pandas:完整的初学者指南
一、说明
在你的Python开发人员或数据科学之旅中,你可能已经多次遇到“熊猫”这个词,但仍然需要弄清楚它的作用。以及数据和熊猫之间的关系。所以让我向你解释一下。
根据最新估计,每天创建 328.77 亿 TB 的数据。 现在是我们利用如此大量的数据来产生见解并预测当前和未来结果的时候了,因此pandas不能不修。
Pandas是一个基于NumPy和Matplotlib构建的Python库,主要用于处理DATA。它用于分析,清理,探索和操作数据。
它由Wes McKinney于2008年开发,用于数据分析目的。

摄影:Justin Morgan on Unsplash
二、为什么我们需要pandas?
一般来说,我们通过智能手机、物联网设备、调查和其他各种来源接收的数据充满了相关和不相关的信息,其中包含重复、缺失和无法操作的值,因此完全难以得出结论。因此,熊猫使我们能够从数据中产生有意义和有价值的见解。
从以表格格式排列数据,执行统计分析到生成图表,熊猫一切皆有可能,使数据分析师和科学家可以轻松地在一个库下执行所有任务。
简单来说,熊猫就像一个过滤器,我们可以用来净化我们的原始数据,以产生有价值的见解。
三、如何使用熊猫?
在窥视熊猫的工具之前,我们必须了解数据在熊猫中是如何存储和排列的。熊猫包含两种类型的数据结构:
- 系列 series
- 数据帧 dataframe
系列:它是一个一维数组,能够保存任何数据类型的数据。
names = ['Alex', 'Bob', 'John']
df = pd.Series(names, index=[1, 2, 3])
print(df) 
数据帧: 数据帧是由行和列(如表)组成的二维数据结构。它是熊猫中最受欢迎的数据结构。
df = pd.read_csv("E:\emp_report.csv")
print(df) 我导入了一个CSV(逗号分隔值),一个使用逗号分隔值的分隔文本文件。在 pandas 中,我们可以使用 read_csv() 命令导入 CSV 文件,然后传递文件位置。

- head()
默认情况下,head 方法返回数据框的前五行。
print(df.head()) 
我们可以看到主数据框中有六行,但使用 head 命令,它打印了数据框的前五行。
甚至可以使用 head(n) 指定所需的行数;如果我们传递 head(12),它将打印数据框的前 12 行。
2. tail()
tail 方法类似于 head,但默认情况下,它不是打印顶部行,而是返回数据框的最后五行。
print(df.tail()) 
我们甚至可以使用 tail(n) 指定我们想要的底部行数;如果我们传递 tail(10),它将打印数据框的最后十行。
3.info()
info() 方法给出了数据框的完整描述,例如列数、每列的数据类型、数据框的内存使用情况等。
print(df.info())
4. describe()
describe() 方法给出了数据帧的完整统计分析,例如每列的最大值、最小值、百分位数、总非空值和标准偏差。
print(df.describe()) 
5. shape
Pandas 中的 shape 属性为我们提供了有关数据框形状的信息,即数据框中的行数和列数。
print(df.shape) 
这里的六是指行数,五是指列数。
6. valuse
返回二维数组中数据框的所有值。
print(df.values)
7. column
列属性返回数据框中每列的标注或名称。
print(df.columns) 
8. index
index 属性返回数据框的索引信息。
print(df.index)
9. count()
count() 方法返回每行或每列的非空值或非 NA 的总数。
print(df.count()) 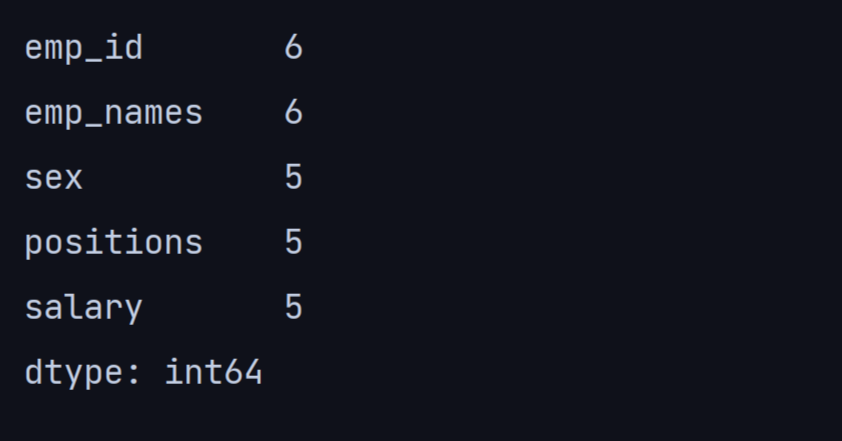
10. value_counts()
value_counts() 方法返回唯一值的计数。
print(df.value_counts('positions')) 
11. sort_values()
排序是指按升序或降序排列数据。在 Pandas 中,我们可以使用 sort_values() 方法对列进行排序,方法是传递列名,然后将升序参数设置为 True 或 False。
print(df.sort_values('salary', ascending=True)) 
在这里,我传递了工资列并将升序参数设置为 True 作为升序;设置为 False 的升序参数将按降序排列工资列。
print(df.sort_values('salary', ascending=False)) 
还有一些参数,例如na_position和就地。na_position允许我们通过传递“第一个”或“最后一个”来选择如何排列 NaN。而当就地设置为 True 时,请就地执行操作。
12. group()
分组允许我们根据类别对数据进行分组,然后对这些类别执行函数。
print(df.groupby('sex')['salary'].sum()) 
在这里,我们根据性别一栏将所有员工分为两类,“M”代表男性,“F”代表女性,然后根据性别计算总工资。
13. isna()
使用 isna() 方法,我们可以检查数据框中的缺失值或 NaN(not-a-number),为 NaN 值返回 True,否则返回 False。
print(df.isna()) 
14. fillna()
fillna() 方法将数据框中的缺失值或 NaN(非数字)替换为指定值。
print(df.fillna({'sex':'F', 'positions': 'Developer', 'salary': 90000}))
15. dropna()
我们甚至可以使用 dropna() 方法删除数据框中缺少值或 NaN(非数字)的行。
print(df.dropna())
16. 重复()
duplicated() 方法允许我们检查数据框中的重复值。对于重复值返回 True;否则是假的。
print(df.duplicated(subset='emp_names'))
17. drop_duplicates()
drop_duplicates() 方法允许我们删除具有重复值的行。
print(df.drop_duplicates(subset='emp_names'))
18.plot()
我们可以使用 Pandas 库和 matplotlib 库的绘图方法绘制图形。下面是绘制简单条形图的示例。
import matplotlib.pyplot as plt
g = df.groupby('sex')['salary'].sum()
g.plot.bar(g)
plt.show()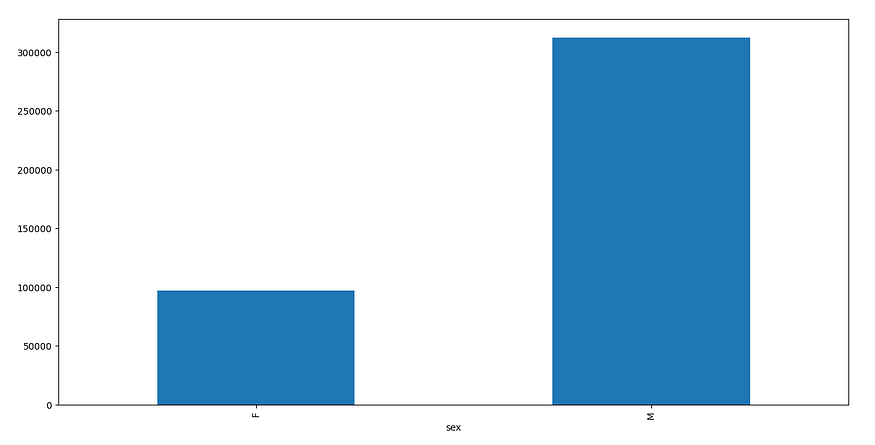
四、结论
上面的例子表明,Pandas 命令快速而灵活,允许我们分析数据、处理缺失的数据,甚至帮助我们删除重复值和可视化数据。