0. 引言
solr作为搜索引擎经常用于各类查询场景,我们之前讲解了solr的查询语法,而除了普通的查询语法,有时我们还需要实现聚合查询来统计一些指标,所以今天我们接着来查看solr的聚合查询语法
1. 常用聚合查询语法
以下演示我们基于之前创建的核心数据进行,可以参考专栏之前的文章
核心字段结构如下:
order_no : 订单号
address: 地址
product_name: 商品
status: 状态
labels: 标签
remarks: 备注
1.1 group 分组查询
1.1.1 简介
group用于实现简单的聚合分组查询、数值计算等
官网文档:https://solr.apache.org/guide/8_2/result-grouping.html
1.1.2 参数
- group: 设置为true后,查询按分组显示,group:true
- group.field: 根据哪个字段设置分组,配合group:true使用
q=*:*&group=true&group.field=product_name
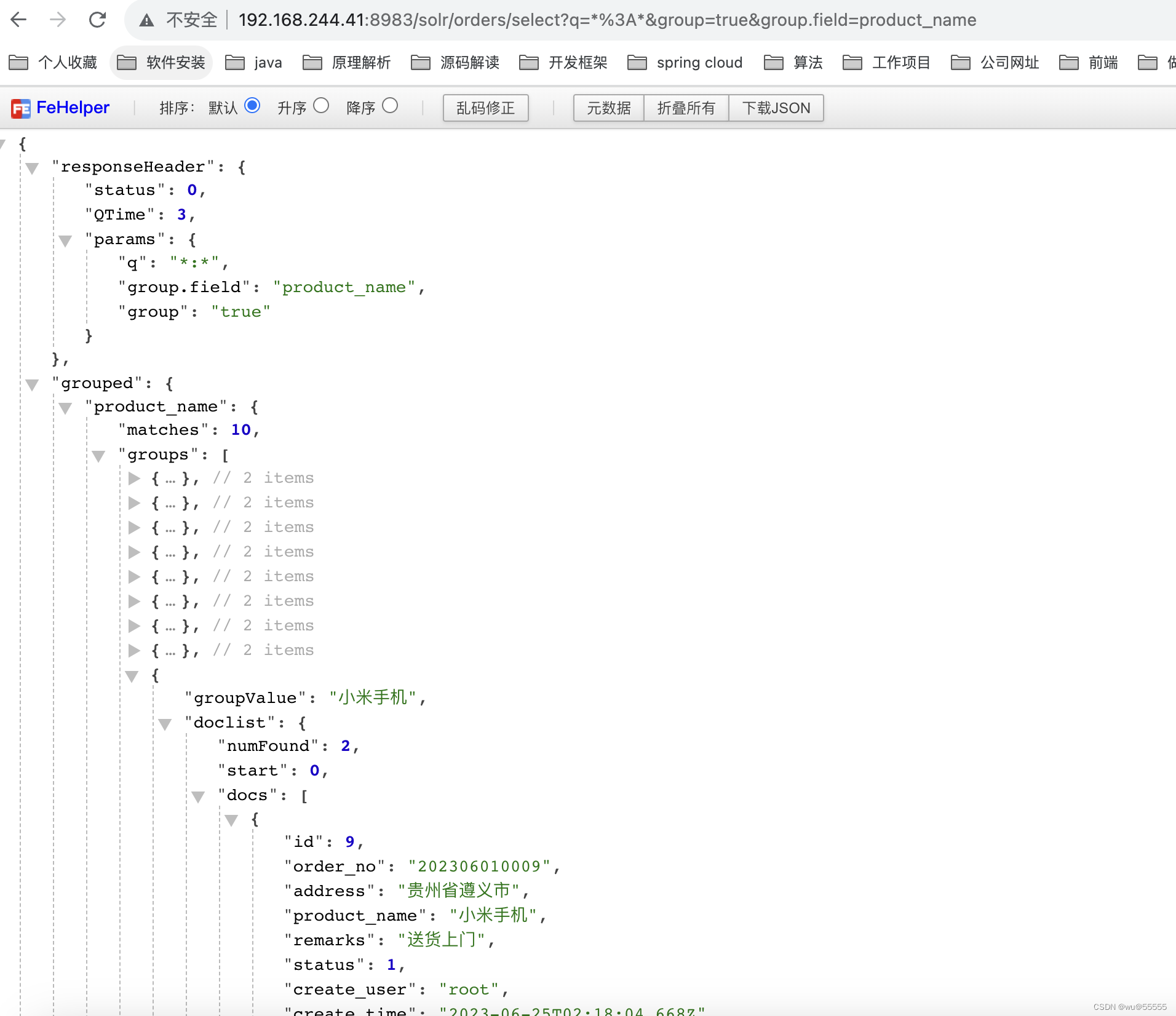
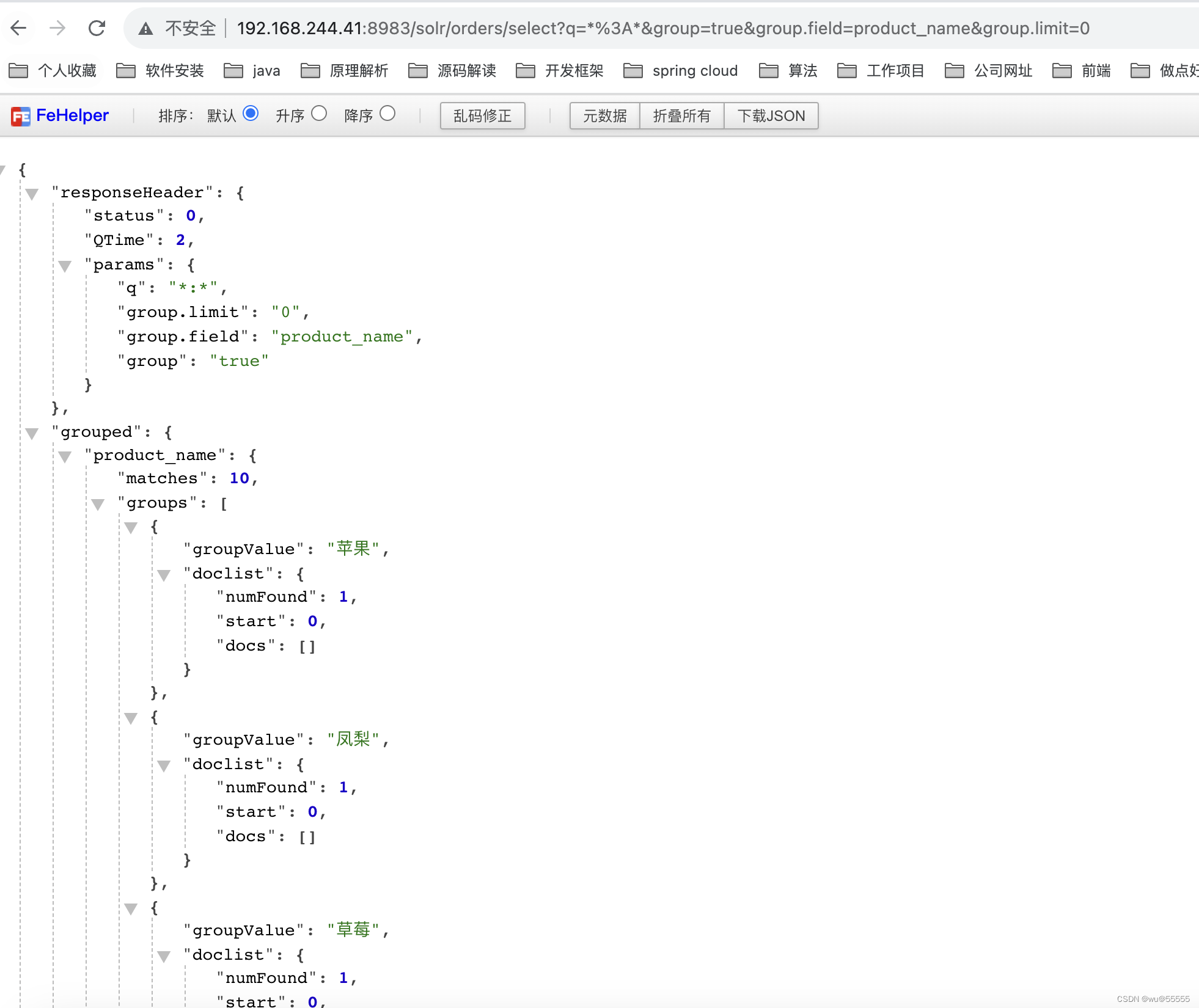
- group.limit:限制返回的docs条数,默认为1,如上所示的示例中,我们发现,每个分组不仅返回的分组数,也返回了命中的详细数据,有的时候我们不需要详细数据,这时就可以将group.limit设置为0来控制返回条数
q=*:*&group=true&group.field=product_name&group.limit=0
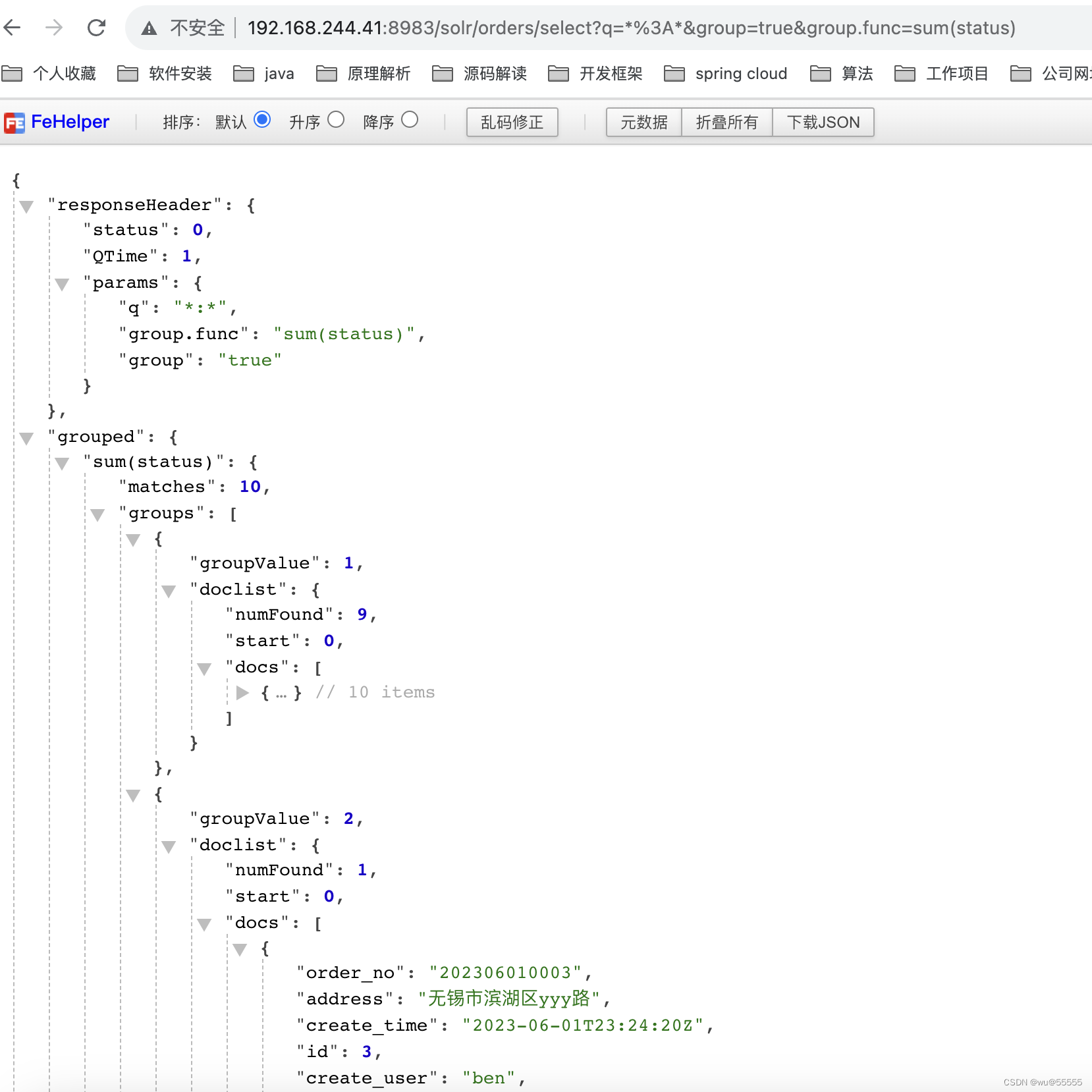
- group.func: 根据函数计算出来的值进行分组,函数支持:求和sum,最小值min,最大值max
q=*:*&group=true&group.func=sum(status)
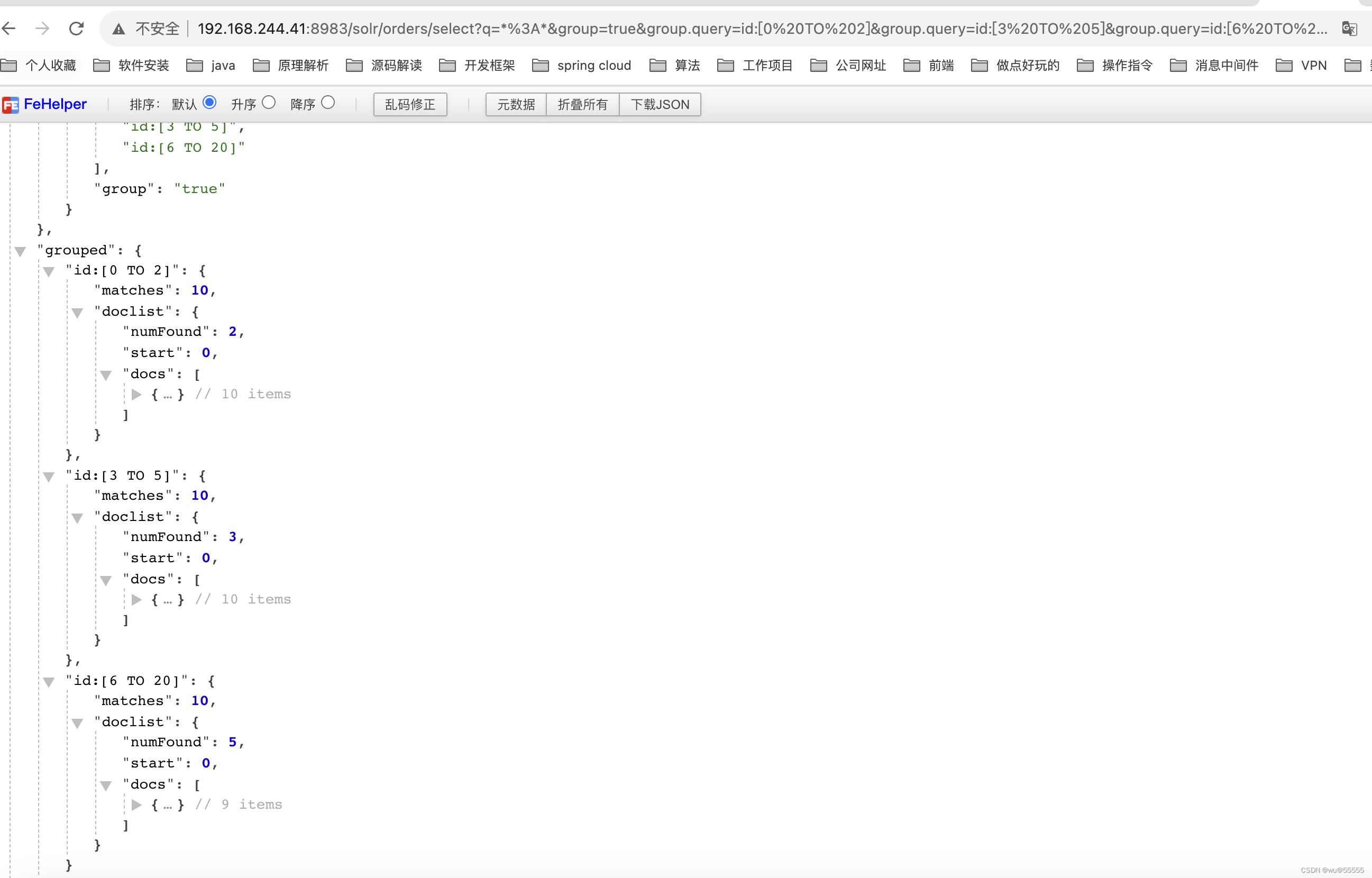
- group.query:根据查询条件进行分组。比如将数据按照0<=id<=2, 3<=id<=5, 6<=id<=20进行分组
q=*:*&group=true&group.query=id:[0 TO 2]&group.query=id:[3 TO 5]&group.query=id:[6 TO 20]
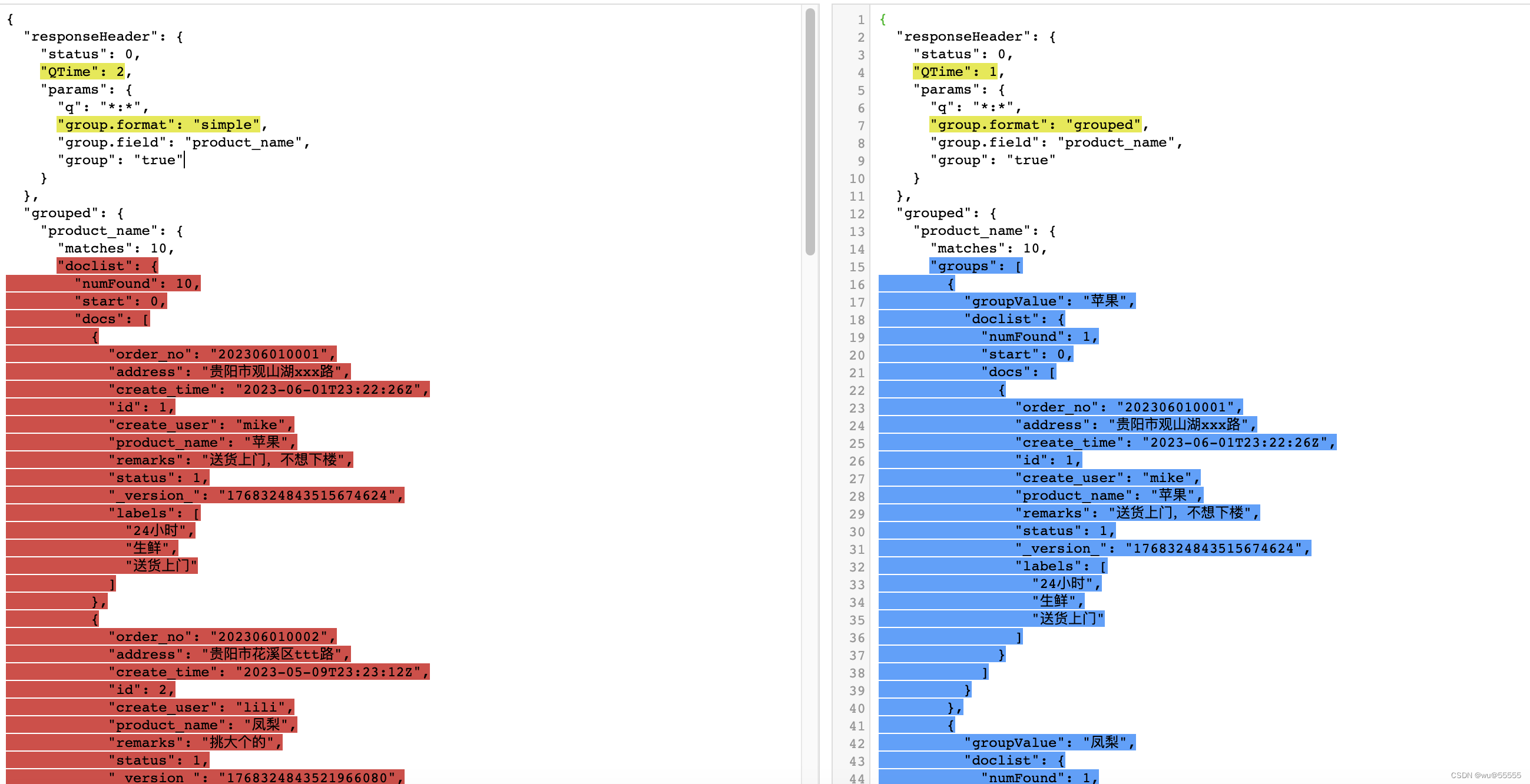
- group.format, 支持两个值:grouped和simple,默认为grouped, 按分组结果展示,如果设置为simple,则会将匹配的结果按平面列表展示,具体可见下图
q=*:*&group=true&group.field=product_name&group.format=simple
q=*:*&group=true&group.field=product_name&group.format=grouped
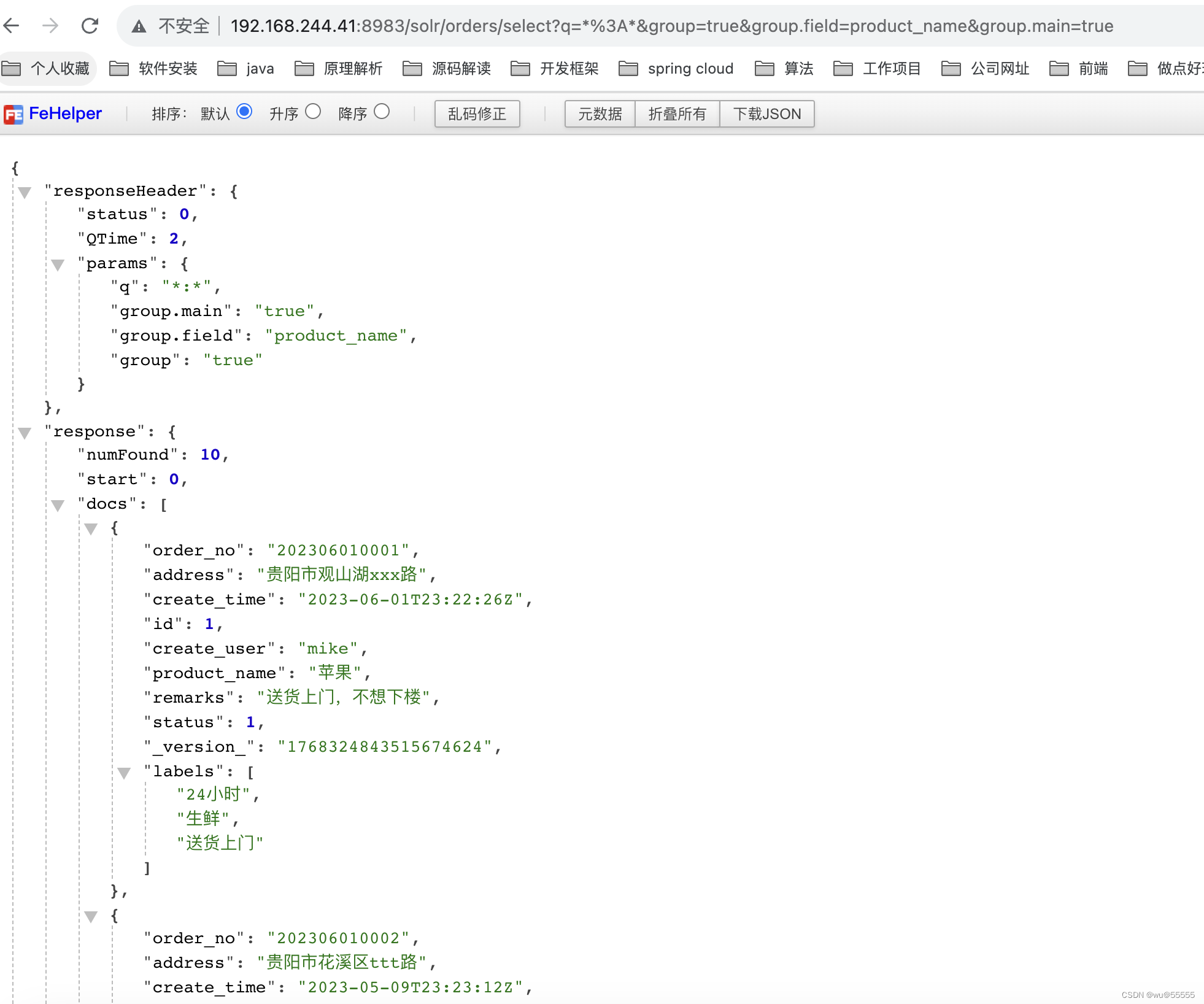
- group.main,是否将第一个字段分组的结果作为返回数据的主结果集,有点类似于group.format=simple (以下解释暂为个人理解,待深入验证,可能存在误解,仅供参考)
q=*:*&group=true&group.field=product_name&group.main=true
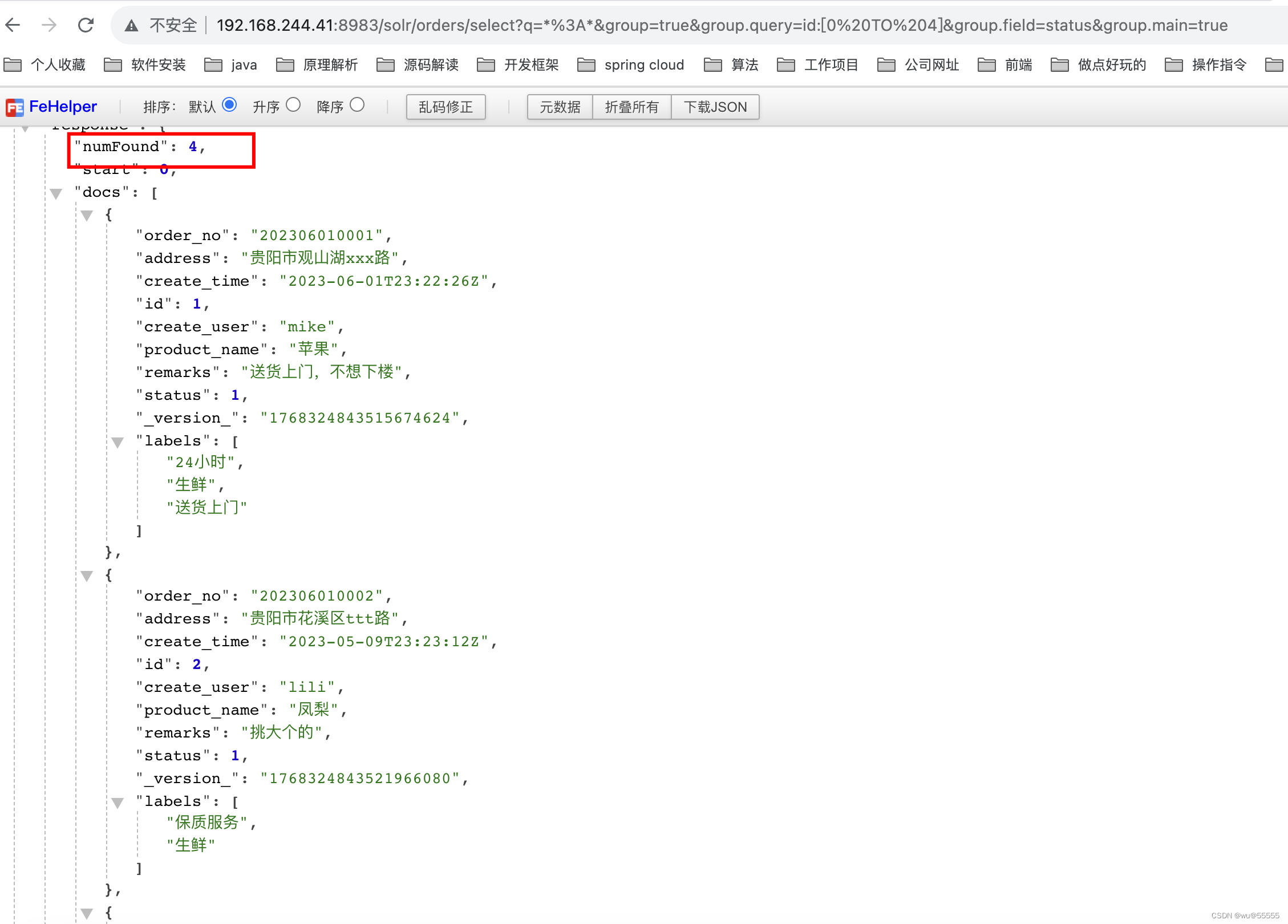
多个分组条件时,显示的就是按照优先级排序后的第一个分组条件的结果详情列表
这里满足group.field=status分组的列表个数是10个,满足group.query:id[0 TO 4]的是4个,因为排序下来group.query:id[0 TO 4]是第一个分组结果集,所以返回的是4个
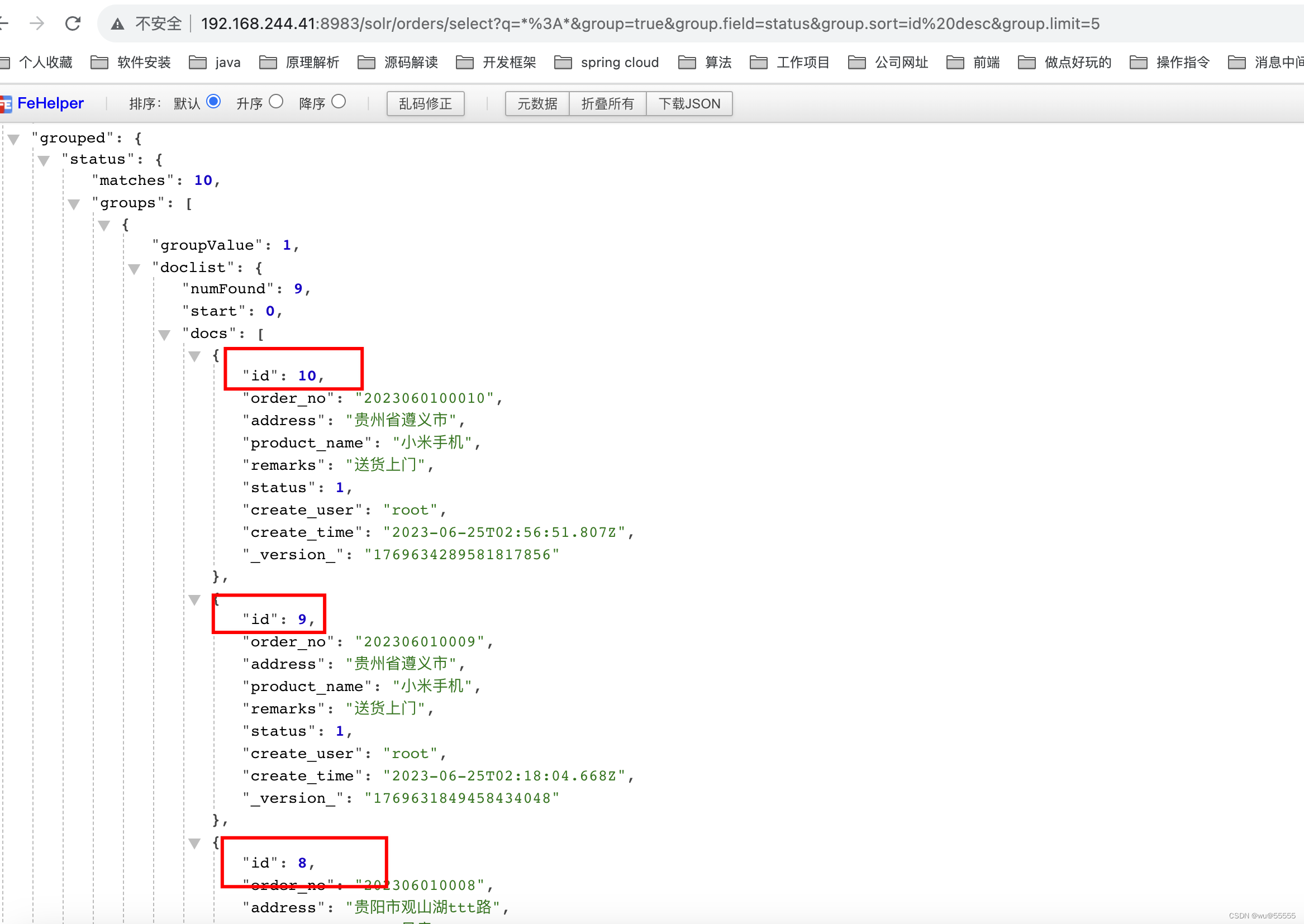
- group.sort:每个分组内文档的排序方式,如下所示,根据status分组,每个分组内docs返回根据id逆序
q=*:*&group=true&group.field=status&group.sort=id desc&group.limit=5
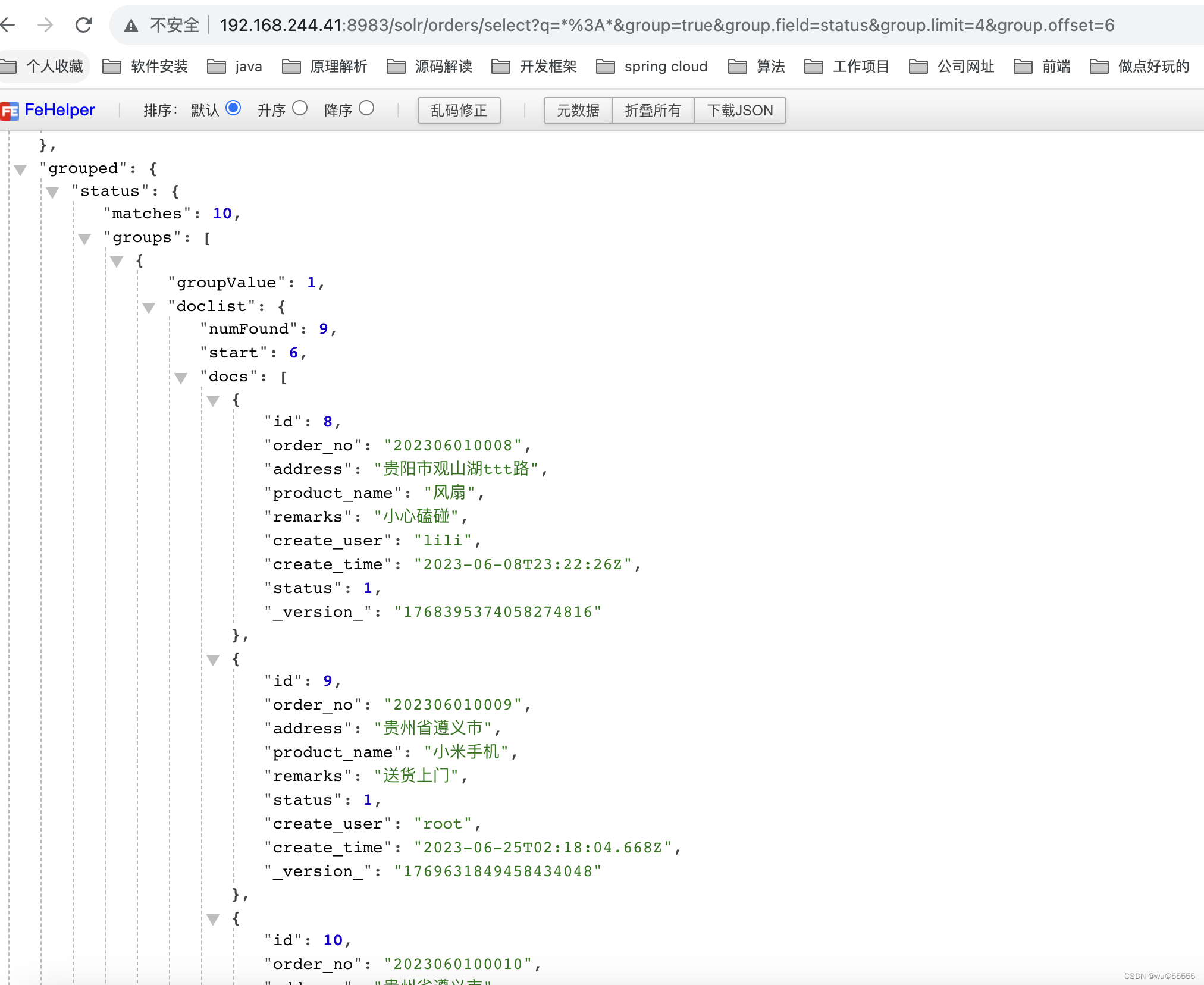
- group.offset:每个分组返回的docs的起点位位置,如下所示,设置group.offset=6,则从id>6后的数据开始显示
q=*:*&group=true&group.field=status&group.limit=4&group.offset=6
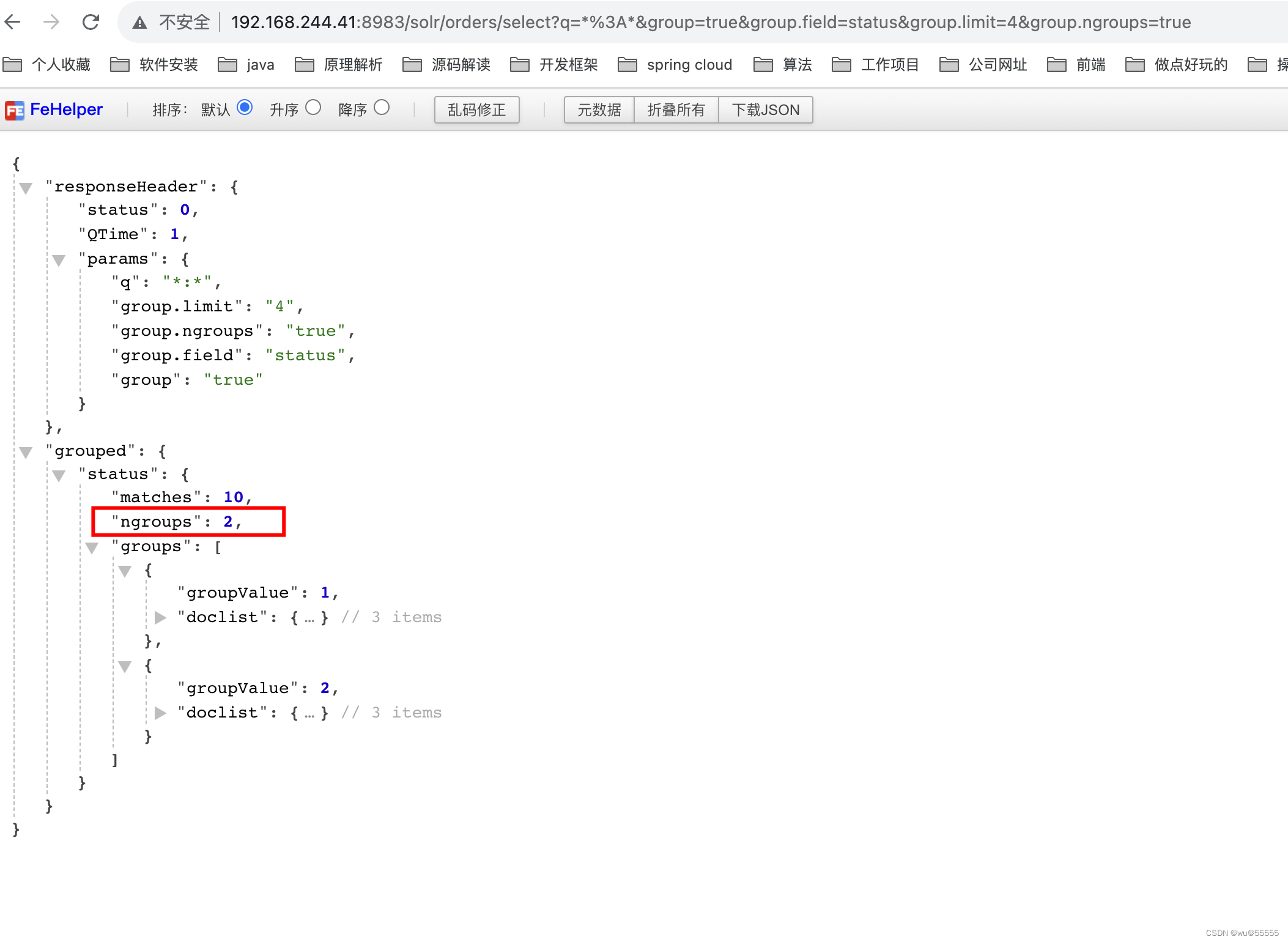
- group.ngroups:是否显示分组数,默认为false
q=*:*&group=true&group.field=status&group.limit=4&group.ngroups=true
- group.truncate,默认为false, 当为ture时,facet计数将基于每组中与查询条件相关度高的文档,而不是全部文档(研究中,暂未找到合适案例)
- row:显示分桶数量,默认为10,有时我们分桶数据不止10个,需要增加显示,可以用row参数设置,相当于sql中的limit
- start:从第几个开始,与row配合,共同组成分页显示
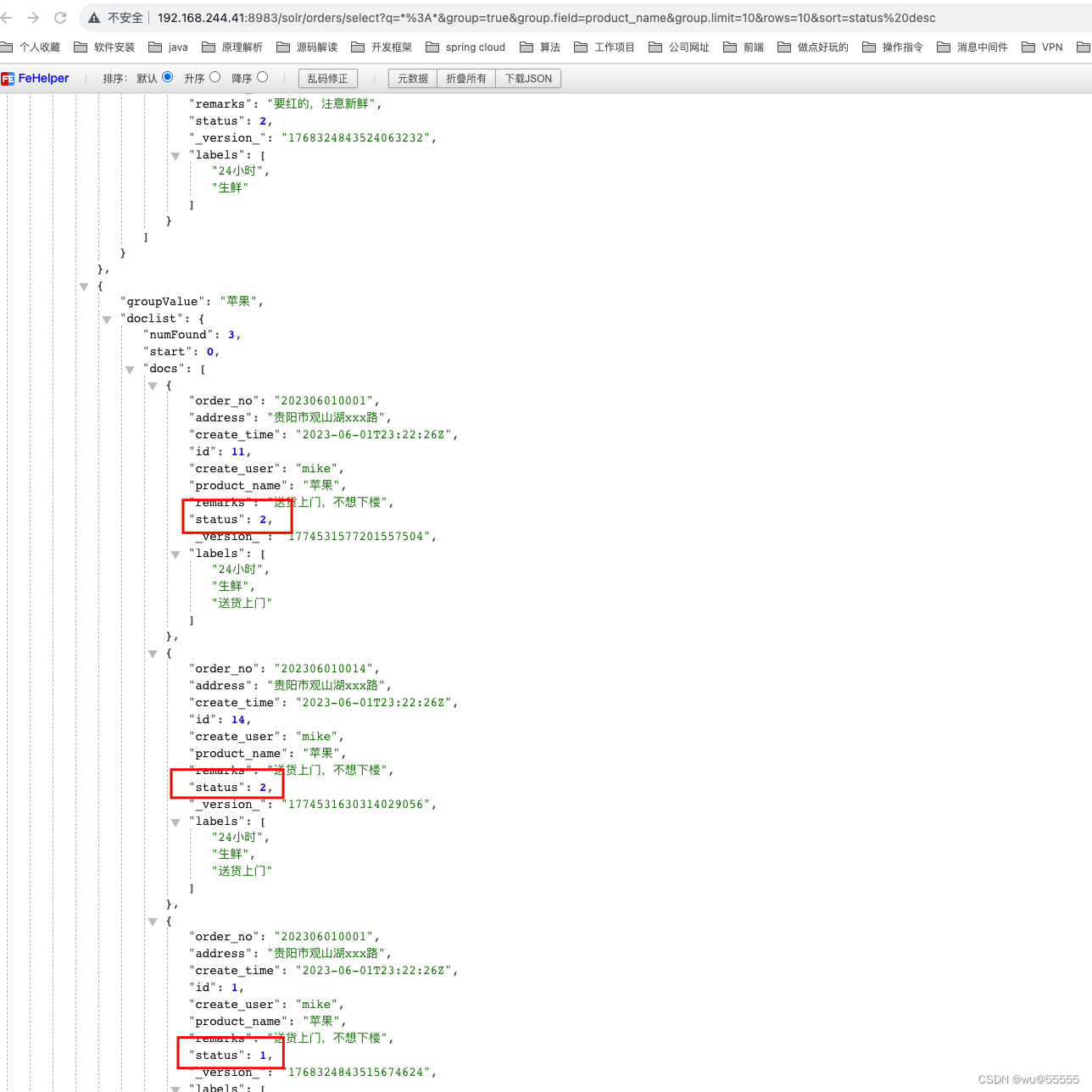
- sort: 根据指定字段进行组间排序,有该字段的桶也将排序在前。与group.sort的区别是:sort用于控制组间排序,group.sort控制组内排序。
q=*:*&group=true&group.field=product_name&group.limit=10&rows=10&sort=status desc
- group.cache.percent:分组搜索结果占用堆内存的百分比,当设置大于0时即开启搜索结果缓存,数值越大允许缓存占用的堆内存大小越大。根据官方的解释,该配置会提升布尔、通配符、模糊查询的效率,但却会降低普通查询效率
1.1.3 案例
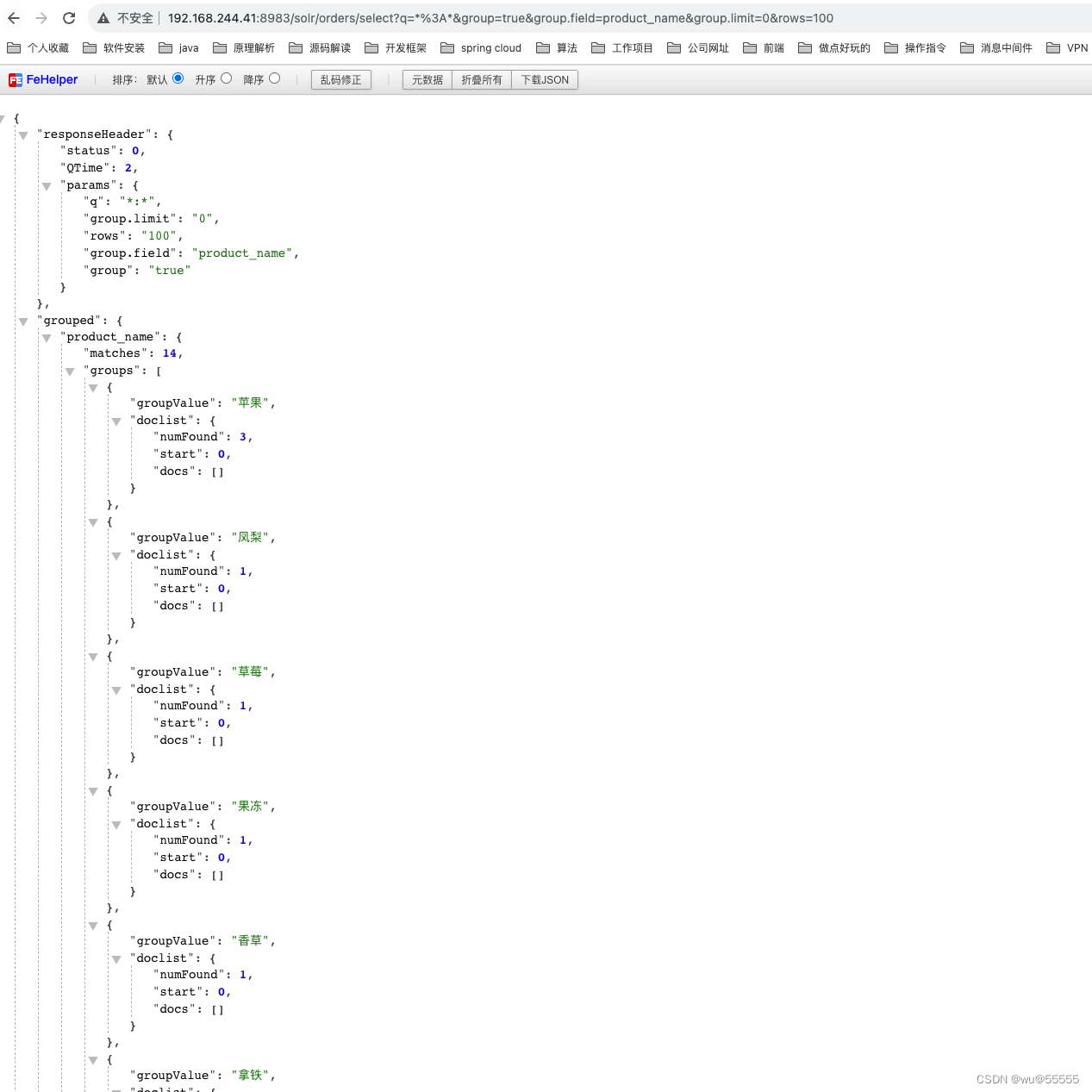
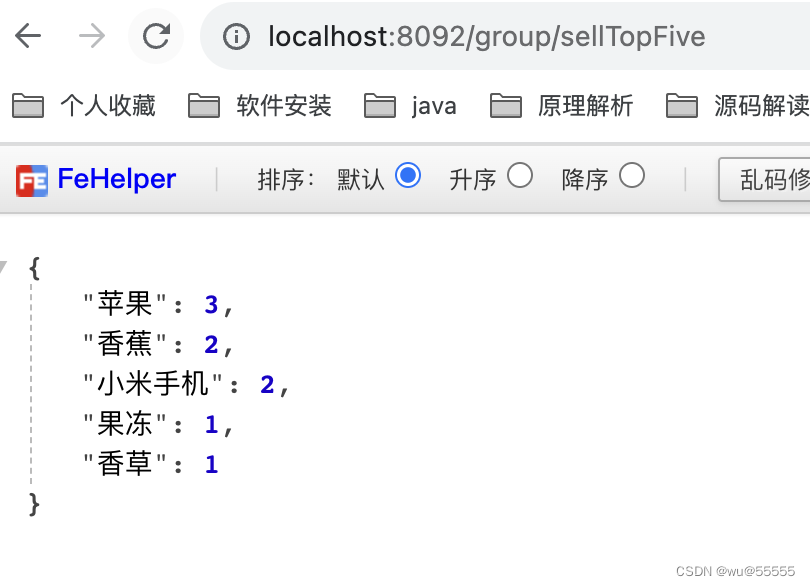
- 1、统计销量排行前5的商品
思路:在开始之前我们需要注意,单纯使用group实际上是无法完成此题的,因为group不支持按照各个桶数量进行排序,需要使用facet,我们将在下文讲解,但如果只使用group的话,排序需要借助java代码再来实现
DSL:
q=*:*&group=true&group.field=product_name&group.limit=0&rows=100
查询结果:
solrJ客户端代码:
@RestController
@RequestMapping("group")
@AllArgsConstructor
public class GroupSearchController {
private final HttpSolrClient solrClient;
@GetMapping("sellTopFive")
public Map<String, Long> sellTopFive() {
Map<String, Long> result = new HashMap<>();
// 设置查询条件
SolrQuery query = new SolrQuery().setQuery("*:*").setRows(100);
// 设置分组条件
query.set(GroupParams.GROUP, true)
.set(GroupParams.GROUP_FIELD, "product_name")
.set(GroupParams.GROUP_LIMIT, 0);
try {
QueryResponse response = solrClient.query("orders",query);
GroupResponse groupResponse = response.getGroupResponse();
List<GroupCommand> values = groupResponse.getValues();
GroupCommand group = values.get(0);
List<Group> productGroups = group.getValues();
for (Group productGroup : productGroups) {
result.put(productGroup.getGroupValue(), productGroup.getResult().getNumFound());
}
// 根据数量逆序排序,截取前5
return result.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.limit(5)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
} catch (SolrServerException | IOException e) {
e.printStackTrace();
return result;
}
}
}
spring-data-solr客户端代码:
@RestController
@RequestMapping("group")
@AllArgsConstructor
public class GroupSearchController {
private final SolrTemplate solrTemplate;
@GetMapping("sellTopFive2")
public Map<String, Long> sellTopFive2() {
Map<String, Long> result = new HashMap<>();
// 设置分组条件
Field field = new SimpleField("product_name");
SimpleQuery groupQuery = new SimpleQuery(new SimpleStringCriteria("*:*")).setRows(100);
GroupOptions groupOptions = new GroupOptions()
.addGroupByField(field)
.setLimit(0);
groupQuery.setGroupOptions(groupOptions);
try {
GroupPage<Orders> page = solrTemplate.queryForGroupPage("orders", groupQuery, Orders.class);
GroupResult<Orders> fieldGroup = page.getGroupResult(field);
List<GroupEntry<Orders>> content = fieldGroup.getGroupEntries().getContent();
for (GroupEntry<Orders> ordersGroupEntry : content) {
result.put(ordersGroupEntry.getGroupValue(), ordersGroupEntry.getResult().getTotalElements());
}
// 根据数量逆序排序,截取前5
return result.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.limit(5)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
}catch (Exception e){
e.printStackTrace();
return result;
}
}
}
执行结果:
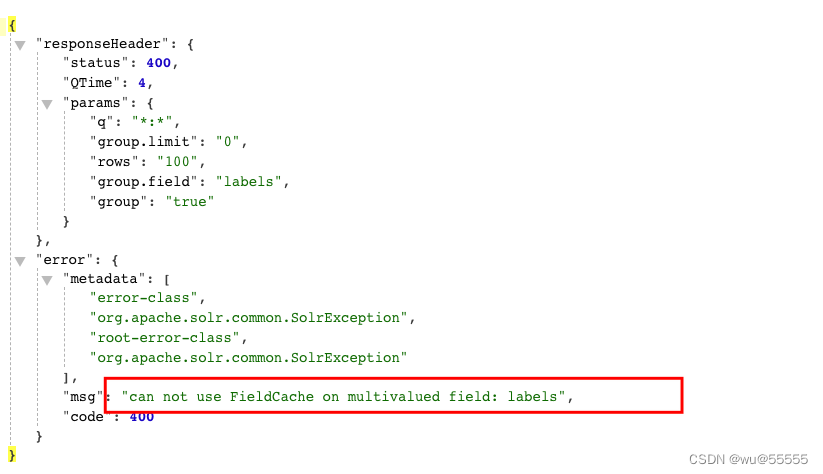
- 2、各个标签的订单数
思路:此题与上述的区别,就在于分组的字段labels是Nested类型,但group分组不支持Nested字段的分组,因此使用group是无法实现的,我们将在Facet中讲解用法
1.2 facet 分组查询
1.2.1 简介
facet与group有些相近,都是做分组查询的,但是facet允许用户再对结果集进行二次处理,也就是支持嵌套聚合,也可以对分组数量进行排序、过滤等,group会返回每个分组详细的数据列表docs,而facet并不会返回每个分组的docs,只是返回一个统计指标。facet与group可以结合使用。
官方文档:https://solr.apache.org/guide/8_2/faceting.html
facet分组查询支持4大类型:
facet.query: 自定义查询分组
facet.field:按字段分组
facet.range: 范围查询分组
facet.date:日期分组
1.2.2 参数
- facet: 设置为true则开启facet分组查询
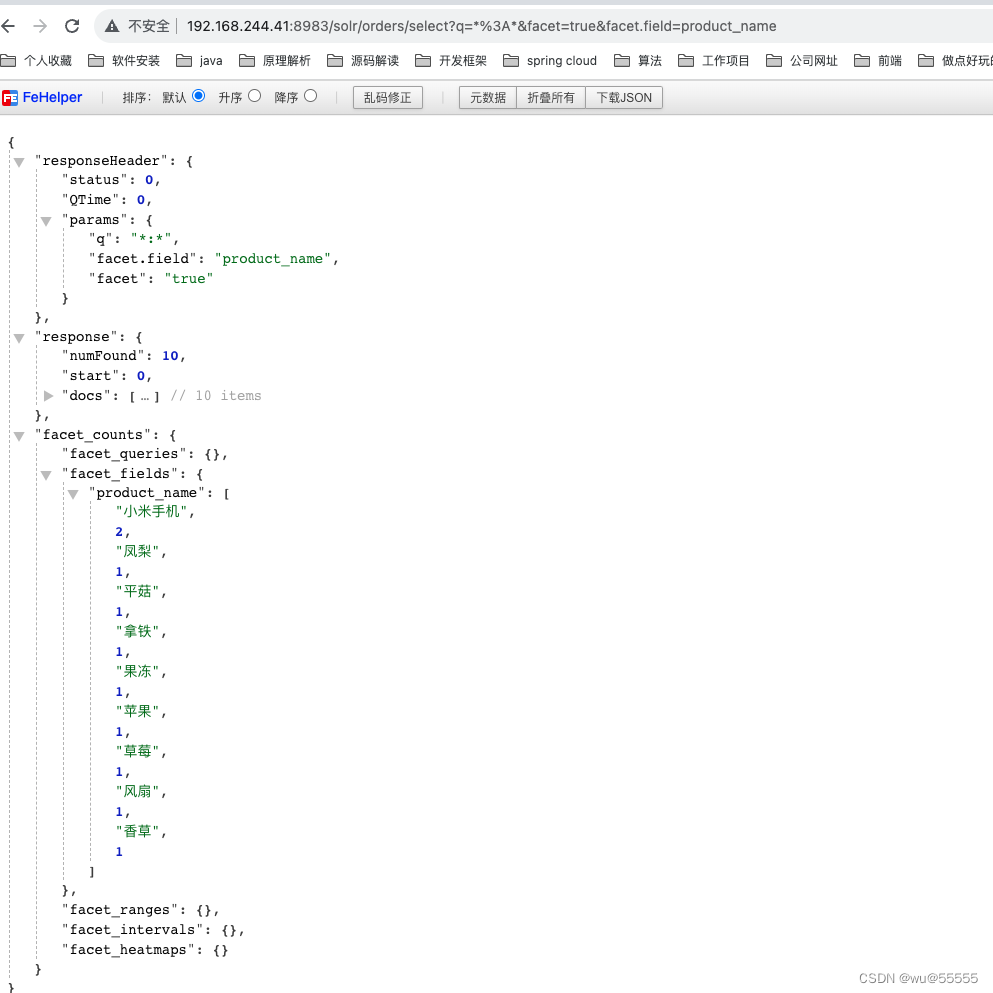
- facet.field:以什么字段作为分组统计字段,如下所示,可以看到与group明显的区别,是没有返回每个分组的docs了。
q=*:*&facet=true&facet.field=product_name
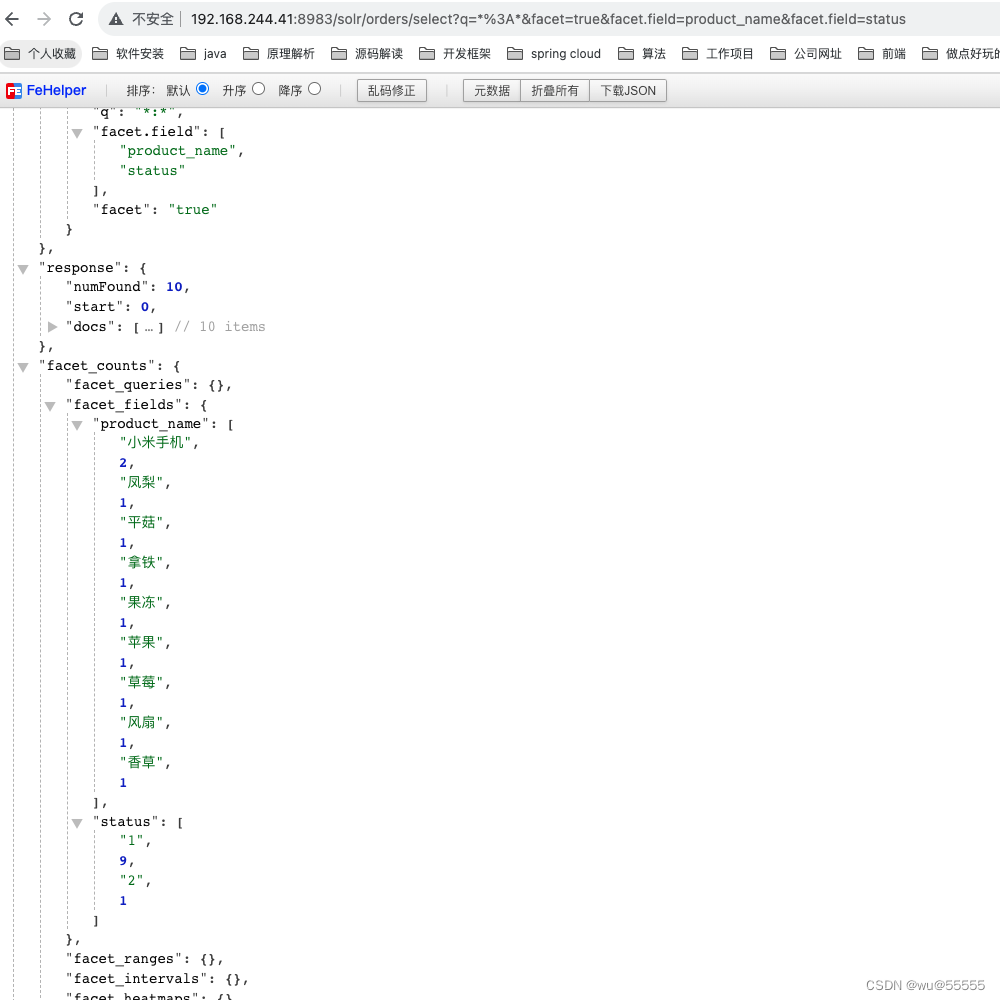
与group.field一样,也可以设置多个分组字段
q=*:*&facet=true&facet.field=product_name&facet.field=status
- facet.pivot:多字段嵌套分组,如上所示的分组是分割开单独分组的,某些场景下我们需要嵌套分组,基于前一个分组结果继续做分组,这就需要用到facet.pivot, 比如,统计每种状态下各个商品的个数
q=*:*&facet=true&facet.pivot=status,product_name
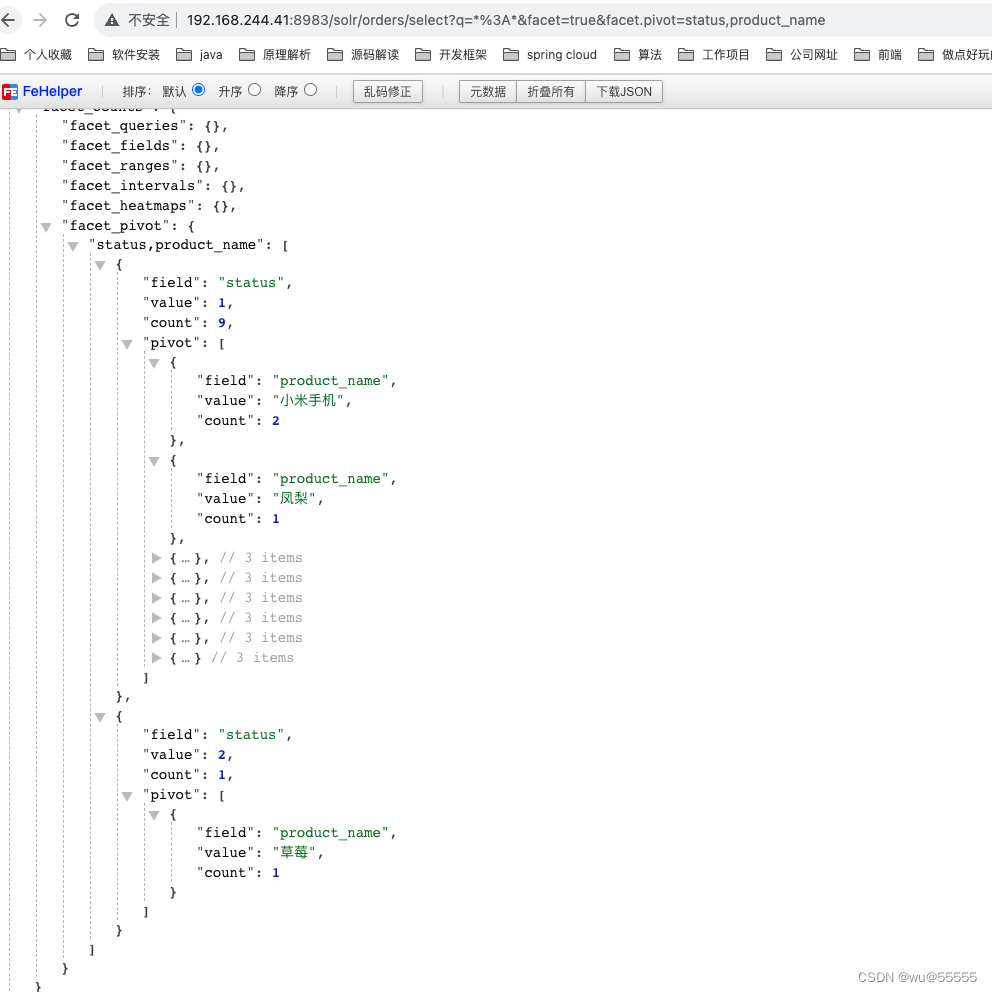
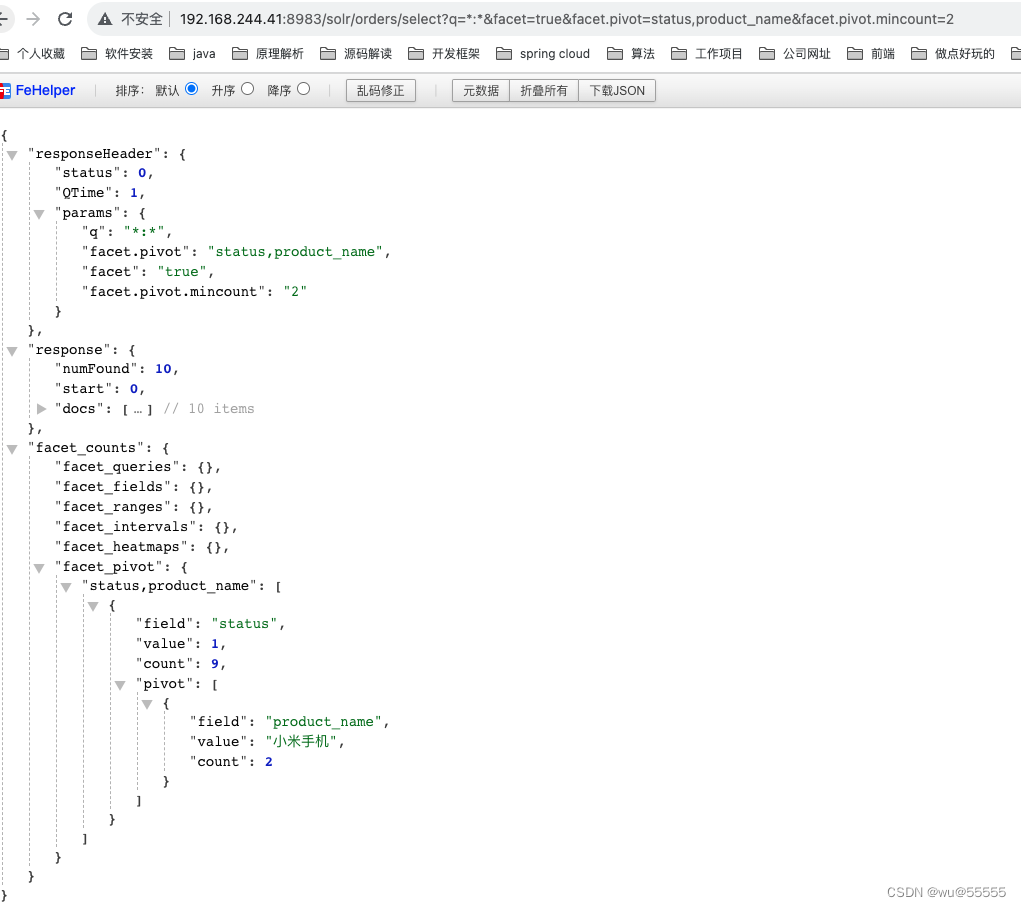
- facet.pivot.mincount,嵌套分组显示最小数量,有时我们希望显示的分组是具有一定数量的,数量比较小的就不要显示了,这就需要用到facet.pivot.mincount,默认值为1
q=*:*&facet=true&facet.pivot=status,product_name&facet.pivot.mincount=2
-
facet.mincount:分组最小数量,与facet.pivot.mincount不同的是,这个是控制facet.field产生的普通分组
-
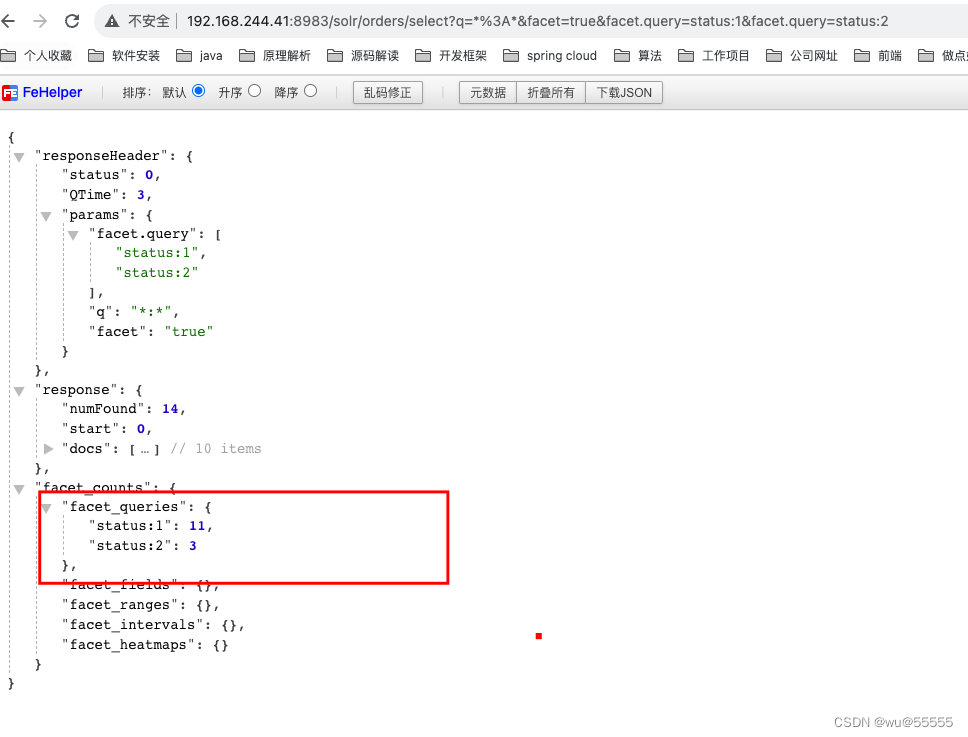
facet.query: 根据查询条件来进行分类,可以设置多个facet.query,来实现自定义的分组统计
q=*:*&facet=true&facet.query=status:1&facet.query=status:2
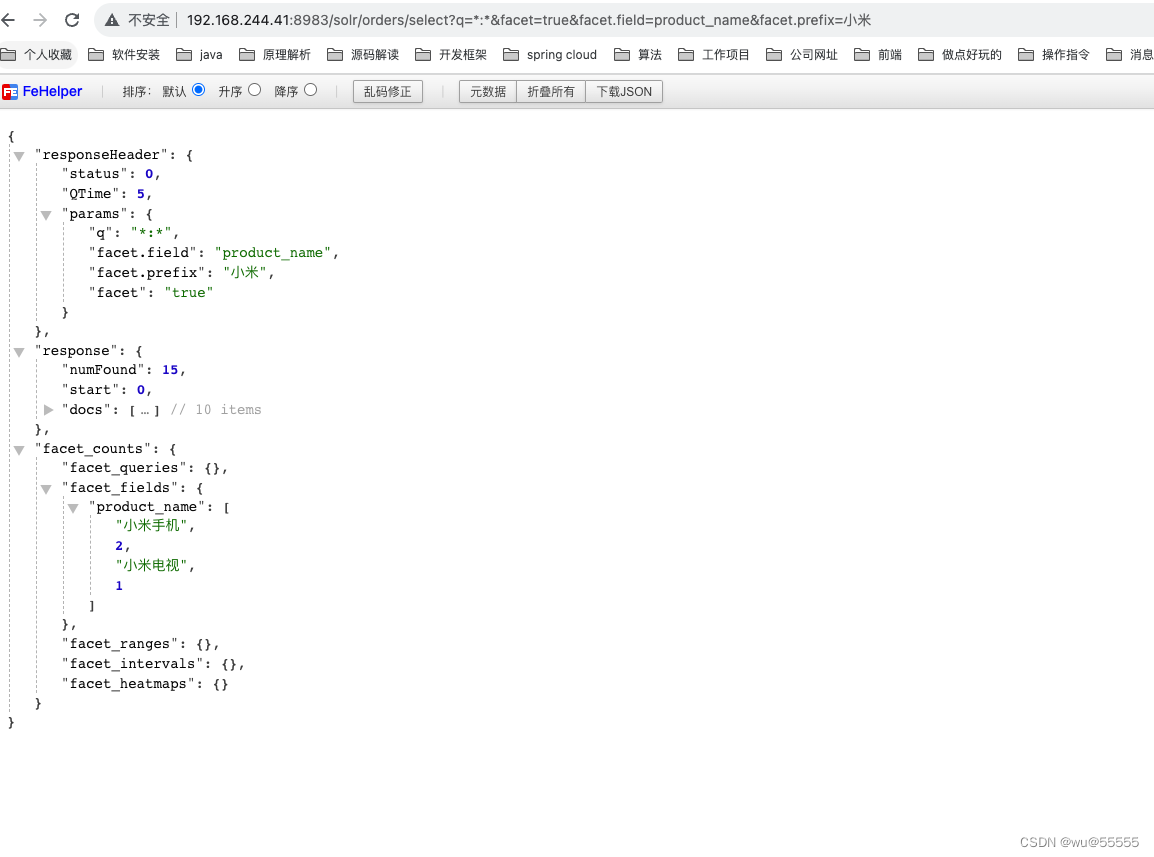
- facet.prefix:分组字段的值满足该前缀的才会被统计
q=*:*&facet=true&facet.field=product_name&facet.prefix=小米
- facet.contains:分组字段包含该值的才会被分组统计
q=*:*&facet=true&facet.field=product_name&facet.contains=小米
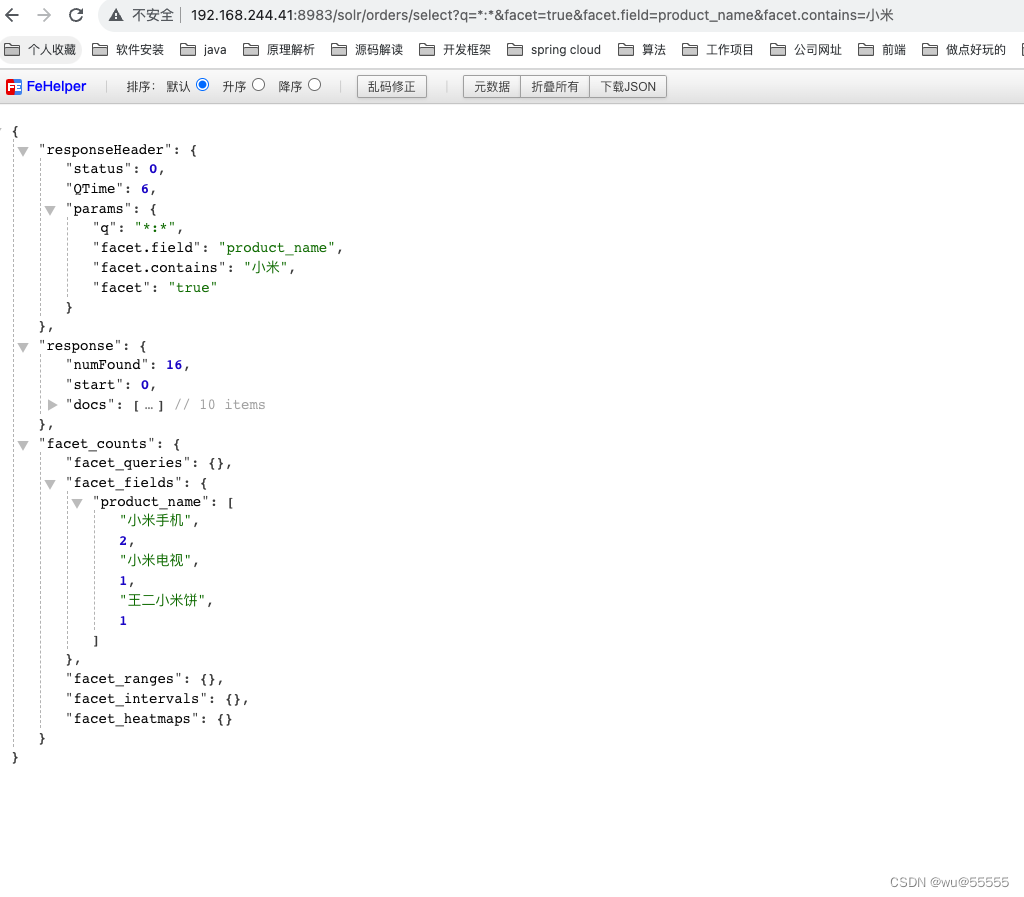
- facet.contains.ignoreCase: 与facet.contains的区别就是不区分大小写
- facet.matches:分组字段值满足该正则表达式的才会被分组统计(未实际使用,待验证)
q=*:*&facet=true&facet.field=product_name&facet.matches=米*
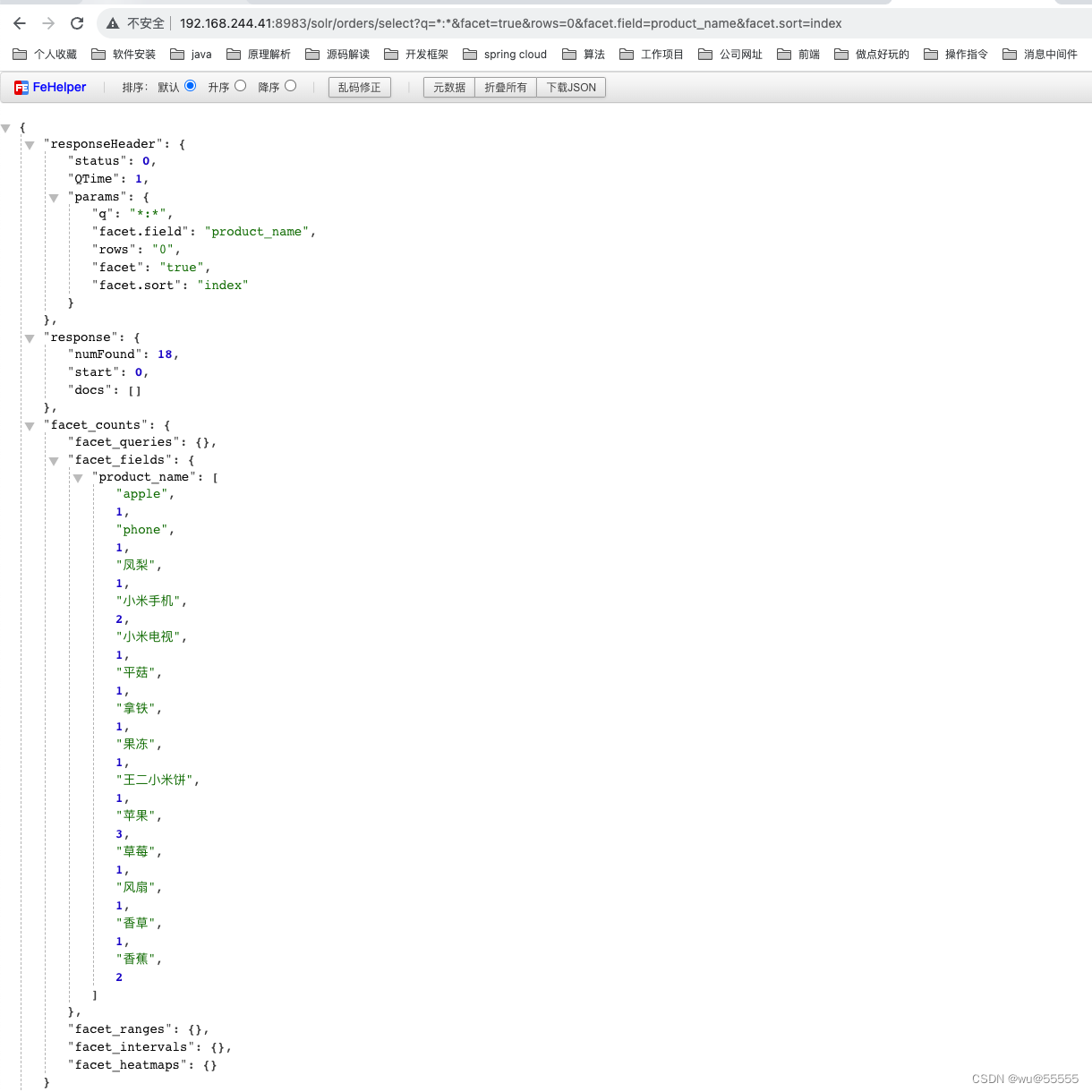
facet.sort:分组排序条件,允许设置两个值:count 按照每个桶的数量逆序排序、index:按照各分组桶名字符排序,默认为count
q=*:*&facet=true&rows=0&facet.field=product_name&facet.sort=index
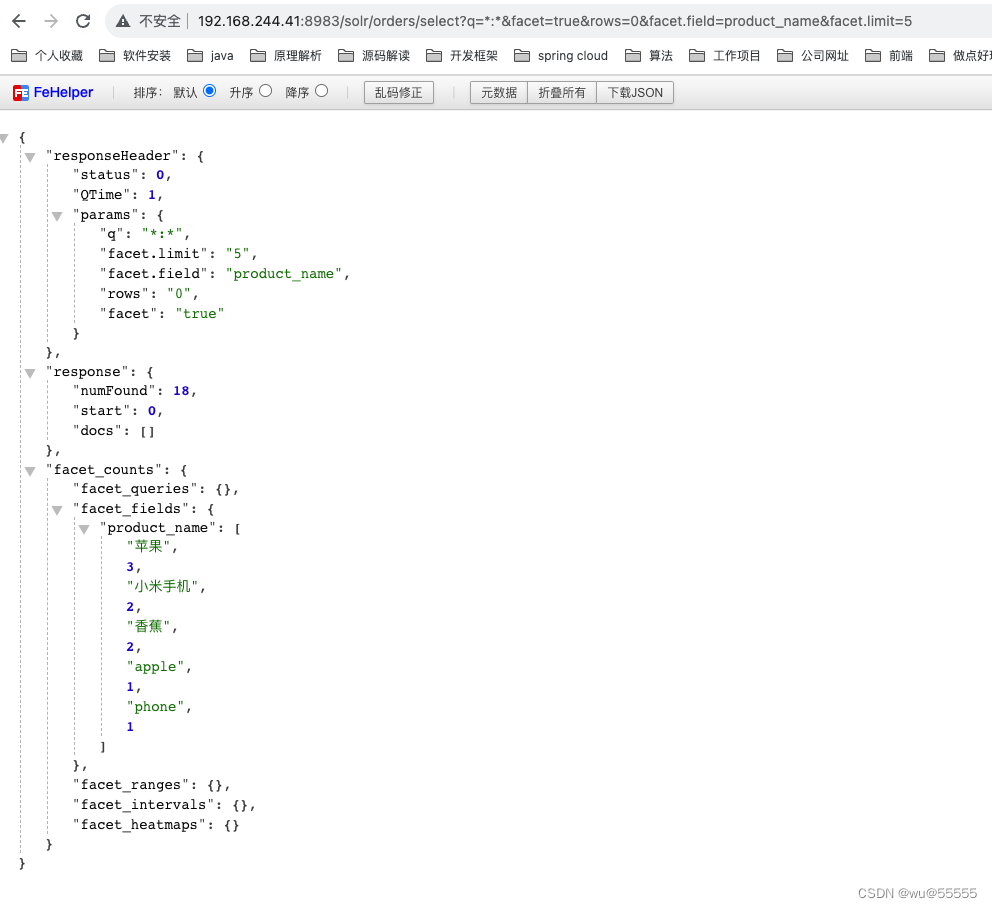
- facet.limit:返回的桶数量,默认100
q=*:*&facet=true&rows=0&facet.field=product_name&facet.limit=5
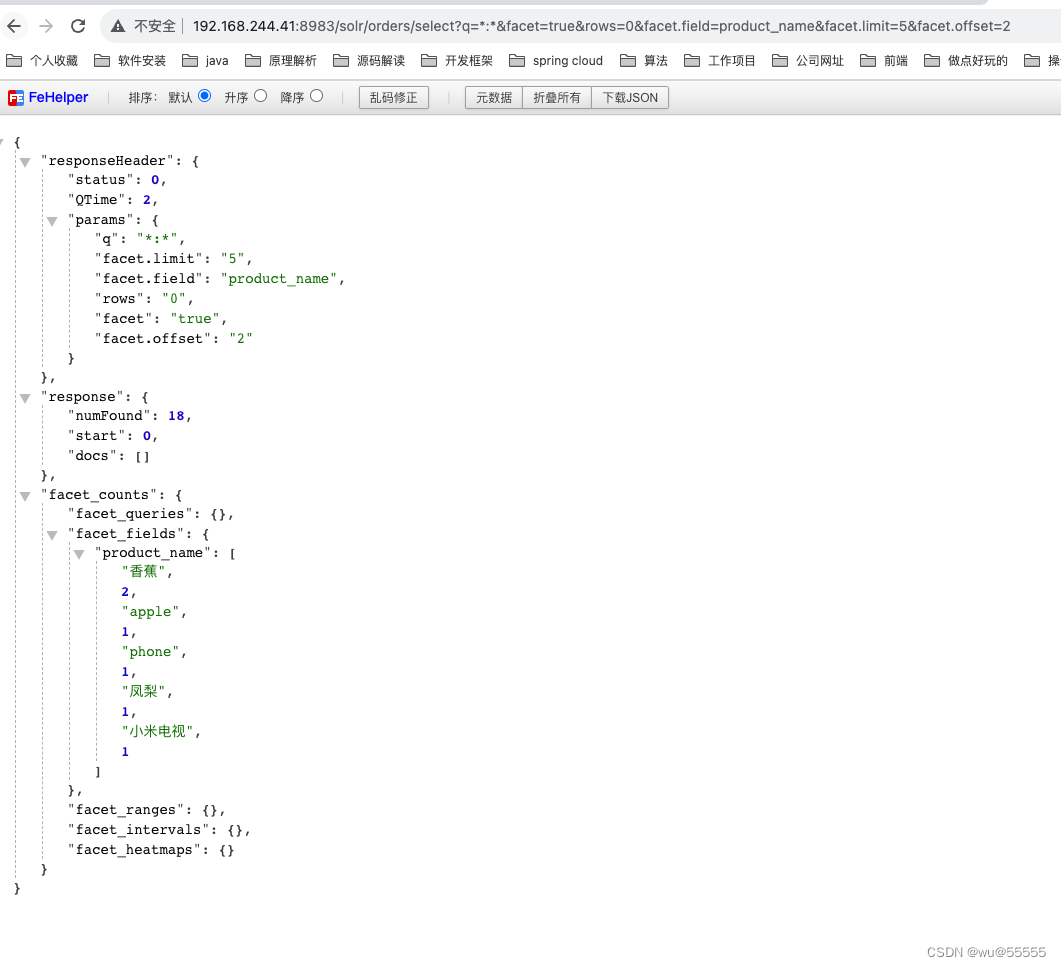
- facet.offset:从第几个桶开始显示
q=*:*&facet=true&rows=0&facet.field=product_name&facet.limit=5&facet.offset=2
- facet.missing:文档数据(每一行数据)中分组字段facet.field没有值的是否统计,默认为false
- facet.method:指定分组算法,支持三种分组算法:fc, enum, filterCache,默认为fc。详细解释可见官方文档
- facet.threads:分组查询创建的线程数,最大值
Integer.MAX_VALUE,最小值0,这时只会创建一个主线程
范围查询分组
- facet.range: 定义范围查询的字段
- facet.range.start:范围查询的最小值
- facet.range.end:范围查询的最大值
- facet.range.gap:范围查询的步长(每组间隔)
- facet.range.hardend:是否将
facet.range.end最为最后一组的上限,值为true/false,默认为false,false时将会把最后一组上限设置为大于facet.range.end的最小可能上限。比如facet.range.end=4,文档中大于4的还有5、6、7,则如果为false时会取5最为上限
q=*:*&facet=true&rows=0&facet.range=status&facet.range.start=1&facet.range.end=5&facet.range.gap=3&facet.range.hardend=true
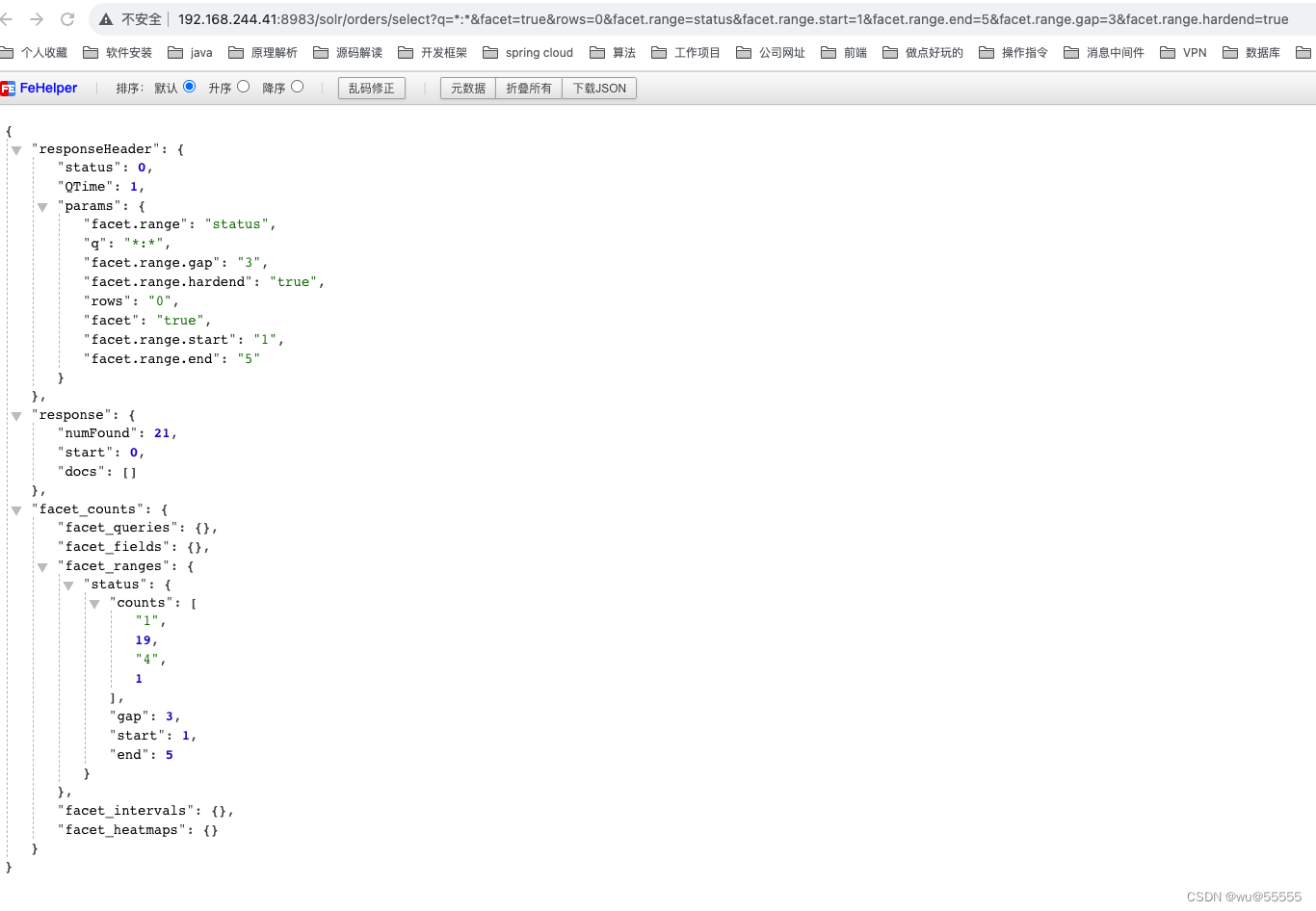
也可以实现按日期月份分组的效果,%2B表示URL中的+
q=*:*&facet=true&rows=0&facet.range=create_time&facet.range.start=NOW/MONTH-12MONTH&facet.range.end=NOW/MONTH&facet.range.gap=%2B1MONTH

- facet.range.include:指定每个区间中,是否包含上下限
lower:所有区间都包含其下限
upper:所有区间都包含其上限
edge:即使未指定相应的上限/下限选项,第一个和最后一个间隙范围也包括其边缘边界(第一个间隙范围较低,最后一个间隙范围较高)
outer:第一个或最后一个区间包含其边界
all:包含上述所有选项
- facet.range.other:其他区间统计规则,值为before、after、between、none、all,默认为none
before:对start之前的值做统计
after:对end之后的值做统计
between:对start至end之间所有值做统计,如果hardend为true的话,那么该值就是各个时间段统计值的和
none:表示该项禁用
all:表示before,after,all都会统计
如果指定了多个范围字段的话,通过facet.<field_id>的形式区分
facet.range=price&facet.range=age&facet.range=lastModified_dt
&f.price.facet.range.end=1000.0
&f.age.facet.range.start=99
&f.lastModified_dt.facet.range.end=NOW/DAY+30DAYS
指定间隔分组
- facet.interval:间隔统计字段
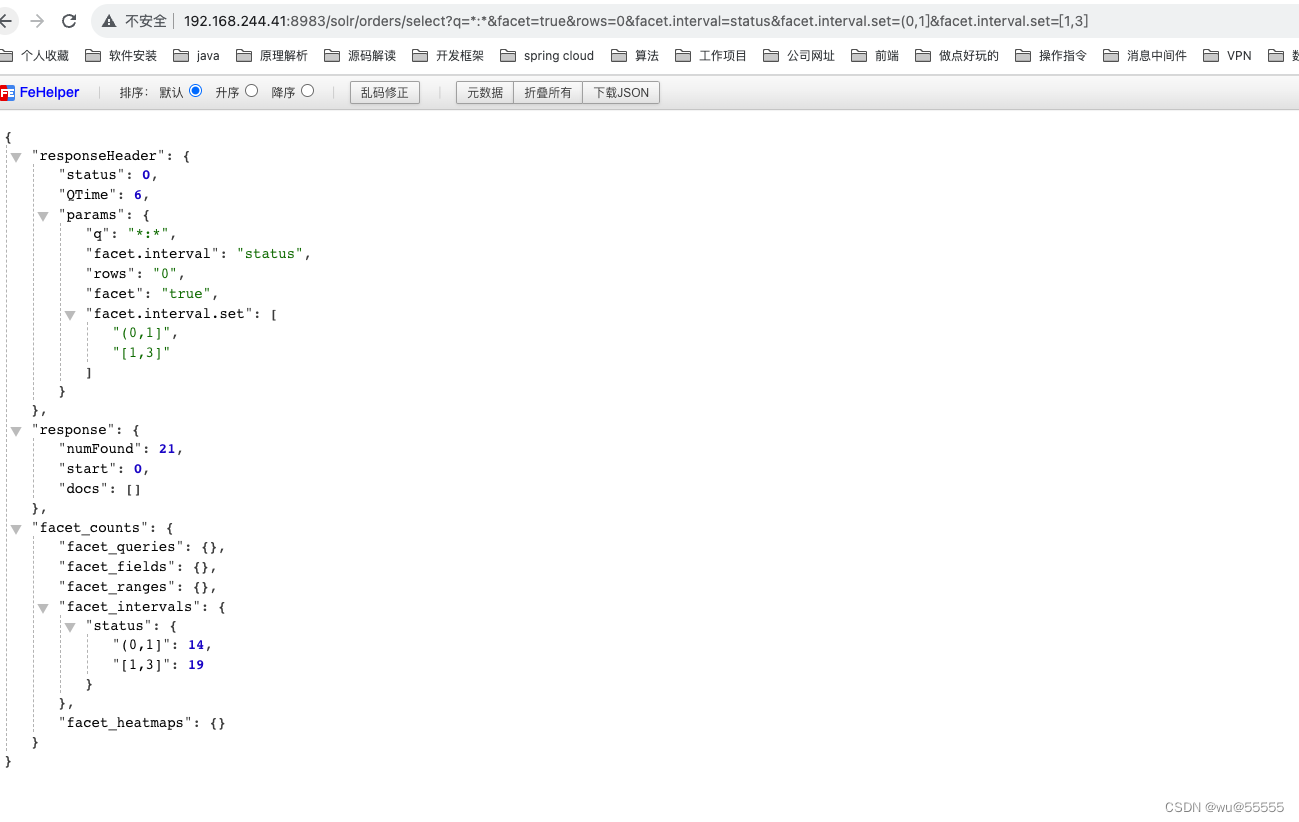
- facet.interval.set:间隔统计指定区间
q=*:*&facet=true&rows=0&facet.interval=status&facet.interval.set=(0,1]&facet.interval.set=[1,3]
时间类型分组
- facet.date:该参数表示需要进行按时间分组的字段名,与facet.field一样,该参数可以设置多个
- facet.date.start:起始时间
- facet.date.end:结束时间
- facet.date.gap:时间间隔.如果start为2023-01-01,end为2024-01-01,gap设置为
+1MONTH则表示间隔1个月,那么将会把这段时间划分为12个间隔段 - facet.date.hardend :与facet.range.hardend类似
facet.date.other 其他区间统计规则,与facet.range.other类似
1.2.3 案例
- 1、统计销量排行前5的商品
facet中默认就根据每组桶数逆序排序,无需特殊指定,如果需要根据桶名排序的,修改facet.sort=index即可
q=*:*&facet=true&rows=0&facet.field=product_name&facet.limit=5
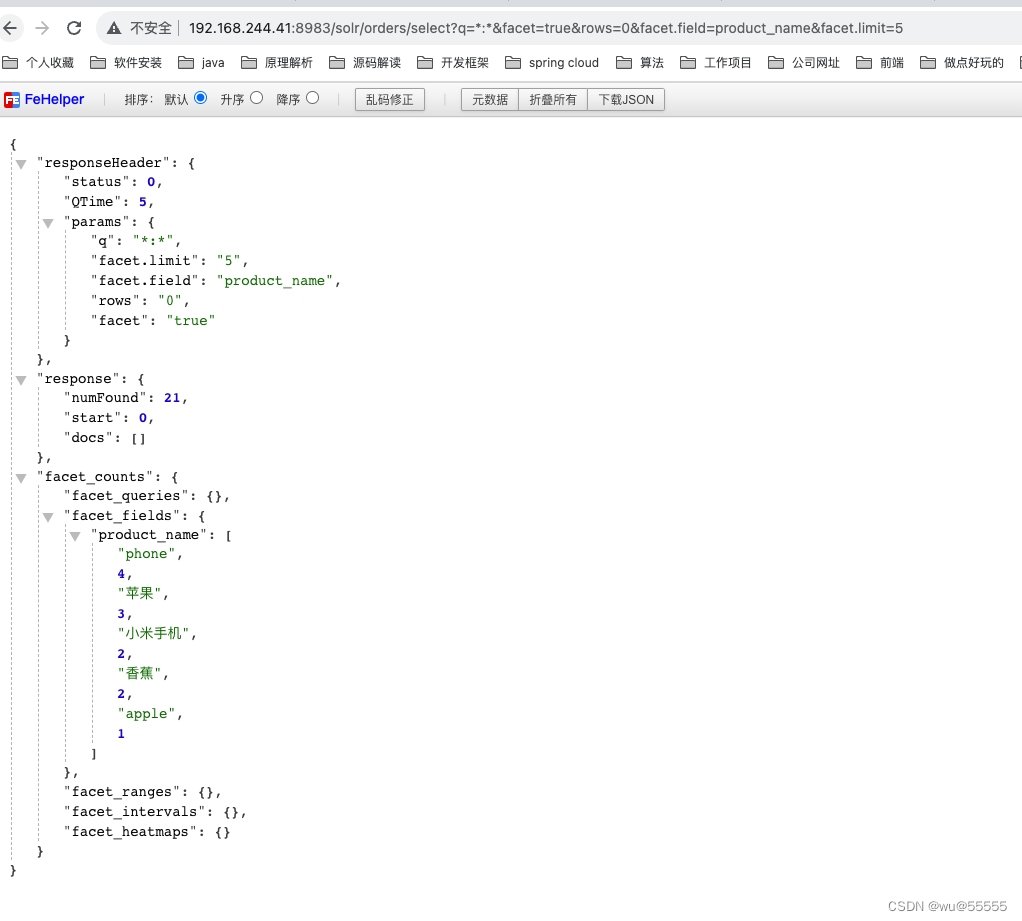
SolrJ实现代码:
@RestController
@RequestMapping("facet")
@AllArgsConstructor
public class FacetSearchController {
private final HttpSolrClient solrClient;
/**
* 统计销量排行前5的商品
* @return
*/
@GetMapping("sellTopFive")
public Map<String, Long> sellTopFive(){
Map<String, Long> result = new HashMap<>();
// 设置查询条件
SolrQuery query = new SolrQuery().setQuery("*:*").setRows(0);
// 设置分组条件
query.set(FacetParams.FACET, true)
.set(FacetParams.FACET_FIELD, "product_name")
.set(FacetParams.FACET_LIMIT, 5);
try {
QueryResponse response = solrClient.query("orders",query);
FacetField facetFields = response.getFacetField("product_name");
for (FacetField.Count value : facetFields.getValues()) {
result.put(value.getName(), value.getCount());
}
// 根据value排序, 若无需排序则可删除此段
return result.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
} catch (SolrServerException | IOException e) {
e.printStackTrace();
}
return result;
}
}
spring-data-solr代码
@GetMapping("sellTopFive2")
public Map<String, Long> sellTopFive2() {
Map<String, Long> result = new HashMap<>();
// 设置分组条件
Field field = new SimpleField("product_name");
SimpleFacetQuery query = new SimpleFacetQuery(new SimpleStringCriteria("*:*")).setRows(0);
FacetOptions facetOptions = new FacetOptions()
.addFacetOnField(field)
.setFacetLimit(5);
query.setFacetOptions(facetOptions);
try {
FacetPage<Orders> page = solrTemplate.queryForFacetPage("orders", query, Orders.class);
Page<FacetFieldEntry> pageResult = page.getFacetResultPage("product_name");
List<FacetFieldEntry> content = pageResult.getContent();
for (FacetFieldEntry facetFieldEntry : content) {
result.put(facetFieldEntry.getValue(), facetFieldEntry.getValueCount());
}
// 根据数量逆序排序
return result.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.limit(5)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
}catch (Exception e){
e.printStackTrace();
return result;
}
}

- 2、各个标签的订单数
facet.field支持Nested类型的字段,直接查询即可,这里标签分类没超过10个,就未设置rows了
q=*:*&facet=true&rows=0&facet.field=labels
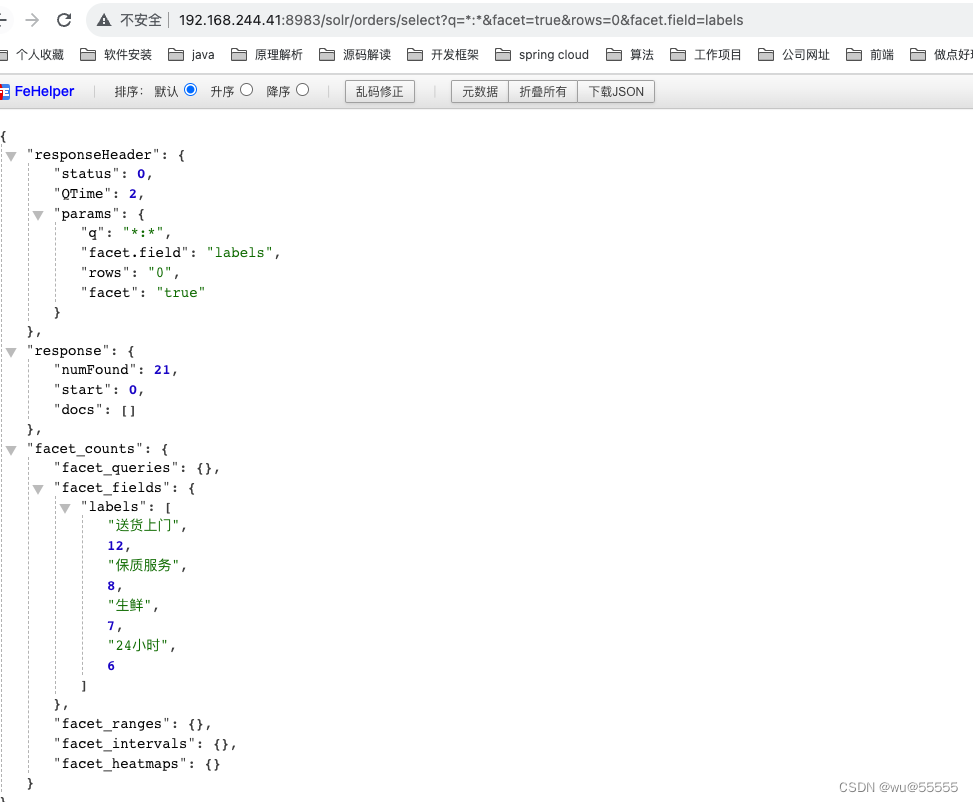
SolrJ代码:
@GetMapping("labelCount")
public Map<String, Long> labelCount(){
Map<String, Long> result = new HashMap<>();
// 设置查询条件
SolrQuery query = new SolrQuery().setQuery("*:*").setRows(0);
// 设置分组条件
query.set(FacetParams.FACET, true)
.set(FacetParams.FACET_FIELD, "labels")
.set(FacetParams.FACET_LIMIT, 100);
try {
QueryResponse response = solrClient.query("orders",query);
FacetField facetFields = response.getFacetField("labels");
for (FacetField.Count value : facetFields.getValues()) {
result.put(value.getName(), value.getCount());
}
} catch (SolrServerException | IOException e) {
e.printStackTrace();
}
return result;
}
- 3、统计近一年内每月的畅销商品TOP5
思路:我们要统计每月的商品中的TOP5,很明显要根据月份+商品进行分组,这属于嵌套分组,因此要使用到facet.pivot。我们有一个创建日期字段create_time。实现方式分为如下几种:
1、创建一个冗余一个月份字段month,用于此处的嵌套查询,这种要修改schema_manage且要重新加载索引,这里solr不支持类似es的动态字段还是不太方便,此方案如果索引数据量较大,重新加载索引影响线上使用,可以考虑直接新建一个核心,待同步完成,直接将查询核心切换到新的核心,然后删除旧核心
2、先按照年月份进行时间分组,然后客户端代码中循环对有值的年份月最为query条件,分别按商品进行分组,得到每个年月的商品分组详情,这种方式的弊端是网络IO较多,如果查询对耗时有较高要求可能不能满足
3、如果数据本身是按照天汇总的,及create_time格式是YYYY-MM-dd,没有到秒,或者一天的数据量并不大,那么可以先按照facet.pivot=create_time,product_name的形式按天把数据汇总出来,然后在java代码把数据再按月份进行二次计算得出,适用于本身按天数据量不大的场景,近一年的话按天分桶也就365个,相对还能接受
4、最友好的方式,就是能有将日期转换为月份的函数,类似month(create_time),然后facet.pivot=month(create_time),product_name来实现统计,但目前我还没有找到相关函数,solr本身好像也不支持这种操作,对于聚合上的支持还是和es有比较大的差距,如果后续大家有更好的方式可以留言告知,互相学习
这里因为我的数据量并不大,就直接采用方式3来实现了
q=*:*&facet=true&rows=0&facet.pivot=create_time,product_name&facet.sort=index
SolrJ客户端代码:
@GetMapping("productTopFiveMonthlyNearYear")
public Map<String, Map<String, Integer>> productTopFiveMonthlyNearYear(){
Map<String, Map<String, Integer>> result = new TreeMap<>();
// 设置查询条件
SolrQuery query = new SolrQuery().setQuery("*:*").setRows(0);
// 设置分组条件
query.set(FacetParams.FACET, true)
.set(FacetParams.FACET_PIVOT, "create_time,product_name")
.set(FacetParams.FACET_SORT, FacetParams.FACET_SORT_INDEX);
try {
QueryResponse response = solrClient.query("orders",query);
List<PivotField> pivotFields = response.getFacetPivot().get("create_time,product_name");
// 组装返回结果,按年月分组
for (PivotField field : pivotFields) {
SimpleDateFormat format = new SimpleDateFormat("yyyyMM");
String month = format.format(field.getValue());
if(!result.containsKey(month)){
Map<String, Integer> monthMap = new LinkedHashMap<>();
for (PivotField pivotField : field.getPivot()) {
monthMap.put(pivotField.getValue().toString(), pivotField.getCount());
}
result.put(month, monthMap);
}else{
Map<String, Integer> monthMap = result.get(month);
for (PivotField pivotField : field.getPivot()) {
String productName = pivotField.getValue().toString();
if(!monthMap.containsKey(productName)){
monthMap.put(productName, pivotField.getCount());
}else{
// 重复的商品 叠加销量
monthMap.put(productName,monthMap.get(productName) + pivotField.getCount());
}
}
}
}
// 每月商品截取前5
for (String month : result.keySet()) {
Map<String, Integer> sortMap = result.get(month).entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.limit(5)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
result.put(month, sortMap);
}
} catch (SolrServerException | IOException e) {
e.printStackTrace();
}
return result;
}
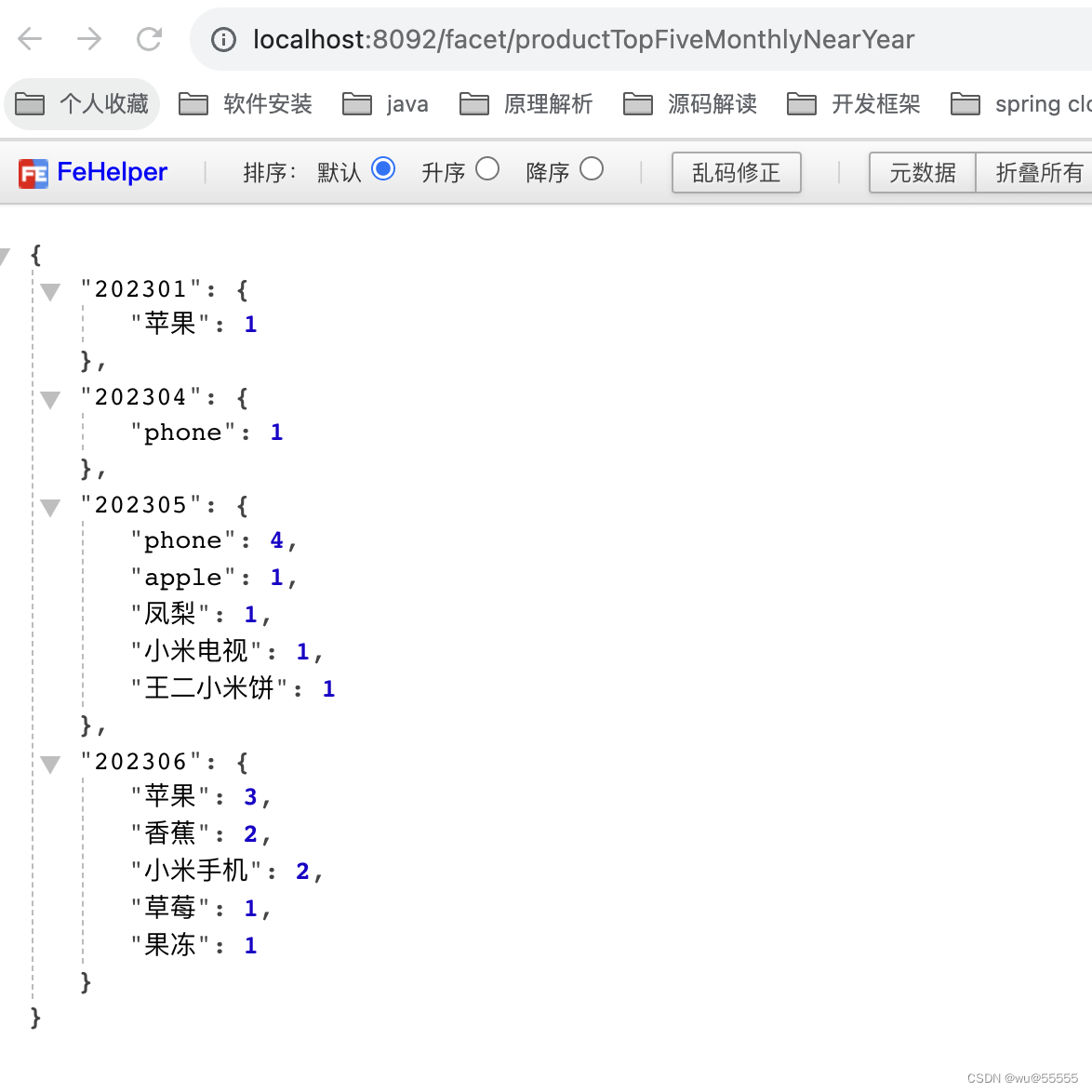
1.3 拓展:stats 查询
当需要统计某字段的平均、最大、最小等统计值时,可以结合stats来查询,具体用法可查看官网文档
官网文档:https://solr.apache.org/guide/8_2/the-stats-component.html

2. 总结
如上,我们对于solr实现分组聚合查询的讲解就到此结束了,可以看出group适合与简单的分组查询,而facet则更加适合场景复杂的分组查询。具体选型还要根据大家的业务场景而定