-> SELECT c.first_name, c.last_name,
-> time(r.rental_date) rental_time
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) = '2005-06-14'
-> ORDER BY 3 desc;
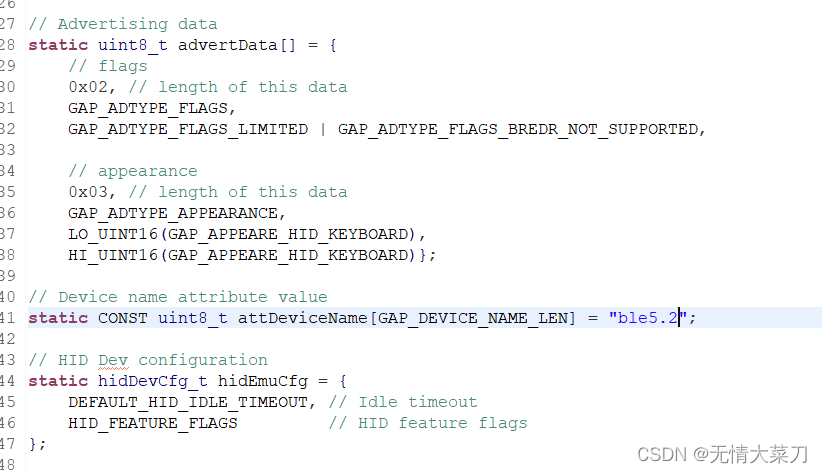
BLE 蓝牙数据广播格式{6个字节(蓝牙设备MAC 地址)AD structure…AD structure N } 37字节 AD structure 长度类型内容
修改被扫描状态(被发现状态)的name:take 被扫描状态的name: take 链接后的状态变成;变成广播态;name: BLE…
1.代码
1.1 t2.js
var year "test";
export { year };
1.2 t1.js import { year } from ./t2.jsalert(year);
1.3 t.html <script type"module" src"./t1.js"></script>
2.运行结果
目录 前言
一、MyBatis动态SQL
1.动态SQL是什么
2.动态SQL的作用
3.常用动态SQL元素
1. where if 元素
2. set if 元素
3. choose when otherwise 元素
4. 自定义 trim 元素 <1>. 自定义 trim 元素改写上面的 where if 语句
<2>. 自定义 trim 元素改…
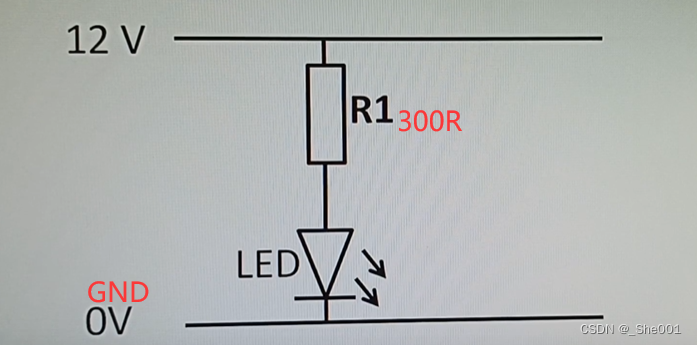
1. LED 的介绍
1.1 LED 是什么 LED :是一种能发光的半导体电子元件。发光二极管(LED)于20世纪60年代问世。在20世纪80年代之前,LED主要作为指示灯使用,从其光色来看,只有红光、橙光、黄光和绿光等几种。这一时期属于…