜索手机
results=search_product(df,"华为手机",n=3)结果:
【新品上市】华为Mate 30 5G 智能手机
【新品上市】华为P40 Pro 5G 智能手机
【热销爆款】华为Mate 30 Pro 5G 智能手机简简单单就以向量的方式做了一个搜索检查。
3 利用 Embedding 信息进行商品推荐的冷启动
什么是冷启动,在新的用户或新的商品的情况下,因为没有历史数据作为佐证,无法准确的评估推荐到每一个人,所以就需要,通过合理的策略和算法,推荐系统可以在没有量历史数据的情况下,为新用户和新商品提供有针对性的推荐,从而提高推荐的准确性和个性化程度。
咱们这里只要是搜索过这个商品的话就给推荐相似商品
这个和上面的搜索代码类似,唯一不同的是,上面的代码给出搜索关键字以后又去找openai调用获取向量,咱们这个直接对比标题内容以后从列中取出向量,没必要浪费去查一次,然后再对比相似度,代码如下:
也就是说我们给的关键字是存在于数据源中的(此处需要与原数据中的产品名称一模一样否则取不出向量会报错)那么可以直接在原数据中产品名称对比,如果一样取出当前产品名称的向量即可。
def recommend_product(df,product_name,n=3,pprint=True):
product_embedding = df[df['product_name'] == product_name].iloc[0].embedding
df['similarity']=df.embedding.apply(lambda x: cosine_similarity(x,product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.product_name
)
if pprint:
for r in results:
print(r)
return results
results=recommend_product(df,"【新品上市】苹果iPhone 11 Pro Max全网通手机",n=3)结果内容:这样一个新的商品根据语义相似度,就能推荐对应商品。
【新品上市】苹果iPhone 11 Pro Max全网通手机
【新品上市】苹果iPhone 11 Pro 512GB全网通手机
【新品上市】苹果iPhone 11 256GB全网通手机4 通过 FAISS 加速搜索过程
先把向量数据加载到faiss里,为什么呢,因为面对大数据量我们每次都要计算距离,那速度肯定是慢的不行,所以可以利用一些向量数据库,或者能够快速搜索相似性的软件包就可以了,比如,我比较推荐你使用 Facebook 开源的 Faiss 这个 Python 包,它的全称就是 Facebook AI Similarity Search,也就是快速进行高维向量的相似性搜索。
把索引加载到 Faiss 里面非常容易,我们直接把整个的 Embedding 变成一个二维矩阵,整个加载到 Faiss 里面就好了。
!pip install faiss-gpu
!pip install numpy
import faiss
import numpy as np
def load_embeddings_to_faiss(df):
# (DataFrame)中的嵌入(embedding)列转换为一个浮点型的 NumPy 数组(numpy array)
# df['embedding'].tolist():将数据框中名为 "embedding" 的列转换为 Python 列表。
# np.array(...):将 Python 列表转换为 NumPy 数组。
# astype('float32'):将数组中的元素类型转换为浮型(32 位浮点数)。
embeddings = np.array(df['embedding'].tolist()).astype('float32')
# 创建了一个 Faiss 的索引对象,用于存储商品embeddings,embeddings.shape[1]=embeddings数组的第二个维度的大小
index = faiss.IndexFlatL2(embeddings.shape[1])
# embeddings加入到索引中,以便可以使用 Faiss 进行快速的相似度搜索
index.add(embeddings)
return index
index = load_embeddings_to_faiss(df)
print("index:",index)然后用这种方式搜索下,围绕着index搜索,需要把我们的关键搜索词转换为向量,再转换为numpy数组,通过reshape转换为二维数组,其实和上边没什么区别,目的还是为了数据都是在一个维度上进行对比。然后经过处理的数据传入index的search函数里进行搜索,搜索出k个相同的数据,并返回
通过faiss搜索,代码如下:
def search_index(index, df, query, k=5):
# reshape转换为二维数组,
query_vector = np.array(get_embedding(query, engine=embedding_model)).reshape(1, -1).astype('float32')
# 搜索与query_vector 最相似的 k 个向量返回的结果一个包含两个数组的元组
# 第一个是最相似的向量与 query_vector 之间的距离
# 第二个数组是最相似的向量在索引中的索引位置
distances, indexes = index.search(query_vector, k)
print("distances:",distances)
print("indexes",indexes)
# 封装返回结果
results = []
for i in range(len(indexes)):
product_names = df.iloc[indexes[i]]['product_name'].values.tolist()
print('for product_names :',product_names)
results.append((distances[i], product_names))
return results
products = search_index(index, df, "自然淡雅背包", k=3)
print("products:",products)
# 将得到的结果解析打印
for distances, product_names in products:
print("distances:",distances)
for i in range(len(distances)):
print(product_names[i], distances[i])结果如下:Faiss 的原理,是通过 ANN 这样的近似最近邻的算法,快速实现相似性的搜索。
distances: [[0.21429113 0.21453398 0.22011249]]
indexes [[ 90 140 112]]
for product_names : ['【新款】优雅百搭女士单肩包', '【新款】优雅百搭女士单肩包', '【新款】优雅百搭女士手拿包']
products: [(array([0.21429113, 0.21453398, 0.22011249], dtype=float32), ['【新款】优雅百搭女士单肩包', '【新款】优雅百搭女士单肩包', '【新款】优雅百搭女士手拿包'])]
distances: [0.21429113 0.21453398 0.22011249]
【新款】优雅百搭女士单肩包 0.21429113
【新款】优雅百搭女士单肩包 0.21453398
【新款】优雅百搭女士手拿包 0.22011249本章视频说明:AI大模型-巧用Embedding实现搜索和推荐功能_哔哩哔哩_bilibili
本文根据徐文浩老师的《AI大模型之美》 整理记录