导读
在计算机科学的发展史上,硬件算力、算法程序与计算数据总是螺旋上升。在硬件相同的条件下,算法的效率和优化程度决定了其利用硬件资源的能力,从而直接影响计算机的算力。因此,为了提升计算机系统带来的综合效益,计算机编程和人工智能算法设计旨在最大化地利用计算机的算力,设计高效的算法以提高计算效率。
深度学习发展到今天,基于 Transformer 的 LLM 模型在推理效率、并行计算能力、长序列建模能力等方面逐渐显现出不足之处。面对海量的计算数据、复杂的下游任务、更高的效能要求,如何实现更快的训练、更小的推理开销、更强的模型性能是当下人工智能研究领域的「核心问题」之一。
2023 年 7 月 25 日,来自微软研究院、清华大学的学者在 Arxiv 上发布了论文「Retentive Network: A Successor to Transformer for Large Language Models」,旨在同时实现低成本推理、并行训练、较强的长序列建模能力,使 CNN、RNN、Transformer 等时代传统意义上的「不可能三角」成为了可能,可谓「质效皆优」。正如论文名所称,RetNet 有望成为 Transformer 的「继承者」,成为 LLM 时代新的支柱性基础架构。智源社区特别邀请了作者之一清华孙宇涛针对RetNet核心进展和未来应用进行了采访,以下为技术解读和访谈原文。
采访:李梦佳 编辑:熊宇轩
LLM 时代的重要应用:长文本建模
步入大语言模型时代,长文本建模任务广泛存在于「多轮对话」、「信息检索」等任务中。长文本建模任务面临序列长度限制、计算效率要求高等挑战。为此,研究人员采用「文本截断」、「文本分块」、「文本选择」等技巧来优化模型,提升建模性能。
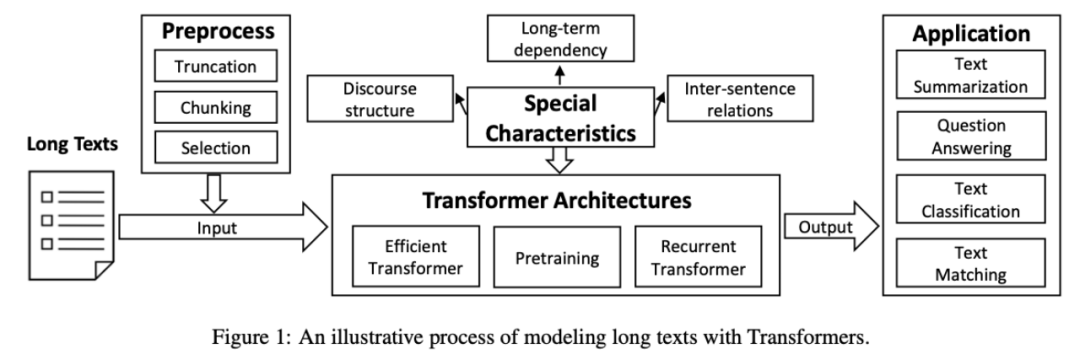
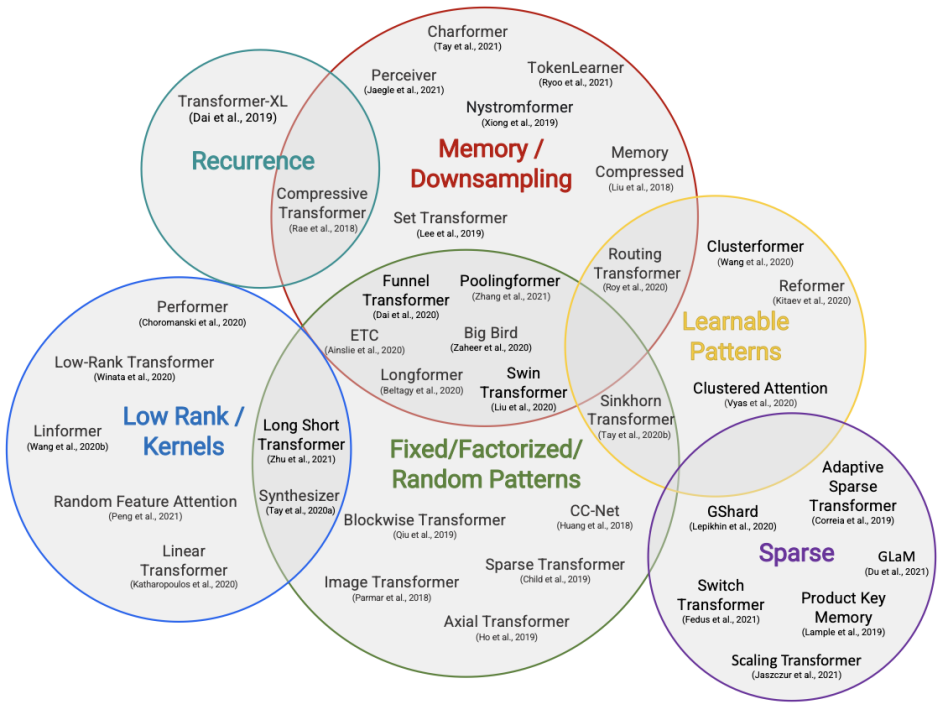
在计算架构方面,原始的 Transformer 模型的计算复杂度会随序列长度增长而指数级上升,面对长文本建模任务亟需提升其计算效率。为此,学者们提出了基于固定模式分析、可学习模式分析、注意力近似、高效编码解码注意力机制设计、循环 Transformer 设计、长文本预训练等技术的解决方案。此外,在 NLP 层面上,一些学者也提出针对长文本的特殊性质(例如,长距离依赖、句间关系、篇章结构)引入归纳偏置,提升建模性能。
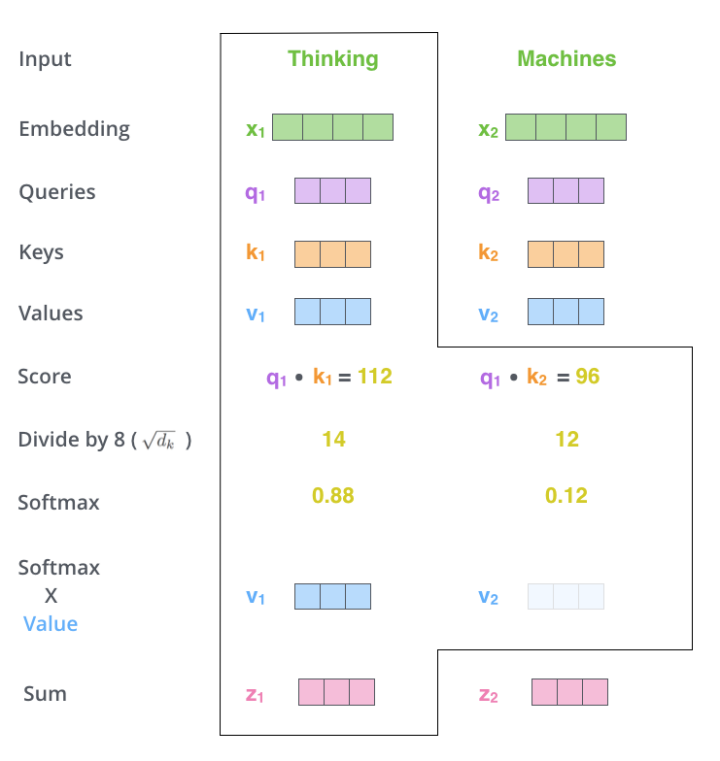
具体而言,Transformer模块内的计算过程如上图所示。在 Softmax 函数内部,Q 与 K 的内积的计算复杂度为 O(N^2),当 N 较大时,将引入巨大的计算量。
相较于被广泛使用的 Transformer ,RetNet 也使用了类似于 Q、K、V 的张量运算机制,借用了 xPos、ROPE 等位置编码思想建模序列中 Token 的位置信息,在局部、长程序列建模方面有很好的表现。不同之处在于,RetNet 去掉了 Softmax 函数,实现了递推和分块处理,有利于并行计算和推理。
RetNet 模型与 S4 模型有紧密的联系。如果将 RetNet 中 Q、K 的计算以上下文无关的方式实现(将其视为可学习的位置无关的变量,而非通过 X 映射得到),就可以将 RetNet 退化为 S4 模型。而 S4 之所以在语言任务上性能弱于 Transformer ,正是由于其忽略了语言丰富的层次特征。RetNet 由此获得了强于 S4 的性能。
基于线性注意力的 Transformer 架构以牺牲位置信息为代价,采用核方法模拟了 Softmax 计算,无法处理多尺度信息。相较之下,RetNet 从头开始实现递推形式的序列建模。
相较于近期的 AFT/RWKV 等工作:使用更高维的隐状态建模中间变量,提升了上下文容量。
值得一提的是,尽管在性能、推理开销、并行计算能力上各有千秋,但上述所有方法都并未在自然语言场景下达到与原始 Transformer 相当的综合性能。而随着大模型时代的到来,人们对于更快、更强、更廉价的基础模型的呼声与日俱增。
LLM 时代的新模型基座:RetNet
人们设计深度学习模型的动机主要包括:(1)建模数据分布(2)提升模型在下游任务上的性能。在大模型部署场景下,基于 Transformer 的模型性能存在较为明显的「瓶颈」。在推理过程中,所有步自注意力步骤的中间结果(K、V)都会被存储下来。这样一来,计算、输入/输出的时间开销和内存的空间开销都会上升,这种弊端在处理长文本时尤为明显。
RetNet 的贡献主要包括:
(1)给出了 Rentention 的三种等价形式:并行、递推、分块,分别对应于语言模型训练、长序列建模、长文本训练工程实现中的需求。
(2)通过多尺度门控 Rentention 使各个注意力头都可以建模多尺度信息,并且互相之间不受影响,对于提升模型性能和稳定性都有很大的帮助。
(3)去掉了非线性的 Softmax 操作,对表征引入了门控的 Swish GLU 函数,补充了模型的非线性处理能力。
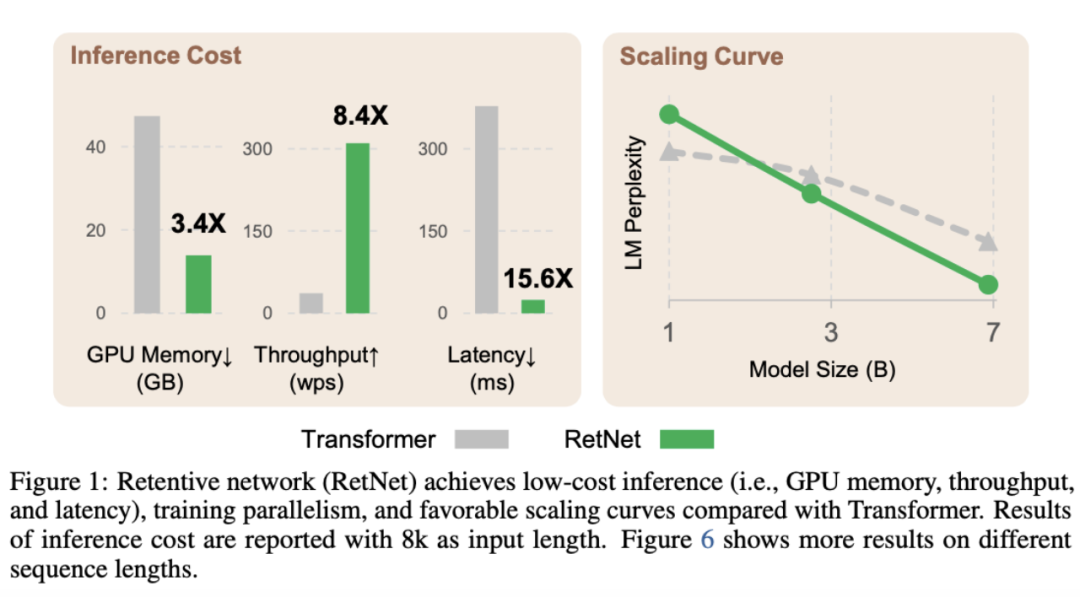
在保持与 Transformer 性能相当的前提下,RetNet实现了并行化训练和开销更低的推理,其推理开销与序列长度无关。当序列长度为 8K,模型参数量为 7B 时,RetNet 的解码速度为带有键/值缓存的 Transformer 的 8.4 倍,内存开销则下降了 70%。RetNet 训练时占用的内存相较于标准的 Transformer 节省了 25-50%, 其训练速度为后者的 7 倍。RetNet 的推理延迟不会受到 batch size 的较大影响,其吞吐量较 Transformer 有巨大提升。
RetNet 的诞生有望大大降低 LLM 的训练、使用门槛,促进 LLM 在边缘计算设备上的应用。未来,甚至「一部手机也可以运行 LLM」。
RetNet 有多强?
RetNet 究竟有多强?我们通过原始论文中的实验结果来感受一下:
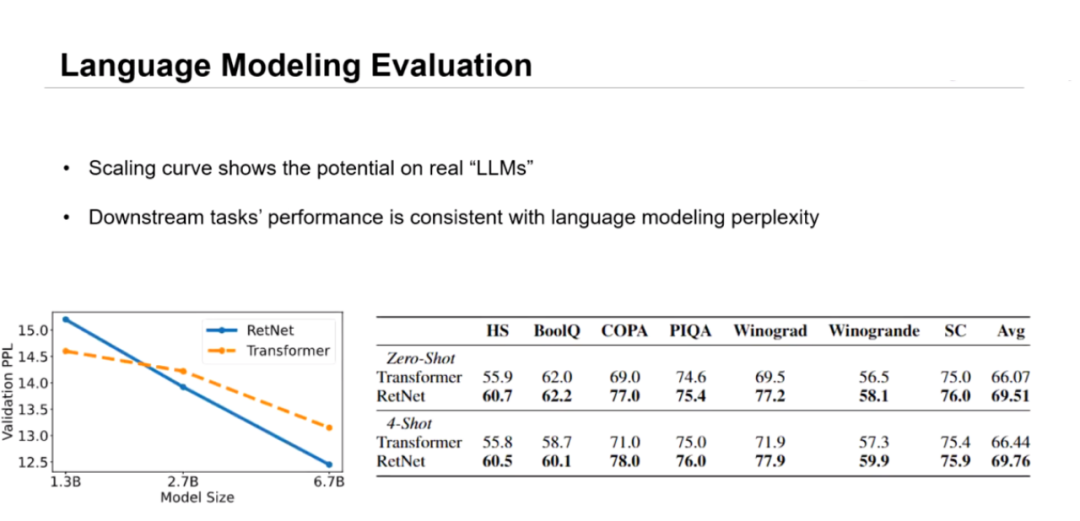
长文本建模是 LLM 的重要应用场景之一。在模型参数量为 1.3B 时,RetNet 还未显现出性能优势,而随着模型规模不断扩大到 2.7B、6.7B RetNet 相较于 Transformer 的 PPL 优势就逐渐显现出来,且越来越明显。
零样本、小样本场景下可以充分显现大语言模型的涌现性能。当模型参数量为 6.7B 时,RetNet 在小样本、零样本下游任务上实现了与 Transformer相当的性能。可见,RetNet 在保证性能不弱于 Transformer 的情况下,极大提升了模型的运行效率,降低了 LLM 的应用门槛,促进了业态的革命性迭代。
在具体操作层面上,「究竟使用怎样的算力可以成功实现 RetNet 模型的训练和推理」是许多算力有限的初创企业和科研院迫切关心的问题。
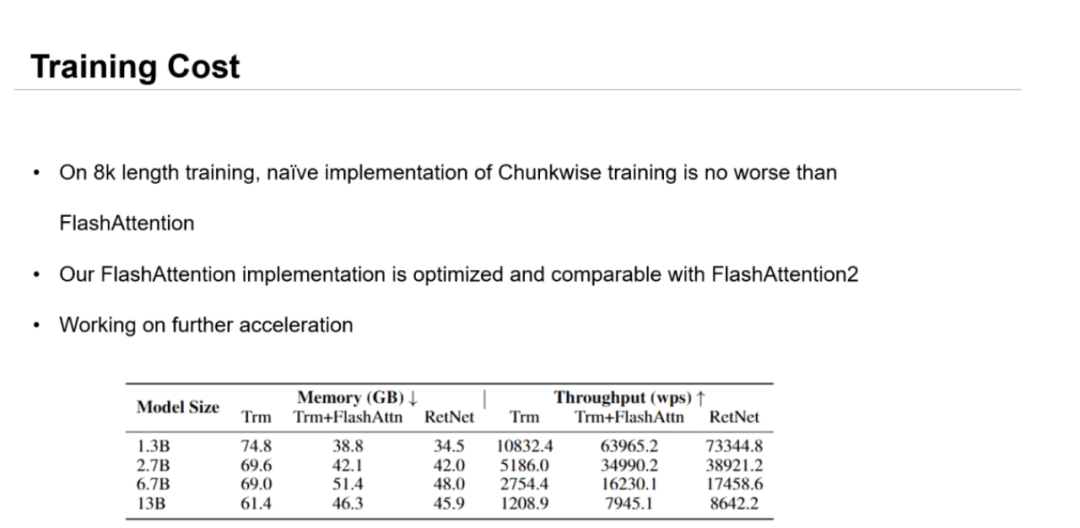
在训练方面,以长度为 8K 的序列为例,训练分块形式的 RetNet 所需的内存空间不到原始 Transformer 的一般,甚至低于基于 FlashAttention 的 Transformer。同时,RetNet 的吞吐量接近原始 Transformer 的 7 倍,且仍然显著高于给予 FlashAttention 的 Tranformer,好比「马儿又能跑,又不怎么吃草」。即使不对 RetNet 进行底层优化,其性能也优于优化后的 FlashAttention,且与 FlashAttention2 相当。
值得注意的是,RetNet 并不依赖特定的内核,可以在 Nvidia A100 和 AMD MI200 计算集群上完美训练,具有相当强的跨平台通用性。
RetNet 的高效与通用性大大降低了训练的硬件要求门槛,让更广大的从业者可以参与到 LLM 的工作中,降低了业界使用 LLM 的计算开销和能源消耗,有望带来巨大的经济效益。
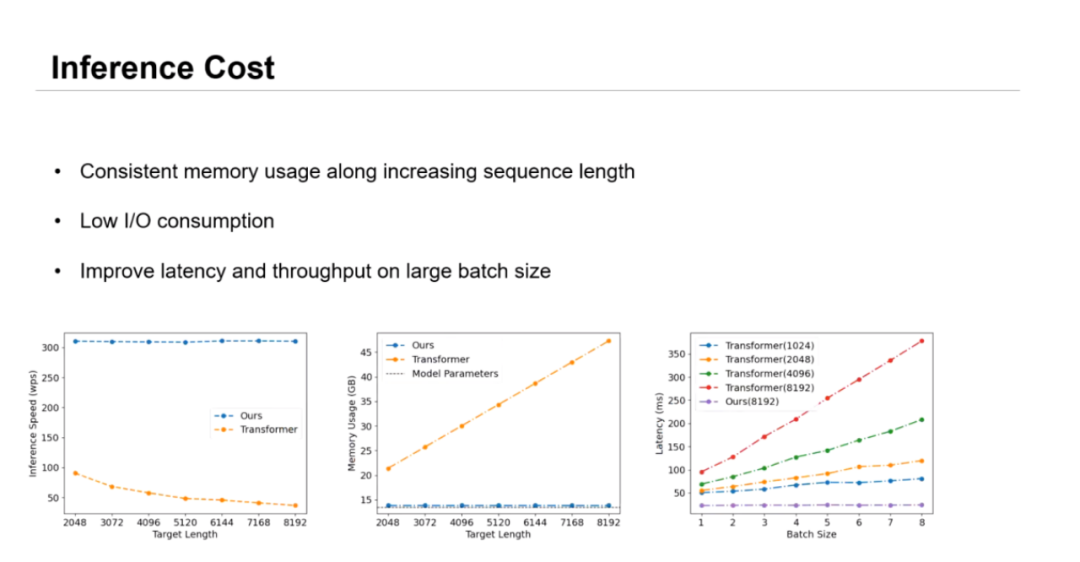
相较于训练上的效率提升。RetNet 在推理过程中的优势更加显著。在显存占用方面:RetNet 的显存开销为 O(1),推理所需的显存开销并不会随着序列的程度增长而增大,吞吐量相较于 Transformer 有巨大的提升,非常有利于长序列建模和边缘部署。RetNet 节省了 I/O,对延迟的优化更加友好。
RetNet 的优良性能
相较于已有的 Transformer 类模型,RetNet 具备以下优良性能:

(1)建模效率高。尽管线性 Transformer 等基于 Transformer 的网络已经有较好的建模能力,但是其在大规模长序列数据集上的建模效率仍然较为低下。RetNet 在代码、视频、语音等复杂长文本场景下也具有一定的应用潜力。
(2)并行训练优。当模型规模特别大时,张量并行已经不能满足模型训练的效率需要,需要做训练并行。基于分块机制的 RetNet 天然契合序列并行任务,可以在机器之间传输隐状态的递归类信息,极大减少网络的信息传输压力,优势十分明显。
(3)量化难度低。对模型做量化优化时需要对 Softmax 函数进行处理(例如,峰值截断)。RetNet 的线性变化形式对于量化操作十分友好,可以进一步增大其在推理中的优势。
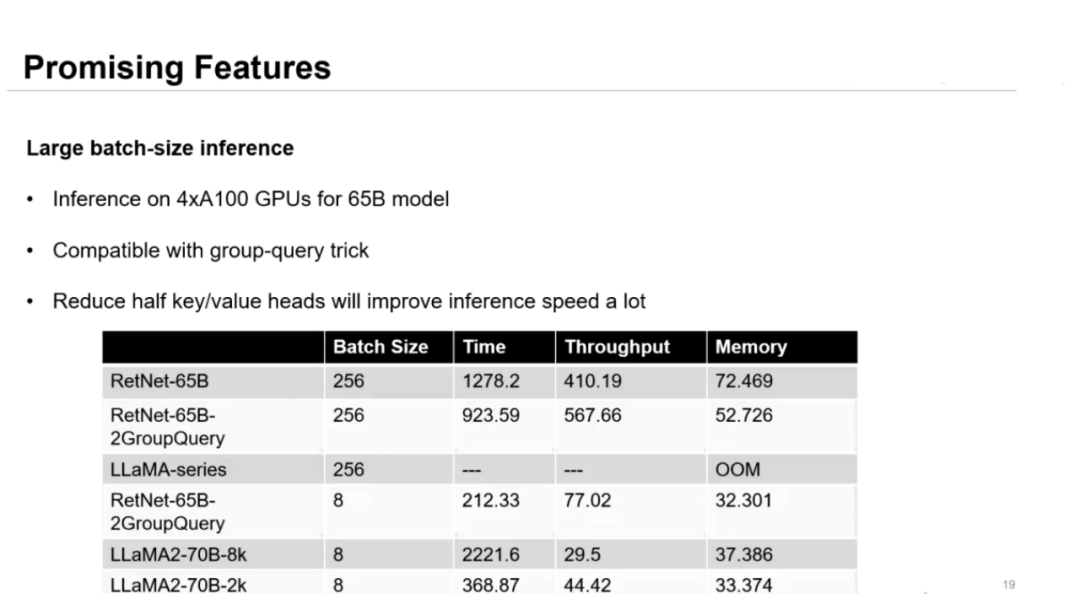
作者在拥有 65B 参数的更大的模型上用 4 张 Nvidia A100 显卡进一步验证了模型在使用大 batch-size 时的性能。实验结果表明,模型与 Group-query 技巧相兼容,可以通过去除一半的注意力头大幅度提升推理速度。
论文链接:https://arxiv.org/pdf/2307.08621.pdf
项目链接:https://aka.ms/retnet
Q&A
Q1 :研发 RetNet 背后的动机是什么?团队做过哪些立项调研,确定该题目的可行性?
现在绝大多数研发大模型的公司、机构,都会碰到一个瓶颈。即在实际部署达模型的过程中,部署成本高,延迟过长,这对大模型更广泛的应用造成严重瓶颈。
这是一个老生常谈的问题,之前的研究者提出了一些解决方案。但这些针对 Transformer 的改进方法在 LLM 场景下并没有更普遍的适用性。此前的工作更多是在特定实验数据上有比较好的表现。
所以我们在实际研发 RetNet 之前,调研复现了之前几乎所有能够高效推理的方案,发现在标准的场景下,这些方案在性能上距离 Transformer 还有很大差距。
我们的研究动机是:(1)在满足推理高效性的基础上,尽可能地提升性能。(2)确保模型的泛用性。越简单的架构,往往泛用性越强。
因此,我们形成了一个很清晰的思路,从递推性出发,得到一些很简洁的式子。从某种程度上说,Rentention 可能是为数不多的序列建模实现方案之一。
从可递推性的角度来说,Rentention 是一个非常普遍的方案,实现了对之前模型更高层次的概括,改模型会表现出比以往模型更强的特征。
没有任何理论能证明 Transformer 就是最好的。自 2017 年被提出以来,有很多工作企图去改进 Transformer 的性能。语言数据建模需要把握数据分布,理解语言的特征,在满足期望特性的情况下进一步开展研究。
Q2:深度学习经历了 CNN、RNN,再到现在Transformer架构的发展过程,是什么节点导致了这些架构的更新?
Transformer 是一个革命性的工作,定义了 AI 发展的一个阶段。在 CNN、RNN 时期,我们针对特定场景设计特定的模型,这种设计对某些局部的任务是更有好处的。
此外,在 Transformer 诞生前的深度学习发展早期,从业者没有足够的算力做更大的模型。小模型往往无法实现长距离依赖。在大模型时代,我们可以直接参考更远的 Token 特征,这不仅仅是 Transformer 的贡献,更是硬件的贡献。
在充足算力的支持下,Transformer 应运而生,将整个 AI 业界的范式从小数据小模型转到大数据大模型。可以说,Transformer 代表了大数据的流派。同时,研究者们解决了可并行性的问题,提供了相应的高效训练的场景。在特征建模方面方面,Transformer 能把更多的特征吸收进来,这就是它和之前架构相比最主要的区别。
Q3:能否更浅显易懂地解释 Retnet 架构?相比于Transformer,它有哪些主要的变革意义?为何有人称其为「M1芯片级别的变革」,最强的提升在哪?
在当前的数据使用场景下,Transformer 提供了很强的基线,使用者也可以在 Transformer 基础上做出改进。RetNet 的研究重点并不在提升 Transformer 在具体任务上的性能,而是降低其使用门槛。RetNet 希望能在低消耗、显存受限的情况下,「让大模型真正地飞入千家万户」。
具体而言,我们放弃了 Transformer 思想中每一对 token 之间都需要进行交互的思想。从计算的角度来说,每一对 Token 进行交互是可以实现的。然而,没有证据证明 Transformer 的出色性能是逐对 token 交互带来的。二者之间没有因果关系。
在计算的过程中,Transformer 的梯度(gradients)比较简单,可优化性比较强,RetNet 也具备这一优点。基于这一点,我们抛弃了Transformer 粗放式的 Token 交互计算模式,转而从可递推性出发,去掉了 Softmax 函数,弱化了 Token 之间的交互计算,显著降低了推理成本和显存占用。
Q4:RetNet 主要针对大模型场景开发,要发挥其优势,对训练数据的数据量有何要求?
从泛用性的角度说,RetNet 要求模型规模要大、数据量要多。RetNet 主要针对长序列建模的训练场景开发(例如,长视频、长文本),这种场景下更能发挥其优势。现有的 CNN、RNN、Transformer 等模型在小数据量的任务上已经有很强的建模能力,并不是 RetNet 设计所考虑的主要问题。
Q5:畅想一下,RetNet架构对深度学习技术的发展会产生哪些影响?
最重要的影响是,如果大模型社区接受 RetNet 作为新的骨干网络,能真正降低推理成本,提高大模型可用性,进而推动更多的人进行基础模型研究。
此外,除了语言场景,还有很多任务存在许多长序列建模需求(包括音频、视频等)。目前的专用 Transformer 模型,需要引入许多技巧。做好 RetNet 架构,有希望在更多的数据场景下产生更好的影响。
Q6:推广 RetNet 走向大规模实用,还需要做哪些工作?
一方面,研究者需要优化模型架构本身,整个研究社区需要在开源平台的支持下,推广大家将该模型应用到各个下游任务场景中。
最基础的一点在于,在下游任务上,要有足够好的数据支撑我们得出好的预训练参数,为下游研究者、从业者提供便利。要想使 RetNet 取代 Transformer,还需要在更多任务上对 RetNet 的性能做验证,让大家真正接受它。
第二,RetNet 需要针对实际部署环境进行深度优化,包括底层的内核算子优化,各个硬件场景下的优化。例如,如果真正想让 RetNet 在 M1 芯片上运行,还有很多针对特定指令集的优化工作要做。目前的代码只是一个开源的算法原型。
Q7:未来在这个大模型下游应用上会有哪些潜力?如何飞入千家万户?
首先,我们需要建立很强的模型架构,并提供泛化性很好的预训练参数。然后,我们还需要再进行模型尺寸裁剪、推理引擎量化、硬件平台适配等处理,使模型可以在个人电脑,甚至手机上以极低的功率来运行。
一方面,我们降低了模型的运行成本。另一方面,我们可以在手机端做一些相应的适配。模型的它的应用门槛会很低。
更多内容 尽在智源社区