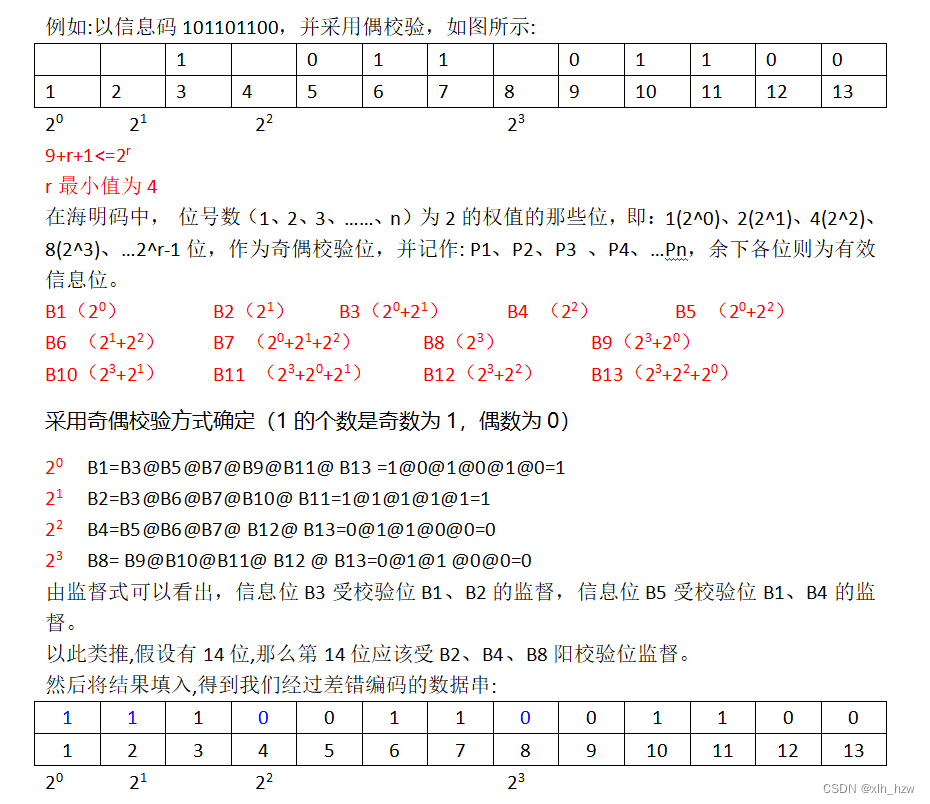
索引的创建和设计原则
- 1. 索引的分类
- 1.1 普通索引
- 1.2 唯一性索引
- 1.3 主键索引
- 1.4 单列索引
- 1.5 多列(联合,组合)索引
- 1.6 全文索引
- 2. 索引的创建
- 2.1 创建表时创建索引
- 1. 隐式创建
- 2. 显式创建
- 3. 全文检索
- 2.2 创建表后创建索引
- 1. alter table 的方式
- 2. create index 的方式
- 3. 索引的删除
- 4. 索引新特性
- 4.1 支持降序索引
- 4.2 隐藏索引
- 1. 创建隐藏索引的方式
- 2. 修改索引是否隐藏
1. 索引的分类
按照功能逻辑进行分类:普通索引,唯一性索引,主键索引,全文索引
按照物理方式进行分类:聚簇索引,非聚簇索引
按照作用字段个数分类:单列索引,联合索引
1.1 普通索引
在创建索引时,不加任何的限制条件。这类索引可以创建在任何数据类型,其值是否为空和唯一,是由字段本本身的约束条件所决定。
1.2 唯一性索引
使用 UNIQUE参数 可以设置唯一性索引,在创建唯一性索引时,限制该索引值必须是唯一的,但允许有空值
1.3 主键索引
主键索引就是一种特殊的唯一性索引,在唯一索引的基础上增加了不为空的约束,也就是 NOT NULL+UNIQUE,一张表里面最多只有一个主键索引。
why?
这是由主键索引的物理实现方式决定的,因为数据在内存中只能按照一种顺序进行存储
1.4 单列索引
作用在一个字段上的索引就是单列索引
1.5 多列(联合,组合)索引
作用在多个字段上的索引,使用时遵循最左前缀原则。
1.6 全文索引
全文索引是目前搜索引擎使用的一种关键技术,适用于大规模数据的检索。使用 FULLTEXT 可以设置全文索引。在整个索引中出现的次数越少的词语,匹配时的相关度就越高。
在当前的大数据时代,关系型数据库对全文索引的需求力不从心。逐渐被其他的搜索引擎代替,所以在MySQL当中,并不会去使用全文索引。
2. 索引的创建
创建索引的方式可以大体上分为两类:
- 造表时创建索引
- 造表后创建索引
2.1 创建表时创建索引
1. 隐式创建
在使用 create table 创建表时,除了可以定义列的数据类型外,还可以定义主键约束,外键约束或者唯一性约束,这些约束在创建同时,也就创建了一个对应的索引。
比如:
create table dept(
dept_id int primary key auto_increment,
dept_name varchar(20)
);
create table emp(
emp_id int primary key auto_increment,
emp_name varchar(20) unique,
dept_id int,
constraint emp_dept_id_fk foreign key(dept_id) references dept(dept_id)
);
结果:

2. 显式创建
创建普通索引:
create table book(
book_id int,
book_name varchar(100),
authors varchar(100),
info varchar(100),
comment varchar(100),
year_publication year,
-- 声明索引
index idx_bname(book_name)
);

创建由约束的索引:
create table book1(
book_id int,
book_name varchar(100),
authors varchar(100),
info varchar(100),
comment varchar(100),
year_publication year,
-- 声明索引
unique index uk_idx_comment(comment),-- 创建唯一性约束
primary key (book_id),-- 创建主键约束
index nul_bid_bname_info(book_id,book_name,info)-- 创建联合索引
);

注意:联合索引遵循最左前缀原则
3. 全文检索
全文索引和上面的创建方式基本一致:fulltext indec(info),但是全文索引的查询方式比较特殊:
select * from book where match(info) against (‘查询字符串’)
注意:
- 使用全文索引前,搞清楚版本支持情况
- 全文索引比起 like + % 的方式要快 N 倍,但是存在精度问题
- 如果需要全文索引的是大量数据。建议先添加数据,再创建索引
2.2 创建表后创建索引
1. alter table 的方式
create table book2(
book_id int,
book_name varchar(100),
authors varchar(100),
info varchar(100),
comment varchar(100),
year_publication year
);
alter table book2 add index idx_cmt(comment);-- 添加普通索引
alter table book2 add unique uk_idx_bname(book_name);-- 添加唯一性索引
alter table book2 add index mul_bid_bname(book_id,book_name); -- 创建联合索引

2. create index 的方式
create table book3(
book_id int,
book_name varchar(100),
authors varchar(100),
info varchar(100),
comment varchar(100),
year_publication year
);
create index idx_cmt on book3(comment);-- 添加普通索引
create unique index uk_idx_bname on book3(book_name);-- 添加唯一性索引
create index mul_bid_bname on book3(book_id,book_name);-- 创建联合索引

3. 索引的删除
当表中要进行大量的增删改的工作时,可以考虑先将索引删除掉,等到这些工作做完之后,在将索引进行恢复。
删除索引的方式和上面2.2创建表以后创建索引的方式是对应的:
- alter table book drop index idx_xmt;
- drop index idx_cmt on book;
注意:添加AUTO_INCREMENT约束字段的唯一索引不能被删除
4. 索引新特性
4.1 支持降序索引
创建联合索引:
create table ts1(
a int,
b int,
index idx_a_b(a ASC,b DESC)
);
插入数据:
DELIMITER //
create procedure ts_insert()
begin
declare i int default 1;
while i<800
do
insert into ts1 select RAND()*80000,RAND()*80000;
set i=i+1;
end while;
commit;
end //
DELIMITER ;
call ts_insert();
分析效率:
explain select * from ts1 order by a,b desc limit 5;

可以看到一共就执行了5行,如果这里不支持降序索引的话,他就会按照升序的索引进行查找,那得多慢啊.
这里还由一点得注意一下,就是索引得升降序和查找数据得升降序应该对应起来:

如果不对应得话,效率也是极低的:

4.2 隐藏索引
在MySQL 5.7 之前,只能通过显式的方式创建索引。此时,如果发现删除索引之后出现错误,又只能将索引创建回来,如果数据量比较大的话,这种方式就是极其小号资源的。
在MySQL 8之后,就开始支持 隐藏索引(invisible indexes),只需要将删除的索引设置为隐藏索引,是查询优化器不再使用这个索引,确定设设置为隐藏索引之后操作不受影响,就可以直接将该索引彻底删除,这种先将索引设置为隐藏索引,再删除索引的方式就是软删除。
同时,你如果向验证删除某个索引之后的查询执行效率,就可以先暂时隐藏该索引。
1. 创建隐藏索引的方式
- 创建表时
create table book4(
book_id int,
book_name varchar(100),
authors varchar(100),
info varchar(100),
comment varchar(100),
year_publication year,
index idx_cmt(comment) invisible -- 设置comment为隐藏索引
);
- 创建表后
alter table book4 add unique index uk_idx_bname(book_name) inviaible;
create unique index uk_idx_bname on book4(book_name) invisible;
2. 修改索引是否隐藏
将uk_idx_bname 修改为可见状态
alter table book4 alter index uk_idx_bname visible;
注意:
当索引被隐藏之后,它的索引状态仍然会实时更新。如果一个索引被长期隐藏,那么可以先将其删除,因为索引的存在会影响 增删改 的性能