引言
随着人工智能技术的飞速发展,以及今年以来 ChatGPT 的爆火,大语言模型 (Large Language Model, LLM) 受到越来越多的关注。
为了实现 LLM 部署时的推理优化,全球各地有众多团队做出了各种优化框架。本文以加州大学伯克利分校开发的 vLLM 框架为例,进行实战探索。
1. 整体介绍
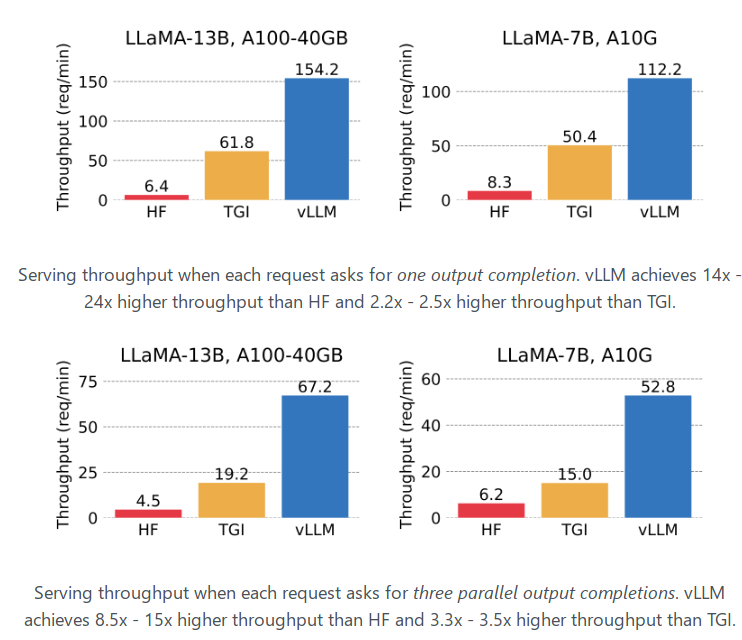
根据公开文档中的实验结果, vLLM 吞吐量比 Hugging Face Transformers 高出 24 倍,比 TGI 高出 3.5 倍。
vLLM 整体框架如下图所示。
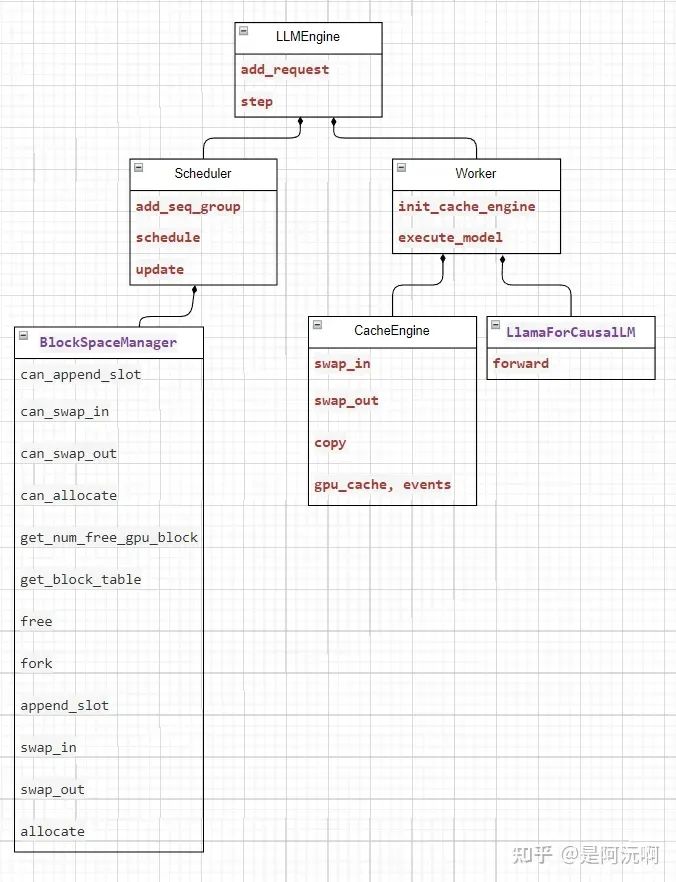
其中的关键技术点包括:
KVCache 显存优化
PagedAttention
Continuous Batching
笔者通过实际使用,认为该框架优点如下:
调试方便: 主框架由 Python 实现,便于用户断点调试。
系统设计工整规范: LLMEngine、Scheduler、Worker 结构清晰,初学者可以方便地理清脉络。
推理速度快: 经过理论计算与实测, 8 卡 A100-40G 足以支持千人试用。
2. offline_inference 示例复现分析
(1) 调试环境配置
为方便复现,笔者制作了 dockerfile 用于编译 base 镜像,base 镜像把 vllm 的依赖库都安装好,基于 base 镜像直接再安装 vllm 库即可复现。
docker build -t vllm_ci-benchmark:base -f ci/docker/ci-benchmark-base.dockerfile .
docker build -t vllm_ci-benchmark:v1 -f ci/docker/ci-benchmark.dockerfile .镜像是基于 nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04 (95d242fe9108) (9.83GB) 制作而来,篇幅所限,此处只展示 ci-benchmark.dockerfile 内容。
FROM vllm_ci-benchmark:base
COPY . /code/vllm
RUN cd /code/vllm && \
python3 -m pip install -e . && \
rm -rf ~/.cache而后基于 vllm_ci-benchmark:v1 镜像创建容器,配置 vscode 断点调试环境,便于跟踪 offline_inference 示例的全流程。
(2) 模型下载与复现
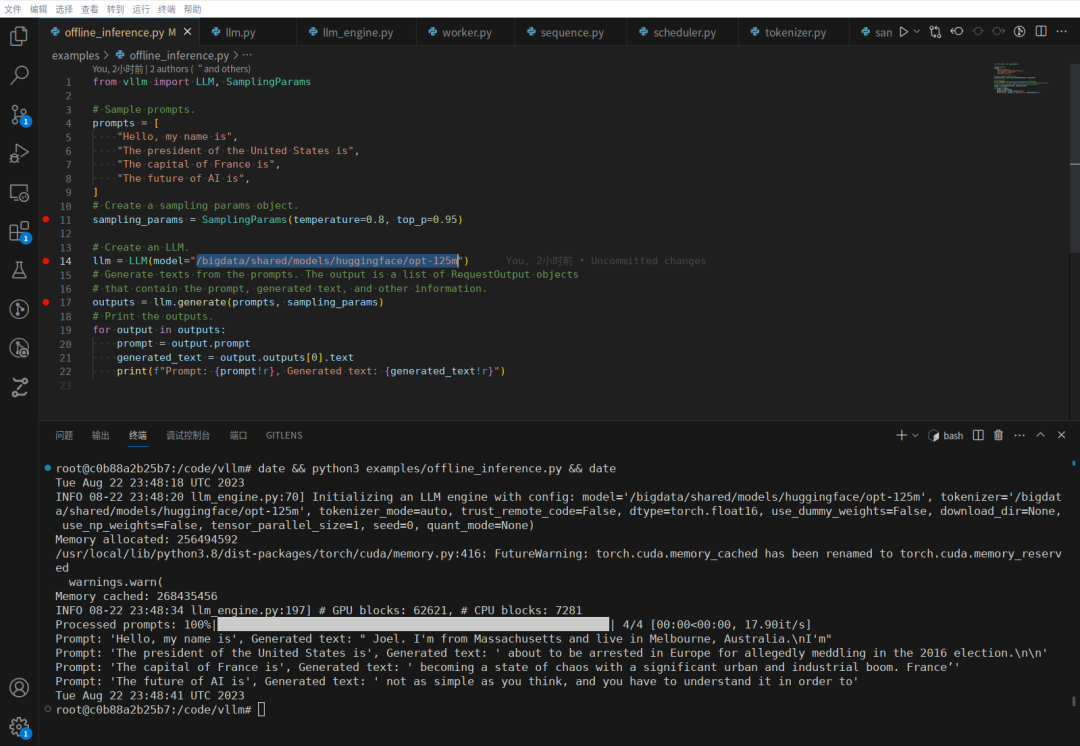
提前从 facebook/opt-125m 下载 pytorch_model.bin 格式的模型和源码文件夹,而后将 offline_inference 中的模型路径改为本地路径,复现结果如下图所示。
(3) offline_inference 流程梳理
(a) Create sampling_params
根据用户设置,创建采样参数类对象 sampling_params,只指定 temperature=0.8, top_p=0.95 的情况下,其他默认值如下所示。
SamplingParams(n=1,
best_of=1,
presence_penalty=0.0,
frequency_penalty=0.0,
temperature=0.8,
top_p=0.95,
top_k=-1,
use_beam_search=False,
stop=[],
ignore_eos=False,
max_tokens=16,
logprobs=None)各参数的取值范围见 vllm/sampling_params.py 里相关 _verify_xxx 函数。
(b) Create an LLM
LLM 类对象的构造函数中,首先创建 EngineArgs 类对象 engine_args 如下。
EngineArgs(model='/bigdata/shared/models/huggingface/opt-125m',
tokenizer='/bigdata/shared/models/huggingface/opt-125m',
tokenizer_mode='auto',
trust_remote_code=False,
download_dir=None,
use_np_weights=False,
use_dummy_weights=False,
dtype='auto',
seed=0,
worker_use_ray=False,
pipeline_parallel_size=1,
tensor_parallel_size=1,
block_size=16,
swap_space=4,
gpu_memory_utilization=0.9,
max_num_batched_tokens=2560,
max_num_seqs=256,
disable_log_stats=True,
quant_mode=None)然后基于 engine_args ,构造 LLM 类内核心变量 llm_engine ,最后添加一个类内计数器 request_counter。
self.llm_engine = LLMEngine.from_engine_args(engine_args)
self.request_counter = Counter()(c) Generate
在 LLM.generate 的处理过程中,核心操作分为两步。
第一步是调用 LLM._add_request ,通过 LLM.llm_engine.add_request 将用户传入的请求添加到请求列表中,添加完后,请求列表 LLM.llm_engine.scheduler.waiting 中内容如下。
[ \
SequenceGroup(request_id=0, sampling_params=SamplingParams(n=1, best_of=1, presence_penalty=0.0, frequency_penalty=0.0, temperature=0.8, top_p=0.95, top_k=-1, use_beam_search=False, stop=[], ignore_eos=False, max_tokens=16, logprobs=None), num_seqs=1),
SequenceGroup(request_id=1, sampling_params=SamplingParams(n=1, best_of=1, presence_penalty=0.0, frequency_penalty=0.0, temperature=0.8, top_p=0.95, top_k=-1, use_beam_search=False, stop=[], ignore_eos=False, max_tokens=16, logprobs=None), num_seqs=1),
SequenceGroup(request_id=2, sampling_params=SamplingParams(n=1, best_of=1, presence_penalty=0.0, frequency_penalty=0.0, temperature=0.8, top_p=0.95, top_k=-1, use_beam_search=False, stop=[], ignore_eos=False, max_tokens=16, logprobs=None), num_seqs=1),
SequenceGroup(request_id=3, sampling_params=SamplingParams(n=1, best_of=1, presence_penalty=0.0, frequency_penalty=0.0, temperature=0.8, top_p=0.95, top_k=-1, use_beam_search=False, stop=[], ignore_eos=False, max_tokens=16, logprobs=None), num_seqs=1)
]第二步是调用 LLM._run_engine,通过 LLM.llm_engine.step(),转到 LLM.llm_engine._run_workers 函数中进行处理。
在 LLM.generate 的处理过程中,LLMEngine, Scheduler, Worker 协作配合,LLMEngine 负责总控,Scheduler 负责调度,Worker 负责执行,脉络清晰,其设计思路很值得学习借鉴。
3. 总结
vLLM 框架通过 PagedAttention 等关键技术,在多 batch 推理时,与传统 Hugging Face Transformers 框架相比,大幅提高了推理速度和吞吐量。
本文针对 vLLM 框架的 offline_inference 示例进行了复现与梳理分析,接下来准备进一步深入探索 PagedAttention 等特性。受限于笔者知识水平,文中可能会存在某些理解身上的偏差,欢迎各位大佬进行交流,共同进步。