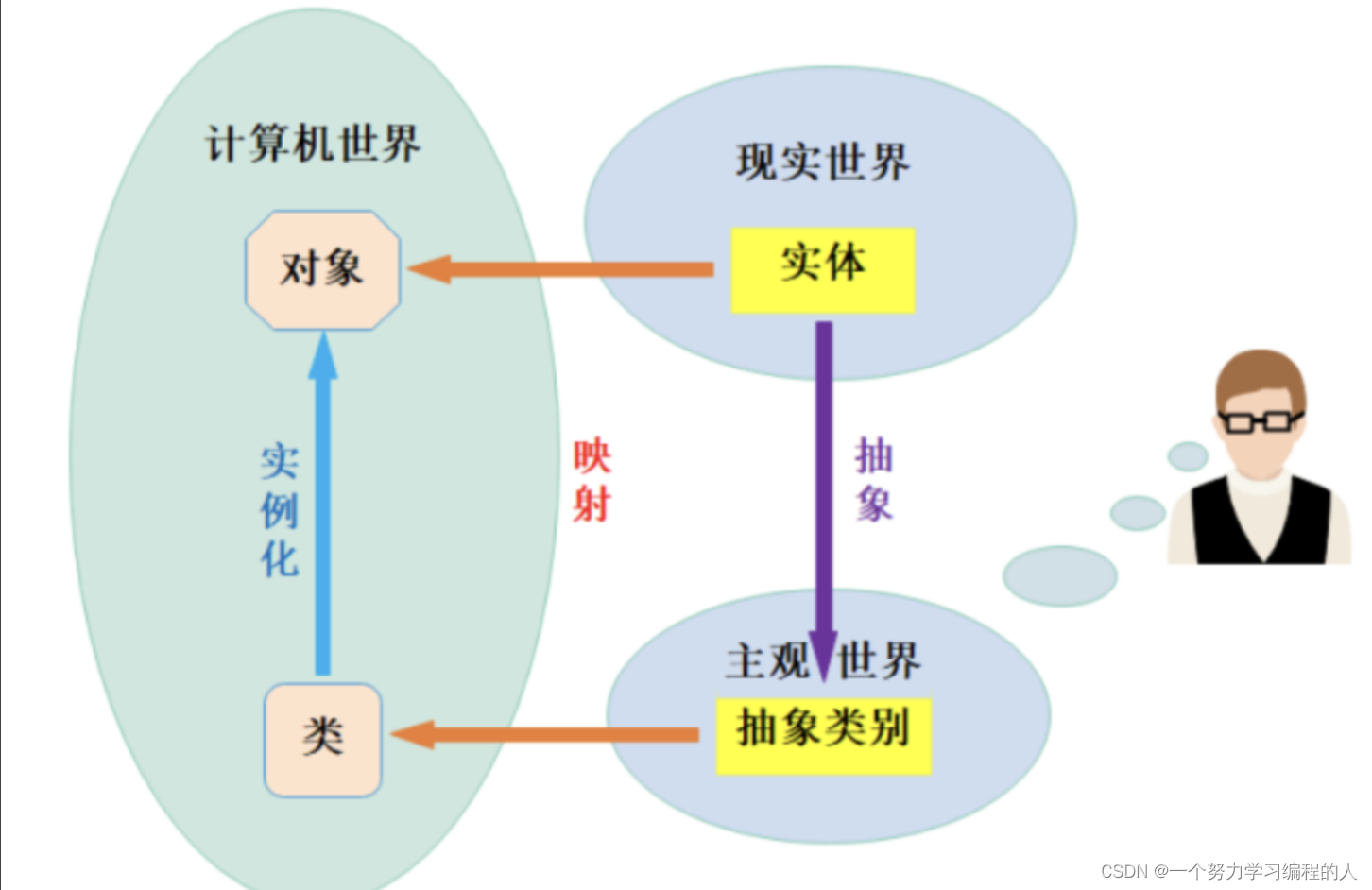
背景
keras深度学习框架,并不是一个独立的深度学习框架,它后台依赖tensorflow或者theano。大部分开发者应该使用的是tensorflow。keras可以很方便的像搭积木一样根据模型搭出我们需要的神经网络,然后进行编译,训练,测试,预测。
今天介绍的手写数字识别实验,主要是熟悉keras搭建神经网络的流程,以及大体的思路。现如今,手写数字识别实验的代码各种各样,对于初学者而言,我们需要的是类似helloworld那样简单的示例。通过示例,我们可以了解神经网络的搭建过程。
这里使用的手写数字识别,通过搭建网络,构建模型,最后保存模型,然后我们加载模型,通过真实的图片来预测,也检验一下神经网络的能力。
这里手写数字识别数据来源于官方自带mnist数据集,这个数据集包含60000个训练集和10000个测试集。每个数据是由28 * 28 = 784个矩阵元素组成。所以我们自己用来测试的图片最后应该也要按照这个28*28的尺寸来制作,并且最后进行预测predict的时候,也要像训练集或者测试集一样,把图片转为一个784元素的数组。
准备代码
import keras
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Activation
from tensorflow.keras import datasets, utils
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
x_train = x_train.reshape((-1, 28*28))
x_train = x_train.astype('float32')/255
x_test = x_test.reshape((-1, 28*28))
x_test = x_test.astype('float32')/255
y_train = utils.to_categorical(y_train, num_classes=10)
y_test = utils.to_categorical(y_test, num_classes=10)
print('x_train.shape', x_train.shape)
print('x_test.shape', x_test.shape)
print('y_train.shape', y_train.shape)
print('y_test.shape', y_test.shape)
"""
layer = [Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax')]
model = Sequential(layer)
"""
model = Sequential()
# model.add(Dense(units=784, activation="relu", input_dim=784))
model.add(Dense(512, activation="relu", input_shape=(28*28, )))
model.add(Dense(10, activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
history = model.fit(x_train, y_train, epochs=5, batch_size=128, validation_data=(x_test, y_test))
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label="Training accuracy")
plt.plot(epochs, val_acc, 'b', label="Validation accuracy")
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
model.save("mnist.h5")
prediction = model.predict(x_test[:1], batch_size=32)
print(x_test[:1])
print(y_test[:1])
print(prediction)
print(np.argmax(prediction, axis=1))这个代码在引入了相关库之后,进行的第一件事就是数据处理:
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
x_train = x_train.reshape((-1, 28*28))
x_train = x_train.astype('float32')/255
x_test = x_test.reshape((-1, 28*28))
x_test = x_test.astype('float32')/255
y_train = utils.to_categorical(y_train, num_classes=10)
y_test = utils.to_categorical(y_test, num_classes=10)
print('x_train.shape', x_train.shape)
print('x_test.shape', x_test.shape)
print('y_train.shape', y_train.shape)
print('y_test.shape', y_test.shape)我们的数据集x_train,x_test就是我们的图片数据,这个数据是784个元素组成的数组,我们先进行转矩阵,然后对像素点取模,得到0-1之间的值。我们代码最后打印了x_test[:1],可以看看它的样子:
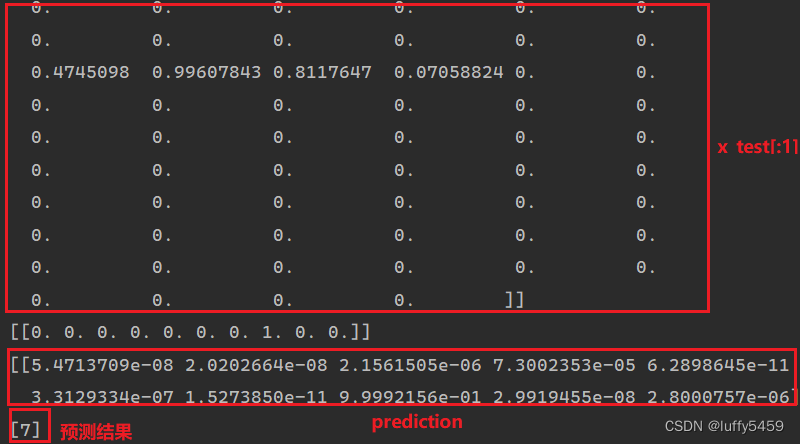
这里我们还使用了utils.to_categorical(y_test,num_classes=10) 对我们的目标进行了one-hot转码。通过这个图我们也看到了,数字 7 转了one-hot编码之后,变为了[0,0,0,0,0,0,0,1,0,0]。
这个代码构建了一个简单的神经网络,也就两层,
第一层输入层 Dense(512,activation="relu",input_shape=(28*28, )) #512个节点,relu激活函数,输入形状或者维度 28*28=784。代码中也给出了另一种通过input_dim来指定维度的方法,意思是一样的,但是那种写法model.add(Dense(units=784, activation="relu", input_dim=784))指定的网络节点units=784。这个数字可以随便定义。手写数字识别里面,设置512,784都可以。
第二层输出层 Dense(10, activation="softmax") #这里指定对应十个分类,也就是数字0,1,2,3,4,5,6,7,8,9的个数。手写数字识别是一个多分类问题。
没有隐藏层,也没有其他的Dropout。就是简单神经网络。
另外,代码中还给出了一种构建神经网络的办法:
layer = [Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax')]
model = Sequential(layer)意思是一样的,只不过,这里units=32,也就是输入层由32个神经网络节点组成。
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()这是编译神经网络和打印神经网络概要。
编译神经网络传入loss="categorical_cressentropy" 表示损失函数求的是交叉熵。optimizer="adam",表示优化器是adam,表示自适应算法,另外,也有可能会看到sgd,随机梯度下降算法,或者rmsprop也是一种自适应算法。metrics=["accuracy"]统计指标,这里指定成功率。
通过model.summary()我们可以看到神经网络节点信息:
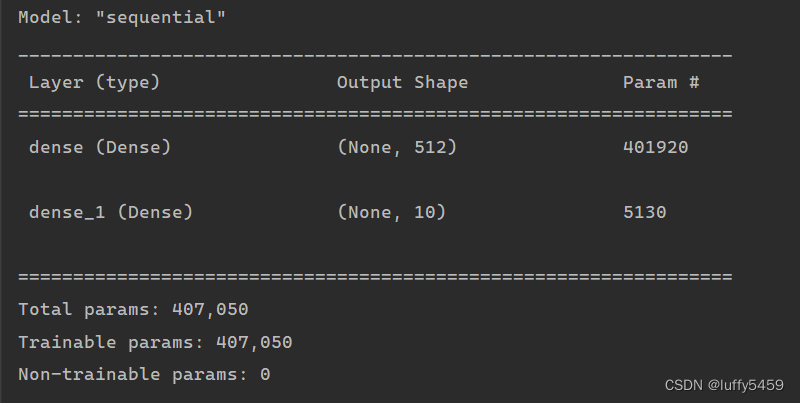
history = model.fit(x_train, y_train, epochs=5, batch_size=128, validation_data=(x_test, y_test))这里是把训练和测试神经网络放在一起了,我们传入的validation_data指定了测试数据集。如果不指定validation_data,那么后面,我们通过model.evaluate(x_test,y_test) 也可以得到loss,acc等数据。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label="Training accuracy")
plt.plot(epochs, val_acc, 'b', label="Validation accuracy")
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()我们通过matplot来展示acc,val_acc等信息,结果如下图所示:
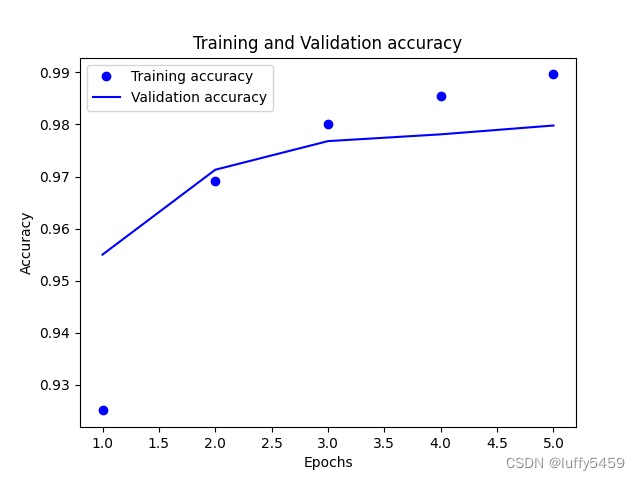
我们还通过model.save("mnist.h5")保存模型,后面我们会加载这个模型来进行预测。
prediction = model.predict(x_test[:1], batch_size=32)
print(x_test[:1])
print(y_test[:1])
print(prediction)
print(np.argmax(prediction, axis=1))我们简单通过测试集的第一个数字7来进行了一个验证,这个验证,主要是要知道我们将来传入图片需要什么类型的数据,以及得到预测结果之后,怎么取值。这里prediction是一个按照概率来进行组装的数组,哪个概率大,最终的结果就是谁。我们通过np.argmax(prediction, axis=1)指定获取一个数组中按行(axis=1)来统计最大的那个数。
***************************************************************
预测
很多代码示例里面,基本上到了model.evaluate()对算法进行评估之后,就没有了,对于刚入门的人来说,神经网络创建了,测试了,好不好用也不知道。因为这个训练集和测试机都是官网给出的例子,对于程序员来说,通过实践来验证一个猜测,那才是最重要的,至于这是什么不重要。
上面的代码最后,我们通过测试集x_test[:1]也就是第一个测试数字简单做了一个预测,大概知道了要预测,需要的数据是一个[28*28=784]的数组。而我们准备的测试图片应该也要和官方给出的测试数据对应上,也即是前面提到的图片是28*28像素的数字图片,如下所示:










同样的给出代码:
import keras
import numpy as np
import cv2
from keras.models import load_model
model = load_model("mnist.h5")
def predict(img_path):
img = cv2.imread(img_path, 0)
img = img.reshape(28, 28).astype("float32") / 255 # 0 1
img = img.reshape(-1, 784) # 28 * 28 -> 784
label = model.predict(img)
label = np.argmax(label, axis=1)
print('{} -> {}'.format(img_path, label[0]))
if __name__ == '__main__':
for _ in range(10):
predict("number_images/b_{}.png".format(_))
这些图片我们放在number_images目录下,命名规则是b_0.png,b_1.png这样子。
最后,我们加载模型,并通过opencv库加载图片,并转换图片矩阵为784个元素的数组。然后交给模型预测,预测结果是一个概率数组,取概率最大的那个数组元素。
预测结果如下:
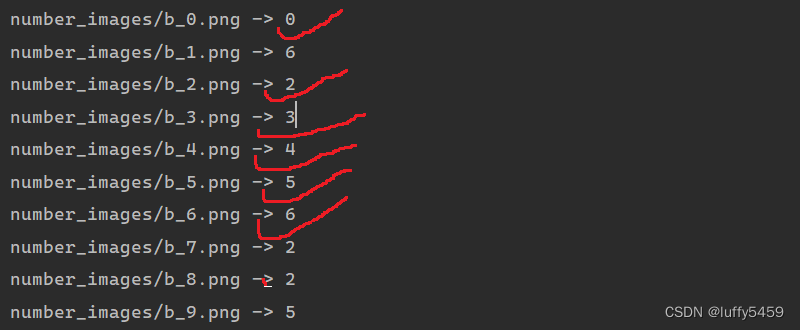
结果很感人,并没有达到很高的概率,准确率60%,而且这个概率对于手写图片识别来说,还有点偏高,因为实际上很多数字图片识别错误。
这篇文章,主要就keras构建简单神经网络,并进行训练,测试,最后还通过我们自己手写的数字图片来进行预测验证,也过了一把深度学习的瘾。
本文keras和tensorflow版本是2.8.0,可能有几个api与其他地方有区别,比如datasets,这里使用的是tensorflow.keras.datasets。另外在计算成功率acc的时候,使用的是history['accuracy'],有的地方可能直接是history['acc'],应该是版本的问题,根据自己的版本找到合适的方法就行。