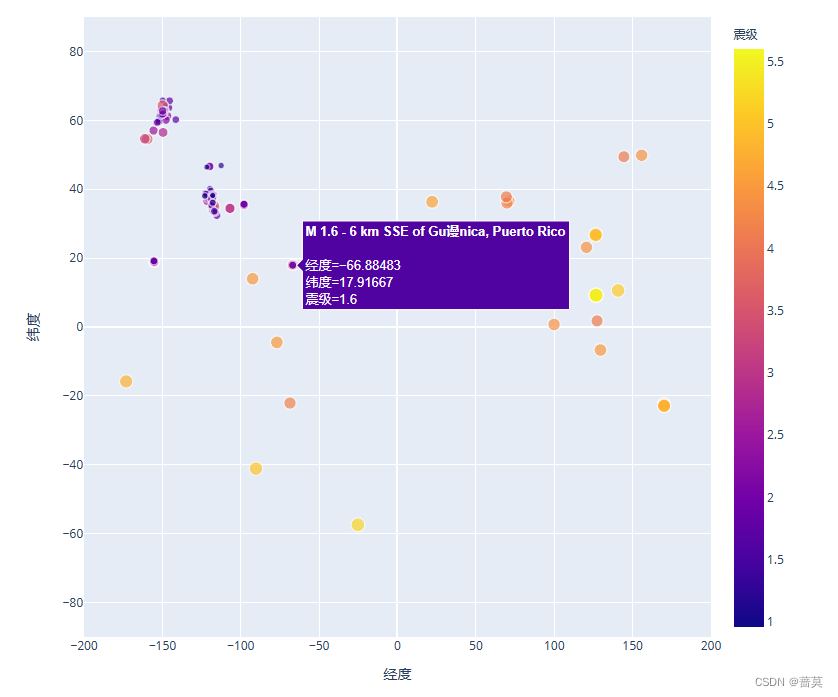
1.单列集合
1.1基础概要
集合中存储的是对象的地址信息,想要输出对象的信息,需要在具体的类中重写toString()方法
Collection代表单列集合,每个元素数据只包含一个值
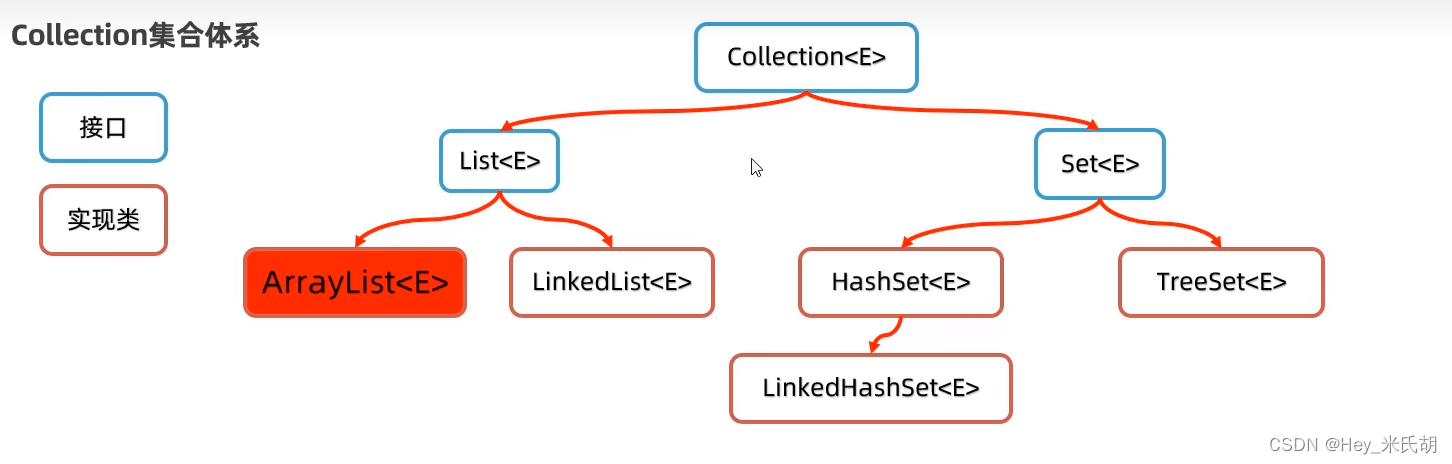
List集合:添加的元素可以是有序、可重复、有索引ArrayList,LinkedList,有序可重复,有索引
Set集合:添加的元素无序,不重复,无索引
HashSet,无序不重复,无索引。
LinkedHashSet,有序不重复,无索引
TreeSet:按照大小默认升序,不重复,无索引
Collection<E>接口的方法能被所有单列集合所调用,详细信息参考java开发文档
Collection<String> list=new ArrayList<>();//多态
Object[] list=list.toArray();将数组集合转为对象数组
#如果想要转换为其他类型的数组
//将数组集合转换为字符串数组,前提是集合里面都是字符串数据
list.toArray(new String[list.size()]);
1.2 Collection的遍历方式
迭代器
Collection集合获取迭代器的方法
Iterator<E> iterator(),返回集合中的迭代器对象,迭代器对象默认指向当前集合的第一个元素
#iterator()
//获取迭代器对象
Collection<String> list=new ArrayList<>();
Iterator<String>=list.iterator();//迭代器对象会存储和集合一样的数据类型
//迭代器遍历集合
#boolean hasNext(),该方法用于返回迭代器中是否还有下一位,用于判断取元素越界
#E next()获取当前位置的元素,同时将迭代器指向下一位元素
while(list.hasNext)
{
System.out.print(list.next());
}
实现思路,集合调用iterator()方法获取迭代器对象,然后通过迭代器内置方法,遍历数据
增强for
//可以遍历数组,也可以遍历集合
Collection<String> list=new ArrayList<>();
for(String s:list)
{
System.out.print(s)
}
lambda表达式
Collection<String> list=new ArrayList<>();
list.forEach(s->{System.out.print(s)})
1.3 List集合
特点及方法
`List<String> list=new ArrayList<>();`
`List<String> list=new LinkedList<>();`
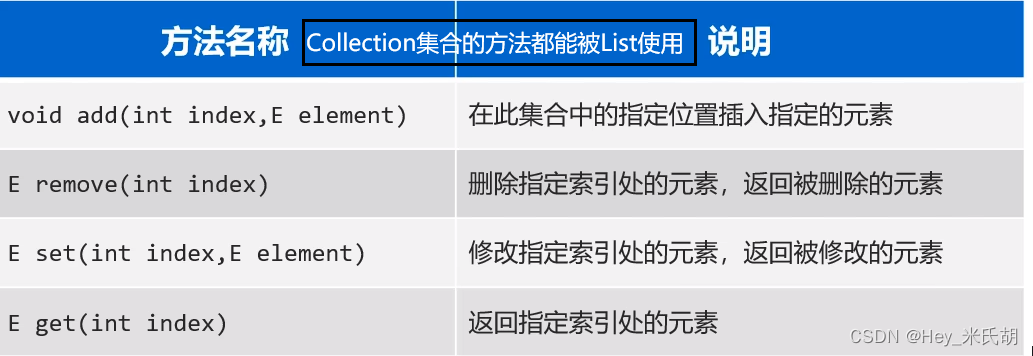
遍历
1.for循环
2.迭代器
3.增强for循环
4.Lambda表达式
ArrayList
基于数组实现
特点:
- 通过索引查询数据,查询速度较快
- 删除效率较低,删除某个数据时,需要将数据整体前移
- 添加效率低,在某个索引位置添加时,需要将数据整体后移,或者需要对数组扩容
- 利用无参构造创建集合,底层会默认创建一个容量为10的数组用作数组集合,当数据存满10个时,会扩容1.5倍
LinkedList
特点:
-
链表中的节点是独立的对象,在内存中是不连续的
-
查询较慢,需要从头开始查找
-
链表增删相对较快,不需要移动元素位置
-
LinkedList基于双链表实现的,双向链表即分别存储前节点和后节点,对于首尾元素增删改查的速度极快
双链表的方法
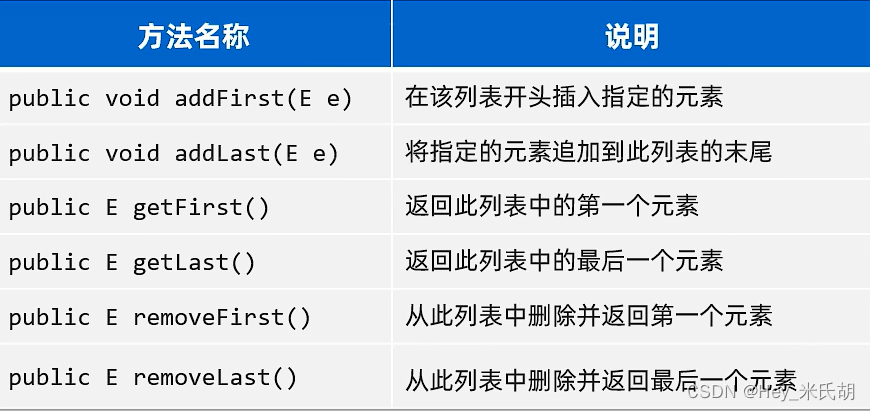
LinkedList的使用场景
1.设计队列
队列频繁操作对头和队尾元素,且队列是有序的LinkedList<String> queue=new LinkedList<>(); #进队,队尾进队 queue.addLast("一号"); queue.addLast("二号"); queue.addLast("三号"); #出队,对头出队 queue.removeFirst(); queue.removeFirst();2.设计栈
LinkedList<String> stack=new LinkedList<>(); //进栈 stack.addFirst("第一颗"); stack.addFirst("第二颗"); stack.addFirst("第三颗"); //出栈 stack.removeFirst();
1.4 Set集合
hashset
特点:无序,不重复,无索引
哈希值:一个int类型的数值,java中的每个对象都有一个哈希值
哈希值的获取 public int hashCode();返回值就是哈希码,该方法由Objeact类提供
同一个对象调用hashcode方法,获取的哈希值是一样的
不同对象,哈希值一般不同,也有可能相同int数值类型表示的范围-21亿~~+21亿
hashset集合是基于哈希表实现的,哈希表是一种增删改查数据,性能都较好的数据结构

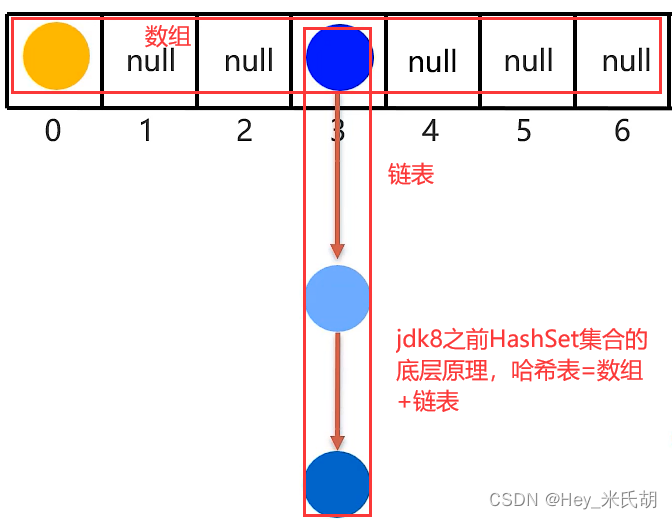
实现原理:
1.创建一个长度默认为16的数组,默认加载因子0.75
即当哈希表存储到16*0.75=12时,就需要进行扩容
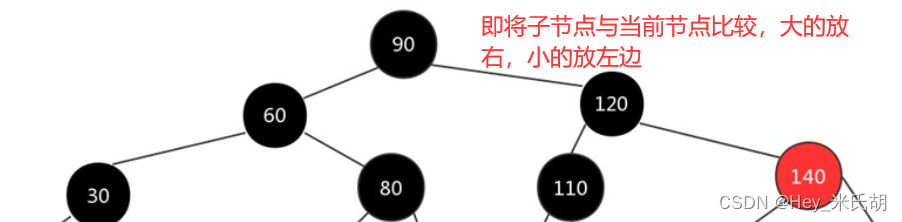
jdk8之后,当链表的长度>8,数组长度>=64,自动将链表转为红黑树
红黑树
2.获取具体对象的哈希值
3.对哈希值按数组长度进行取余操作
4.在取余操作后,在数组下标等于余数位进行存值5.如果多个对象在同一个下标位置,则当前下标位存储方式改为链表存储,在存储前,需要对元素逐个进行判断,一样的就不保存
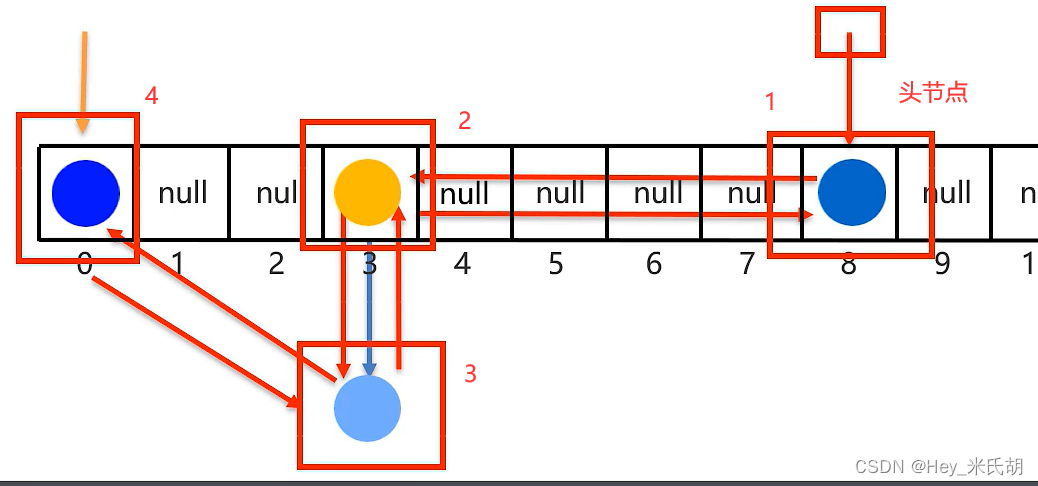
LinkedSet
特点:有序、不重复、无索引
- 有序的实现是通过使用双链表机制
- 无序:从下标0开始找,如果某个下标中有链表元素,则就必须先将该链表元素找完后,再找其他下标的元素
- 引入双链表后,Linkedset集合为有序
TreeSet
特点:排序(默认升序),不重复,无索引
排序是基于红黑树实现的
- 对于Integer\Double类型,默认按照数值本身排序
- 对于字符串,默认按照首字符的编号排序
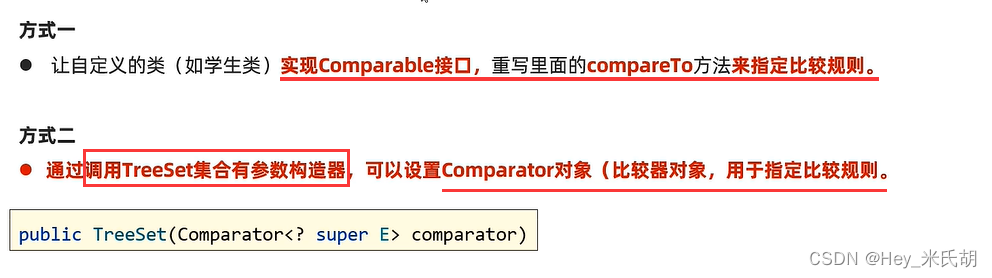
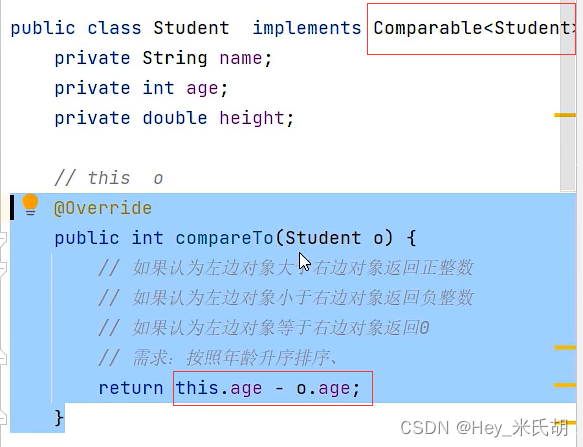
- 对于自定义对象,需要自定义排序,方法如下
总结 - 有序、有索引、可重复,且频繁的根据索引查找数据—ArrayList,底层基于数组实现
- 有序、可重复、有索引,且增删首位数据频率较多—LinkedList,底层基于双链表实现
- 无序、不重复、无索引,增删改查都快—HashSet,底层基于哈希表实现
- 有序、不重复、无索引,—LinkedHashSet,底层基于双链表实现
- 排序、不重复、无索引,—TreeSet,底层基于红黑树实现
遍历删除时,发生异常
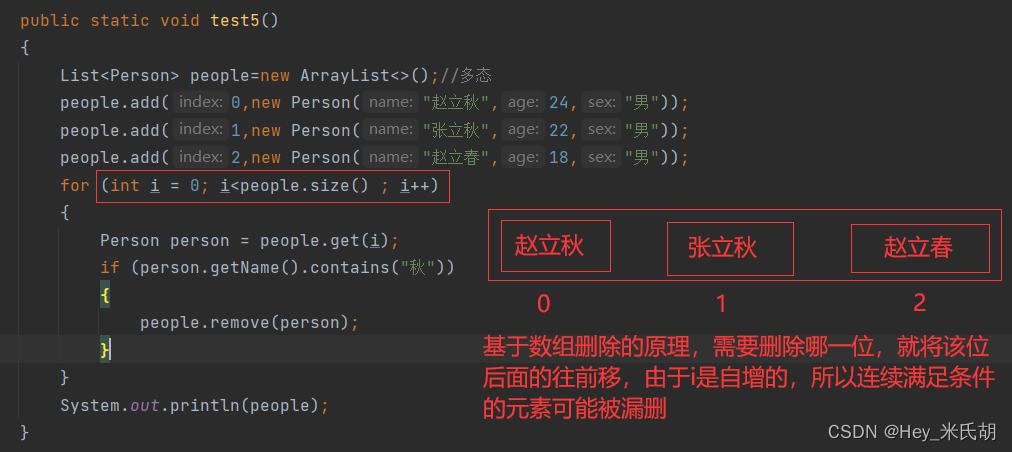
#集合遍历,根据条件删除,没有完全删除的解决方案
//for循环
public static void test5()
{
List<Person> people=new ArrayList<>();//多态
people.add(0,new Person("赵立秋",24,"男"));
people.add(1,new Person("张立秋",22,"男"));
people.add(2,new Person("赵立春",18,"男"));
for (int i = people.size()-1; i>=0 ; i--)
{
Person person = people.get(i);
if (person.getName().contains("秋"))
{
people.remove(person);
}
}
System.out.println(people);
}
//迭代器遍历
Iterator<Person> iterator = people.iterator();
while (iterator.hasNext())
{
Person next = iterator.next();
if (next.getName().contains("秋"))
{
iterator.remove(); //底层的逻辑就是i--
}
}
System.out.println(people);
}
1.5 Collectoion的其他知识
可变参数
即可选择传参也可选择不传参
特点:
1.一个形参列表中,只能有一个可变参数
2.可变参数必须放在形参列表的最后
3.可变参数在方法内部就是一个数组
public static void test(int age,int...nums)//...nums就是可变形参
Collections
不是Collection集合,而是一种操作集合的工具类

使用上述中的sort方法,如果参数中的集合是类对象,想要进行排序就必须在该类实现Comparable接口,指定比较规则
2.双列集合
map代表双列集合,每个元素包含两个值,键值对
map集合中,键不能重复,值可以
应用场景:一 一对应
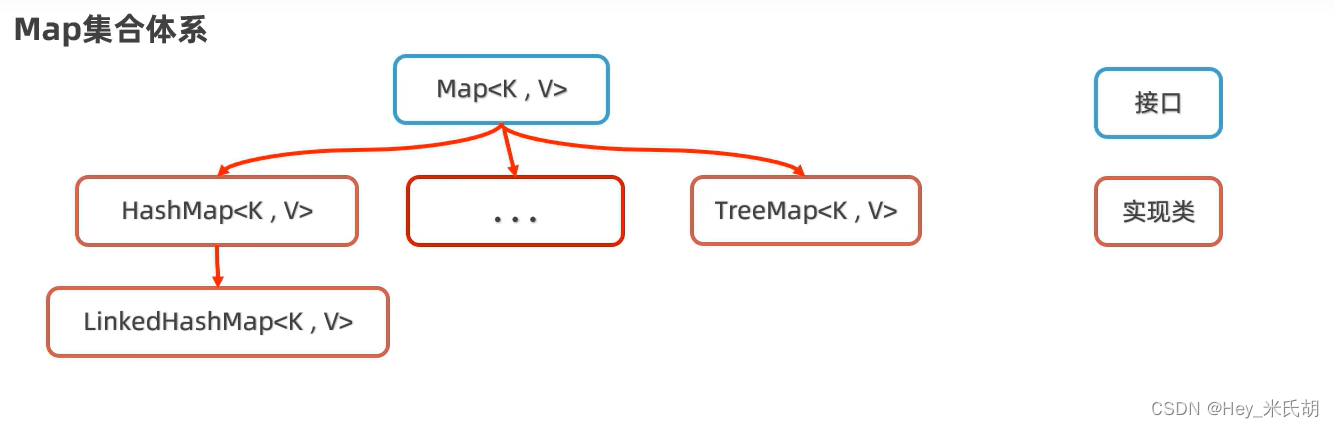
Map集合的特点
- HashMap:无序、不重复(键相同时,后者覆盖前者)、无索引
- LinkedHashMap:有序(键决定)、不重复、无索引
- TreeMap:按照大小默认升序排序(键决定),无索引,不重复
map集合的遍历方式
1.entryset的方式,进行遍历
//双列转单列集合,将键值对转换成一个整体对象,通过增强for遍历
Map<String,String> map=new HashMap<>();
Set<Map.Entry<String,String>> entry=map.entrySet();
for(Map.Entry<String,String> en:entry)
{
en.getKey();
en.getValue();
}
2.Lambda表达式遍历map集合(jdk8版本后可用)
map.forEach((k,v)->
{
System.out.print(k+"--->"+v);
}
);
Map集合遍历案例
#Map集合,模拟投票
public static void test2()
{
List<String> list=new ArrayList<>();
String [] str={"A风景区","B田园","C公园","D王府井","E万达广场"};
Random random=new Random();
for (int i =1; i <=35; i++) {
int index = random.nextInt(5);
list.add(str[index]);
}
Map<String,Integer> scenery=new HashMap<>();
for (String i:list) {
if (scenery.containsKey(i))
{
scenery.put(i,scenery.get(i)+1);
}
else
{
scenery.put(i,1);
}
}
System.out.println(scenery);
}
HashMap底层原理
- HashMap和HashSet的底层原理一样,都是基于哈希表完成的
- JDK8之前,哈希表=数组+链表
- JDK8之后,哈希表=数组+链表+红黑树
- 哈希表是一个增删改查数据,性能都比较好的数据结构
- HashMap的存储原理,是用键的哈希值取余,确定存储位置的
HashMap实现键值唯一:
- 如果键不是一个自定义类,则函数发现键值重复的时候,后者会覆盖前者
- 如果键是一个自定义的类,那么就需要在该类中重写equals和hashcode的方法
LinkedHashMap底层原理
- 底层是基于哈希表实现的吗,每个键值对元素采用双链表机制存储
- 有序、不重复、无索引
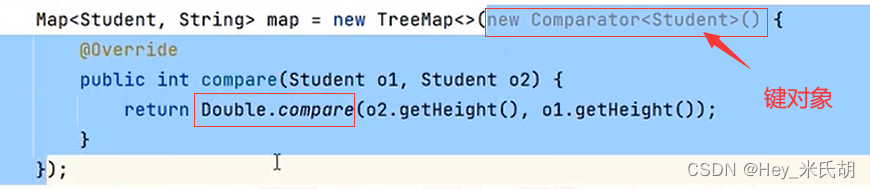
TreeMap
- 排序,不重复,无索引
- 根据键值排序,如果键值是一个类
1.通过在该类中实现Comparable接口,重写compareTo()方法

2.在TreeMap的构造方法中,创建比较器
集合嵌套
public static void test4()
{
List<String> city=new ArrayList<>();
Collections.addAll(city,"南充","成都","攀枝花","达州");
Map<String,List<String>> map=new HashMap<>();
map.put("四川",city);
System.out.println(map);
//{四川=[南充, 成都, 攀枝花, 达州]}
}```

![[C++] STL_vector 迭代器失效问题](https://img-blog.csdnimg.cn/947fb7d35e7249d091e02ec54f5e01fc.png)
![[GDOUCTF 2023]EZ WEB](https://img-blog.csdnimg.cn/c129bf06a5a547269d25573e340e591b.png)