推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景
“这是给你的”,“为你推荐的”或“你可能也喜欢”,是大多数数字业务中必不可少的短语,特别是在电子商务或流媒体平台中。
尽管它们看起来像一个简单的概念,但它们暗示了企业与客户互动和联系方式的新时代:推荐时代。
老实说,我们大多数人,如果不是所有人,在寻找要看的内容时都被 Netflix 的推荐冲昏了头脑,或者直接前往亚马逊上的推荐部分看看接下来要买什么。
在本文中,我将解释如何使用图形数据库构建实时推荐引擎。
什么是推荐引擎?
推荐引擎是一种工具包,它应用高级数据过滤和预测分析来预测客户的需求和愿望,即客户可能消费或参与的内容、产品或服务。
为了获得这些建议,引擎使用以下信息的组合:
- 客户过去的行为和历史记录,例如购买的产品或观看的系列。
- 客户的当前行为以及与其他客户的关系。
- 产品按客户排名。
- 企业最畅销的产品。
- 类似或相关客户的行为和历史记录。
什么是图形数据库?
图形数据库是一个NoSQL数据库,其中数据存储在图形结构中,而不是表或文档中。图形数据结构由可以通过关系连接的节点组成。节点和关系都可以有自己的属性(键值对),这些属性进一步描述它们。
下图介绍了图形数据结构的基本概念:
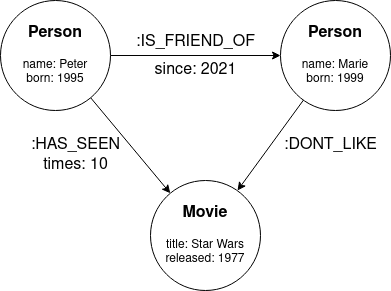
图形数据结构示例
流媒体平台的实时推荐引擎
现在我们知道了什么是推荐引擎和图形数据库,我们已经准备好介绍如何使用流式处理平台的图形数据库构建推荐引擎。
下图存储了两个客户看过的电影以及两个客户之间的关系。
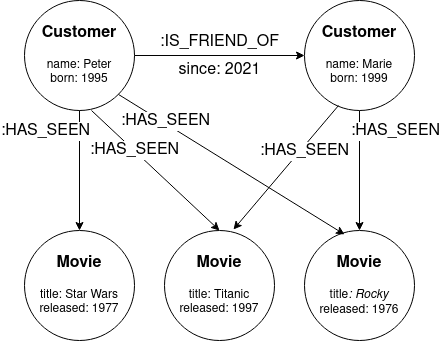
流媒体平台的图表示例。
将这些信息存储为图表,我们现在可以考虑电影推荐来影响下一部要观看的电影。最简单的策略是在整个平台上显示观看次数最多的电影。使用Cypher查询语言可以轻松:
MATCH (:Customer)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5但是,此查询非常通用,不考虑客户的上下文,因此未针对任何给定客户进行优化。我们可以更好地使用客户的社交网络,查询朋友和朋友的朋友关系。使用Cypher非常简单:
MATCH (customer:Customer {name:'Marie'})
<-[:IS_FRIEND_OF*1..2]-(friend:Customer)
WHERE customer <> friend
WITH DISTINCT friend
MATCH (friend)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5此查询有两个部分由 WITH 子句划分,这允许我们将结果从第一部分传送到第二部分。
在查询的第一部分,我们找到当前客户 (),并使用灵活的路径长度表示法(表示一个或两个深度关系)遍历 Marie 的直接朋友或他们的朋友(她的朋友的朋友)的图形匹配。{name: 'Marie'}-[:IS_FRIEND_OF*1..2]->IS_FRIEND_OF
我们注意不要将玛丽本人包括在结果中(条款),也不要得到重复的朋友的朋友也是直接的(条款)。WHERE DISTINCT
查询的后半部分与最简单的查询相同,但现在我们不考虑平台上的所有客户,而是考虑玛丽的朋友和朋友的朋友。
就是这样,我们刚刚为流媒体平台构建了实时推荐引擎。
总结
在本文中,介绍了以下主题:
- 什么是推荐引擎以及它用于提出建议的信息量。
- 什么是图形数据库以及如何将数据存储为图形而不是表或文档。
- 如何使用图形数据库为流媒体平台构建实时推荐引擎的示例。
原文链接:如何使用图形数据库构建实时推荐引擎 (mvrlink.com)