Java 语言的面向对象,平台无关,安全,开发效率高等特点,使其在许多领域中得到了越来越广泛的应用。但是由于Java程序由于自身的局限性,使其无法应用于实时领域。由于垃圾收集器运行时将中断Java程序的运行,其运行时刻和垃圾搜集时间具有不确定性。在应用程序高频率分配和释放内存时,垃圾收集要占用的时间可能比程序自身运行的时间还要多。这些都使得 Java程序无法满足在实时领域应用的要求。
Java实时规范(RTSJ)的内存管理机制既保证了Java本身的内存安全的优势,同时又保证了在实时系统中对内存操作的的可预测性。不产生垃圾的代码不会导致请求式的垃圾收集;不引用堆中对象的代码可以抢占垃圾收集器的线程。为了能够保留垃圾收集的好处又能避免垃圾收集器对实时特性的影响,基于以上两个事实RTSJ扩展了Java内存管理机制,在传统的堆内存的基础上,又提出了内存区域(Memory Area)的概念。在新增加的这几个内存区域中分配对象不会导致垃圾收集器的执行,不会使系统受到其不可预测性的影响。
本文根据RTSJ的要求,介绍了RTSJ内存管理机制实现的各个基本要点,包括使用Display树的内存引用检查, LTMemory和VTMemory的分配机制, ScopeStack的维护等。文章通过研究一个可运行在多种操作系统并兼容多种硬件平台的开源的Java虚拟机SableVM的基础上,结合国内外最新的理论,提出了一个对其实时性进行改进的方案,并对其进行实验。该方案有别于国内外现有的实时Java虚拟机的实现,在内存管理方面即符合RTSJ的要求,同时又保证了Java程序可移植性的要求。
目录
5 实验结果与分析
5.1 实现方法
5.2 实验结果与分析
5.2.1 固定分配内存实验
5.2.2 递增分配内存实验
5.2.3 总结
5 实验结果与分析
5.1 实现方法
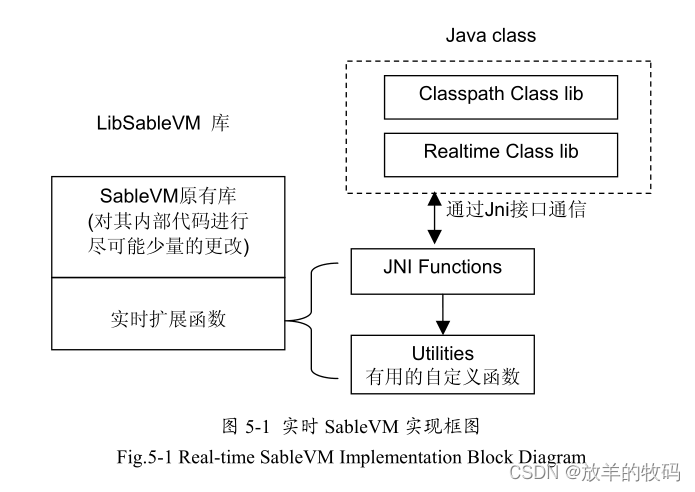
本实现结合了开源的Java虚拟机SableVM和开源的RTSJ实现jRate两者的优点,使 SableVM 实现了 RTSJ 内存管理机制。实现包括2 个部分,实时 Java 类库和虚拟机本地接口实现。实时 Java 类库采用了 jRate 的实现,而在 SableVM 中只需将该实时 Java类库中的本地函数实现好,就能够将实时Java类库和虚拟机连接起来。如图5-1 所示。
5.2 实验结果与分析
对内存分配的实时性测试采用了2种方式,一种是采用每次固定分配固定大小的内存,如500KB,测试其分配时间,观察其每次分配时间的确定性;另一种是采用每次分配内存的大小不断递增,观察分配内存的大小和分配时间的关系。
这里的实时内存管理是软实时,要求内存分配的时间具有确定性,同时允许其在合理的范围内的波动。
为了使实验达到较高的精度,测量时间的方法是采用realtime类库中的HighResolutionClock 等类。这些类的本地方法实现中获取时间的方法是采用奔腾处理器所支持的RDTSC指令【38】,该指令直接访问时钟计数器,代码如下:
unsigned long long int rdtsc_;
__asm__ __volatile__ ("rdtsc" : "=A" (rdtsc_) // Output
);
// Convert clock number into nano seconds
long double timeNS = rdtsc_ * CLOCK_PERIOD_NS;该方法可以精确到纳秒,完全满足本实验的要求。
5.2.1 固定分配内存实验
固定分配内存的代码如下:
继承实时线程类:
public class MyRTThread extends RealtimeThread {
public void run() {
…
TestLogic logic = new TestLogic();
for (i=1; i<=10; ++i) { // 分配 10 次 , 取 10 次数据
m_memArea.enter(logic); // 切换当前的分配上下文设为 m_memArea
}
…
}
}创建一个运行逻辑logic。运行逻辑就是一个继承于Runnable的类,他必须带有run()方法,可以说内存区域都是在运行逻辑中使用的:
class TestLogic implements Runnable {
public void run() {
…
start = clock.getClockTickCount(); // 获取开始的精确时间
data = new byte[size]; // 分配 size 大小的内存,
end = clock.getClockTickCount();// 获取结束的精确时间
usedTime = end - start;
sout.println(size + "\t" + usedTime);
…
}
}代码中,首先继承了实时线程RealtimeThread类,在run()方法中分10次,每次使用指定的内存区域分配大小为size的对象,使用高精度时钟计算分配对象的时间,然后打印出来。
实验中,指定size为500kB,内存区域大小为10MB,内存区域对象分别设为HeapMemory, LTMemory, CTMemory。实验结果,如图5-2到5-4所示。
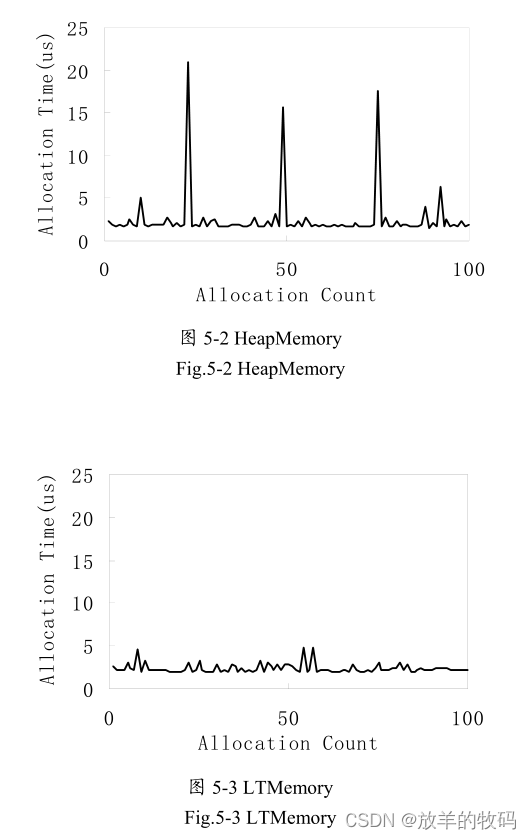
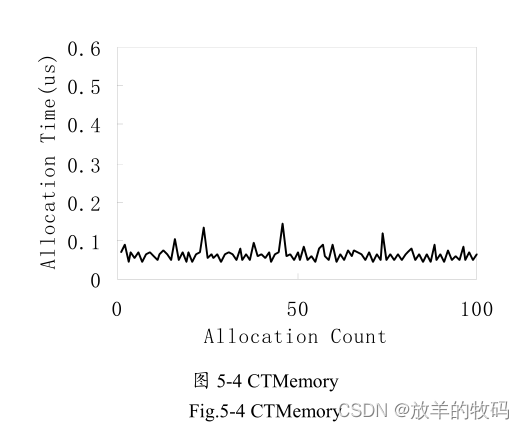
图5-2、5-3、5-4 是采取每次分配固定大小内存(500KB)的情况。由实验结果可以看出,在每次分配内存大小相同的情况下,堆内存的分配时间受到垃圾收集器的影响很大,垃圾收集的时间是内存分配时间的10倍以上,而对于LTMemory和CTMemory它的分配时间波动比较小。

图5-5把这三种内存区域进行比较。相比之下,由于CTMemroy没有了对象初始化操作,其分配时间是LTMemory的1/20左右,正常情况下LTMemroy分配内存的时间与HeapMemory近似,因为它们采用的是类似的分配的算法。
5.2.2 递增分配内存实验
递增分配内存的实验代码如下所示。
继承实时线程类:
public class MyRTThread extends RealtimeThread {
public void run() {
…
TestLogic logic = new TestLogic();
sout = new PrintWriter(new BufferedOutputStream(System.out));
int n=0, i=0;
logic.size = 16;
for (i=1; i<=10; ++i) {
System.gc();
logic.size = logic.size * 2;
m_memArea.enter(logic);
}
sout.flush();
…
}
}创建一个运行逻辑logic,对内存进行递增分配实验。
class TestLogic implements Runnable {
public void run() {
…
start = clock.getClockTickCount();
data = new byte[1];
start = clock.getClockTickCount();
start = clock.getClockTickCount();
for (i =1; i<=100; ++i) {
data = new byte[size];
}
end = clock.getClockTickCount();
usedTime = end - start;
sout.println(size + "\t" + usedTime);
…
}
}代码中,首先继承了实时线程RealtimeThread类,在run()方法中分10次,每次使用指定的内存区域递增分配倍数为2的对象,使用高精度时钟计算分配对象的时间,然后打印出来。
实验中,指定分配大小从32B到16384B,内存区域大小为10MB,内存区域对象分别设为HeapMemory, LTMemory, CTMemory。实验结果如图5-6到5-9所示。
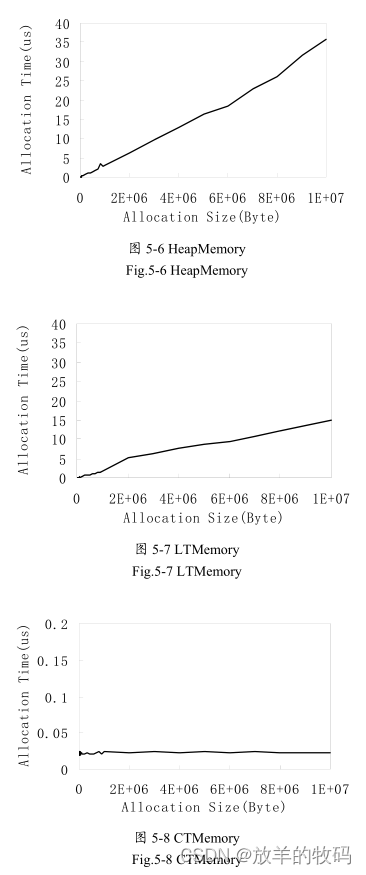
图5-6、5-7、5-8是采取递增式分配内存的情况。从递增式分配内存的测试结果可以看出,CTMemory的分配时间不随分配内存的大小而变化。HeapMemory和LTMemory的分配时间与分配内存的大小基本上成正比,在分配的内存比较小的时候分配时间随内存大小的变化不明显,这是因为对象的初始化时间占用的比例较小。
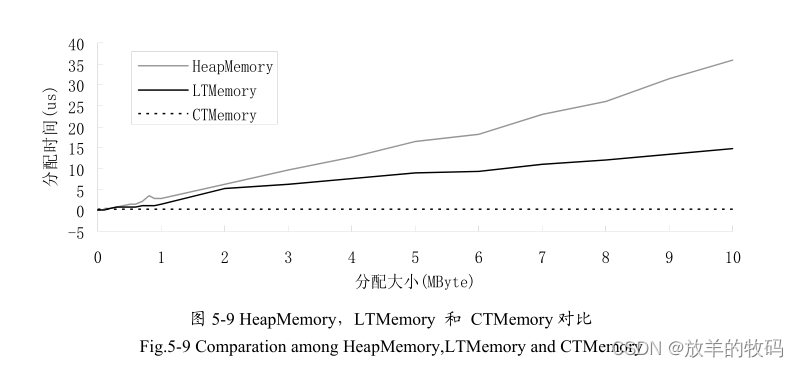
图5-9 把这三种内存区域进行比较。表5-1 列出了一组对比数据。
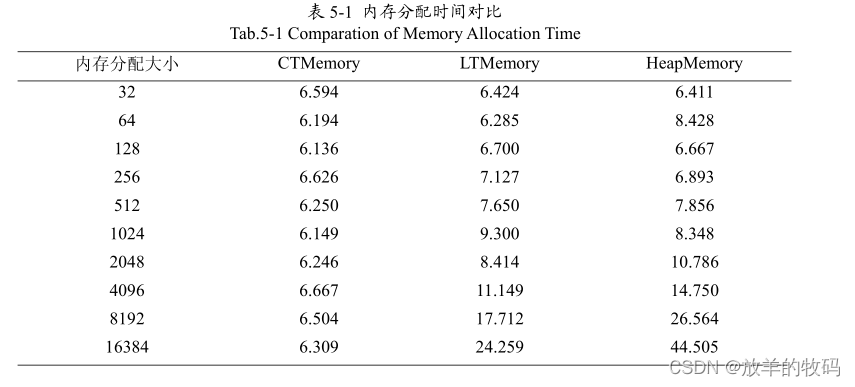
从这些数据可以看出在内存分配大小较小时各内存区域的分配时间是基本相同的,而且变化不大。当内存分配大小较大时可以明显的看出分配时间的差别,尤其是HeapMemory 的性能下降很快。同时可以看到当分配的内存很大的时候 LTMemory 的分配时间比HeapMemory小得多。
5.2.3 总结
从实验结果可知,新增的 CTMemory 和 LTMemory 已经基本满足了 RTSJ 的要求,在这些内存区域中分配内存不会引起垃圾收集,从而保证了内存分配时间的确定性。同时CTMemory和LTMemory比HeapMemory拥有更高的性能。可以看到,本文设计的内存区域模型的已经可以满足一般实际应用中的实时性的要求。