1. 函数功能
将连续性数值进行离散化处理:如对年龄、消费金额等进行分组
2. 函数语法
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True)
3. 函数参数
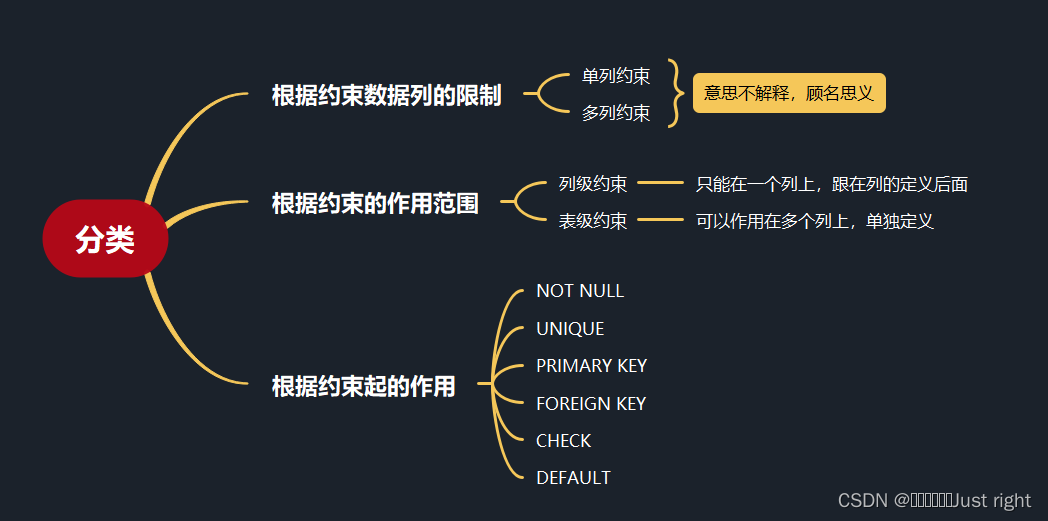
| 参数 | 含义 |
|---|---|
| x | 要离散分箱操作的数组,必须是一维的 |
| bins | 取值为:(1)整数n:将数据x划分为组距相等的n组;(2)标量组成的序列:指定每组的分界值;(3)IntervalIndex:间隔索引 |
| right | 布尔值,默认为True:包括每组的右边边界值:当“ right = True”(默认值)时,则“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4] |
| labels | 指定离散化后返回每组的标签,长度与组数一致。默认为None:以分界值组成的左开右闭区间展示;取值为False时,返回一个区分箱的整数组成的序列。 |
| retbins | 布尔值,默认为False:不返回分箱情况,该参数在bins取值为整数时起作用 |
| precision | 分箱数值的精度,取值为整数,默认为3 |
| include_lowest | 布尔值,默认为False:不包括每组的左侧分界值,即:左开区间 |
| duplicates | 可选参数:当bins的边界值存在重复,采取的措施:raise(报错:默认)或者drop(删除) |
| ordered | 布尔值,默认为True:对labels标签排序,属于定序型变量:优秀>良好;取值为False时:得到的标签labels属于定类型变量:如:汉族、维吾尔族 |
4. 返回值
返回值包括两个
| 返回值 | 含义 |
|---|---|
| out | 返回值取决于labels参数的取值:(1)labels参数取值为None(默认):输入为Series时返回一个Series,其他输入类型返回categorical;(2)labels取值为标量组成的序列:输入为Series时返回一个Series,其他输入类型返回categorical;(3)labels取值为False时:返回一个整数组成的数组 |
| bins | 计算得到或者制定的每组分界值,当retbins=True时,才会返回该值 |
5. 示例
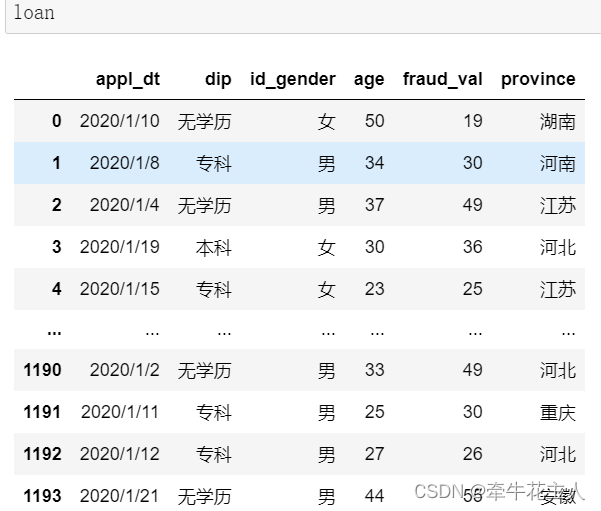
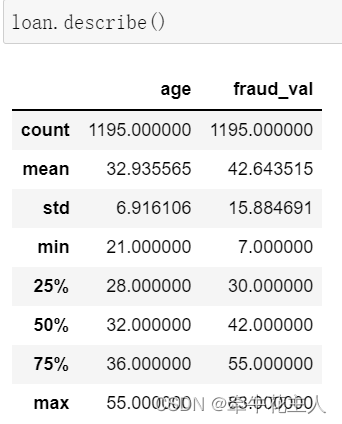
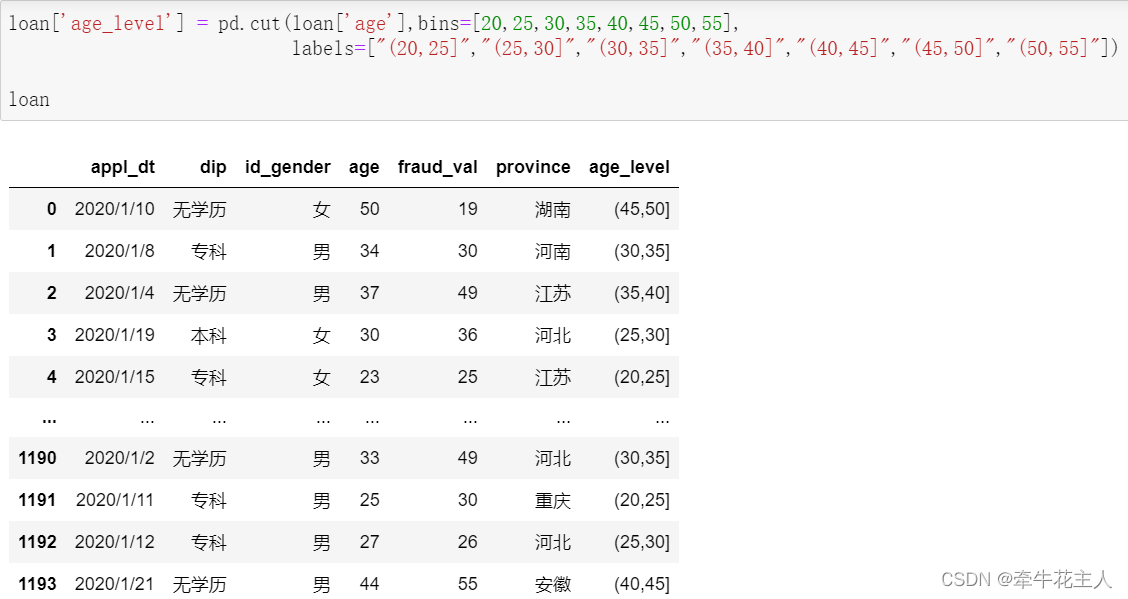
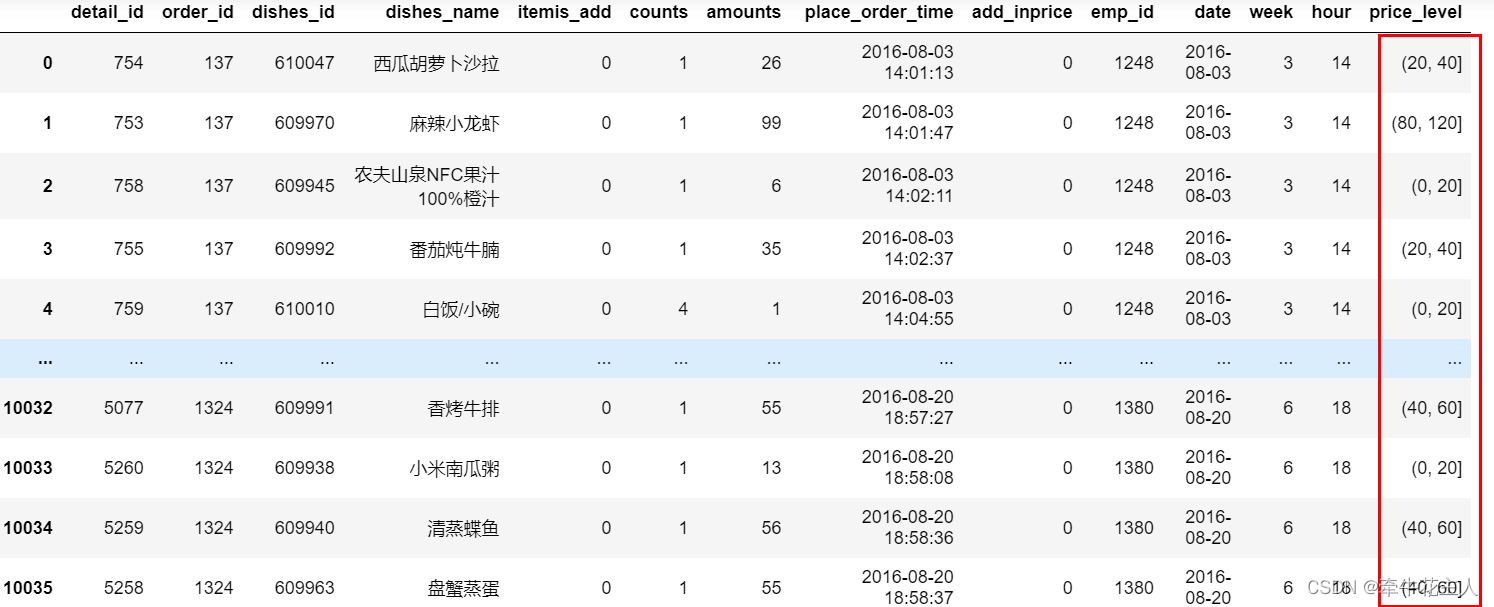
其实标签为上述数字边界组成时,不需要通过Labels特别指定,取值为None时,默认即是上述形式。见下例:

![Maven报错 [ERROR] Malformed \uxxxx encoding.](https://img-blog.csdnimg.cn/df41c676d8a34a4b9c275985a016282d.png)