0 摘要
论文:A survey on learning from imbalanced data streams: taxonomy, challenges, empirical study, and reproducible experimental framework
发表:2023年发表在Machine Learning上。
源代码:https://github.com/canoalberto/imbalanced-streams
类不平衡给数据流分类带来了新的挑战。最近在文献中提出的许多算法使用各种数据驱动层面、算法层面和集成方法来解决这个问题。然而,在如何评估这些算法方面,缺乏标准化和商定的程序和基准。本文工作提出了一个标准化、详尽和全面的实验框架,以评估各种具有挑战性的不平衡数据流场景中的算法。实验研究在515个不平衡数据流上评估了24个最先进的数据流算法,在二分类和多分类场景下这些数据流结合了静态和动态类不平衡比率、实例级困难、概念漂移、真实世界和半合成数据集。这导致了一项大规模的实验研究,比较了数据流挖掘领域中最先进的分类器。我们讨论了这些场景中最先进的分类器的优点和缺点,并为最终用户提供了针对不平衡数据流选择最佳算法的一般建议。此外,我们还制定了该领域的开放挑战和未来方向。我们的实验框架是完全可复制的,并且很容易用新方法扩展。通过这种方式,我们提出了一种标准化的方法来在不平衡的数据流中进行实验,其他研究人员可以使用这种方法来对新提出的方法进行完整、可信和公平的评估。
1 引言
我们收集、整合、存储和分析大量数据的能力最近取得了进步,这给机器学习方法带来了新的挑战。传统的算法被设计为从静态数据集中发现知识。相反,当代数据源产生的信息具有数量和速度的特点。这样的场景被称为数据流(Gama, 2010; Bahri et al., 2021; Read and Žliobaitė, 2023),传统方法在处理这种数据流有所欠缺。
与从静态数据中学习相比,最大的挑战之一在于需要适应数据不断变化的本质,其中的概念是非平稳的,可能会随着时间而变化。这种现象被称为概念漂移(Krawczyk et al., 2017;Khamassi et al.,2018),并导致分类器的退化,因为在以前的概念上学习的知识可能对最近的实例不再有用。从概念漂移中恢复需要显式检测器或隐式适应机制的存在。
数据流挖掘的另一个重要挑战在于需要算法显示对类不平衡的鲁棒性(Krawczyk, 2016;Fernández et al.,2018a)。尽管经过近三十年的研究,处理倾斜的类分布仍然是机器学习的一个关键领域。这在流场景中变得更具挑战性,因为不平衡与概念漂移同时发生。不仅类的定义发生了变化,而且失衡比例也变得动态,类的角色也可能发生转换。假设固定数据属性的解决方案不能在这里应用,因为流可能在不同程度的不平衡和类之间的平衡期间振荡。
此外,不平衡的流可能有其他潜在的困难,如小样本量,边界和罕见的实例,类之间的重叠,或嘈杂的标签(Santos et al.,2022)。不平衡的数据流通常通过类重采样来处理(Korycki & Krawczyk, 2020;Bernardo等,2020b;Bernardo & Della Valle, 2021a),算法自适应机制(Loezer et al, 2020;Lu et al, 2020),或集成方法(Zyblewski et al, 2021;Cano & Krawczyk, 2022)。这个问题的动机是大量现实世界的问题,其中数据既存现流的特征又出现噪声的情况,例如Twitter流(Shah & Dunn, 2022)、欺诈检测(Bourdonnaye & Daniel, 2022)、滥用和仇恨言论检测(Marwa等人,2021)、物联网(Sudharsan等人,2021)或智能制造(Lee, 2018)。虽然有一些关于如何处理不平衡数据流的工作,但对于完全可复制、透明和有影响力的研究来说,没有一致认可的标准、基准或良好实践。
研究的目标。为二元和多类不平衡数据流创建一个标准化、详尽和信息丰富的实验框架,并对最先进的分类器进行广泛的比较。
动机。虽然文献中有许多针对漂移和不平衡数据流的算法,但缺乏关于如何全面评估这些算法的标准化程序和基准。现有的研究通常局限于算法和数据困难的选择,通常只考虑二分类数据,并且没有提供必须考虑不平衡数据流的哪些方面并将其转化为有意义的基准问题的见解。不平衡数据流需要一个统一和全面的评估框架,可以作为研究人员根据文献中相关方法评估他们新提出的算法的模板。此外,对最先进的方法进行深入的实验比较,可以获得有价值的见解,了解在不同条件下分类器和学习机制的工作原理。因此,我们提出了一个评估框架,并进行了大规模的实证研究,以获得深入了解的性能方法下的广泛和不同的一组数据困难。
概述和贡献。本文提出了一个完整的框架,用于对不平衡数据流的分类器进行基准测试和评估。我们总结现有的工作,并根据既定的分类法专门针对倾斜和流问题进行组织。我们提炼出该领域中出现的最关键和最具洞察力的问题,并用它们设计一组基准问题,以捕捉独特的学习困难和挑战。我们将这些基准编译成一个框架,该框架嵌入了各种度量、统计测试和可视化工具。最后,我们通过比较24种最先进的算法来展示我们的框架,这使我们能够选择表现最好的算法,发现它们在哪些特定领域表现出色,并为最终用户制定建议。本文的主要贡献总结如下:
- 不平衡数据流的算法分类。我们根据已建立的分类法组织了目前最先进的方法,这些分类法总结了从不平衡数据流中学习的最新进展,并提供了最重要贡献的综述。
- 全面和可重复的评估框架。我们提出了一个完整的整体框架,用于评估二分类和多分类不平衡数据流的分类器,该框架将度量标准、统计测试和可视化工具标准化,用于透明和可重复的研究。
- 各种基准问题。我们制定了一组在我们的框架中使用的基准问题。我们捕获了不平衡数据流中存在的最重要和最具挑战性的问题,例如动态不平衡比率、实例级困难(边界、罕见和子概念)或类的数量。此外,我们还包括了现实世界和半合成的不平衡问题,总共产生了515个数据流基准测试。
- 最先进分类器之间的比较。我们基于提出的框架和515个基准问题,对24种最先进的流挖掘算法进行了广泛、全面和可重复的比较研究。
- 建议和公开挑战。基于详尽的实验研究结果,我们为最终用户制定了建议,以便了解性能最好的分类器的优点和缺点。此外,我们制定了从不平衡数据流中学习的公开挑战,这些挑战应该由研究人员在未来几年解决。
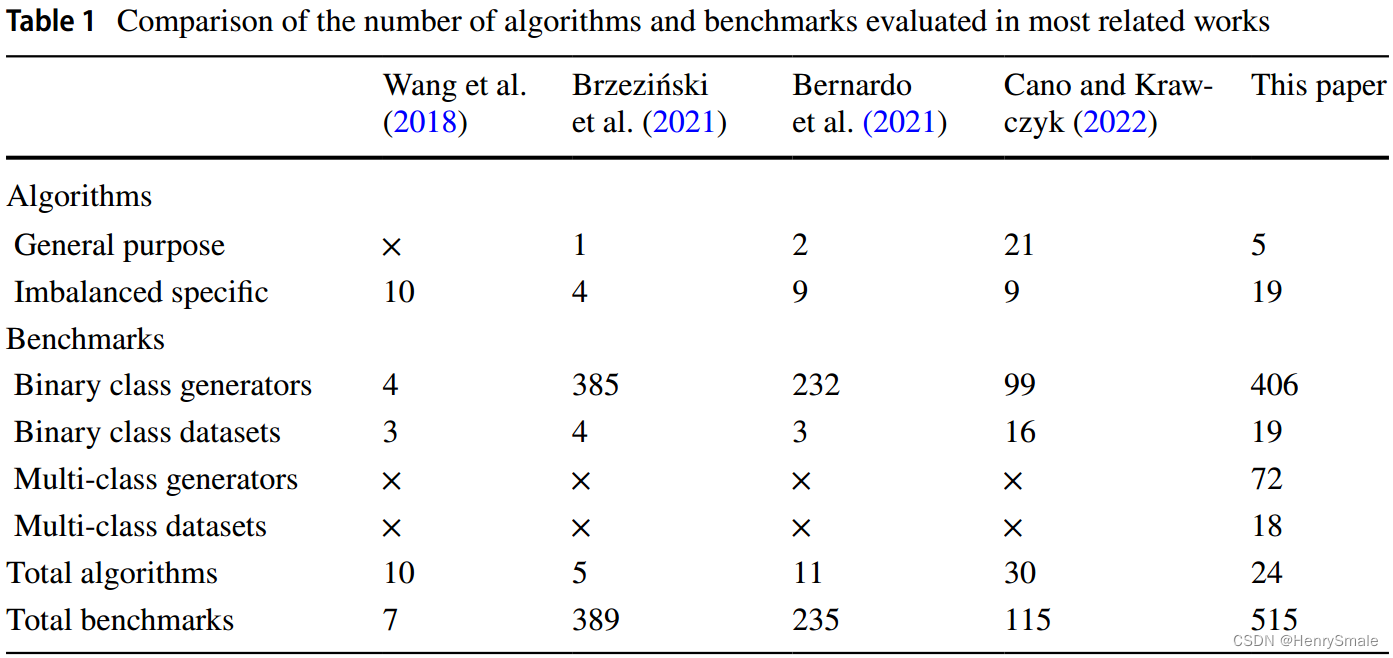
与大多数相关实验工作的比较。近年来,发表了几篇涉及类不平衡和数据流联合领域的大型实验研究的调查论文和著作。因此,重要的是要了解他们和这项工作之间的关键区别,以及我们的综述如何为这个主题提供以前的工作中没有涉及的新见解。Wang等人(2018)提出了几种现有技术的概述,包括漂移检测器和自适应分类器,并通过实验比较了它们的预测准确性。虽然是该领域的第一个专门研究,但它的局限性在于没有评估比较算法的计算复杂性,使用了非常小的数据集选择(7个基准),并且只调查了不平衡数据流的有限属性(没有触及实例级特征或多类问题)。Brzeziński等人(2021)提出了一项后续研究,重点关注不平衡流的数据级属性,如实例困难(边界和罕见实例)和子概念的存在。然而,这项研究已经完成对于有限数量的算法(5个分类器),并且只关注两类问题。
Bernardo等人(2021)提出了针对不平衡数据流的方法的实验比较。他们使用不同水平的不平衡比和三种漂移速度扩展了Brzeziński等人(2021)的基准。然而,他们的研究分析了有限数量的算法(11个分类器)和三个真实世界的数据集。Cano和Krawczyk(2022)对30种专注于集成方法的算法进行了大量比较,但其中21种是通用集成,而不是不平衡的特定分类器。
这四个工作只解决二分类不平衡数据流。本文扩展了以往所有研究的基准评估,提出了新的基准场景,扩展了真实数据集的数量,并对两类和多类不平衡数据流进行了评估。我们还将比较扩展到24个分类器,其中19个是专门为不平衡数据流设计的。表1总结了这些作品在实验评价上的主要差异。这使我们得出结论,虽然这些工作是重要的第一步,但需要对从不平衡数据流中学习进行统一,全面和整体的研究,这些研究可以用作研究人员评估其新提出的算法的模板。
本文组织如下。第2节提供了数据流的背景知识。第3节讨论了不平衡数据的主要挑战。第4节介绍了不平衡流的具体困难。第5节描述了处理不平衡流的集成方法。第6节介绍了实验设置和方法。第7节给出并分析了我们的研究结果。第8节总结了经验教训。第9节为最终用户选择不平衡数据流的最佳算法提出了建议。第10节讨论了开放的挑战和未来的方向。最后,第11节给出了结论。