1、问题描述
生产环境Nginx间歇性502的事故分析过程
客户端请求后端服务时一直报错 502 bad gateway,查看后端的服务是正常启动的。后来又查看Nginx的错误日志,发现请求后端接口时Nginx报错no live upstreams while connecting to upstream,查看该错误的解释可以得到的结果是upstream中没有可以提供服务的server,即Nginx已经发现不了存活的后端了,但是,我直接访问后端的server却是可以使用的,证明server端可用。
最后查找文档,发现问题出现在业务上要求保持会话,但是Nginx到后端并没有保持会话,那么,Nginx当然就找不到后端可用服务,就会报no live upstream。
参考文档:https://xiezefan.me/2017/09/27/nginx-502-bug-trace/
2、服务架构如下:
+--------+ HTTP +-------+ HTTP +-------+
| Client | ------> | | ------> | API A |
+--------+ | | +-------+
| | HTTP +-------+
| | ------> | API B |
| | +-------+
| | HTTP +-------+
| Nginx | ------> | API C |
| | HTTP +-------+
| | ------> | API D |
| | HTTP +-------+
| | ------> | API E |
| | HTTP +-------+
| | ------> | API F |
+-------+ +-------+
3、排查思路
一般讲,Nginx 502就是后端处理不过来,但查看监控后端几个API的负载均很低,当前请求的QPS远远低于服务的上限。而且同一瞬间,多套独立部署的API均处理不过来的概率也比较低。
我们简单做了个对比测试,分别对域名(请求走Nginx)与直接通过IP对内网一个API通过进行小规模压测。
对比测试发现,直接通过域名走Nginx对API进行压测的话,QPS远远小于预期,并且存在大量失败请求。基本断定问题出在Nginx —> API 这条链路上。同时排除了后端服务响应不过来的可能性。网络问题可能性大一点。
一开始我们怀疑云服务商对内网带宽做了限制,我们观察内网带宽达到在200MB/S后就上不去了,所以我们在Nginx机器上ping后端服务,观察一段时间发现有小量抖动,但基本延迟正常。那云服务商对网络做限制的可能性就变小了很多。
我们观察Nginx错误日志:
2023/08/26 14:23:00 [error] 5950#5950: *5172133211 no live upstreams while connecting to upstream, client: xxx.xxx.xxx.xxx, server: api.xx.xxxxxxx.cn, request: "POST /xx/xxxxxx/bidder HTTP/1.1", upstream: "http://xxxxxxxxxx/bidder", host: "api.xx.xxxxxxx.cn"
这里出现no live upstreams while connecting to upstream, 也就说一瞬间Nginx检测不到任何存活的后端服务,而网络又没有大波动,那就可能是TCP链接出问题。打开Zabbix监控发现TCP连接数的确发生剧烈的波动现象。
异常TCP连接数趋势
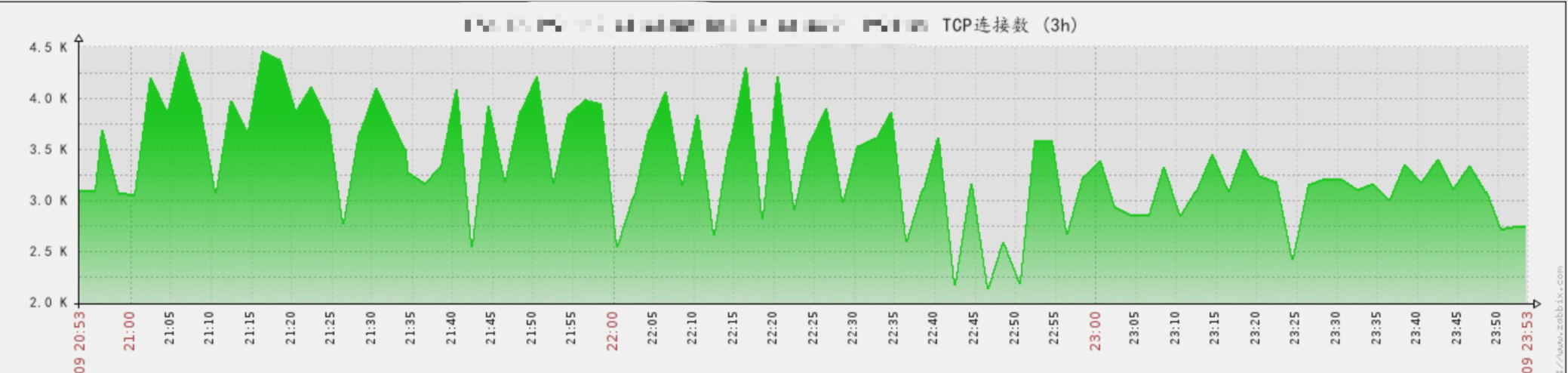
这时候问题很明显,Nginx->API这一链路存在大量的TCP链接被回收的情况,我们马上在API机器上查看链接状态
shell > netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
SYN_RECV 1
ESTABLISHED 656
FIN_WAIT1 4
TIME_WAIT 153429
TIME_WAIT特别的多,大量的连接被API侧主动关闭了。这说明Nginx->API这一步请求并没有Keep-Alive,我们检查Nginx,确定是配置了Keep-Alive
4、解决办法
修改nginx的配置
location ^~ /xxxxxx/ {
...
proxy_http_version 1.1;
proxy_set_header Connection ""; //规制强制指定使用1.1协议
...
}