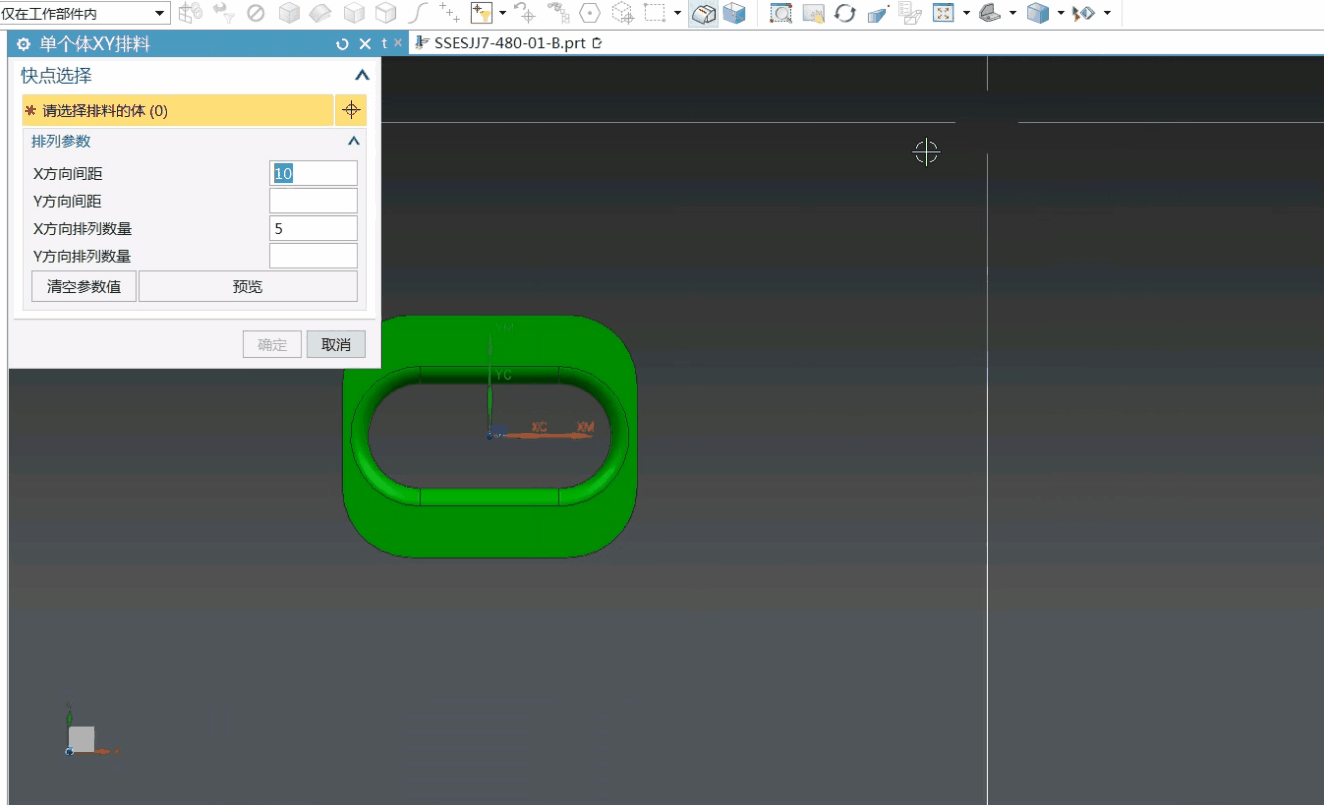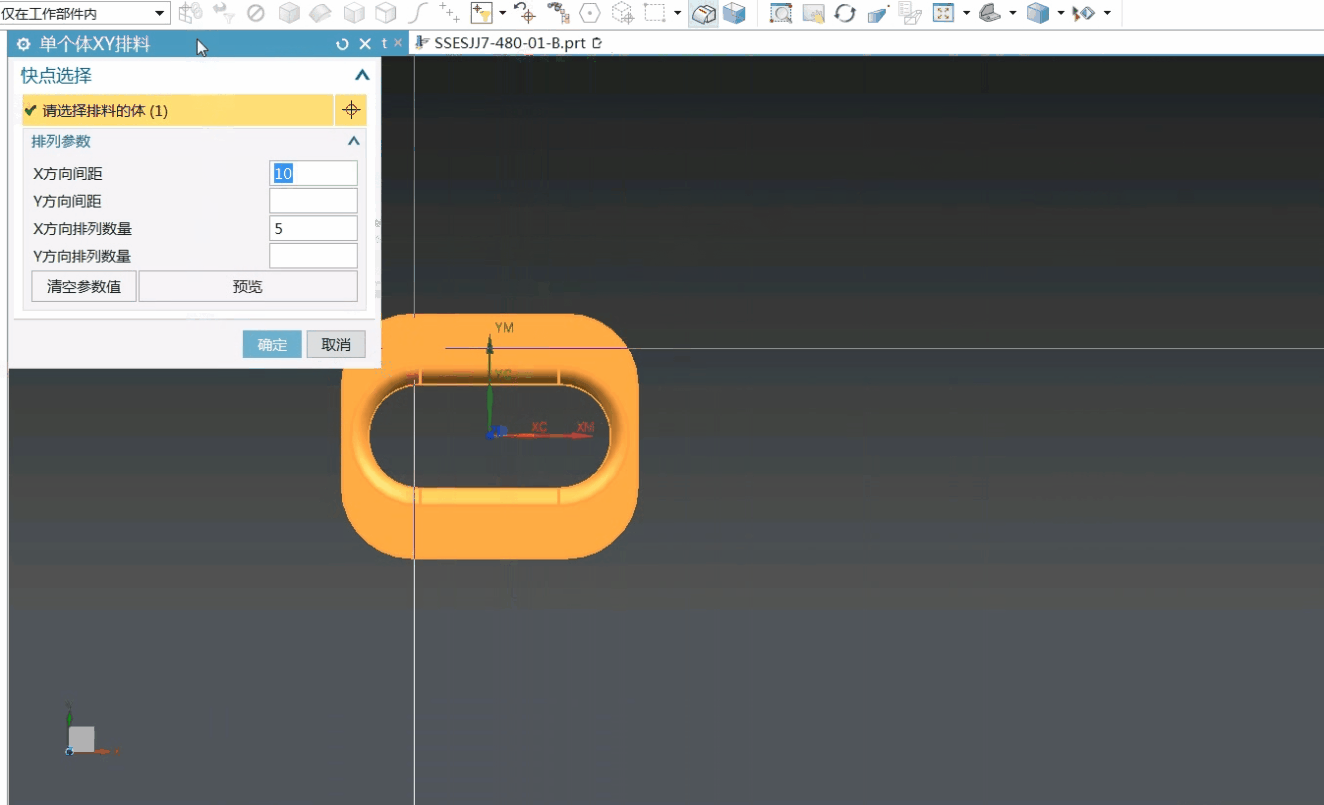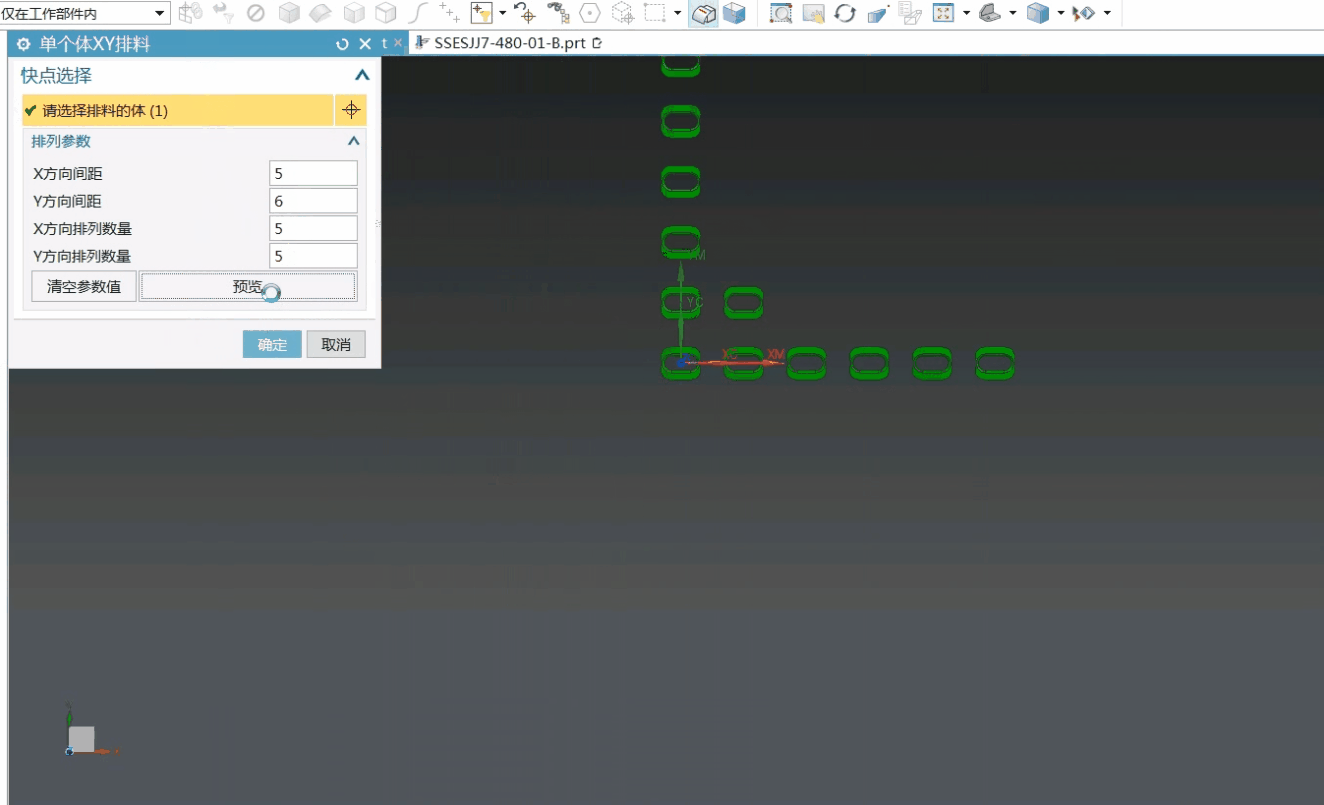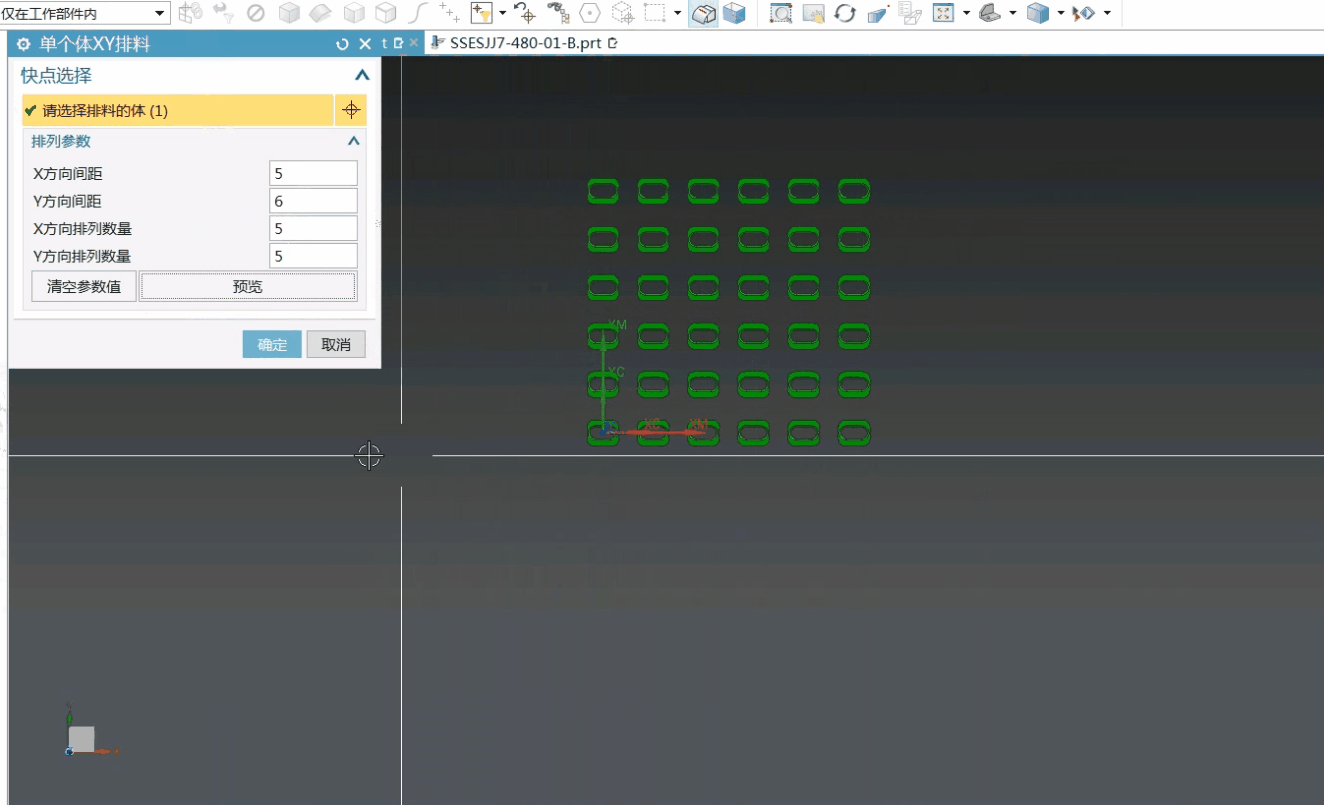
- 下载spark 安装包
spark官网下载
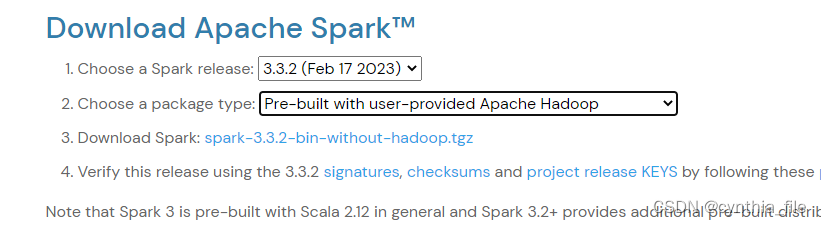
pre-built with user-provided 会支持更多的hadoop,已经安装了hadoop和java环境的选这个比较好
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
- 安装
解压
tar -xvf spark-3.3.2-bin-hadoop3.tgz -C /usr/local
改名
mv spark-3.3.2-bin-hadoop3.tgz spark
修改配置使spark 能访问hadoop
cd spark
cp conf/spark-env.sh.template conf/spark-env.sh
vim conf/spark-env.sh
最后一行添加
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/hadoop/bin/hadoop classpath)
- 交互
-
本地模式
./bin/spark-shell --master local 单线程
./bin/spark-shell --master local[*] 服务器线程数 等效 ./bin/spark-shell -
独立集群模式:hadoop 是伪分布式布置的,spark就只能是standAlone模式
spark://HOST:PORT 默认7077
spark://localhost:7077 -
yarn-client 模式 调试时用
客户端可以获得查看信息
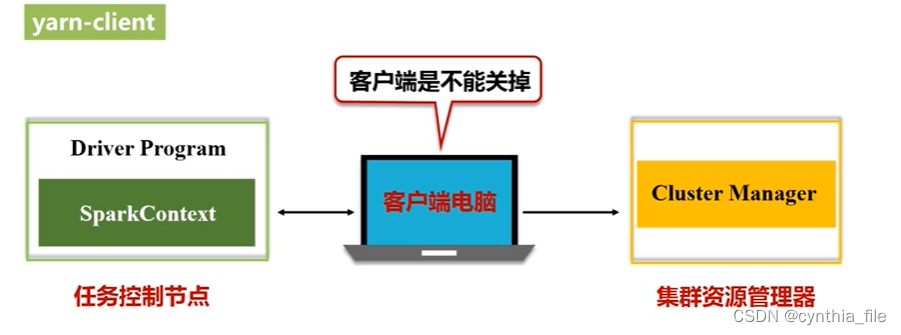
-
yarn-cluster模式 生产模式使用
Spark的Driver节点从集群中选择
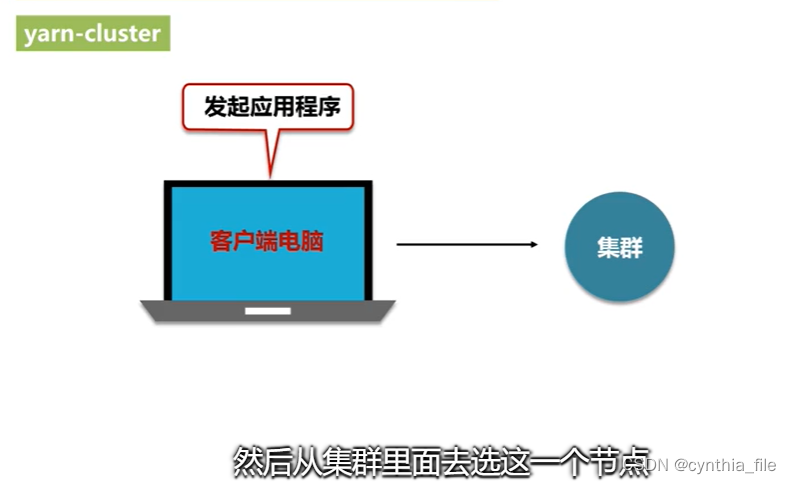
-
程序运行 sbt
https://dblab.xmu.edu.cn/blog/804/
![【java】【项目实战】[外卖八]产品展示、购物车、下单开发](https://img-blog.csdnimg.cn/aa899bfeae6a43b2a99ba1d5f8b4044b.png)