一、数据集准备
数据集可以使用官网数据集,也可以用ssb-dbgen来准备
1.准备数据
这里最后生成表的数据行数为60亿行,数据量为300G左右
git clone https://github.com/vadimtk/ssb-dbgen.git
cd ssb-dbgen/
make
1.1 生成数据
# -s 指生成多少G的数据
$ ./dbgen -s 40 -T c
$ ./dbgen -s 40 -T l
$ ./dbgen -s 40 -T p
$ ./dbgen -s 40 -T s
1.2 创建表
CREATE TABLE customer
(
C_CUSTKEY UInt32,
C_NAME String,
C_ADDRESS String,
C_CITY LowCardinality(String),
C_NATION LowCardinality(String),
C_REGION LowCardinality(String),
C_PHONE String,
C_MKTSEGMENT LowCardinality(String)
)
ENGINE = MergeTree ORDER BY (C_CUSTKEY);
CREATE TABLE lineorder
(
LO_ORDERKEY UInt32,
LO_LINENUMBER UInt8,
LO_CUSTKEY UInt32,
LO_PARTKEY UInt32,
LO_SUPPKEY UInt32,
LO_ORDERDATE Date,
LO_ORDERPRIORITY LowCardinality(String),
LO_SHIPPRIORITY UInt8,
LO_QUANTITY UInt8,
LO_EXTENDEDPRICE UInt32,
LO_ORDTOTALPRICE UInt32,
LO_DISCOUNT UInt8,
LO_REVENUE UInt32,
LO_SUPPLYCOST UInt32,
LO_TAX UInt8,
LO_COMMITDATE Date,
LO_SHIPMODE LowCardinality(String)
)
ENGINE = MergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY);
CREATE TABLE part
(
P_PARTKEY UInt32,
P_NAME String,
P_MFGR LowCardinality(String),
P_CATEGORY LowCardinality(String),
P_BRAND LowCardinality(String),
P_COLOR LowCardinality(String),
P_TYPE LowCardinality(String),
P_SIZE UInt8,
P_CONTAINER LowCardinality(String)
)
ENGINE = MergeTree ORDER BY P_PARTKEY;
CREATE TABLE supplier
(
S_SUPPKEY UInt32,
S_NAME String,
S_ADDRESS String,
S_CITY LowCardinality(String),
S_NATION LowCardinality(String),
S_REGION LowCardinality(String),
S_PHONE String
)
ENGINE = MergeTree ORDER BY S_SUPPKEY;
1.3 导入数据
$ clickhouse-client --query "INSERT INTO db_bench.customer FORMAT CSV" < customer.tbl
$ clickhouse-client --query "INSERT INTO db_bench.part FORMAT CSV" < part.tbl
$ clickhouse-client --query "INSERT INTO db_bench.supplier FORMAT CSV" < supplier.tbl
$ clickhouse-client --query "INSERT INTO db_bench.lineorder FORMAT CSV" < lineorder.tbl
1.4 join表
这个操作耗时两个小时,占用内存为29G
# 因为这个操作比较耗费内存,所以要事先设置好内存限制
SET max_memory_usage = 30000000000;
CREATE TABLE lineorder_flat
ENGINE = MergeTree ORDER BY (LO_ORDERDATE, LO_ORDERKEY)
AS SELECT
l.LO_ORDERKEY AS LO_ORDERKEY,
l.LO_LINENUMBER AS LO_LINENUMBER,
l.LO_CUSTKEY AS LO_CUSTKEY,
l.LO_PARTKEY AS LO_PARTKEY,
l.LO_SUPPKEY AS LO_SUPPKEY,
l.LO_ORDERDATE AS LO_ORDERDATE,
l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY,
l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY,
l.LO_QUANTITY AS LO_QUANTITY,
l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE,
l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE,
l.LO_DISCOUNT AS LO_DISCOUNT,
l.LO_REVENUE AS LO_REVENUE,
l.LO_SUPPLYCOST AS LO_SUPPLYCOST,
l.LO_TAX AS LO_TAX,
l.LO_COMMITDATE AS LO_COMMITDATE,
l.LO_SHIPMODE AS LO_SHIPMODE,
c.C_NAME AS C_NAME,
c.C_ADDRESS AS C_ADDRESS,
c.C_CITY AS C_CITY,
c.C_NATION AS C_NATION,
c.C_REGION AS C_REGION,
c.C_PHONE AS C_PHONE,
c.C_MKTSEGMENT AS C_MKTSEGMENT,
s.S_NAME AS S_NAME,
s.S_ADDRESS AS S_ADDRESS,
s.S_CITY AS S_CITY,
s.S_NATION AS S_NATION,
s.S_REGION AS S_REGION,
s.S_PHONE AS S_PHONE,
p.P_NAME AS P_NAME,
p.P_MFGR AS P_MFGR,
p.P_CATEGORY AS P_CATEGORY,
p.P_BRAND AS P_BRAND,
p.P_COLOR AS P_COLOR,
p.P_TYPE AS P_TYPE,
p.P_SIZE AS P_SIZE,
p.P_CONTAINER AS P_CONTAINER
FROM lineorder AS l
INNER JOIN customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN part AS p ON p.P_PARTKEY = l.LO_PARTKEY;
二、基准测试
1.benchmark的使用
1.1 基本用法
# 以下几种写法都可以
$ clickhouse-benchmark --query ["single query"] [keys]
$ echo "single query" | clickhouse-benchmark [keys]
$ clickhouse-benchmark [keys] <<< "single query"
clickhouse-benchmark [keys] < queries_file;
# 比较两个clickhouse性能
$ echo "SELECT * FROM system.numbers LIMIT 10000000 OFFSET 10000000" | clickhouse-benchmark --host=localhost --port=9001 --host=localhost --port=9000 -i 10
1.2 参数详解
--query=QUERY — 要执行的查询。 如果未传递此参数,clickhouse-benchmark 将从标准输入读取查询。
-c N, --concurrency=N — clickhouse-benchmark 同时发送的查询数。 默认值:1。
-d N, --delay=N — 中间报告之间的间隔(以秒为单位)(以禁用报告集 0)。 默认值:1。
-h HOST, --host=HOST — 服务器主机。 默认值:本地主机。 对于比较模式,您可以使用多个 -h 键。
-p N, --port=N — 服务器端口。 默认值:9000。对于比较模式,您可以使用多个 -p 键。
-i N, --iterations=N — 查询总数。 默认值:0(永远重复)。
-r, --randomize — 如果有多个输入查询,则查询执行的随机顺序。
-s, --secure — 使用 TLS 连接。
-t N, --timelimit=N — 时间限制(以秒为单位)。 当达到指定的时间限制时,clickhouse-benchmark 将停止发送查询。 默认值:0(时间限制禁用)。
--confidence=N — T 检验的置信度。 可能的值:0 (80%)、1 (90%)、2 (95%)、3 (98%)、4 (99%)、5 (99.5%)。 默认值:5。在比较模式下,clickhouse-benchmark 执行独立双样本学生 t 检验,以确定两个分布在所选置信水平下是否没有差异。
--cumulative — 打印累积数据而不是每个间隔的数据。
--database=DATABASE_NAME — ClickHouse 数据库名称。 默认值:默认。
--json=FILEPATH — JSON 输出。 设置密钥后,clickhouse-benchmark 会将报告输出到指定的 JSON 文件。
--user=USERNAME — ClickHouse 用户名。 默认值:默认。
--password=PSWD — ClickHouse 用户密码。 默认值:空字符串。
--stacktrace — 堆栈跟踪输出。 设置密钥后,clickhouse-bencmark 会输出异常的堆栈跟踪。
--stage=WORD — 服务器上的查询处理阶段。 ClickHouse 在指定阶段停止查询处理并向 clickhouse-benchmark 返回答案。 可能的值:complete、fetch_columns、with_mergeable_state。 默认值:完整。
--help — 显示帮助消息。
如果要对查询应用某些设置,请将它们作为键传递 --<session setting name>= SETTING_VALUE。 例如,--max_memory_usage=1048576。
1.3 结果分析
# 执行的查询数:字段中的查询数。
Queries executed: 72 (1800.000%).
# ClickHouse 服务器的端点。
# queries:已处理查询的数量。
# QPS:在 --delay 参数指定的时间段内服务器每秒执行的查询数量。
# RPS:在 --delay 参数指定的时间段内服务器每秒读取的行数。
# MiB/s:在 --delay 参数中指定的时间段内,服务器每秒读取多少兆字节。
# result RPS:在 --delay 参数中指定的时间段内,服务器每秒将多少行放入查询结果中。
# result MiB/s。 在 --delay 参数指定的时间段内,服务器每秒向查询结果放置多少兆字节。
localhost:9000, queries 2, QPS: 0.156, RPS: 432704682.870, MiB/s: 1370.478, result RPS: 2.185, result MiB/s: 0.000.
# 查询执行时间的百分位数。
0.000% 0.217 sec.
10.000% 0.217 sec.
20.000% 0.217 sec.
30.000% 0.217 sec.
40.000% 0.217 sec.
50.000% 12.594 sec.
60.000% 12.594 sec.
70.000% 12.594 sec.
80.000% 12.594 sec.
90.000% 12.594 sec.
95.000% 12.594 sec.
99.000% 12.594 sec.
99.900% 12.594 sec.
99.990% 12.594 sec.
状态字符串包含(按顺序):
ClickHouse 服务器的端点。
已处理查询的数量。
QPS:在 --delay 参数指定的时间段内服务器每秒执行的查询数量。
RPS:在 --delay 参数指定的时间段内服务器每秒读取的行数。
MiB/s:在 --delay 参数中指定的时间段内,服务器每秒读取多少兆字节。
结果 RPS:在 --delay 参数中指定的时间段内,服务器每秒将多少行放入查询结果中。
结果 MiB/s。 在 --delay 参数指定的时间段内,服务器每秒向查询结果放置多少兆字节。
查询执行时间的百分位数。
2.基本测试
基准测试的内容可以看官网,具体的sql在这里查看。我是共写了4个sql文件,内容如下
# test1.sql
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue FROM db_bench.lineorder_flat WHERE toYear(LO_ORDERDATE) = 1993 AND LO_DISCOUNT BETWEEN 1 AND 3 AND LO_QUANTITY < 25;
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue FROM db_bench.lineorder_flat WHERE toYYYYMM(LO_ORDERDATE) = 199401 AND LO_DISCOUNT BETWEEN 4 AND 6 AND LO_QUANTITY BETWEEN 26 AND 35;
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue FROM db_bench.lineorder_flat WHERE toISOWeek(LO_ORDERDATE) = 6 AND toYear(LO_ORDERDATE) = 1994 AND LO_DISCOUNT BETWEEN 5 AND 7 AND LO_QUANTITY BETWEEN 26 AND 35;
# test2.sql
SELECT sum(LO_REVENUE),toYear(LO_ORDERDATE) AS year,P_BRAND FROM db_bench.lineorder_flat WHERE P_CATEGORY = 'MFGR#12' AND S_REGION = 'AMERICA' GROUP BY year,P_BRAND ORDER BY year,P_BRAND;
SELECT sum(LO_REVENUE),toYear(LO_ORDERDATE) AS year,P_BRAND FROM db_bench.lineorder_flat WHERE P_BRAND >= 'MFGR#2221' AND P_BRAND <= 'MFGR#2228' AND S_REGION = 'ASIA' GROUP BY year,P_BRAND ORDER BY year,P_BRAND;
SELECT sum(LO_REVENUE), toYear(LO_ORDERDATE) AS year, P_BRAND FROM db_bench.lineorder_flat WHERE P_BRAND = 'MFGR#2239' AND S_REGION = 'EUROPE' GROUP BY year, P_BRAND ORDER BY year, P_BRAND;
# test3.sql
SELECT C_NATION, S_NATION, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND year >= 1992 AND year <= 1997 GROUP BY C_NATION, S_NATION, year ORDER BY year ASC, revenue DESC;
SELECT C_CITY, S_CITY, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE C_NATION = 'UNITED STATES' AND S_NATION = 'UNITED STATES' AND year >= 1992 AND year <= 1997 GROUP BY C_CITY, S_CITY, year ORDER BY year ASC, revenue DESC;
SELECT C_CITY, S_CITY, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE (C_CITY = 'UNITED KI1' OR C_CITY = 'UNITED KI5') AND (S_CITY = 'UNITED KI1' OR S_CITY = 'UNITED KI5') AND year >= 1992 AND year <= 1997 GROUP BY C_CITY, S_CITY, year ORDER BY year ASC, revenue DESC;
SELECT C_CITY, S_CITY, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE (C_CITY = 'UNITED KI1' OR C_CITY = 'UNITED KI5') AND (S_CITY = 'UNITED KI1' OR S_CITY = 'UNITED KI5') AND toYYYYMM(LO_ORDERDATE) = 199712 GROUP BY C_CITY, S_CITY, year ORDER BY year ASC, revenue DESC;
# test4.sql
SELECT toYear(LO_ORDERDATE) AS year, C_NATION, sum(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM db_bench.lineorder_flat WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND (P_MFGR = 'MFGR#1' OR P_MFGR = 'MFGR#2') GROUP BY year, C_NATION ORDER BY year ASC, C_NATION ASC;
SELECT toYear(LO_ORDERDATE) AS year, S_NATION, P_CATEGORY, sum(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM db_bench.lineorder_flat WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND (year = 1997 OR year = 1998) AND (P_MFGR = 'MFGR#1' OR P_MFGR = 'MFGR#2') GROUP BY year, S_NATION, P_CATEGORY ORDER BY year ASC, S_NATION ASC, P_CATEGORY ASC;
SELECT toYear(LO_ORDERDATE) AS year, S_CITY, P_BRAND, sum(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM db_bench.lineorder_flat WHERE S_NATION = 'UNITED STATES' AND (year = 1997 OR year = 1998) AND P_CATEGORY = 'MFGR#14' GROUP BY year, S_CITY, P_BRAND ORDER BY year ASC, S_CITY ASC, P_BRAND ASC;
2.1 测试方法
clickhouse-benchmark < test1.sql
clickhouse-benchmark < test2.sql
clickhouse-benchmark < test3.sql
clickhouse-benchmark < test4.sql
2.2 测试结果
# test1
Queries executed: 921 (30700.000%).
localhost:9000, queries 2, QPS: 5.558, RPS: 263878534.377, MiB/s: 2012.050, result RPS: 5.558, result MiB/s: 0.000.
0.000% 0.091 sec.
10.000% 0.091 sec.
20.000% 0.091 sec.
30.000% 0.091 sec.
40.000% 0.091 sec.
50.000% 0.268 sec.
60.000% 0.268 sec.
70.000% 0.268 sec.
80.000% 0.268 sec.
90.000% 0.268 sec.
95.000% 0.268 sec.
99.000% 0.268 sec.
99.900% 0.268 sec.
# test2
Queries executed: 32 (1066.667%).
localhost:9000, queries 1, QPS: 0.054, RPS: 326066467.053, MiB/s: 2797.293, result RPS: 3.043, result MiB/s: 0.000.
0.000% 18.401 sec.
10.000% 18.401 sec.
20.000% 18.401 sec.
30.000% 18.401 sec.
40.000% 18.401 sec.
50.000% 18.401 sec.
60.000% 18.401 sec.
70.000% 18.401 sec.
80.000% 18.401 sec.
90.000% 18.401 sec.
95.000% 18.401 sec.
99.000% 18.401 sec.
99.900% 18.401 sec.
99.990% 18.401 sec.
# test3
localhost:9000, queries 73, QPS: 0.082, RPS: 340111314.396, MiB/s: 2527.187, result RPS: 15.938, result MiB/s: 0.000.
0.000% 0.182 sec.
10.000% 0.217 sec.
20.000% 0.230 sec.
30.000% 10.547 sec.
40.000% 12.614 sec.
50.000% 14.860 sec.
60.000% 16.560 sec.
70.000% 18.072 sec.
80.000% 18.285 sec.
90.000% 19.915 sec.
95.000% 19.962 sec.
99.000% 20.011 sec.
99.900% 20.059 sec.
99.990% 20.059 sec.
# test4
Queries executed: 3 (100.000%).
localhost:9000, queries 1, QPS: 0.474, RPS: 683988835.693, MiB/s: 9777.042, result RPS: 378.949, result MiB/s: 0.004.
0.000% 2.111 sec.
10.000% 2.111 sec.
20.000% 2.111 sec.
30.000% 2.111 sec.
40.000% 2.111 sec.
50.000% 2.111 sec.
60.000% 2.111 sec.
70.000% 2.111 sec.
80.000% 2.111 sec.
90.000% 2.111 sec.
95.000% 2.111 sec.
99.000% 2.111 sec.
99.900% 2.111 sec.
99.990% 2.111 sec.
2.3 cpu情况
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7031 999 20 0 0.257t 1.470g 99080 S 4656 0.8 3643:13 clickhouse-serv
2.4 读取数据情况
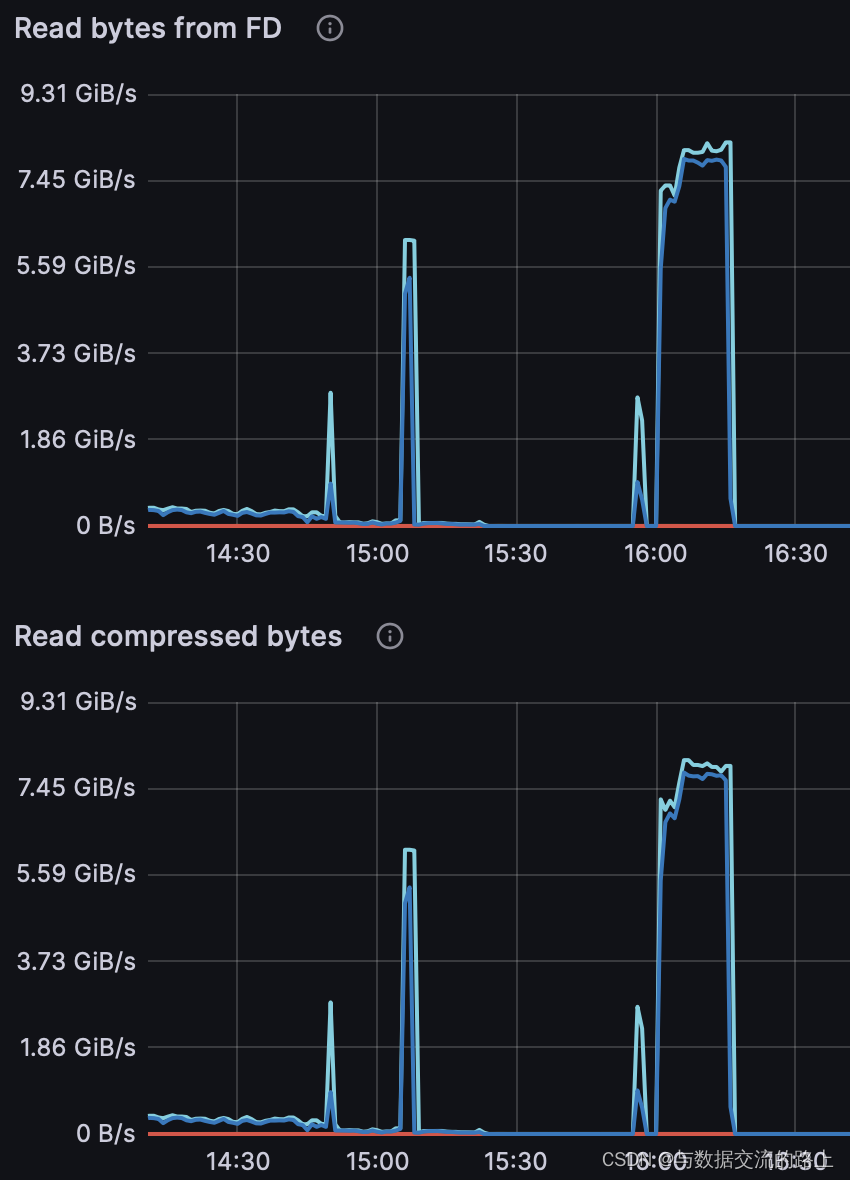
结论: 可以看到读取数据的速度还是非常快的,每秒读取的行数和数据量都很大,读取时非常耗cpu资源,但内存占用缺极少