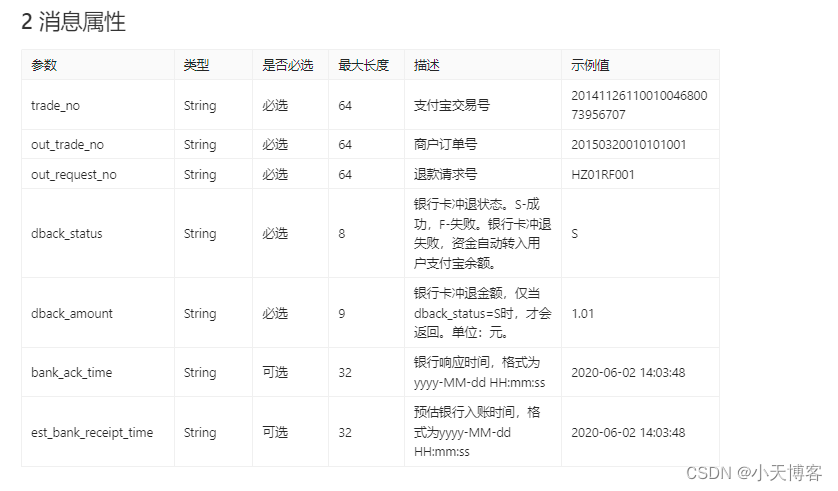
这里的知识点在于如何合并两张表,事实上这种业务场景我们很熟悉了,这就是我们在学习 MySQL 的时候接触到的内连接,左连接,而现在我们要学习 mapreduce 中的做法
这里我们可以选择在 map 阶段和reduce阶段去做
数据:
链接: https://pan.baidu.com/s/1PH1J8SIEJA5UX0muvN-vuQ?pwd=idwx 提取码: idwx
顾客信息
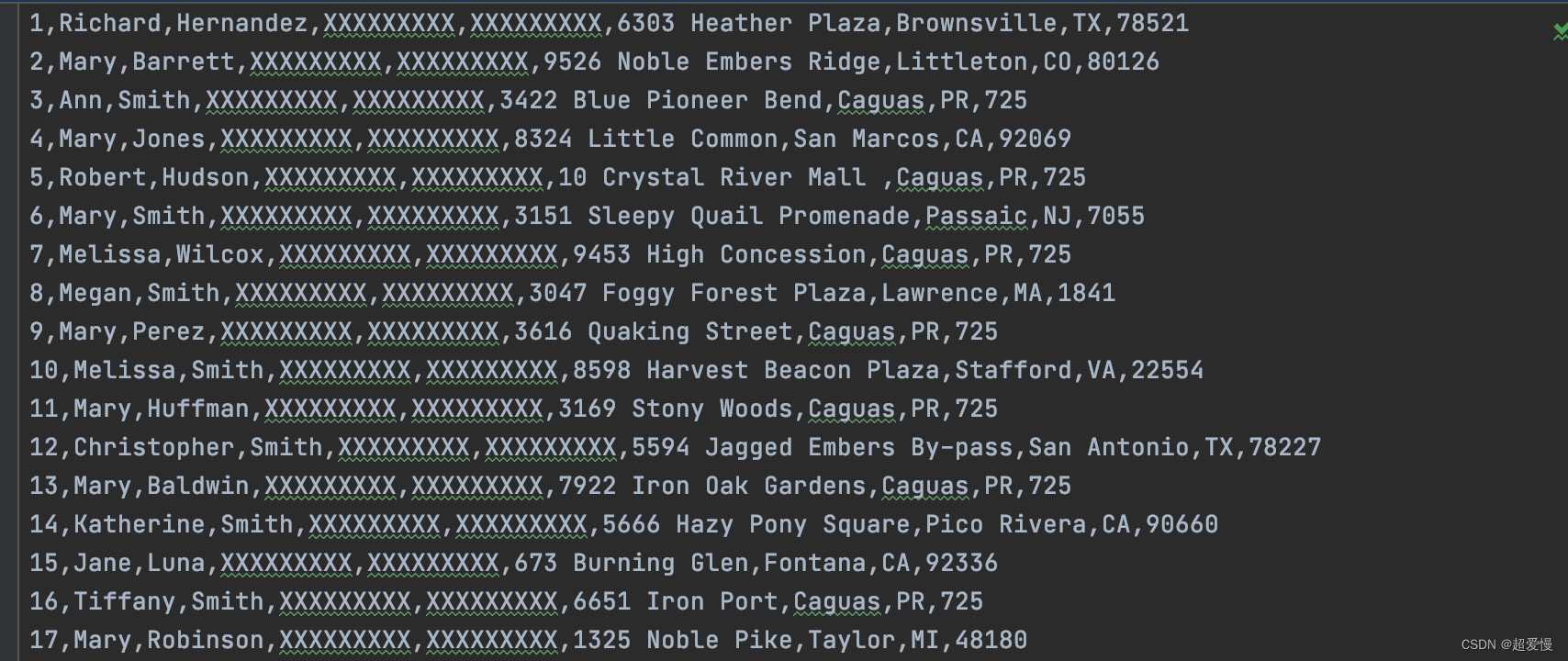
订单信息
编写实体类 CustomerOrder
这里我们除了顾客与订单的属性外,额外定义了一个状态,用来区分当前类是顾客信息还是订单信息
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CustomerOrders implements WritableComparable<CustomerOrders> {
private Integer customerId;
private String customerName;
private Integer orderId;
private String orderStatus;
// 标签
private String flag;
@Override
public String toString() {
return "CustomerOrders{" +
"customerId=" + customerId +
", customerName='" + customerName + '\'' +
", orderId=" + orderId +
", orderStatus='" + orderStatus + '\'' +
", flag='" + flag + '\'' +
'}';
}
public CustomerOrders() {
}
public CustomerOrders(Integer customerId, String customerName, Integer orderId, String orderStatus, String flag) {
this.customerId = customerId;
this.customerName = customerName;
this.orderId = orderId;
this.orderStatus = orderStatus;
this.flag = flag;
}
public Integer getCustomerId() {
return customerId;
}
public void setCustomerId(Integer customerId) {
this.customerId = customerId;
}
public String getCustomerName() {
return customerName;
}
public void setCustomerName(String customerName) {
this.customerName = customerName;
}
public Integer getOrderId() {
return orderId;
}
public void setOrderId(Integer orderId) {
this.orderId = orderId;
}
public String getOrderStatus() {
return orderStatus;
}
public void setOrderStatus(String orderStatus) {
this.orderStatus = orderStatus;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public int compareTo(CustomerOrders o) {
return 0;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(customerId);
dataOutput.writeUTF(customerName);
dataOutput.writeInt(orderId);
dataOutput.writeUTF(orderStatus);
dataOutput.writeUTF(flag);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.customerId = dataInput.readInt();
this.customerName = dataInput.readUTF();
this.orderId = dataInput.readInt();
this.orderStatus = dataInput.readUTF();
this.flag = dataInput.readUTF();
}
}
1. 在 reduce 阶段合并
传入两个文件
(1)map 阶段
setup方法在 map 方法前运行,找到当前数据所在文件的名称,用来区分当前这条数据是顾客信息还是订单信息
map 方法将传进来的数据包装成对象,最后已键值对的形式传给下一阶段
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,CustomerOrders> {
String fileName = "";
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit fileSplit = (FileSplit) context.getInputSplit();
System.out.println("setup method: "+ fileSplit.getPath().toString());
fileName = fileSplit.getPath().getName();
System.out.println("fileName : "+fileName);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// System.out.println("map stage:");
// System.out.println("key : "+key+"\tvalue : "+value);
String[]field = value.toString().split(",");
CustomerOrders customerOrders = new CustomerOrders();
if (fileName.startsWith("orders")){ //订单内容
customerOrders.setCustomerId(Integer.parseInt(field[2]));
customerOrders.setCustomerName("");
customerOrders.setOrderId(Integer.parseInt(field[0]));
customerOrders.setFlag("1");
customerOrders.setOrderStatus(field[3]);
}else { //用户信息
customerOrders.setCustomerId(Integer.parseInt(field[0]));
customerOrders.setCustomerName(field[1]);
customerOrders.setOrderId(0);
customerOrders.setFlag("0");
customerOrders.setOrderStatus("");
}
Text text = new Text(customerOrders.getCustomerId().toString());
context.write(text, customerOrders);
}
}
(2)reduce 阶段
这里的 reduce 方法则是,先遍历找到唯一的一个顾客信息,然后将顾客信息填充到订单信息中,再合并为一个 Text 输出
当然也可以有不同的写法,比如将每一条订单信息处理完后就写入 context 之后输出
还有就是这里的对象的赋值写的不太好,但是不能直接用=去赋值,可以使用 BeanUtils 的 copyproperties()方法去赋值
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class ReduceJoinReducer extends Reducer<Text,CustomerOrders,Text,Text> {
@Override
protected void reduce(Text key, Iterable<CustomerOrders> values, Context context) throws IOException, InterruptedException {
System.out.println("reduce stage: key:"+key+" values:"+values);
String customerName = "";
String text = "";
List<CustomerOrders> list = new ArrayList<>();
for (CustomerOrders co : values){
if (co.getFlag().equals("0")){
customerName = co.getCustomerName();
}
CustomerOrders customerOrders = new CustomerOrders();
customerOrders.setCustomerName(co.getCustomerName());
customerOrders.setFlag(co.getFlag());
customerOrders.setCustomerId(co.getCustomerId());
customerOrders.setOrderStatus(co.getOrderStatus());
customerOrders.setOrderId(co.getOrderId());
list.add(customerOrders);
}
System.out.println(list);
System.out.println();
for (CustomerOrders co : list){
if (co.getFlag().equals("1")){
CustomerOrders customerOrders = new CustomerOrders();
customerOrders = co;
customerOrders.setCustomerName(customerName);
customerOrders.setFlag("2");
System.out.println(customerOrders.toString());
text += customerOrders.toString()+"\t";
}
}
System.out.println(text);
System.out.println("customerName:"+customerName);
context.write(key, new Text(text));
}
}(3)driver 启动
基本操作,设置好各个参数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ReduceJoinDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReduceJoinDriver.class);
job.setMapperClass(ReduceJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CustomerOrders.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job ,new Path[]{new Path(args[0]),new Path(args[1])});
Path path = new Path(args[2]);
FileSystem fs = FileSystem.get(path.toUri(),conf);
if (fs.exists(path)){
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job,path);
fs.close();
job.waitForCompletion(true);
}}2. 在 map 阶段合并
传入一个文件,另一个文件以缓存文件cachefile的形式传入,这种方法要注意,cachefile的大小不能太大,可以形象的打个比方,你去朋友家做客,晚上朋友家没有被子,你捎带个被子过去,这是可以的,但是如果说你朋友缺个房子,你不能捎带个房子过去对吧。
(1)map 阶段
setup方法使用 io 流的方法将顾客信息读取进来,使用 List<CustomerOrders>去存储
map 方法对于每个订单信息都遍历一次列表,通过顾客编号这一关联属性去找到对应的顾客信息并填充进去
import md.kb23.demo03.CustomerOrders;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.codehaus.jackson.map.util.BeanUtil;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
public class MapJoinMapper extends Mapper<LongWritable, Text, CustomerOrders, NullWritable> {
private List<CustomerOrders> list = new ArrayList<CustomerOrders>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cashFiles = context.getCacheFiles();
for (URI uri : cashFiles){
System.out.println(uri.getPath());
String currentFileName = new Path(uri).getName();
if (currentFileName.startsWith("customers")){
String path = uri.getPath();
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(path)));
String line;
while ((line = br.readLine())!=null){
System.out.println(line);
String[] field = line.split(",");
CustomerOrders customerOrders = new CustomerOrders(Integer.parseInt(field[0]),field[1]+" "+field[2],0,"","");
list.add(customerOrders);
}
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[]orderField = value.toString().split(",");
int customerId = Integer.parseInt(orderField[2]);
CustomerOrders customerOrders = null;
for (CustomerOrders customer : list){
if (customer.getCustomerId()==customerId){
customerOrders=customer;
}
}
CustomerOrders order = new CustomerOrders();
if (customerOrders!=null){
order.setCustomerName(customerOrders.getCustomerName());
}else {
order.setCustomerName("");
}
order.setCustomerId(customerId);
order.setOrderStatus(orderField[3]);
order.setFlag("1");
order.setOrderId(Integer.parseInt(orderField[0]));
context.write(order, null);
}
}
(2)driver 启动
这里我们在 map 阶段已经将事情都做完了,就不用再额外写一个 reduce 了,另外就是注意一下 cachefile 的添加方法
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MapJoinDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
long start = System.currentTimeMillis();
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MapJoinDriver.class);
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(CustomerOrders.class);
job.setMapOutputValueClass(NullWritable.class);
Path inpath = new Path("in/demo3/orders.csv");
FileInputFormat.setInputPaths(job,inpath);
Path outpath = new Path("out/out5");
FileSystem fs = FileSystem.get(outpath.toUri(),conf);
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
//设置 reduce 阶段任务数
job.setNumReduceTasks(0);
Path cashPath = new Path("in/demo3/customers.csv");
job.addCacheFile(cashPath.toUri());
job.waitForCompletion(true);
long end = System.currentTimeMillis();
System.out.println("程序运行时间:"+(end-start));
}
}