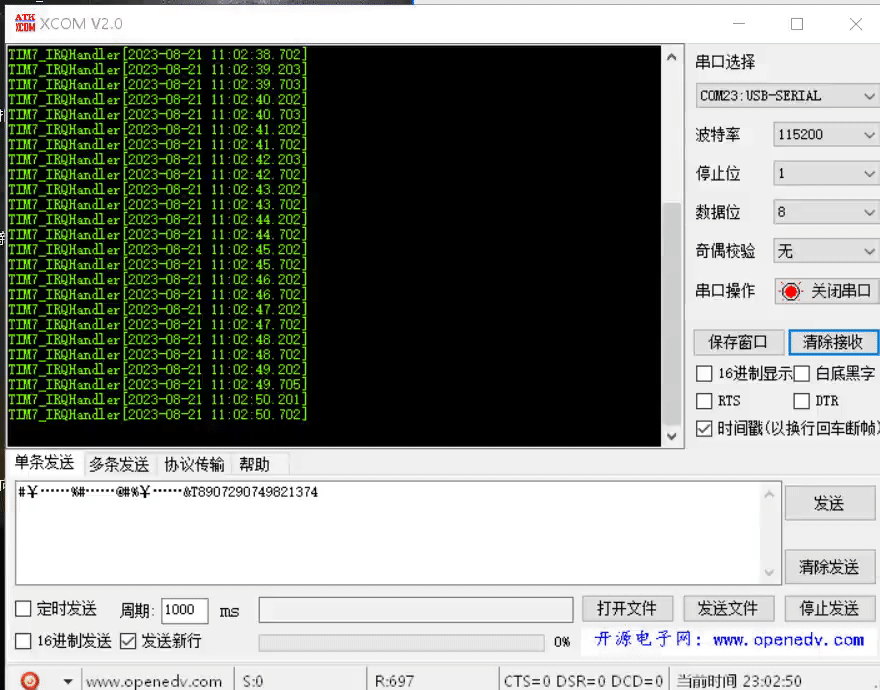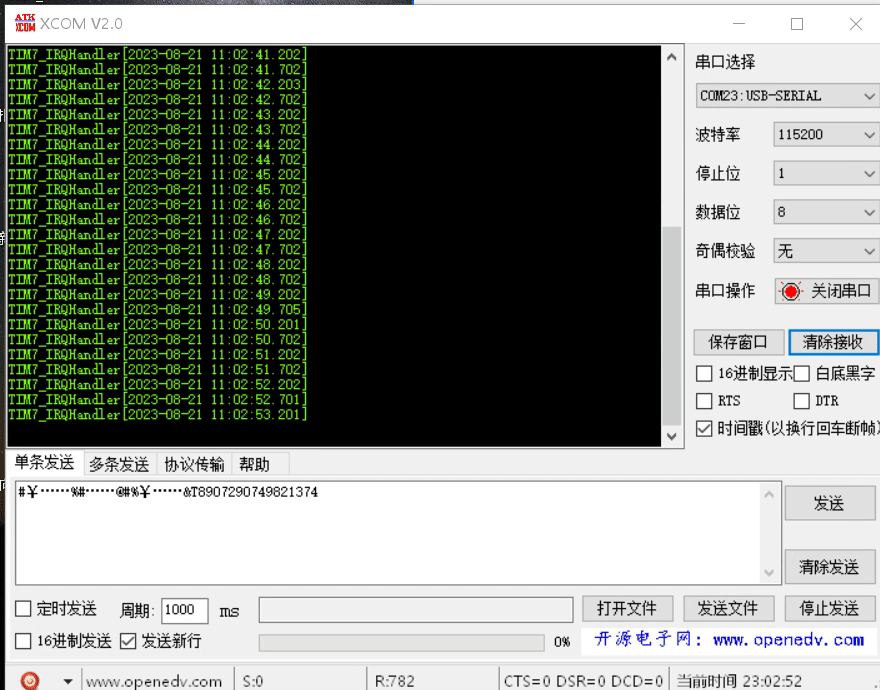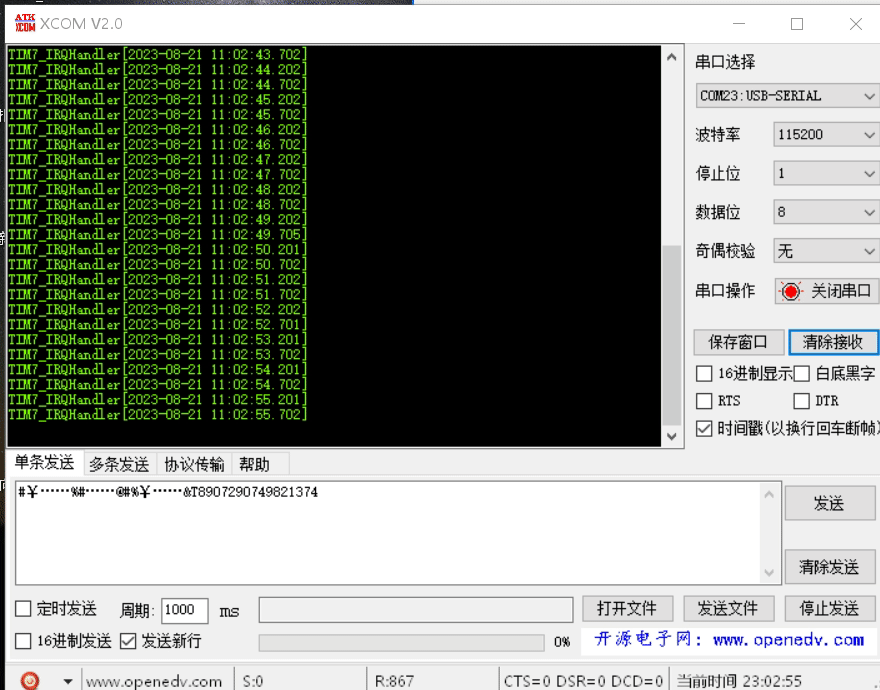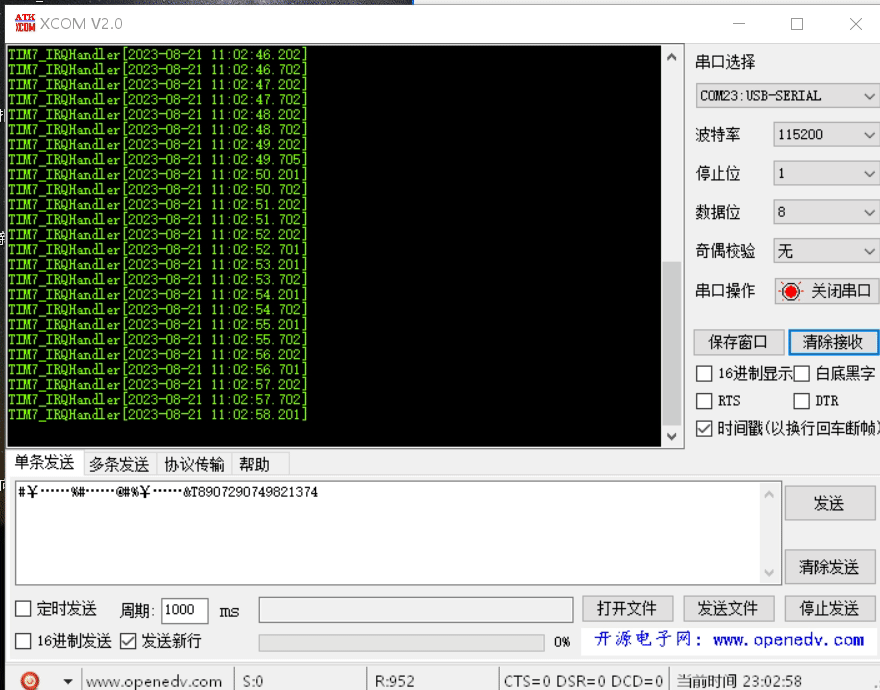
Jctools介绍--jctools是一个Java开源并发非阻塞数据结构实现,其中主要实现了非阻塞Map和非阻塞queue,旨在为Java提供高性能并发数据结构实现;
jctool的特点--为什么性能高:
- lazyset--putOrderedObject,使用loadload内存屏障,写不会立即可见
- 大量的位运算
- 伪共享-通过pad类实现内存填充,使得index的写和element的写不会相互影响
- 无锁--cas循环代替锁
- 循环数组,避免了频繁GC和对象创建---对应的是内存回收和重分配
Jctools中的mpsc实现类即简单介绍--
- MpscArrayQueue
- 基于并发环形数据队列ConcurrentCircularArrayQueue的多生产者单消费者队列
- 该实现使用快速流方法从队列中进行轮询(进行微小更改以正确发布索引),
- 并在producer端扩展了Leslie Lamport并发队列算法(由Martin Thompson提出)。
- 只扩容一次,扩容至初始大小的1.5倍
- MpscBlockingConsumerArrayQueue
- 这是消费者端BlockingQueue的部分实现,仅在BaseMpscLinkedArrayQueue中描述的机制之上,但在本例中,保留位用于阻塞而不是调整大小。
- MpscChunkedArrayQueue
- MPSC阵列队列,从初始容量开始,在初始大小的链接块中增长到maxCapacity。只有当当前区块已满并且元素在调整大小时没有被复制时,队列才会增长,相反,指向新区块的链接会存储在旧区块中,供消费者使用。
- 只扩容一次,可以理解为固定大小
- MpscCompoundQueue
- 内部多个MpscArrayQueue--固定大小
- fastPoll 和 slowPoll---fastPoll根据线程ID来决定那个MpscArrayQueue入队,如果该队满则slowPoll---遍历MpscArrayQueue,寻找可以插入的queue;
- MpscGrowableArrayQueue
- 一个MPSC阵列队列,从 nitialCapacity开始,在链接的块中增长到maxCapacity,每次都将其大小翻倍,直到使用完整的备份阵列。
- MpscLinkedQueue
- 链表实现无界队列
- MpscUnboundedArrayQueue
- MPSC阵列队列,从初始容量开始,在初始大小的链接块中无限增长;
- 无界队列
- MpscUnboundedXaddArrayQueue
- 底层实现还是数组链表
- 与MpscUnboundArrayQueue不同的是,它的设计目的是在更多producer同时提交时提供更好的扩展
可以看出Jctools提供八种Mpsc的具体实现分别针对不同的生产者消费者场景,Jctools提供的Mpscqueue高性能的主要原因是文章开始提到的几种方案,以及对应的具体实现的一些优化技巧,本身使用还是基本的队列操作,屏蔽了底层的实现细节,具体分析几种经典的实现;
首先大概解释一下Mpscqueue中实现性能优化的几种技术方案--
- lazyset:
- Mpsc中很多值通过调用native方法putOrderedObject()来实现写入,而putOrderedObject()方法是Unsafe提供的直接内存操作的方法,大概可以理解为putOrderedObject()方法可以通过一个对象中的内存偏移量直接对内存的某个区域写入值,而根据Java内存模型来说分为工作内存和主内存,而这里putOrderedObject()直接写入的是工作内存,期待后续相关操作或依赖os来延时写入主内存,这就导致了putOrderedObject()写入的值一段时间对线程不可见(包括写入线程),但是提高了线程写入的性能;---在生产者消费者模型下,生产者一般不需要读取消息,而Mpsc下我们认为消费者也不会立即读取消息,所以对于消息写入提高了很大的性能
- 这里需要了解Java的内存模型,内存屏障以及Java对象内存布局相关的知识,详细可以看我其他文章
- 伪共享问题
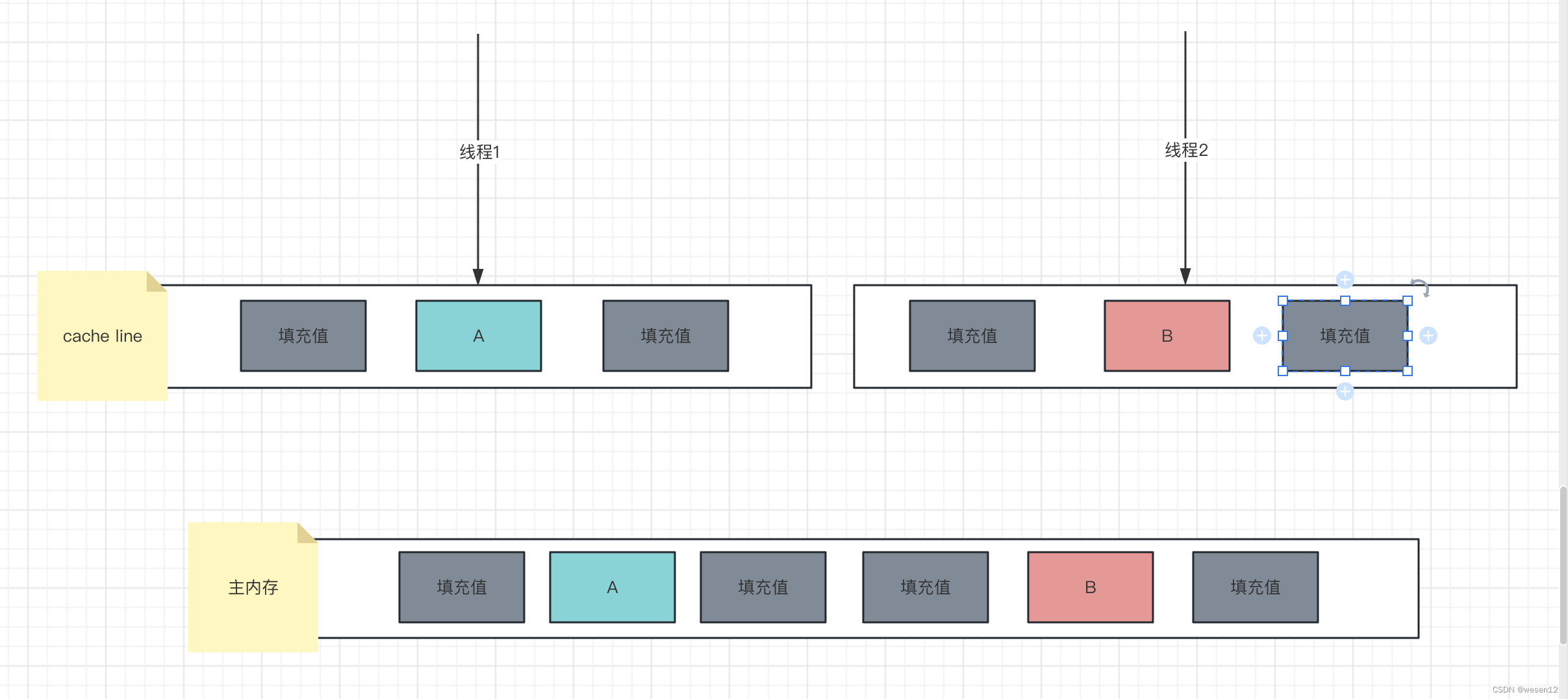
- 现代OS CPU中一般使用多级缓存来解决CPU和内存之间的性能差异,而缓存一般加载缓存行的数据而不是只读取我们程序中需要读的对应的一个值---这里涉及到常用的缓存命中的问题
- 而如果不同的线程对相互相邻的变量进行读写操作,就导致了缓存对缓存行的频繁加载和卸载,导致了性能的浪费--

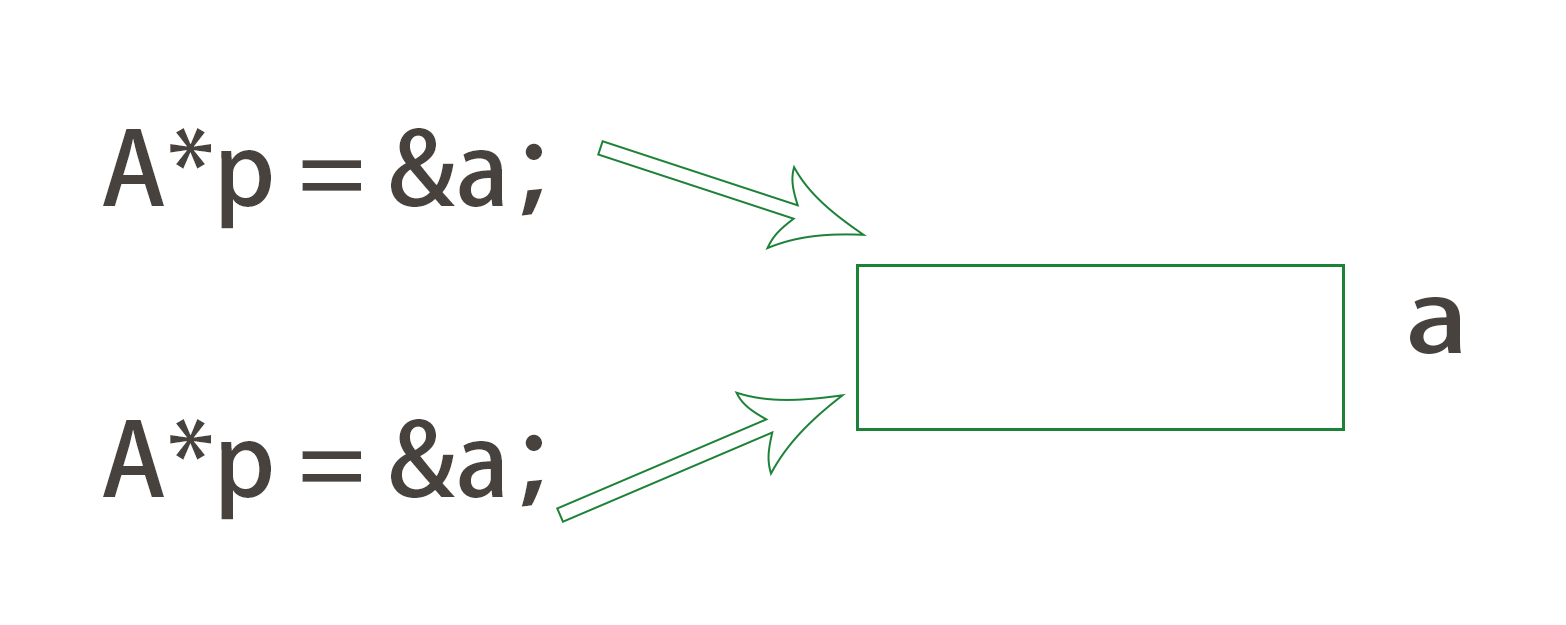
- 具体结合上图解释一下什么是伪共享:
- 首先,根据线程模型来说,同一个进程下的多个线程是贡献内存资源的--这就是共享
- 那什么叫伪共享呢,就是上边提到的线程工作内存,或者具体实现为CPU的多级缓存,每个线程有自己的工作内存,在工作内存中维护了内存中变量的副本,所以站在线程的角度来说变量并不是共享的,而是单独维护副本的;
- 伪共享有什么问题呢?我们知道线程维护了变量副本,但是OS提供的数据模型是线程共享模型,所以,线程中对于副本的修改最终会写回到主内存中从而同步给其他线程,达到真正的内存共享,这就设计到内存一致性协议,Java中的是MEMI;但是OS在为线程读取某个变量的值的时候并不是每次只读取或者写入一个值,而是以cacheline为单位来操作的(cacheline 一般为2的n次幂,大小为64B,128B,具体看os或者机器硬件的实现),如上图中,线程1只对变量A做读写,而线程2只对变量B做读写,但是实际内存中A和B是存储在相邻的内存空间中的,这就导致了线程1和线程2同时将AB作为一个cacheline读取到了自己的工作内存中,而由于OS对于内存一致性的维护,导致,线程1对A的修改需要写回到主存并同步给线程2,线程2对B的读写也是同理,这就导致了由于变量存储位置的关系,导致线程1和线程2逻辑上互不影响的操作实际上相互影响到了,从而导致了不必要的性能浪费;--这里需要注意的是,伪共享问题只发生在不同线程对同一cacheline中的不同变量访问的情况下---如果多个线程对同一个变量使用那就必须每次做同步操作,另外如果多个变量存在于不同的cacheline中的话也不存在伪共享问题;
- 那如何在避免伪共享问题呢?其实很简单,首先伪共享是OS为了提高性能使用的一种缓存命中策略,我们无法改变OS或者硬件的缓存策略,但是我们可以在代码层面改变变量的存储位置,最好的方法是我们保证大多数情况下会被加载到同一个cacheline的一组变量只被一个线程读写,但是这种情况过于复杂,涉及到并行化计算的策略,另外一种思路就是内存填充,内存填充怎么理解呢?我们在大概了解cacheline的大小的情况下,对某一个变量两边填充不会被使用的无用的数据,保证了一个cacheline中只包含了一个变量,从而使得多个线程使用不同变量的时候不会相互影响到;如下图
- Jctools中的Mpsc实现中就通过大量的pad类做为填充类--

总结--Jctools使用无锁和unsafe类中提供的直接内存操作来提高多线程并发下的性能问题;要了解mpsc 的核心优化就要先了解内存共享相关问题;具体的Mpsc实现看后续的文章;