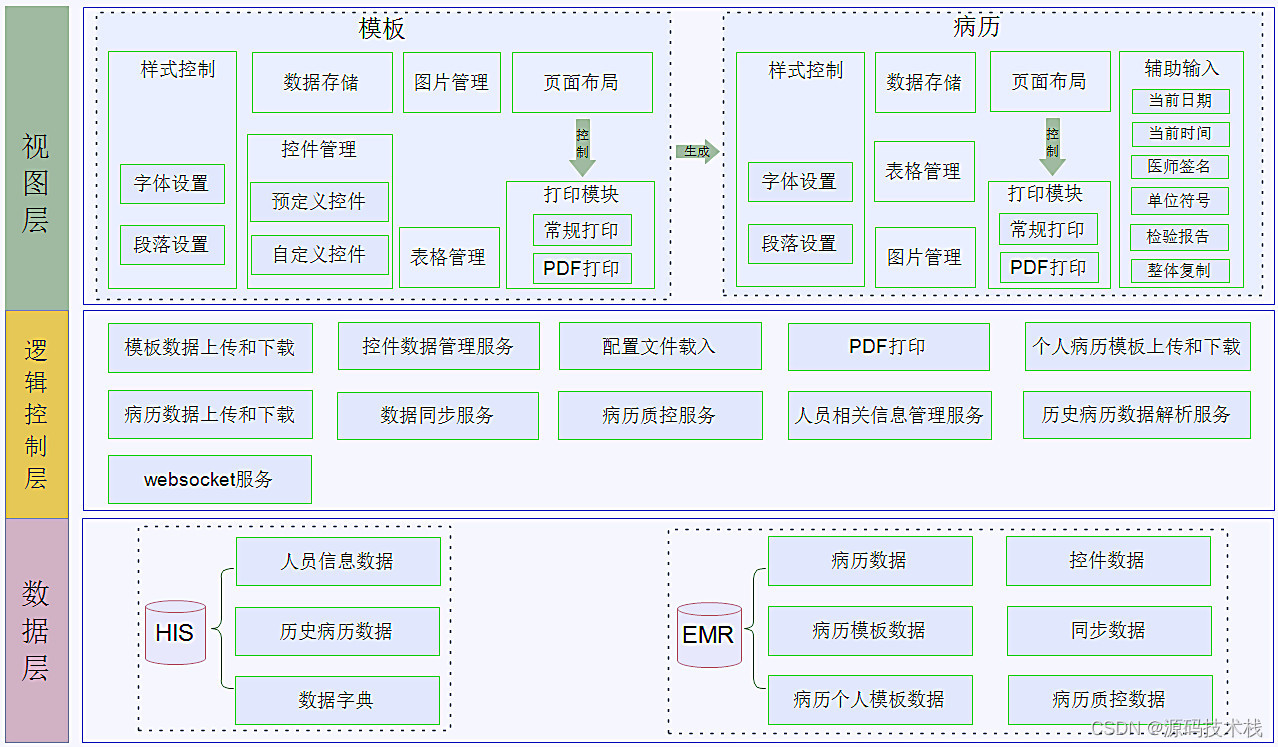
深入Golang之Mutex

基本使用方法
可以限制临界区只能同时由一个线程持有。
- 直接在流程结构中使用
lock、unlock - 嵌入到结构中,然后通过结构体的
mutex属性 调用lock、unlock - 嵌入到结构体中,但是是直接在需要锁定的资源方法中使用,让外界无需关注资源锁定
在进行资源锁定的过程中,很容易出现 data race,这时候我们可以使用 race detector ,融入到 持续集成 中,以减少代码的 Bug
看实现

初版互斥锁
设立持有锁的标识 flag 和 sema 信号量来控制互斥,实际上是利用 CAS 指令完成原子计算。
- 字段
key:是一个flag,用来标识这个排外锁是否被某个goroutine所持有,如果key大于等于 1,说明这个排外锁已经被持有;key不仅仅标识了锁是否被goroutine所持有,还记录了当前持有和等待获取锁
的goroutine的数量 - 字段
sema:是个信号量变量,用来控制等待goroutine的阻塞休眠和唤醒。
Unlock 方法可以被任意的 goroutine 调用释放锁,即使是没持有这个互斥锁的 goroutine,也可以进行这个操作。这是因为,Mutex 本身并没有包含持有这把锁的 goroutine 的信息,所以,Unlock 也不会对此进行检查。Mutex 的这个设计一直保持至今。
由于上面这个原因,就有可能出现 if 判断中释放其他 goroutine,释放锁的 goroutine 不必是锁的持有者
func lockTest()
{
lock()
var count
if count {
unlock()
}
// 此处就可能出现 goroutine 释放其他的锁
unlock()
}
四种常见使用错误
Lock/Unlock 不是成对出现的,漏写、意外删除
Copy已使用的 Mutex
type Counter struct {
sync.Mutex
Count int
}
func main() {
var c Counter
c.Lock()
defer c.Unlock()
c.Count++
foo(c) // 复制锁
}
// 这里Counter的参数是通过复制的方式传入的
func foo(c Counter) {
c.Lock()
defer c.Unlock()
fmt.Println("in foo")
}
为什么它不能被复制?
原因在于 Mutex 是一个有状态的对象,它的 state 字段记录这个锁的状态。如果你要复制一个已经加锁的 Mutex 给一个新的变量,那么新的刚初始化的变量居然被加锁了,这显然不符合预期
重入
- 可重入锁概念解释
当一个线程获取锁时,如果没有其他线程拥有这个锁,那么这个线程就成功获取了这个锁,之后,如果其他线程再去请求这个锁,就会处于阻塞状态。如果拥有这把锁的线程再请求这把锁的话,不会阻塞,而是成功返回,所以叫可重入锁。
Mutex不是可重入锁
想想也不奇怪,因为 Mutex 的实现中没有记录哪个 goroutine 拥有这把锁。理论上,任何 goroutine 都可以随意地 Unlock 这把锁,所以没办法计算重入条件
func foo(l sync.Locker) {
fmt.Println("in foo")
l.Lock()
bar(l)
l.Unlock()
}
// 这就是可重入锁
func bar(l sync.Locker) {
l.Lock()
fmt.Println("in bar")
l.Unlock()
}
func main() {
l := &sync.Mutex{}
foo(l)
}
自己实现可重入锁
- 通过 goroutine id
// RecursiveMutex 包装一个Mutex,实现可重入
type RecursiveMutex struct {
sync.Mutex
owner int64 // 当前持有锁的goroutine id
recursion int32 // 这个goroutine 重入的次数
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get() // 如果当前持有锁的goroutine就是这次调用的goroutine,说明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock() // 获得锁的goroutine第一次调用,记录下它的goroutine id,调用次数加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get() // 非持有锁的goroutine尝试释放锁,错误的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
} // 调用次数减1
m.recursion--
if m.recursion != 0 { // 如果这个goroutine还没有完全释放,则直接返回
return
} // 此goroutine最后一次调用,需要释放锁
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
有一点,要注意,尽管拥有者可以多次调用 Lock,但是也必须调用相同次数的 Unlock,这样才能把锁释放掉。这是一个合理的设计,可以保证 Lock 和 Unlock 一一对应。
- 方案二:token
这个与 goroutine id 差不多, goroutine id 既然没有暴露出来,说明设计方不希望使用这个,而这只是可重入锁的一个标识,我们可以自定义这个标识,由协程自己提供,在调用 lock 和 unlock 中,自己传入一个生成的 token 即可,逻辑是一样的
死锁
- 互斥: 排他性资源
- 环路等待: 形成环路
- 持有和等待: 持有还去和其他资源竞争
- 不可剥夺: 资源只能由持有它的 goroutine 释放
打破以上条件其中一个或者几个即可解除死锁
扩展 Mutex
- 实现 TryLock
- 获取等待者的数量等指标
- 使用 Mutex 实现一个线程安全的队列
读写锁的实现原理及避坑指南
标准库中的 RWMutex 是一个 reader/writer 互斥锁。RWMutex 在某一时刻只能由任意数量的 reader 持有,或者是只被单个的 writer 持有。
他是基于 Mutex 的。如果你遇到可以明确区分 reader 和 writer goroutine 的场景,且有大量的并发读、少量的并发写,并且有强烈的性能需求,你就可以考虑使用读写锁 RWMutex 替换 Mutex。
读写锁的实现方式
- Read-preferring:读优先的设计可以提供很高的并发性,但是,在竞争激烈的情况下可能会导致写饥饿。这是因为,如果有大量的读,这种设计会导致只有所有的读都释放了锁之后,写才可能获取到锁。
- Write-preferring:写优先的设计意味着,如果已经有一个 writer 在等待请求锁的话,它会阻止新来的请求锁的 reader 获取到锁,所以优先保障 writer。当然,如果有一些 reader 已经请求了锁的话,新请求的 writer 也会等待已经存在的 reader 都释放锁之后才能获取。所以,写优先级设计中的优先权是针对新来的请求而言的。这种设计主要避免了 writer 的饥饿问题。
- 不指定优先级:这种设计比较简单,不区分 reader 和 writer 优先级,某些场景下这种不指定优先级的设计反而更有效,因为第一类优先级会导致写饥饿,第二类优先级可能会导致读饥饿,这种不指定优先级的访问不再区分读写,大家都是同一个优先级,解决了饥饿的问题。
Go 标准库中的 RWMutex 设计是 Write-preferring 方案。一个正在阻塞的 Lock 调用会排除新的 reader 请求到锁。
RWMutex 的 3 个踩坑点
- 不可复制
- 重入导致死锁
- 释放未加锁的 RWMutex
我们知道,有活跃 reader 的时候,writer 会等待,如果我们在 reader 的读操作时调用 writer 的写操作(它会调用 Lock 方法),那么,这个 reader 和 writer 就会形成互相依赖的死锁状态。Reader 想等待 writer 完成后再释放锁,而 writer 需要这个 reader 释放锁之后,才能不阻塞地继续执行。这是一个读写锁常见的死锁场景。
第三种死锁的场景更加隐蔽。
当一个 writer 请求锁的时候,如果已经有一些活跃的 reader,它会等待这些活跃的 reader 完成,才有可能获取到锁,但是,如果之后活跃的 reader 再依赖新的 reader 的话,这些新的 reader 就会等待 writer 释放锁之后才能继续执行,这就形成了一个环形依赖: writer 依赖活跃的 reader -> 活跃的 reader 依赖新来的 reader -> 新来的 reader 依赖 writer。