Raft算法是通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致
在分布式系统中,节点可能出现宕机、网络故障等,所以在3个节点的分布式系统中,如何选举出一个Leader节点。比如我们部署一个ZK集群。
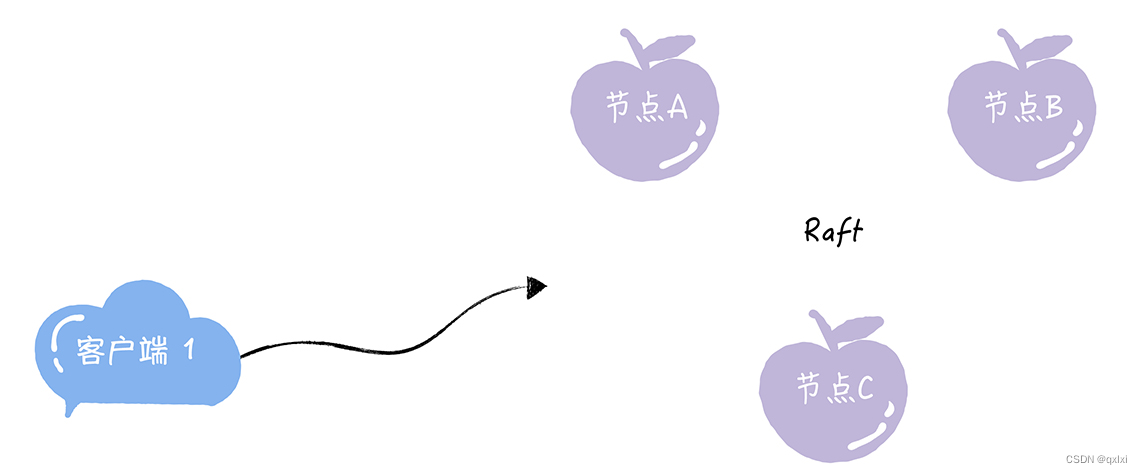
成员
Leader领导者、Follower追随者、候选人(Candidate)每个节点同一时间只会存在一个状态
追随者:接收领导者的消息和心跳检测,如果一定时间没有收到心跳检测就自己跳出来当候选人
候选者:向其他的节点发送消息,通知投票,如果拿到大多数的票,当选为领导者
领导者:处理写请求,管理日志复制和不断发送心跳信息
所以整个过程就是 追随者->
过程
其实整个过程比较简单,raft会随机给每个几点生成一个超时时间。默认所有节点都是追随者。
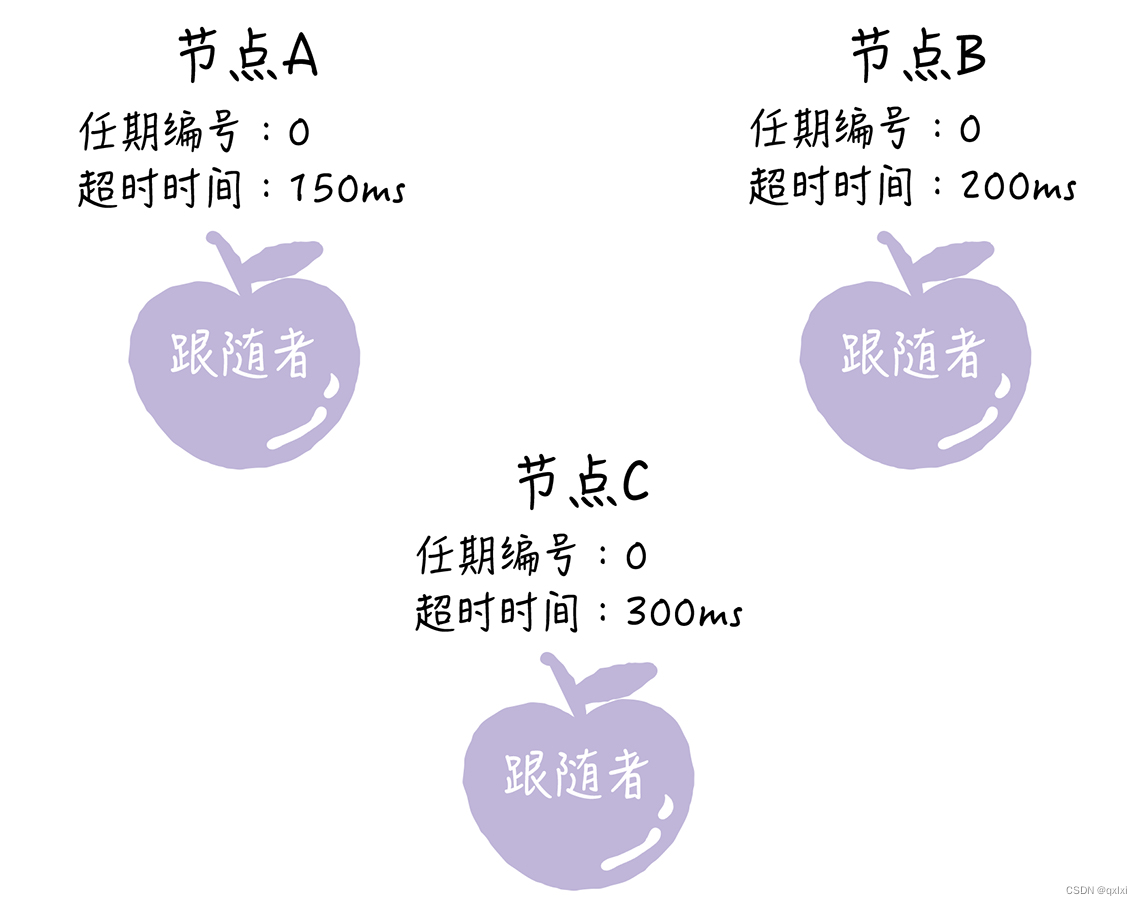
因为节点A的超时时间最短。没有获取到leader。所以先发起投票。将自己的任期编号修改为7
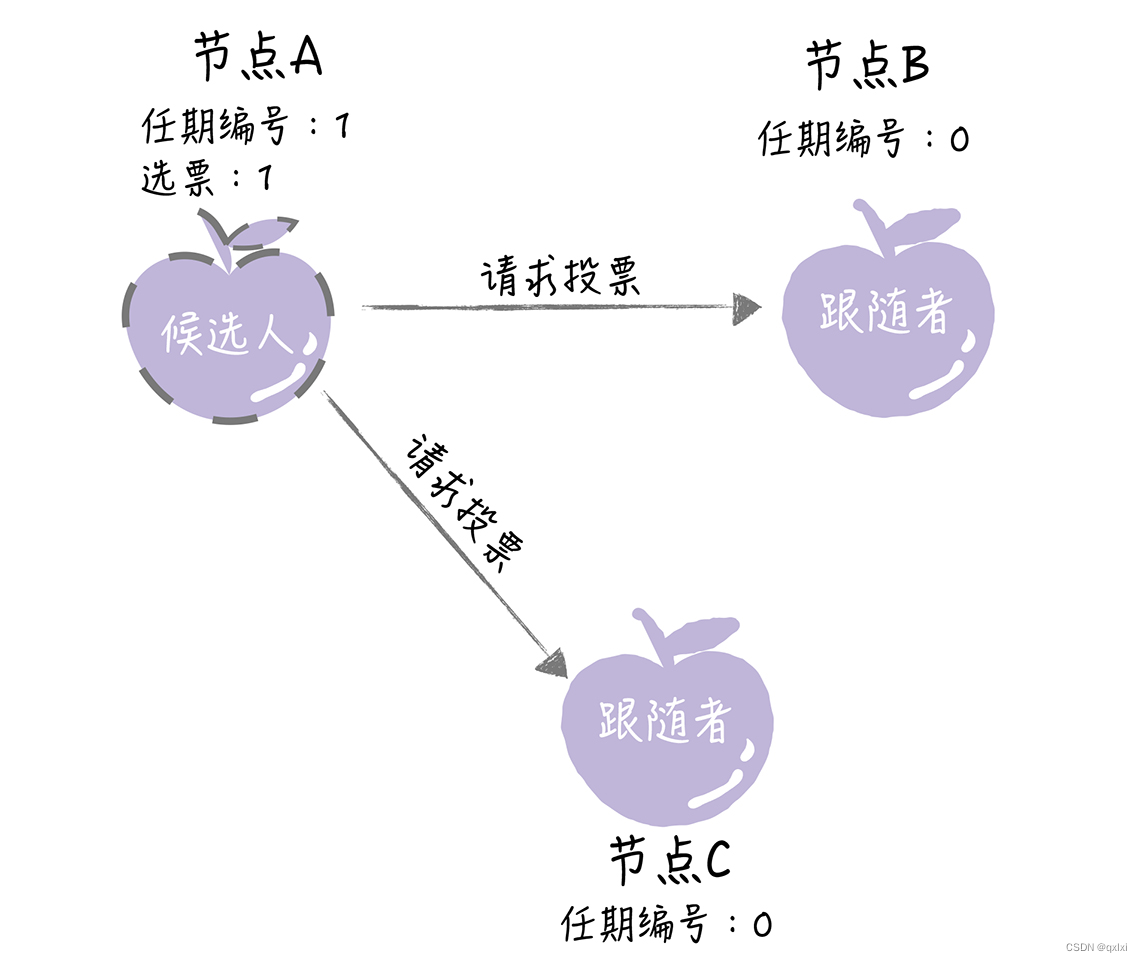
节点A、B。如果在本期任期编号中没有投票那么就投给A。
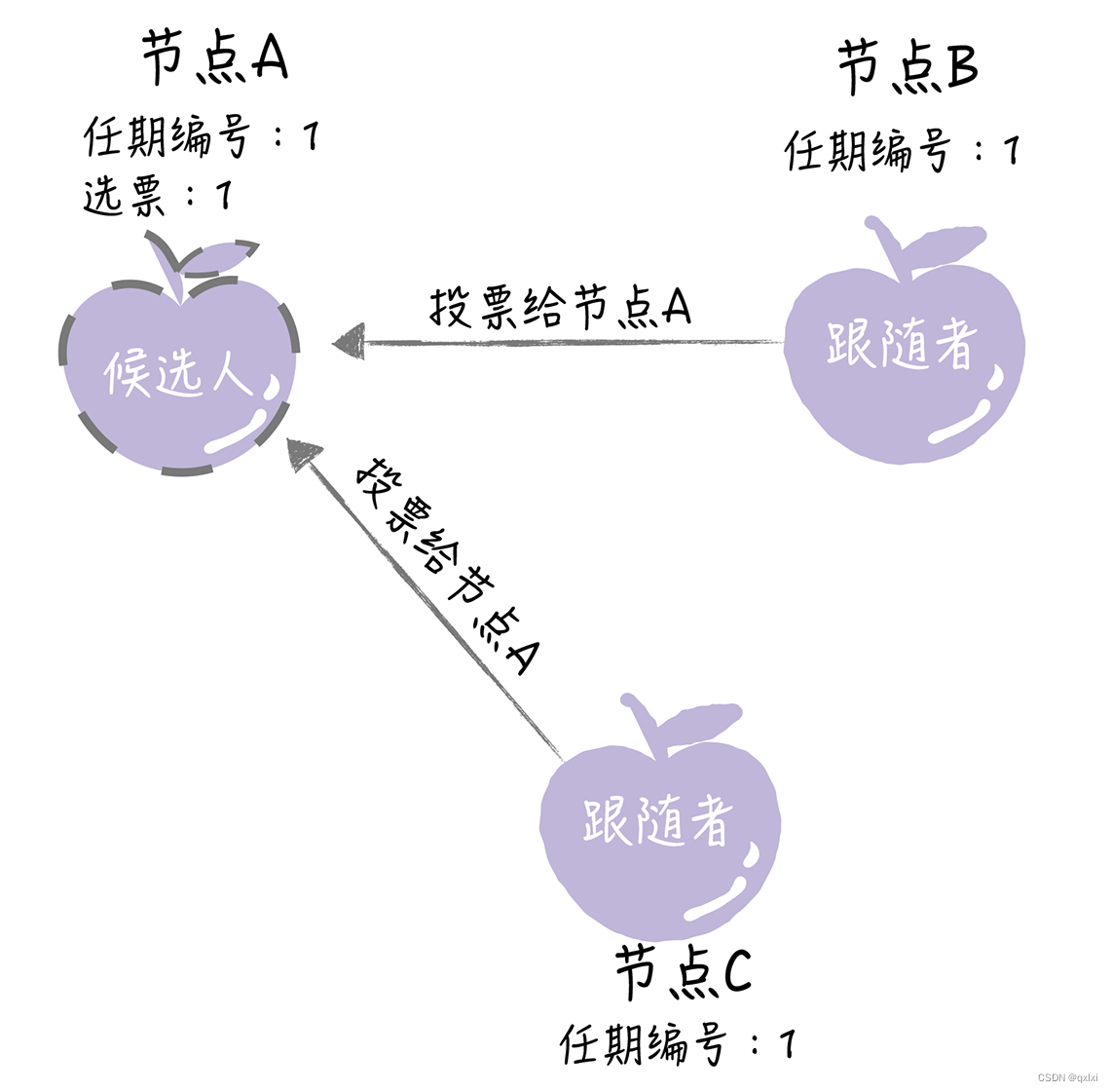
当A成功获取半数以上的票,就成为leader。然后和节点B、节点C进行心跳检测。
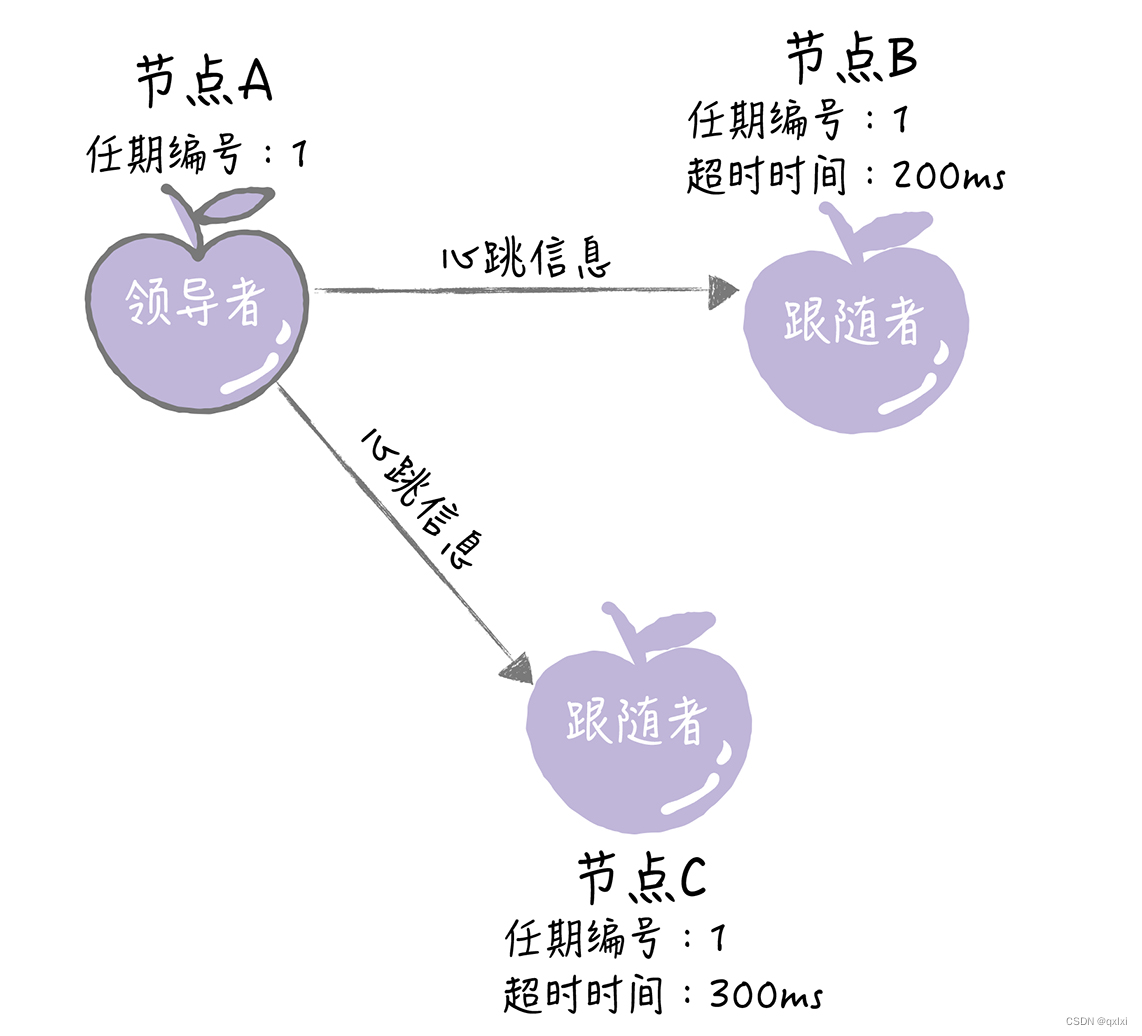
选举有哪些规则
- 一个人在同一编号中只能投一票。
- 领导者周期性的向所有追随者发送心跳消息,告知领导者存活着。
- 如果固定时间内,追随者没有收到领导者的心跳,那么追随者就会发起一轮新的自我选举。
- 一次选举中,票数过半的候选人 晋升为领导者
- 在一个任期内,除非领导者出现宕机或者网络分区,否则会一直它
- 在一次选举中,每个服务器节点都只能提出一票,并且是先到先投。
- 在同一次选举中,如果任期编号相同,日志文件对应的索引号越大,不会给小于自己的投票,直接拒绝。