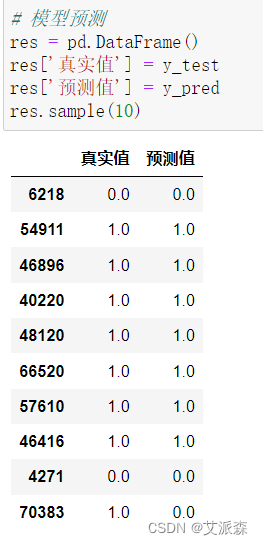
论文名称: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文下载链接:https://arxiv.org/abs/2010.11929
前言
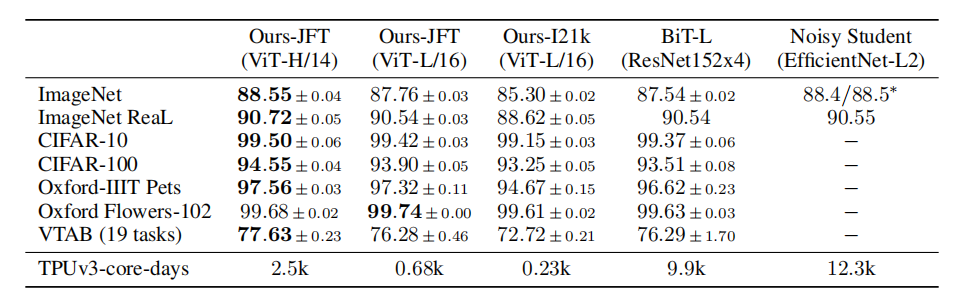
Transformer早在2020年就在NLP领域大放异彩,并通过BERT等无监督预训练技术将NLP推上一个新的高度。VIT受其启发,尝试将Transformer应用到CV领域,并通过JFT数据预训练,在ImageNet1K上能够达到88.55%的准确率。如今,Transformer在CV,NLP,多模态等领域均已达到最先进水平,值得大家学习并应用于工作中。接下来的时间,将记录我在CV领域大模型的学习历程,欢迎大家一起讨论,互相学习。
模型详解
ViT流程简述:ViT通过大kernel的卷积将输入图片分为多个patch,这些patch就如同NLP中的token,会被投影为固定长度的向量送入Transformer Encoder中。通过L层Transformer Encoder输出特征O。由于是分类任务,在输入的token中加入一个特殊的cls_token,该token与patch embedding产生的token一样,会在Transformer Encoder中与其他token计算qkv,建立全局语义,并经过全连接最后输出预测类别。
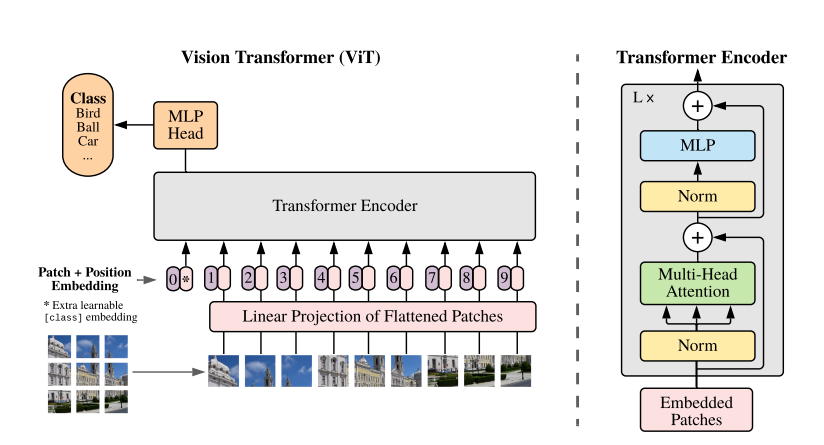
如上图所示,ViT分为以下几个步骤:
1.patch embedding
对于图像其数据格式为[N, C, H, W,],这里将其看作维度为[64,3,224,224]的输入。如下代码所示,首先通过self.projection(kernel=16,stride=16的conv2d)将图片(224x224)按照16x16大小的Patch进行划分,划分后会得到
(
224
/
16
)
2
( 224 / 16 ) ^2
(224/16)2 =196个Patches,经过self.projection后输入变为维度为[64,768,14,14]的特征,由于kernel与stride较大,需要对输入进行补边self.adaptive_padding(x)。接着通过线性映射(x = x.flatten(2).transpose(1, 2))将特征[64,768,14,14]转换成[64,196,768]维度,patch embedding时,self.norm=None,因此这里特征没有进行归一化操作。以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过卷积得到一个长度为768的向量(后面都直接称为token,图片patch块[16, 16, 3]embedding为->[1,768]维度的特征)。
引入self.cls_token = nn.Parameter(torch.zeros(1, 1, self.embed_dims)),作为模型最后输出的识别特征,其与上面输出的特征进行cat,获得最终的特征(维度[64,197,768])。至此,ViT就将图像识别问题转换为一个seq2seq问题了。
class PatchEmbed(BaseModule):
def __init__(self,
in_channels=3,
embed_dims=768,
conv_type='Conv2d',
kernel_size=16,
stride=16,
padding='corner',
dilation=1,
bias=True,
norm_cfg=None,
input_size=None,
init_cfg=None):
super(PatchEmbed, self).__init__(init_cfg=init_cfg)
self.embed_dims = embed_dims
if stride is None:
stride = kernel_size
kernel_size = to_2tuple(kernel_size)
stride = to_2tuple(stride)
dilation = to_2tuple(dilation)
if isinstance(padding, str):
self.adaptive_padding = AdaptivePadding(
kernel_size=kernel_size,
stride=stride,
dilation=dilation,
padding=padding)
# disable the padding of conv
padding = 0
else:
self.adaptive_padding = None
padding = to_2tuple(padding)
self.projection = build_conv_layer(
dict(type=conv_type),
in_channels=in_channels,
out_channels=embed_dims,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=bias)
if norm_cfg is not None:
self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
else:
self.norm = None
if input_size:
input_size = to_2tuple(input_size)
# `init_out_size` would be used outside to
# calculate the num_patches
# e.g. when `use_abs_pos_embed` outside
self.init_input_size = input_size
if self.adaptive_padding:
pad_h, pad_w = self.adaptive_padding.get_pad_shape(input_size)
input_h, input_w = input_size
input_h = input_h + pad_h
input_w = input_w + pad_w
input_size = (input_h, input_w)
# https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
h_out = (input_size[0] + 2 * padding[0] - dilation[0] *
(kernel_size[0] - 1) - 1) // stride[0] + 1
w_out = (input_size[1] + 2 * padding[1] - dilation[1] *
(kernel_size[1] - 1) - 1) // stride[1] + 1
self.init_out_size = (h_out, w_out)
else:
self.init_input_size = None
self.init_out_size = None
def forward(self, x):
if self.adaptive_padding:
x = self.adaptive_padding(x)
x = self.projection(x)
out_size = (x.shape[2], x.shape[3])
x = x.flatten(2).transpose(1, 2)
if self.norm is not None:
x = self.norm(x)
return x, out_size
2.positional encoding
在步骤1patch embedding中,ViT将输入[64,3,224,224]embedding成维度为[64,197,768]的tokens,这个过程将二维图片降维成一维token,丢失了位置信息。为了在token中重新引入位置信息,ViT加入了位置编码。self.pos_embed是维度为[1,197,768]的可学习参数,通过trunc_normal_截断的正态分布初始化。
self.pos_embed = nn.Parameter(
torch.zeros(1, num_patches + self.num_extra_tokens,
self.embed_dims))
trunc_normal_(self.pos_embed, std=0.02)
这里需要注意,因为ViT需要在大数据集上进行预训练,下游任务中容易出现token的数量不一致的问题,即预训练时图片尺寸与下游任务图片尺寸不同,num_patches不一致,导致self.pos_embed位置编码维度不同。为了解决这个问题,ViT对self.pos_embed的参数进行插值,从而保证维度一致,且一定程度保留预训练的位置信息。卷积以及全连接可以处理不同的输入尺寸(channel不变),因此只需要将self.pos_embed的参数插值保证与num_patches维度一致,就可以将预训练模型迁移至下游任务中进行finetune。
def resize_pos_embed(pos_embed,
src_shape,
dst_shape,
mode='bicubic',
num_extra_tokens=1):
if src_shape[0] == dst_shape[0] and src_shape[1] == dst_shape[1]:
return pos_embed
assert pos_embed.ndim == 3, 'shape of pos_embed must be [1, L, C]'
_, L, C = pos_embed.shape
src_h, src_w = src_shape
assert L == src_h * src_w + num_extra_tokens, \
f"The length of `pos_embed` ({L}) doesn't match the expected " \
f'shape ({src_h}*{src_w}+{num_extra_tokens}). Please check the' \
'`img_size` argument.'
extra_tokens = pos_embed[:, :num_extra_tokens]
src_weight = pos_embed[:, num_extra_tokens:]
src_weight = src_weight.reshape(1, src_h, src_w, C).permute(0, 3, 1, 2)
dst_weight = F.interpolate(
src_weight, size=dst_shape, align_corners=False, mode=mode)
dst_weight = torch.flatten(dst_weight, 2).transpose(1, 2)
return torch.cat((extra_tokens, dst_weight), dim=1)
3.Transformer Encoder

在步骤2中,ViT将token与位置编码sum获得输入Transformer Encoder的特征Embeded Patch。从图中我们知道,Transformer Encoder包含了3个组成部分,Norm,Multi-Head Attention以及MLP。这里Norm指的时layer norm(LN), Multi-Head Attention值self-attention中的多头注意力,MLP是两层全连接层。

LN:
ln是一种特征归一化方式,与BN类似,如上图所示,LN处理的特征维度是[C,H,W],即每幅图单独计算方差,期望,并归一化特征。强调一下,这里为什么使用LN。因为在NLP中,token长度不是一个定值,在一个batch中,可能出现不同长度的token,如果使用BN,统计batch中的每个channel维度的统计量,丢失了句子之间的关联性,且长度不一致需要补0,统计量随机性高,没有太大意义。而LN是对单个数据进行Norm与batch无关,token长度不影响LN计算统计量,且包含整句话语义,使句子关联性更强。这里使用LN是为了不改变transformer结构。

Multi-Head Attention:
由于self-attention的计算参数有限(只有qkv3个全连接层),限制了模型的表达能力。为了提高模型复杂程度,其借鉴了CNN中的channel,即用多个self-attention将其堆叠起来,既不增加内存,又丰富了模型参数,并称之为Multi-Head Attention。
如下代码所示,x为特征Embeded Patch其维度是[64,197,768],通过全连接(self.qkv = nn.Linear(self.input_dims, embed_dims * 3, bias=qkv_bias))转化为qkv(维度[64,197,2304]),因为qkv为三个特征,这里embed_dims需要×3。由于是多头注意力,这里需要将qkv reshape成(B, N, 3, self.num_heads, self.head_dims)维度,其中B是batchsize,N=197是token个数,self.num_heads=12为头数, self.head_dims=64是每个头的维度。由于qkv是通过一个全连接处理获得的,所以需要将其分开q, k, v = qkv[0], qkv[1], qkv[2]。


首先计算QK每一行内积,为了防止内积过大,需要除以
d
k
1
/
2
d_k^{1/2}
dk1/2。利用softmax将其激活成V的系数。这里每个token的V都会与其他token计算attention,所以transformer从一开始就具备了全局语义全局感受野,这是与CNN的最大差异(CNN需要堆叠大量的downsample才能让模型深处的特征具有大的感受野)。
class MultiheadAttention(BaseModule):
"""Multi-head Attention Module
Args:
embed_dims (int): The embedding dimension.
num_heads (int): Parallel attention heads.
input_dims (int, optional): The input dimension, and if None,
use ``embed_dims``. Defaults to None.
attn_drop (float): Dropout rate of the dropout layer after the
attention calculation of query and key. Defaults to 0.
proj_drop (float): Dropout rate of the dropout layer after the
output projection. Defaults to 0.
dropout_layer (dict): The dropout config before adding the shortcut.
Defaults to ``dict(type='Dropout', drop_prob=0.)``.
qkv_bias (bool): If True, add a learnable bias to q, k, v.
Defaults to True.
qk_scale (float, optional): Override default qk scale of
``head_dim ** -0.5`` if set. Defaults to None.
proj_bias (bool) If True, add a learnable bias to output projection.
Defaults to True.
v_shortcut (bool): Add a shortcut from value to output. It's usually
used if ``input_dims`` is different from ``embed_dims``.
Defaults to False.
init_cfg (dict, optional): The Config for initialization.
Defaults to None.
"""
def __init__(self,
embed_dims,
num_heads,
input_dims=None,
attn_drop=0.,
proj_drop=0.,
dropout_layer=dict(type='Dropout', drop_prob=0.),
qkv_bias=True,
qk_scale=None,
proj_bias=True,
v_shortcut=False,
init_cfg=None):
super(MultiheadAttention, self).__init__(init_cfg=init_cfg)
self.input_dims = input_dims or embed_dims
self.embed_dims = embed_dims
self.num_heads = num_heads
self.v_shortcut = v_shortcut
self.head_dims = embed_dims // num_heads
self.scale = qk_scale or self.head_dims**-0.5
self.qkv = nn.Linear(self.input_dims, embed_dims * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(embed_dims, embed_dims, bias=proj_bias)
self.proj_drop = nn.Dropout(proj_drop)
self.out_drop = DROPOUT_LAYERS.build(dropout_layer)
def forward(self, x):
B, N, _ = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
self.head_dims).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.embed_dims)
x = self.proj(x)
x = self.out_drop(self.proj_drop(x))
if self.v_shortcut:
x = v.squeeze(1) + x
return x
MLP:
将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768,在mmcls中MLP也称为FFN。
class FFN(BaseModule):
"""Implements feed-forward networks (FFNs) with identity connection.
"""
@deprecated_api_warning(
{
'dropout': 'ffn_drop',
'add_residual': 'add_identity'
},
cls_name='FFN')
def __init__(self,
embed_dims=256,
feedforward_channels=1024,
num_fcs=2,
act_cfg=dict(type='ReLU', inplace=True),
ffn_drop=0.,
dropout_layer=None,
add_identity=True,
init_cfg=None,
**kwargs):
super(FFN, self).__init__(init_cfg)
assert num_fcs >= 2, 'num_fcs should be no less ' \
f'than 2. got {num_fcs}.'
self.embed_dims = embed_dims
self.feedforward_channels = feedforward_channels
self.num_fcs = num_fcs
self.act_cfg = act_cfg
self.activate = build_activation_layer(act_cfg)
layers = []
in_channels = embed_dims
for _ in range(num_fcs - 1):
layers.append(
Sequential(
Linear(in_channels, feedforward_channels), self.activate,
nn.Dropout(ffn_drop)))
in_channels = feedforward_channels
layers.append(Linear(feedforward_channels, embed_dims))
layers.append(nn.Dropout(ffn_drop))
self.layers = Sequential(*layers)
self.dropout_layer = build_dropout(
dropout_layer) if dropout_layer else torch.nn.Identity()
self.add_identity = add_identity
@deprecated_api_warning({'residual': 'identity'}, cls_name='FFN')
def forward(self, x, identity=None):
"""Forward function for `FFN`.
The function would add x to the output tensor if residue is None.
"""
out = self.layers(x)
if not self.add_identity:
return self.dropout_layer(out)
if identity is None:
identity = x
return identity + self.dropout_layer(out)
整个TransformerEncoderLayer就由上述几个部分组成,其中norm均为LN,且每层都增加了dropout。由于Transformer模型表达能力强,容易造成过拟合的现象,ViT中添加了大量dropout,droppath操作。
class TransformerEncoderLayer(BaseModule):
def __init__(self,
embed_dims,
num_heads,
feedforward_channels,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
num_fcs=2,
qkv_bias=True,
act_cfg=dict(type='GELU'),
norm_cfg=dict(type='LN'),
init_cfg=None):
super(TransformerEncoderLayer, self).__init__(init_cfg=init_cfg)
self.embed_dims = embed_dims
self.norm1_name, norm1 = build_norm_layer(
norm_cfg, self.embed_dims, postfix=1)
self.add_module(self.norm1_name, norm1)
self.attn = MultiheadAttention(
embed_dims=embed_dims,
num_heads=num_heads,
attn_drop=attn_drop_rate,
proj_drop=drop_rate,
dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
qkv_bias=qkv_bias)
self.norm2_name, norm2 = build_norm_layer(
norm_cfg, self.embed_dims, postfix=2)
self.add_module(self.norm2_name, norm2)
self.ffn = FFN(
embed_dims=embed_dims,
feedforward_channels=feedforward_channels,
num_fcs=num_fcs,
ffn_drop=drop_rate,
dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
act_cfg=act_cfg)
@property
def norm1(self):
return getattr(self, self.norm1_name)
@property
def norm2(self):
return getattr(self, self.norm2_name)
def init_weights(self):
super(TransformerEncoderLayer, self).init_weights()
for m in self.ffn.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.normal_(m.bias, std=1e-6)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = self.ffn(self.norm2(x), identity=x)
return x
一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出作为encoder的最终输出 ,代表最终的image presentation。ViT流程如下公式:
1.self.patch_embed(x)将图片embeding成token,添加cls_token并cat到x中。将位置编码
E
p
o
s
E_{pos}
Eposresize成patch分辨率与x相加(x = x + resize_pos_embed)作为Transformer Encoder的输入
Z
0
Z_0
Z0;
2.
Z
l
Z_l
Zl输入通过LN归一化
L
N
(
Z
l
)
LN(Z_l)
LN(Zl),并经过多头注意力输出
Z
l
′
Z'_l
Zl′;
3.多头注意力输出
Z
l
′
Z'_l
Zl′经过FFN两层全连接并与其残差相加获得输出
Z
l
Z_l
Zl;
4.cls_token = x[:, 0],最后会将特殊字符cls对应的输出作为encoder的最终输出 ,代表最终的image presentation。
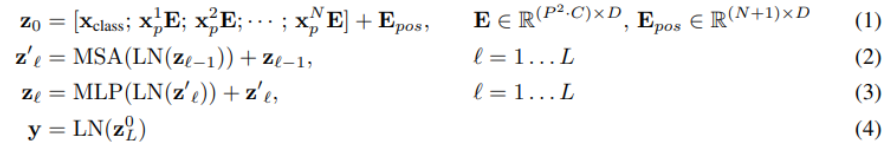
def forward(self, x):
B = x.shape[0]
x, patch_resolution = self.patch_embed(x)
# stole cls_tokens impl from Phil Wang, thanks
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + resize_pos_embed(
self.pos_embed,
self.patch_resolution,
patch_resolution,
mode=self.interpolate_mode,
num_extra_tokens=self.num_extra_tokens)
x = self.drop_after_pos(x)
if not self.with_cls_token:
# Remove class token for transformer encoder input
x = x[:, 1:]
outs = []
for i, layer in enumerate(self.layers):
x = layer(x)
if i == len(self.layers) - 1 and self.final_norm:
x = self.norm1(x)
if i in self.out_indices:
B, _, C = x.shape
if self.with_cls_token:
patch_token = x[:, 1:].reshape(B, *patch_resolution, C)
patch_token = patch_token.permute(0, 3, 1, 2)
cls_token = x[:, 0]
else:
patch_token = x.reshape(B, *patch_resolution, C)
patch_token = patch_token.permute(0, 3, 1, 2)
cls_token = None
if self.output_cls_token:
out = [patch_token, cls_token]
else:
out = patch_token
outs.append(out)
return tuple(outs)

![【Android】 No matching variant of com.android.tools.build:gradle:[版本号] was found](https://img-blog.csdnimg.cn/18061ff5584843479c428b044d21a99c.png#pic)