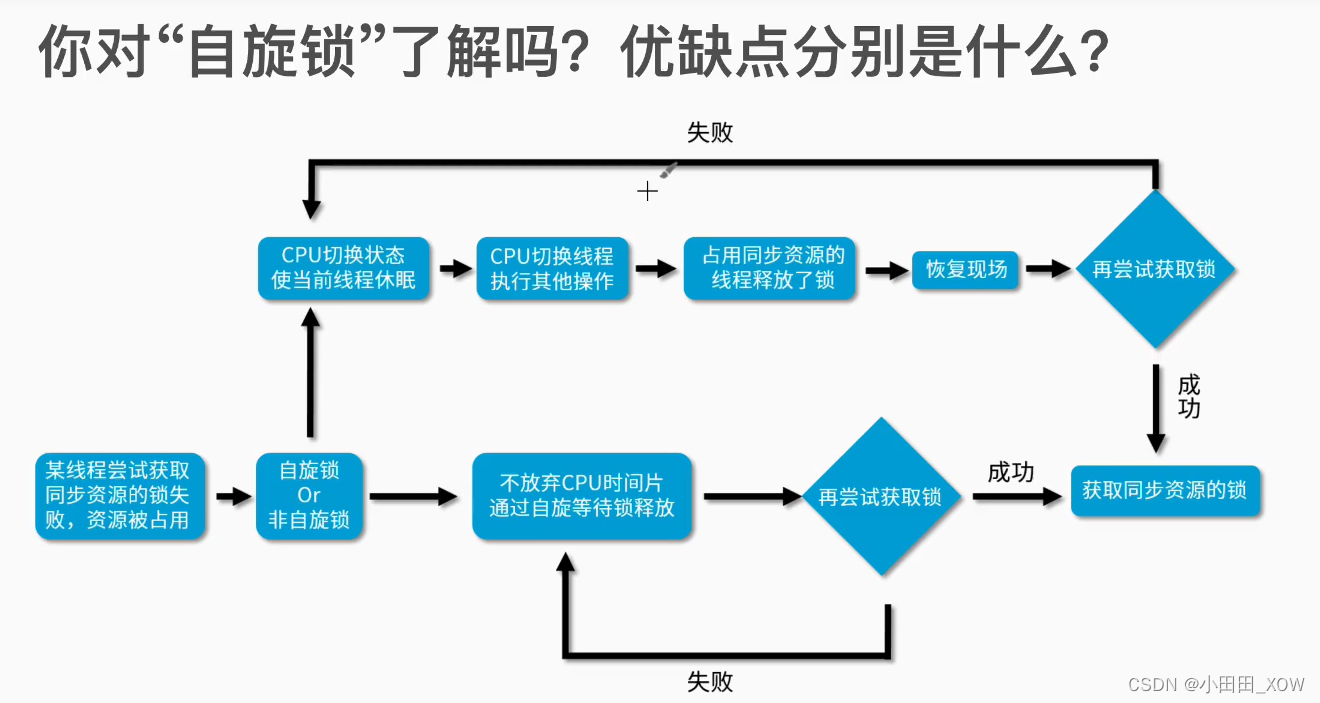
优点:
- 1. 自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗 ,这些操作会导致线程发生两次上下文切换!
- 2.非自旋锁在获取不到锁的时候会进入阻塞状态 ,从而进入内核态,当获取到锁的时候需要从内核态恢复,需要线程上下文切换。 (线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能)
缺点:
- 1. 但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用 cpu 做无用功,占着 XX 不 XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要 cpu 的线程又不能获取到 cpu,造成 cpu 的浪费。所以这种情况下我们要关闭自旋锁。
- 2.上面Java实现的自旋锁不是公平的,即无法满足等待时间最长的线程优先获取锁。不公平的锁就会存在“线程饥饿”问题。
自旋锁的实现:
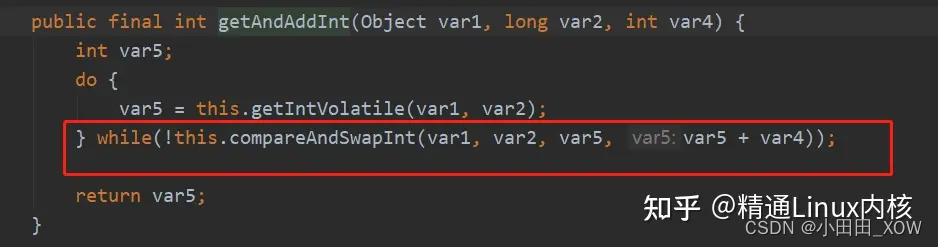
最明显的案列:CAS 机制
这是 AtomicInteger 的一个底层实现。(源码)
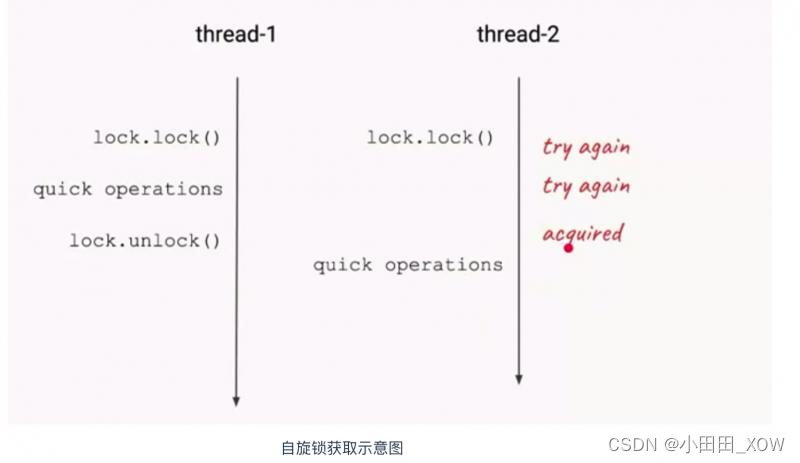
自旋锁与互斥锁
- 自旋锁与互斥锁都是为了实现保护资源共享的机制。
- 无论是自旋锁还是互斥锁,在任意时刻,都最多只能有一个保持者。
- 获取互斥锁的线程,如果锁已经被占用,则该线程将进入睡眠状态;获取自旋锁的线程则不会睡眠,而是一直循环等待锁释放。
自旋锁的实现
下面我们用Java 代码来实现一个简单的自旋锁
public class SpinLockTest {
private AtomicBoolean available = new AtomicBoolean(false);
public void lock(){
// 循环检测尝试获取锁
while (!tryLock()){
// doSomething...
}
}
public boolean tryLock(){
// 尝试获取锁,成功返回true,失败返回false
return available.compareAndSet(false,true);
}
public void unLock(){
if(!available.compareAndSet(true,false)){
throw new RuntimeException("释放锁失败");
}
}
}
这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。对于上面的SpinlockTest,当多个线程想要获取锁时,谁最先将available设为false谁就能最先获得锁,这可能会造成某些线程一直都未获取到锁造成线程饥饿。就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁,通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫排队自旋锁(QueuedSpinlock)。计算机科学家们使用了各种方式来实现排队自旋锁,如TicketLock,MCSLock,CLHLock。接下来我们分别对这几种锁做个大致的介绍。
TicketLock
在计算机科学领域中,TicketLock 是一种同步机制或锁定算法,它是一种自旋锁,它使用ticket 来控制线程执行顺序。
就像票据队列管理系统一样。面包店或者服务机构(例如银行)都会使用这种方式来为每个先到达的顾客记录其到达的顺序,而不用每次都进行排队。通常,这种地点都会有一个分配器(叫号器,挂号器等等都行),先到的人需要在这个机器上取出自己现在排队的号码,这个号码是按照自增的顺序进行的,旁边还会有一个标牌显示的是正在服务的标志,这通常是代表目前正在服务的队列号,当前的号码完成服务后,标志牌会显示下一个号码可以去服务了。
像上面系统一样,TicketLock 是基于先进先出(FIFO) 队列的机制。它增加了锁的公平性,其设计原则如下:TicketLock 中有两个 int 类型的数值,开始都是0,第一个值是队列ticket(队列票据), 第二个值是 出队(票据)。队列票据是线程在队列中的位置,而出队票据是现在持有锁的票证的队列位置。可能有点模糊不清,简单来说,就是队列票据是你取票号的位置,出队票据是你距离叫号的位置。现在应该明白一些了吧。
当叫号叫到你的时候,不能有相同的号码同时办业务,必须只有一个人可以去办,办完后,叫号机叫到下一个人,这就叫做原子性。你在办业务的时候不能被其他人所干扰,而且不可能会有两个持有相同号码的人去同时办业务。然后,下一个人看自己的号是否和叫到的号码保持一致,如果一致的话,那么就轮到你去办业务,否则只能继续等待。上面这个流程的关键点在于,每个办业务的人在办完业务之后,他必须丢弃自己的号码,叫号机才能继续叫到下面的人,如果这个人没有丢弃这个号码,那么其他人只能继续等待。下面来实现一下这个票据排队方案
public class TicketLock {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
// 获取锁:如果获取成功,返回当前线程的排队号
public int lock(){
int currentTicketNum = dueueNum.incrementAndGet();
while (currentTicketNum != queueNum.get()){
// doSomething...
}
return currentTicketNum;
}
// 释放锁:传入当前排队的号码
public void unLock(int ticketNum){
queueNum.compareAndSet(ticketNum,ticketNum + 1);
}
}
每次叫号机在叫号的时候,都会判断自己是不是被叫的号,并且每个人在办完业务的时候,叫号机根据在当前号码的基础上 + 1,让队列继续往前走。
但是上面这个设计是有问题的,因为获得自己的号码之后,是可以对号码进行更改的,这就造成系统紊乱,锁不能及时释放。这时候就需要有一个能确保每个人按会着自己号码排队办业务的角色,在得知这一点之后,我们重新设计一下这个逻辑
public class TicketLock2 {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
private ThreadLocal<Integer> ticketLocal = new ThreadLocal<>();
public void lock(){
int currentTicketNum = dueueNum.incrementAndGet();
// 获取锁的时候,将当前线程的排队号保存起来
ticketLocal.set(currentTicketNum);
while (currentTicketNum != queueNum.get()){
// doSomething...
}
}
// 释放锁:从排队缓冲池中取
public void unLock(){
Integer currentTicket = ticketLocal.get();
queueNum.compareAndSet(currentTicket,currentTicket + 1);
}
}
这次就不再需要返回值(lock是void),办业务的时候,要将当前的这一个号码缓存起来,在办完业务后,需要释放缓存的这条票据。
缺点
TicketLock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量queueNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
为了解决这个问题,MCSLock 和 CLHLock 应运而生。
CLHLock
上面说到TicketLock 是基于队列的,那么 CLHLock 就是基于链表设计的,CLH的发明人是:Craig,Landin and Hagersten,用它们各自的字母开头命名。CLH 是一种基于链表的可扩展,高性能,公平的自旋锁,申请线程只能在本地变量上自旋,它会不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
public class CLHLock {
public static class CLHNode{
private volatile boolean isLocked = true;
}
// 尾部节点
private volatile CLHNode tail;
private static final ThreadLocal<CLHNode> LOCAL = new ThreadLocal<>();
private static final AtomicReferenceFieldUpdater<CLHLock,CLHNode> UPDATER =
AtomicReferenceFieldUpdater.newUpdater(CLHLock.class,CLHNode.class,"tail");
public void lock(){
// 新建节点并将节点与当前线程保存起来
CLHNode node = new CLHNode();
LOCAL.set(node);
// 将新建的节点设置为尾部节点,并返回旧的节点(原子操作),这里旧的节点实际上就是当前节点的前驱节点
CLHNode preNode = UPDATER.getAndSet(this,node);
if(preNode != null){
// 前驱节点不为null表示当锁被其他线程占用,通过不断轮询判断前驱节点的锁标志位等待前驱节点释放锁
while (preNode.isLocked){
}
preNode = null;
LOCAL.set(node);
}
// 如果不存在前驱节点,表示该锁没有被其他线程占用,则当前线程获得锁
}
public void unlock() {
// 获取当前线程对应的节点
CLHNode node = LOCAL.get();
// 如果tail节点等于node,则将tail节点更新为null,同时将node的lock状态职位false,表示当前线程释放了锁
if (!UPDATER.compareAndSet(this, node, null)) {
node.isLocked = false;
}
node = null;
}
}
MCSLock
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。MCS 来自于其发明人名字的首字母: John Mellor-Crummey和Michael Scott。
public class MCSLock {
public static class MCSNode {
volatile MCSNode next;
volatile boolean isLocked = true;
}
private static final ThreadLocal<MCSNode> NODE = new ThreadLocal<>();
// 队列
@SuppressWarnings("unused")
private volatile MCSNode queue;
private static final AtomicReferenceFieldUpdater<MCSLock,MCSNode> UPDATE =
AtomicReferenceFieldUpdater.newUpdater(MCSLock.class,MCSNode.class,"queue");
public void lock(){
// 创建节点并保存到ThreadLocal中
MCSNode currentNode = new MCSNode();
NODE.set(currentNode);
// 将queue设置为当前节点,并且返回之前的节点
MCSNode preNode = UPDATE.getAndSet(this, currentNode);
if (preNode != null) {
// 如果之前节点不为null,表示锁已经被其他线程持有
preNode.next = currentNode;
// 循环判断,直到当前节点的锁标志位为false
while (currentNode.isLocked) {
}
}
}
public void unlock() {
MCSNode currentNode = NODE.get();
// next为null表示没有正在等待获取锁的线程
if (currentNode.next == null) {
// 更新状态并设置queue为null
if (UPDATE.compareAndSet(this, currentNode, null)) {
// 如果成功了,表示queue==currentNode,即当前节点后面没有节点了
return;
} else {
// 如果不成功,表示queue!=currentNode,即当前节点后面多了一个节点,表示有线程在等待
// 如果当前节点的后续节点为null,则需要等待其不为null(参考加锁方法)
while (currentNode.next == null) {
}
}
} else {
// 如果不为null,表示有线程在等待获取锁,此时将等待线程对应的节点锁状态更新为false,同时将当前线程的后继节点设为null
currentNode.next.isLocked = false;
currentNode.next = null;
}
}
}
CLHLock 和 MCSLock
- 都是基于链表,不同的是CLHLock是基于隐式链表,没有真正的后续节点属性,MCSLock是显示链表,有一个指向后续节点的属性。
- 将获取锁的线程状态借助节点(node)保存,每个线程都有一份独立的节点,这样就解决了TicketLock多处理器缓存同步的问题。
总结
此篇文章我们主要讲述了自旋锁的提出背景,自旋锁是为了提高资源的使用频率而出现的一种锁,自旋锁说的是线程获取锁的时候,如果锁被其他线程持有,则当前线程将循环等待,直到获取到锁。
自旋锁在等待期间不会睡眠或者释放自己的线程。自旋锁不适用于长时间持有CPU的情况,这会加剧系统的负担,为了解决这种情况,需要设定自旋周期,那么自旋周期的设定也是一门学问。
还提到了自旋锁本身无法保证公平性,那么为了保证公平性又引出了TicketLock ,TicketLock 是采用排队叫号的机制来实现的一种公平锁,但是它每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
所以我们又引出了CLHLock和MCSLock,CLHLock和MCSLock通过链表的方式避免了减少了处理器缓存同步,极大的提高了性能,区别在于CLHLock是通过轮询其前驱节点的状态,而MCS则是查看当前节点的锁状态。
知识来源:
【并发与线程】你对“自旋锁”了解吗?优缺点分别是什么?_哔哩哔哩_bilibili
自旋锁 - 知乎
https://www.cnblogs.com/cxuanBlog/p/11679883.html