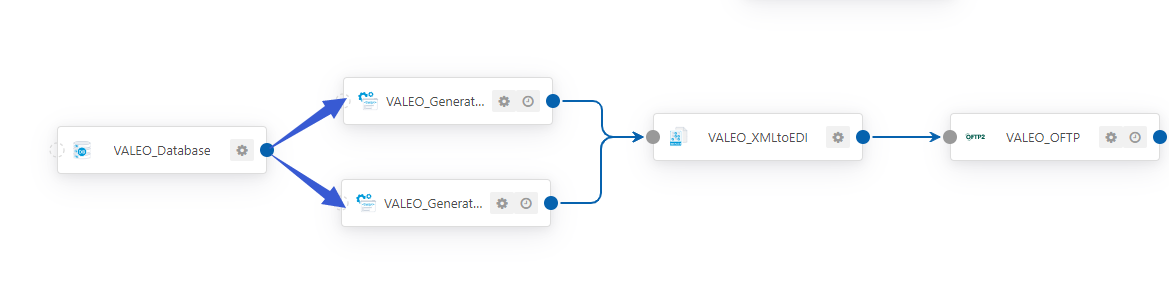
文章目录
- 进程层面
- 隔离与限制
- 容器镜像
容器本身没有价值,有价值的是“容器编排”。
- 也正因为如此,容器技术生态才爆发了一场关于“容器编排”的“战争”。而这次战争,最终以 Kubernetes 项目和 CNCF 社区的胜利而告终。
容器,到底是怎么一回事儿?
- 容器其实是一种沙盒技术。顾名思义,沙盒就是能够像一个集装箱一样,把你的应用“装”起来的技术。这样,应用与应用之间,就因为有了边界而不至于相互干扰;而被装进集装箱的应用,也可以被方便地搬来搬去,这不就是 PaaS 最理想的状态嘛。
进程层面
-
对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。
-
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
-
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而Namespace 技术则是用来修改进程视图的主要方法。
Cgroups 和 Namespace 这两个概念很抽象,动手实践一下,就很容易理解这两项技术了。
- 首先创建一个容器来试试:
docker run -it busybox /bin/sh-it参数告诉了 Docker 项目在启动容器后,需要给我们分配一个文本输入 / 输出环境,也就是 TTY,跟容器的标准输入相关联,这样我们就可以和这个 Docker 容器进行交互了。而 /bin/sh 就是我们要在 Docker 容器里运行的程序。- 所以,上面这条指令翻译成人类的语言就是:请帮我启动一个容器,在容器里执行 /bin/sh,并且给我分配一个命令行终端跟这个容器交互。
- 执行一下 ps 指令,就会发现一些更有趣的事情:
ps
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
7 root 0:00 ps
/ #
- 可以看到,我们在 Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的 /bin/sh,以及我们刚刚执行的 ps,已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
这究竟是怎么做到呢?
- 本来,每当我们在宿主机上运行了一个 /bin/sh 程序,操作系统都会给它分配一个进程编号,比如 PID=100。这个编号是进程的唯一标识,就像员工的工牌一样。所以 PID=100,可以粗略地理解为这个 /bin/sh 是我们公司里的第 100 号员工,而第 1 号员工就自然是统领全局的人物。
- 而现在,我们要通过 Docker 把这个 /bin/sh 程序运行在一个容器当中。这时候,Docker 就会在这个第 100 号员工入职时给他施一个“障眼法”,让他永远看不到前面的其他 99 个员工。这样,他就会错误地以为自己就是公司里的第 1 号员工。
- 这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进程只能看到重新计算过的进程编号,比如 PID=1。可实际上,他们在宿主机的操作系统里,还是原来的第 100 号进程。
- 这种技术,就是 Linux 里面的 Namespace 机制。而 Namespace 的使用方式也非常有意思:它其实只是 Linux 创建新进程的一个可选参数。
除了用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
-
所以说,容器,其实是一种特殊的进程而已。
-
很多人会把 Docker 项目称为“轻量级”虚拟化技术的原因,实际上就是把虚拟机的概念套在了容器上。可是这样的说法,却并不严谨。
-
在理解了 Namespace 的工作方式之后,你就会明白,跟真实存在的虚拟机不同,在使用 Docker 的时候,并没有一个真正的“Docker 容器”运行在宿主机里面。Docker 项目帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,Docker 为它们加上了各种各样的 Namespace 参数。
-
这时,这些进程就会觉得自己是各自 PID Namespace 里的第 1 号进程,只能看到各自 Mount Namespace 里挂载的目录和文件,只能访问到各自 Network Namespace 里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝。
隔离与限制
基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
- 首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
- 可以在容器里通过 Mount Namespace 单独挂载其他不同版本的操作系统文件,比如 CentOS 或者 Ubuntu,但这并不能改变共享宿主机内核的事实。
- 其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
- 如果你的容器中的程序使用 settimeofday(2) 系统调用修改了时间,整个宿主机的时间都会被随之修改,这显然不符合用户的预期。相比于在虚拟机里面可以随便折腾的自由度,在容器里部署应用的时候,“什么能做,什么不能做”,就是用户必须考虑的一个问题。
介绍完容器的“隔离”技术之后,再来研究一下容器的“限制”问题
-
我们不是已经通过 Linux Namespace 创建了一个“容器”吗,为什么还需要对容器做“限制”呢?
- 以 PID Namespace 为例,来解释这个问题。虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
-
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。 Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
-
inux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
容器镜像
一个“容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境。

- 从这个结构中不难看出,一个正在运行的 Linux 容器,其实可以被“一分为二”地看待:
- 一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分我们称为 “容器镜像”(Container Image),是容器的静态视图;
- 一个由 Namespace+Cgroups 构成的隔离环境,这一部分我们称为 “容器运行时”(Container Runtime),是容器的动态视图。
这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
- 对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
- 这样,一个完整的容器就诞生了。不过,Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。
需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
-
rootfs 只包括了操作系统的“躯壳”,并没有包括操作系统的“灵魂”。对于容器来说,同一台机器上的所有容器,都共享宿主机操作系统的内核。这就意味着,如果你的应用程序需要配置内核参数、加载额外的内核模块,以及跟内核进行直接的交互,你就需要注意了:这些操作和依赖的对象,都是宿主机操作系统的内核,它对于该机器上的所有容器来说是一个“全局变量”,牵一发而动全身。
-
这也是容器相比于虚拟机的主要缺陷之一:毕竟后者不仅有模拟出来的硬件机器充当沙盒,而且每个沙盒里还运行着一个完整的 Guest OS 给应用随便折腾。
-
不过,正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。
-
由于云端与本地服务器环境不同,应用的打包过程,一直是使用 PaaS 时最“痛苦”的一个步骤。但有了容器之后,更准确地说,有了容器镜像(即 rootfs)之后,这个问题被非常优雅地解决了。
-
rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
- 强调 Linux 容器,是因为比如 Docker on Mac,以及 Windows Docker(Hyper-V 实现),实际上是基于虚拟化技术实现的,与Linux 容器完全不同。
一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
- 如果指定 -net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。这就为容器直接操作和使用宿主机网络提供了一个渠道。
- docker commit,实际上就是在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成了一个新的镜像。当然,下面这些只读层在宿主机上是共享的,不会占用额外的空间。而由于使用了联合文件系统,你在容器里对镜像 rootfs 所做的任何修改,都会被操作系统先复制到这个可读写层,然后再修改。这就是所谓的:Copy-on-Write。
容器技术使用了 rootfs 机制和 Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统环境。这时候,我们就需要考虑这样两个问题:
-
容器里进程新建的文件,怎么才能让宿主机获取到?
-
宿主机上的文件和目录,怎么才能让容器里的进程访问到?
-
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
Docker 又是如何做到把一个宿主机上的目录或者文件,挂载到容器里面去呢?难道又是 Mount Namespace 的黑科技吗?
- 当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
- 所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
- 更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
这里提到的 " 容器进程 ",是 Docker 创建的一个容器初始化进程 (dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
- 这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
你知道的越多,你不知道的越多。


![[C++][C#]yolox TensorRT C++ C#部署](https://i0.hdslb.com/bfs/archive/9f09dc4a43e94c3e6648de2464b81c5cbc8287e4.jpg@100w_100h_1c.png@57w_57h_1c.png)