【目录】
文章目录
- 2. Series对象-一维数据
- 1. 知识回顾-创建字典
- 2. 调用库的类、函数、变量语法
- 3. 实例化类创建一个对象
- 4. Series一维数组
- 5. pd.Series创建一个Series对象
- 6. data = 列表
- 7. 同时传入data和index
- 8. data = 字典
- 9. Series对象的3要素:索引+数据+类型
- 9.1 data=列表,列表元素均为字符串
- 9.2 data=列表,列表元素均为字符串+整数
- 9.3 data=列表,列表元素均为整数
- 9.4 data=列表,列表元素均为浮点数
- 10. Series类的values和index属性
- 11. 利用index获取Series的索引
- 12. 利用values获取Series的值
- 13. 课堂练习
- 14. 总结
- 15. 课后练习
【正文】
2. Series对象-一维数据
【学习时间】
60分钟
1. 知识回顾-创建字典
【语法】
一个字典主要由5部分构成:
-
- 英文大括号
{ }
- 英文大括号
-
- 字典的键
-
- 键与值之间用英文冒号
:隔开
- 键与值之间用英文冒号
-
- 字典的值
-
- 键值对之间用英文逗号
,分隔
- 键值对之间用英文逗号

code_dict字典名。- 字典用
{ }大括号表示。注意集合也用{ }大括号表示。 北京是字典键。:英文冒号。100000是字典的值。'北京':100000称为一个键值对。- 2个键值对之间用英文逗号
,分隔。
【课堂练习】
创建一个字典。
字典的键为:姓名 和 性别。
姓名 对应的值是 ['张三', '李四', '王五']。
性别对应的值是 ['男','女','男']。
【代码示例】
# 字典的键为'姓名'和'年龄',
# 字典的值为['张三', '李四', '王五']、['男','女','男']
my_dict = {'姓名': ['张三', '李四', '王五'], '性别': ['男','女','男']}
# 打印字典
print(my_dict)
【终端输出】
{'姓名': ['张三', '李四', '王五'], '性别': ['男', '女', '男']}
2. 调用库的类、函数、变量语法
- 调用库的类:
库名.类名( ),如csv.DictReader() - 调用库的函数:
库名.函数名( ),如os.mkdir() - 调用库的变量:
库名.变量名,如os.name
【总结】
- 不管调用什么,库名后都需要紧跟一个英文小圆点
.。 - 调用类和函数需要加英文圆括号
( )。 - 调用变量不用加英文圆括号
( ),因为变量没有参数可以传递。
【课堂练习】
已知库名为pandas。
Series是pandas库的一个类。
请完善代码调用Series类。
【代码示例】
# 导入pandas库并简写为pd
import pandas as pd
# 调用库的类:库名.类名( )
# pd是库名,Series是类名
s = pd.Series()
3. 实例化类创建一个对象
在面向对象编程中,类是一个模板,而对象则是根据这个模板创建出来的具体实体。
通过实例化,我们可以使用类中定义的属性和方法来完成相应的操作。
【创建对象语法】
对象名 = 类名()
-
等号的左边是我们给创建对象起的名字。
-
等号右边写类名,表示这个对象是根据这个类生产出来的。
-
类名后紧跟一对英文圆括号
( )。
【查看对象属性语法】
对象名.属性名
属性是定义在类里的变量。
【课堂练习】
已知类名为Cars。
请用上述类创建一个aodi_A6 对象。
该对象的颜色属性为红色,车型属性为小轿车。
【代码示例】
# 定义一个车类,类名为Cars
class Cars:
# 直接写在类里的变量称为类属性
color= "红色"
type_1 = "小轿车"
# 创建对象
# 对象名 = 类名()
aodi_A6 = Cars( )
# 查看对象的属性
# 对象名.属性名
# aodi_A6是对象名,color是属性名
print(aodi_A6.color)
【终端输出】
红色
4. Series一维数组
pandas库的核心数据结构是两种类型的数据对象:Series和DataFrame。
Series[ˈsɪəriːz]:系列。
Series:一维数组。
【什么是Series数据?】
Series是pandas库中的一种数据结构,用于表示一维的标签化数据。
Series可以存储任意类型的数据。
Series的每个数据都会自动关联一个索引。
索引可以是数字或字符串。
【什么是一维数据?】
一维数据是指只有一个维度的数据集合。
一维数据通常表示为单行或单列的数据集,其中每个元素都可以通过索引来访问。
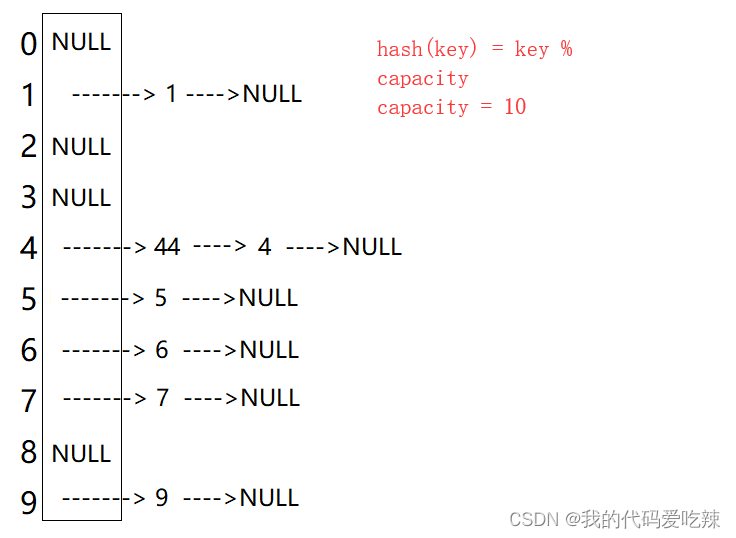
下图所示的就是一维数组:

5. pd.Series创建一个Series对象
【语法】
pd.Series(data, index)
【参数】
pd是库名。.英文小圆点。库名后接一个小圆点表示调用。Series类名。data是必需参数,表示要传递的数据。index是可选参数,用于自定义索引。
index[ˈɪndeks]:索引。
实例化类创建对象的语法为:对象名 = 类名()
pd.Series(data, index)也是一个实例化类创建对象语句。
只是这里的类不是自定义的类,而是调用的pandas库的类。
pd.Series(data, index)实例化Series类后得到一个Series对象。
实例化Series类必须传递一个data参数。
data参数的数据类型可以是列表、数组、字典等。
下面我们依次来看。
6. data = 列表
【代码示例】
# 导入pandas库并简写为pd
import pandas as pd
data =["赵", "钱", "孙", "李"]
s1 = pd.Series(data)
print(type(s1))
print(s1)
【终端输出】
<class 'pandas.core.series.Series'>
0 赵
1 钱
2 孙
3 李
dtype: object
【代码解析】
终端输出的<class 'pandas.core.series.Series'>表示实例化Series类后得到一个Series对象。
Series对象是一个一维数组。
pd是库名。.英文小圆点,库名后接一个小圆点表示调用。Series类名。data存储的是一个列表。
在没有index参数的情况下,pd.Series(data) 会自动为列表中的每一个元素分配对应的数字索引。
默认索引是从 0 开始,以 0, 1, 2, 3,… 的形式按序分配给列表中的元素。
第1个元素赵,自动分配索引0 。
第2个元素钱,自动分配索引1 。
第3个元素孙,自动分配索引2 。
第4个元素李,自动分配索引3 。
上面的0 1 2 3就是默认的数据索引。

7. 同时传入data和index
【代码示例】
# 导入pandas库并简写为pd
import pandas as pd
data =["赵", "钱", "孙", "李"]
index=['A','B','C','D']
s1 = pd.Series(data, index )
print(s1)
【终端输出】
A 赵
B 钱
C 孙
D 李
dtype: object
【代码解析】
这里的代码相对于上一段代码多传入了一个参数index。
pd是库名。.英文小圆点,库名后接一个小圆点表示调用。Series类名。data存储的是一个列表。index=['A','B','C','D']表示用A B C D做为数据索引。
【有没有index的区别】
没有index参数,赵对应的索引为默认索引0。
有index参数,赵对应的索引为传入的索引A。
8. data = 字典
【代码示例】
# 导入pandas库并简写为pd
import pandas as pd
data = {'A':'赵','B':'钱','C':'孙','D':'李'}
s1 = pd.Series(data)
print(s1)
【终端输出】
A 赵
B 钱
C 孙
D 李
dtype: object
当传入的data数据类型为字典时:
字典的键A B C D就是数据的索引。
字典的值赵 钱 孙 李是数据的值。
9. Series对象的3要素:索引+数据+类型
9.1 data=列表,列表元素均为字符串
# 导入pandas库并简写为pd
import pandas as pd
# 列表的元素均为字符串
data = ["赵", "钱", "孙", "李"]
s1 = pd.Series(data)
print(s1)
【终端输出】
0 赵
1 钱
2 孙
3 李
dtype: object
输出一个Series如下图所示:

dtype:类型。
object[ˈɒbdʒɪkt]:对象。
- 左侧的
0 1 2 3是索引。 - 右侧的
赵 钱 孙 李是数据。 dtype指pandas库中的数据类型。object表示数据类型为字符串。

在Series对象中,只要有一条数据是字符串类型,则dtype就为 object。
上面的代码传给参数data的数据只有字符串类型。
终端输出dtype: object,object等价于字符串类型。
dtype: object字符串类型。
9.2 data=列表,列表元素均为字符串+整数
# 导入pandas库并简写为pd
import pandas as pd
# 列表的元素均为字符串+整数
data = ["赵", "钱", 1, 2]
s1 = pd.Series(data)
print(s1)
【终端输出】
0 赵
1 钱
2 1
3 2
dtype: object
列表data的元素有字符串赵 钱,也有整数1 2 。
但在Series对象中,只要有一条数据是字符串类型,则dtype就为 object。
因此终端输出dtype: object,object等价于字符串类型。
9.3 data=列表,列表元素均为整数
# 导入pandas库并简写为pd
import pandas as pd
# 列表的元素均为整数
data = [1, 2, 3, 4]
s1 = pd.Series(data)
print(s1)
【终端输出】
0 1
1 2
2 3
3 4
dtype: int64
列表data的元素均为字符串。
终端输出dtype: int64,数据均为整数。
9.4 data=列表,列表元素均为浮点数
# 导入pandas库并简写为pd
import pandas as pd
# 列表的元素均为浮点数
data = [1.1, 2.2, 3.3, 4.4]
s1 = pd.Series(data)
print(s1)
【终端输出】
0 1.1
1 2.2
2 3.3
3 4.4
dtype: float64
列表data的元素均为浮点数。
终端输出dtype: float64,数据均为浮点数。
10. Series类的values和index属性
Series类是pandas库中的一个数据结构,它有两个属性:values和index。
values属性是一个一维数组,用于存储Series对象中的数据。
这个数组可以包含不同的数据类型,如整数、浮点数、字符串等。
我们可以通过访问这个属性来获取Series对象中的数据。
index属性是一个索引对象,用于标识Series对象中每个数据项的标签。
索引可以是整数、字符串或其他数据类型。
通过index属性,我们可以对Series对象进行标签化的访问和操作。
11. 利用index获取Series的索引
# 导入pandas库并简写为pd
import pandas as pd
data = {'A':'赵','B':'钱','C':'孙','D':'李'}
# 调用库的类:库名.类名( )
# pd是库名,Series是类名
# 创建对象:对象名 = 类名()
# s1是对象名,Series是类名
s1 = pd.Series(data)
# 查看对象的属性
# 对象名.属性名
print(s1.index)
【终端输出】
Index(['A', 'B', 'C', 'D'], dtype='object')
【代码解析】
s1是实例化类后创建的对象,是对象名。index是该对象具有的属性。对象名.属性名可输出属性。
Index表是对象的索引,因此这里输出的就是数据的索引值['A', 'B', 'C', 'D']。
12. 利用values获取Series的值
# 导入pandas库并简写为pd
import pandas as pd
data = {'A':'赵','B':'钱','C':'孙','D':'李'}
# 调用库的类:库名.类名( )
# pd是库名,Series是类名
# 创建对象:对象名 = 类名()
# s1是对象名,Series是类名
s1 = pd.Series(data)
# 查看对象的属性
# 对象名.属性名
print(s1.values)
【终端输出】
['赵' '钱' '孙' '李']
values表是对象的数据,因此这里输出的就是对象中的数据['赵' '钱' '孙' '李']。
13. 课堂练习
【目标任务】
假设你正在记录每天的体重,并且你有以下数据:
星期一: 55
星期二: 54
星期三: 53
星期四: 52
星期五: 51
要求使用上面这些数据创建一个名为 weight 的 Series 对象,并将星期作为索引。
最后分别输出Series 对象的索引和数据。
【代码示例】
import pandas as pd
data = [55, 54, 53, 52, 51]
index = ['星期一', '星期二', '星期三', '星期四', '星期五']
weight = pd.Series(data, index)
print(weight)
print("Series对象的索引:",weight.index)
print("Series对象的数据:",weight.values)
【终端输出】
星期一 55
星期二 54
星期三 53
星期四 52
星期五 51
dtype: int64
Series对象的索引: Index(['星期一', '星期二', '星期三', '星期四', '星期五'], dtype='object')
Series对象的数据: [55 54 53 52 51]
14. 总结

15. 课后练习
【目标任务】
已知2个列表如下:
list_1 = [1, 2, 3, 4]
iist_2 = [9, 8, 7, 6]
要求将这两个列表中的元素一一对应相加,返回一个新列表。
【一一相加】
1+9 = 10
2+8 = 10
3+7 = 10
4+6 = 10
【返回的列表】
list_3 = [10, 10, 10, 10]
【代码示例】
list_1 = [1, 2, 3, 4]
list_2 = [9, 8, 7, 6]
result = []
for i in range(len(list_1)):
result.append(list_1[i] + list_2[i])
print(result)
【终端输出】
[10, 10, 10, 10]
【代码解析】
list_1 = [1, 2, 3, 4]
print(len(list_1))
【终端输出】
4
len函数是一个内置函数,在Python中用于返回一个对象的长度或元素个数。
它可以用于字符串、列表、元组、字典等可迭代对象。
当应用于字符串时,len函数返回字符串中字符的个数。
当应用于列表、元组或字典时,len函数返回容器中元素的个数。
上面的列表有4个元素,因此len(list_1)=4
for i in range(len(list_1))等价于for i in range(4)。
list_1 = [1, 2, 3, 4]
list_1[0]
【终端输出】
1
列表索引取值语法列表名[索引]。
list_1[0]取到列表的第一元素1。
list_1[i] + list_2[i]
2个列表的索引均为i,就实现了列表取值的一一对应。
取值后将2个元素进行加法运算,就实现了题目的求和。
result.append(list_1[i] + list_2[i])
- 向列表中增加元素的语法为
列表名.append(要增加的元素)。 result是列表名。append向列表增加元素的函数。list_1[i] + list_2[i]要增加的元素。
上面这个方法是我们在基础语法部分学习的方法,今天学了Series后,我们可以用更简洁的办法来计算出2个列表一一对应的和。
用Series的相关知识该怎么计算呢,大家先动动脑想一想吧!
【参考答案】