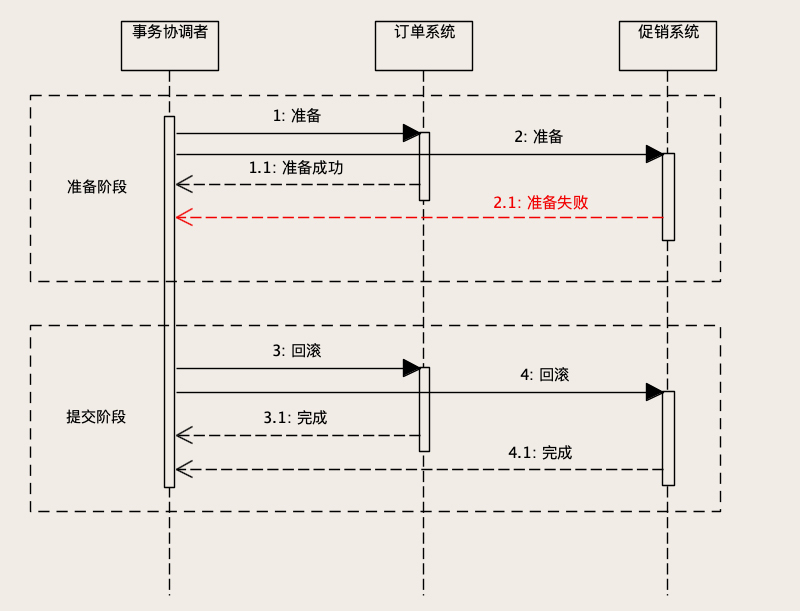
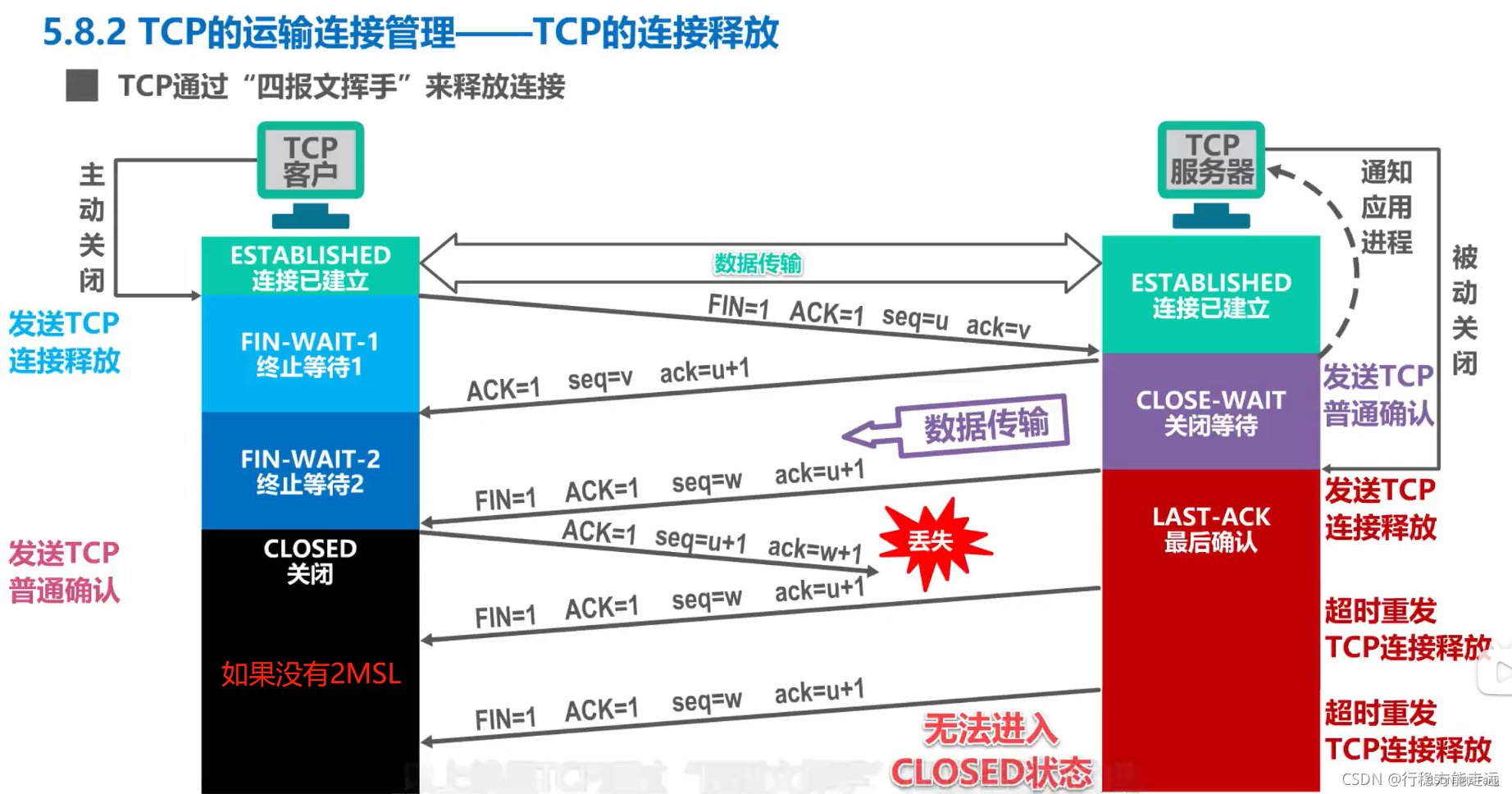
但是需要特殊的处理,再程序里会说明 ,这里选择操作+1
package com. lagou ;
import java. util. Arrays ;
public class test4 {
public static int two ( int [ ] arr, int start, int end) {
int pivot;
pivot = start;
int left = start + 1 ;
int right = end;
while ( true ) {
while ( left < right && arr[ right] > arr[ pivot] ) {
right-- ;
}
while ( left < right && arr[ left] < arr[ pivot] ) {
left++ ;
}
if ( left < right) {
int temp = arr[ left] ;
arr[ left] = arr[ right] ;
arr[ right] = temp;
right-- ;
left++ ;
}
if ( left >= right) {
if ( arr[ right] > arr[ pivot] ) {
right-- ;
}
int temp = arr[ right] ;
arr[ right] = arr[ pivot] ;
arr[ pivot] = temp;
break ;
}
}
return right;
}
public static int one ( int [ ] arr, int start, int end) {
int pivot;
pivot = start;
int mark = start;
for ( int i = start + 1 ; i <= end; i++ ) {
if ( arr[ pivot] > arr[ i] ) {
mark++ ;
if ( i != mark) {
int temp = arr[ mark] ;
arr[ mark] = arr[ i] ;
arr[ i] = temp;
}
}
}
int temp = arr[ mark] ;
arr[ mark] = arr[ pivot] ;
arr[ pivot] = temp;
return mark;
}
public static void quickSort ( int [ ] arr, int start, int end) {
if ( start >= end|| arr== null ) {
return ;
}
int mark = one ( arr, start, end) ;
quickSort ( arr, start, mark - 1 ) ;
quickSort ( arr, mark + 1 , end) ;
}
public static void quickSort1 ( int [ ] arr, int start, int end) {
if ( start >= end|| arr== null ) {
return ;
}
int pivot = two ( arr, start, end) ;
quickSort1 ( arr, start, pivot - 1 ) ;
quickSort1 ( arr, pivot + 1 , end) ;
}
public static void main ( String [ ] args) {
int [ ] arr = new int [ ] { 4 , 7 , 3 , 5 , 6 , 2 , 8 , 1 } ;
quickSort ( arr, 0 , arr. length - 1 ) ;
System . out. println ( Arrays . toString ( arr) ) ;
arr = new int [ ] { 4 , 2 , 3 , 5 , 6 , 7 , 8 , 1 } ;
quickSort1 ( arr, 0 , arr. length - 1 ) ;
System . out. println ( Arrays . toString ( arr) ) ;
}
}
package com. lagou ;
import java. util. * ;
public class test5 {
public static void max ( int [ ] array, int start, int last) {
int chi = 2 * start + 1 ;
while ( chi <= last) {
if ( chi + 1 <= last && array[ chi] < array[ chi + 1 ] ) {
chi++ ;
}
if ( array[ start] > array[ chi] ) {
break ;
}
int temp = array[ start] ;
array[ start] = array[ chi] ;
array[ chi] = temp;
start = chi;
chi = 2 * chi + 1 ;
}
}
public static void sort ( int [ ] array) {
for ( int i = array. length / 2 - 1 ; i >= 0 ; i-- ) {
max ( array, i, array. length - 1 ) ;
}
for ( int i = 0 ; i < array. length - 1 ; i++ ) {
int temp = array[ array. length - 1 - i] ;
array[ array. length - 1 - i] = array[ 0 ] ;
array[ 0 ] = temp;
max ( array, 0 , array. length - 1 - 1 - i) ;
}
}
public static void max1 ( int [ ] array, int start, int last) {
int temp = array[ start] ;
int chi = 2 * start + 1 ;
while ( chi <= last) {
if ( chi + 1 <= last && array[ chi] < array[ chi + 1 ] ) {
chi++ ;
}
if ( temp > array[ chi] ) {
break ;
}
array[ start] = array[ chi] ;
start = chi;
chi = 2 * chi + 1 ;
}
array[ start] = temp;
}
public static void sort2 ( int [ ] array) {
for ( int i = array. length / 2 - 1 ; i >= 0 ; i-- ) {
max ( array, i, array. length - 1 ) ;
}
for ( int i = array. length - 1 ; i > 0 ; i-- ) {
int temp = array[ i] ;
array[ i] = array[ 0 ] ;
array[ 0 ] = temp;
max ( array, 0 , i - 1 ) ;
}
}
public class Node {
int key;
Node left;
Node right;
public Node ( int key) {
this . key = key;
}
}
Node root;
public void head ( int [ ] array) {
if ( array != null ) {
List < Node > = new ArrayList < > ( ) ;
for ( int i = 0 ; i < array. length; i++ ) {
list. add ( new Node ( 0 ) ) ;
}
list. get ( 0 ) . key = array[ 0 ] ;
root = list. get ( 0 ) ;
for ( int i = 0 ; i < list. size ( ) ; i++ ) {
int left = 2 * i + 1 ;
int right = 2 * i + 2 ;
if ( left < list. size ( ) ) {
list. get ( i) . left = list. get ( left) ;
list. get ( left) . key = array[ left] ;
}
if ( right < list. size ( ) ) {
list. get ( i) . right = list. get ( right) ;
list. get ( right) . key = array[ right] ;
}
}
int [ ] result = new int [ list. size ( ) ] ;
int i = 0 ;
Queue < Node > = new LinkedList ( ) ;
queue. offer ( root) ;
while ( ! queue. isEmpty ( ) ) {
Node poll = queue. poll ( ) ;
result[ i] = poll. key;
i++ ;
if ( poll. left != null ) {
queue. offer ( poll. left) ;
}
if ( poll. right != null ) {
queue. offer ( poll. right) ;
}
}
String b = "" ;
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < result. length; ii++ ) {
if ( ii == result. length - 1 ) {
b = b + result[ ii] + "]" ;
} else {
b = b + result[ ii] + "," ;
}
}
System . out. println ( b) ;
} else {
System . out. println ( "没有数组信息" ) ;
}
}
public static void main ( String [ ] args) {
int [ ] arr = { 7 , 6 , 4 , 3 , 5 , 2 , 10 , 9 , 8 } ;
System . out. println ( "排序前:" + Arrays . toString ( arr) ) ;
sort ( arr) ;
System . out. println ( "排序后:" + Arrays . toString ( arr) ) ;
arr = new int [ ] { 7 , 6 , 4 , 3 , 5 , 2 , 10 , 9 , 8 } ;
System . out. println ( "排序前:" + Arrays . toString ( arr) ) ;
sort2 ( arr) ;
System . out. println ( "排序后:" + Arrays . toString ( arr) ) ;
test5 t = new test5 ( ) ;
t. head ( arr) ;
System . out. println ( t. root) ;
}
}
package com. lagou ;
public class test6 {
public static void Sort ( int [ ] array, int offset) {
int [ ] a = new int [ array. length] ;
for ( int i = 0 ; i < array. length; i++ ) {
a[ array[ i] - offset] ++ ;
}
System . out. print ( "[" ) ;
int ii = 0 ;
for ( int i = 0 ; i < a. length; i++ ) {
while ( a[ i] != 0 ) {
if ( ii == 0 ) {
System . out. print ( i + offset) ;
ii++ ;
a[ i] -- ;
} else {
System . out. print ( "," + ( i + offset) ) ;
a[ i] -- ;
}
}
}
System . out. println ( "]" ) ;
}
public static void main ( String [ ] args) {
int [ ] scores = { 95 , 94 , 91 , 98 , 99 , 90 , 99 , 93 , 91 , 92 } ;
Sort ( scores, 90 ) ;
}
}
package com. lagou ;
import java. util. * ;
public class test7 {
public static void Sort ( double [ ] array) {
double max = array[ 0 ] ;
double min = array[ 0 ] ;
for ( int i = 1 ; i < array. length; i++ ) {
if ( array[ i] > max) {
max = array[ i] ;
}
if ( array[ i] < min) {
min = array[ i] ;
}
}
double d = max - min;
List < LinkedList < Double > > = new ArrayList < > ( array. length) ;
for ( int i = 0 ; i < array. length; i++ ) {
l. add ( new LinkedList ( ) ) ;
}
for ( int i = 0 ; i < array. length; i++ ) {
int num = ( int ) ( ( array[ i] - min) * ( array. length - 1 ) / d) ;
l. get ( num) . add ( array[ i] ) ;
}
for ( int i = 0 ; i < l. size ( ) ; i++ ) {
Collections . sort ( l. get ( i) ) ;
}
double [ ] sortedArray = new double [ array. length] ;
int index = 0 ;
for ( LinkedList < Double > : l) {
for ( double element : list) {
sortedArray[ index] = element;
index++ ;
}
}
System . out. print ( "[" ) ;
for ( int i = 0 ; i < sortedArray. length; i++ ) {
if ( i == sortedArray. length - 1 ) {
System . out. println ( sortedArray[ i] + "]" ) ;
} else {
System . out. print ( sortedArray[ i] + "," ) ;
}
}
}
public static void main ( String [ ] args) {
double [ ] array = { 4.12 , 6.421 , 0.0023 , 3.0 , 2.123 , 8.122 , 4.12 , 10.09 } ;
Sort ( array) ;
System . out. println ( "最大值是:" + array[ array. length - 1 ] ) ;
array = new double [ ] { 4.12 , 6.421 , 0.0023 , 3.0 , 2.123 , 8.122 , 4.12 , 10.09 } ;
List < LinkedList < Double > > = max ( array) ;
Array ( max, array) ;
}
public static List < LinkedList < Double > > max ( double [ ] array) {
double max = array[ 0 ] ;
double min = array[ 0 ] ;
for ( int i = 1 ; i < array. length; i++ ) {
if ( array[ i] > max) {
max = array[ i] ;
}
if ( array[ i] < min) {
min = array[ i] ;
}
}
double d = max - min;
List < LinkedList < Double > > = new ArrayList < > ( array. length) ;
for ( int i = 0 ; i < array. length; i++ ) {
l. add ( new LinkedList ( ) ) ;
}
for ( int i = 0 ; i < array. length; i++ ) {
int num = ( int ) ( ( array[ i] - min) * ( array. length - 1 ) / d) ;
l. get ( num) . add ( array[ i] ) ;
}
System . out. println ( "最大值是:" + l. get ( l. size ( ) - 1 ) . get ( 0 ) ) ;
return l;
}
public static void Array ( List < LinkedList < Double > > , double [ ] array) {
for ( int i = 0 ; i < l. size ( ) ; i++ ) {
Collections . sort ( l. get ( i) ) ;
}
double [ ] sortedArray = new double [ array. length] ;
int index = 0 ;
for ( LinkedList < Double > : l) {
for ( double element : list) {
sortedArray[ index] = element;
index++ ;
}
}
System . out. print ( "[" ) ;
for ( int i = 0 ; i < sortedArray. length; i++ ) {
if ( i == sortedArray. length - 1 ) {
System . out. println ( sortedArray[ i] + "]" ) ;
} else {
System . out. print ( sortedArray[ i] + "," ) ;
}
}
}
}
package com. lagou ;
public class test11 {
public static void main ( String [ ] args) {
System . out. println ( "hello" . indexOf ( "el" ) ) ;
}
}
package com. lagou ;
public class test22 {
public static void main ( String [ ] args) {
String i = "hello" ;
String k = "ll" ;
for ( int j = 0 ; j < i. length ( ) - k. length ( ) + 1 ; j++ ) {
boolean equals = i. substring ( j, k. length ( ) + j) . equals ( k) ;
if ( equals == true ) {
System . out. println ( "下标在" + j + "位置找到" ) ;
return ;
}
}
System . out. println ( "没有找到" ) ;
}
}
52+65,ZZ=90 * 52+90,而aa=97 * 26+97,zz=122 26+97,我们直接的比较,ZZ=4770,aa=2619,AA=3445,zz=3269,很明显,26的次方的最大值,都比52次方的最小值要小,所以他们不会相同,而52若再小点,就不一定了,即得出结论,52的跨度足够大,所以自定义的52可以使用
package com. lagou ;
public class test33 {
public static int strToHash ( String s) {
int hash = 0 ;
for ( int i = 0 ; i < s. length ( ) ; i++ ) {
hash *= 26 ;
hash += ( s. charAt ( i) - 97 ) ;
}
return hash;
}
public static void is ( String s, String b) {
int i = strToHash ( b) ;
for ( int j = 0 ; j < s. length ( ) - b. length ( ) + 1 ; j++ ) {
if ( strToHash ( s. substring ( j, b. length ( ) + j) ) == i) {
System . out. println ( "匹配成功,下标是:" + j) ;
return ;
}
}
System . out. println ( "没有找到" ) ;
}
public static void main ( String [ ] args) {
is ( "avfg" , "fg" ) ;
}
}
这里是没有考虑哈希算法的计算的 时间复杂度的,所以要注意
以后以哈希算法是O(1)这个为主
package com. lagou ;
public class test44 {
public static void generateBC ( String b, int [ ] dc) {
for ( int i = 0 ; i < dc. length; i++ ) {
dc[ i] = - 1 ;
}
for ( int i = 0 ; i < b. length ( ) ; i++ ) {
dc[ b. charAt ( i) ] = i;
}
}
public static void bad ( String a, String b) {
int [ ] array = new int [ 256 ] ;
generateBC ( b, array) ;
for ( int i = 0 ; i < a. length ( ) - b. length ( ) + 1 ; ) {
int j = 0 ;
for ( j = b. length ( ) - 1 ; j >= 0 ; j-- ) {
if ( a. charAt ( j + i) != b. charAt ( j) ) {
break ;
}
}
if ( j < 0 ) {
System . out. println ( "匹配成功,下标是:" + i) ;
return ;
}
int ii = 0 ;
if ( j != b. length ( ) - 1 ) {
char c = a. charAt ( j + i) ;
for ( ii = j - 1 ; ii >= 0 ; ii-- ) {
if ( b. charAt ( ii) == c) {
break ;
}
}
}
if ( j == b. length ( ) - 1 ) {
i += j - array[ a. charAt ( j + i) ] ;
} else {
i += j - ii;
}
}
System . out. println ( "没有找到" ) ;
}
public static void generateBC11 ( int [ ] dc) {
for ( int i = 0 ; i < dc. length; i++ ) {
dc[ i] = - 1 ;
}
}
public static void generateBC12 ( String b, int [ ] dc, char v) {
for ( int i = b. length ( ) - 1 ; i >= 0 ; i-- ) {
if ( b. charAt ( i) == v) {
dc[ v] = i;
break ;
}
}
}
public static void badd ( String a, String b) {
int [ ] array = new int [ 256 ] ;
generateBC11 ( array) ;
for ( int i = 0 ; i < a. length ( ) - b. length ( ) + 1 ; ) {
int j = 0 ;
for ( j = b. length ( ) - 1 ; j >= 0 ; j-- ) {
if ( a. charAt ( j + i) != b. charAt ( j) ) {
break ;
}
}
if ( j < 0 ) {
System . out. println ( "匹配成功,下标是:" + i) ;
return ;
}
String c = b. substring ( 0 , j) ;
generateBC12 ( c, array, a. charAt ( j + i) ) ;
i += j - array[ a. charAt ( j + i) ] ;
if ( i + j <= a. length ( ) - 1 ) {
array[ a. charAt ( j + i) ] = - 1 ;
}
}
System . out. println ( "没有找到" ) ;
}
public static void bad1 ( String a, String b) {
int [ ] array = new int [ 256 ] ;
generateBC ( b, array) ;
for ( int i = 0 ; i < a. length ( ) - b. length ( ) + 1 ; ) {
int j = 0 ;
for ( j = b. length ( ) - 1 ; j >= 0 ; j-- ) {
if ( a. charAt ( j + i) != b. charAt ( j) ) {
break ;
}
}
if ( j < 0 ) {
System . out. println ( "匹配成功,下标是:" + i) ;
return ;
}
int ii = 0 ;
if ( j != b. length ( ) - 1 ) {
char c = a. charAt ( j + i) ;
for ( ii = j - 1 ; ii >= 0 ; ii-- ) {
if ( b. charAt ( ii) == c) {
break ;
}
}
}
int aa;
boolean is = true ;
if ( j == b. length ( ) - 1 ) {
aa = j - array[ a. charAt ( j + i) ] ;
is = false ;
} else {
aa = j - ii;
}
int bb = 0 ;
if ( is == true ) {
int gg = b. length ( ) ;
for ( int kk = j - ( b. length ( ) - 1 - j - 1 ) ; kk >= 0 ; kk-- ) {
if ( b. charAt ( kk) == b. charAt ( j + 1 ) ) {
int oo = 0 ;
for ( int pp = 1 ; pp < b. length ( ) - 1 - j - 1 ; pp++ ) {
if ( b. charAt ( pp) != b. charAt ( j + 1 + pp) ) {
oo = 1 ;
break ;
}
}
if ( oo == 0 ) {
gg = kk;
}
}
}
int p = gg;
if ( gg == b. length ( ) ) {
int tt = 0 ;
for ( int ll = b. length ( ) - 1 - j - 1 , jj = 1 ; ll > 0 ; ll-- , jj++ ) {
if ( b. charAt ( 0 ) == b. charAt ( j + 1 + ll) ) {
tt = jj;
}
}
gg -= tt;
}
if ( p == b. length ( ) ) {
bb = gg;
} else {
bb = j + 1 - gg;
}
}
if ( aa >= bb) {
i += aa;
} else {
i += bb;
}
}
System . out. println ( "没有找到" ) ;
}
public static void bad2 ( String a, String b) {
int [ ] array = new int [ 256 ] ;
generateBC ( b, array) ;
for ( int i = 0 ; i < a. length ( ) - b. length ( ) + 1 ; ) {
int j = 0 ;
for ( j = b. length ( ) - 1 ; j >= 0 ; j-- ) {
if ( a. charAt ( j + i) != b. charAt ( j) ) {
break ;
}
}
if ( j < 0 ) {
System . out. println ( "匹配成功,下标是:" + i) ;
return ;
}
int ii = 0 ;
if ( j != b. length ( ) - 1 ) {
char c = a. charAt ( j + i) ;
for ( int iii = 0 ; iii <= j - 1 ; iii++ ) {
if ( b. charAt ( iii) == c) {
ii = iii;
}
}
if ( j == 0 ) {
ii = - 1 ;
}
}
if ( j == b. length ( ) - 1 ) {
i += j - array[ a. charAt ( j + i) ] ;
} else {
i += j - ii;
}
}
System . out. println ( "没有找到" ) ;
}
public static void bad3 ( String a, String b) {
int [ ] array = new int [ 256 ] ;
generateBC ( b, array) ;
for ( int i = 0 ; i < a. length ( ) - b. length ( ) + 1 ; ) {
int j = 0 ;
for ( j = b. length ( ) - 1 ; j >= 0 ; j-- ) {
if ( a. charAt ( j + i) != b. charAt ( j) ) {
break ;
}
}
if ( j < 0 ) {
System . out. println ( "匹配成功,下标是:" + i) ;
return ;
}
boolean is = true ;
if ( j == b. length ( ) - 1 ) {
is = false ;
}
int bb = 0 ;
if ( is == true ) {
int gg = b. length ( ) ;
for ( int kk = j - ( b. length ( ) - 1 - j - 1 ) ; kk >= 0 ; kk-- ) {
if ( b. charAt ( kk) == b. charAt ( j + 1 ) ) {
int oo = 0 ;
for ( int pp = 1 ; pp < b. length ( ) - 1 - j - 1 ; pp++ ) {
if ( b. charAt ( pp) != b. charAt ( j + 1 + pp) ) {
oo = 1 ;
break ;
}
}
if ( oo == 0 ) {
gg = kk;
}
}
}
int p = gg;
if ( gg == b. length ( ) ) {
int tt = 0 ;
for ( int ll = b. length ( ) - 1 - j - 1 , jj = 1 ; ll > 0 ; ll-- , jj++ ) {
if ( b. charAt ( 0 ) == b. charAt ( j + 1 + ll) ) {
tt = jj;
}
}
gg -= tt;
}
if ( p == b. length ( ) ) {
bb = gg;
} else {
bb = j + 1 - gg;
}
}
i += bb;
}
System . out. println ( "没有找到" ) ;
}
public static void main ( String [ ] args) {
String a = "dffvff" ;
String b = "dvf" ;
System . out. println ( "下标从0开始的哦" ) ;
bad ( a, b) ;
badd ( a, b) ;
bad1 ( a, b) ;
bad2 ( a, b) ;
bad3 ( a, b) ;
}
}
public class TrieNode {
public char data;
public TrieNode [ ] children = new TrieNode [ 26 ] ;
public boolean isEndingChar = false ;
public TrieNode ( char data) {
this . data = data;
}
}
package com. lagou ;
public class test55 {
public static class TrieNode {
public char data;
public TrieNode [ ] children = new TrieNode [ 26 ] ;
public boolean isEndingChar = false ;
public TrieNode ( char data) {
this . data = data;
}
}
public static TrieNode root = new TrieNode ( '/' ) ;
public static void insert ( String a) {
TrieNode node = root;
for ( int i = 0 ; i < a. length ( ) ; i++ ) {
char c = a. charAt ( i) ;
int i1 = c - 97 ;
if ( node. children[ i1] == null ) {
node. children[ i1] = new TrieNode ( c) ;
}
node = node. children[ i1] ;
}
node. isEndingChar = true ;
}
public static void select ( String a) {
TrieNode node = root;
for ( int i = 0 ; i < a. length ( ) ; i++ ) {
char c = a. charAt ( i) ;
int i1 = c - 97 ;
if ( node. children[ i1] == null ) {
System . out. println ( "没有该字符串" ) ;
return ;
}
node = node. children[ i1] ;
}
if ( node. isEndingChar == true ) {
System . out. println ( "有该字符串" ) ;
} else {
System . out. println ( "没有该字符串" ) ;
}
}
public static void main ( String [ ] args) {
insert ( "hello" ) ;
insert ( "her" ) ;
insert ( "hi" ) ;
insert ( "how" ) ;
insert ( "see" ) ;
insert ( "so" ) ;
select ( "how" ) ;
}
}
package com. lagou ;
import java. util. ArrayList ;
import java. util. List ;
public class test66 {
public List list;
int [ ] [ ] i;
int du;
public test66 ( int n) {
i = new int [ n] [ n] ;
du = 0 ;
list = new ArrayList < > ( n) ;
}
public void insertNode ( Object node) {
list. add ( node) ;
}
public void insertEdge ( int a, int b, int c) {
i[ a] [ b] = c;
du++ ;
}
public int getWeight ( int a, int b) {
return i[ a] [ b] ;
}
public Object getNode ( int i) {
return list. get ( i) ;
}
public int getEage ( ) {
return du;
}
public int getNodeAll ( ) {
return list. size ( ) ;
}
public static void main ( String [ ] args) {
int a = 4 ;
String [ ] s = { "v1" , "v2" , "v3" , "v4" } ;
test66 t = new test66 ( a) ;
for ( String c : s) {
t. insertNode ( c) ;
}
t. insertEdge ( 0 , 1 , 2 ) ;
t. insertEdge ( 0 , 2 , 5 ) ;
t. insertEdge ( 2 , 3 , 8 ) ;
t. insertEdge ( 3 , 0 , 7 ) ;
System . out. println ( "结点个数是:" + t. getNodeAll ( ) ) ;
System . out. println ( "边的个数是:" + t. getEage ( ) ) ;
}
}
顶点和边组成的 ,所以我们就抽象出两种类,一个 是Vertex顶点类,一个是Edge边类,注意:这里是将开始的节点称为顶点,顶点指向的顶点称为边类(这里要注意,之所以是边类,在程序里面会说明)package com. lagou ;
import java. util. HashMap ;
import java. util. Iterator ;
import java. util. Map ;
import java. util. Set ;
public class test77 {
public class Vertex {
String name;
Edge next;
public Vertex ( String name, Edge next) {
this . name = name;
this . next = next;
}
}
public class Edge {
String name;
int weight;
Edge next;
public Edge ( String name, int weight, Edge next) {
this . name = name;
this . weight = weight;
this . next = next;
}
}
Map < String , Vertex > ;
public test77 ( ) {
map = new HashMap < > ( ) ;
}
public void insertNode ( String a) {
Vertex aa = new Vertex ( a, null ) ;
map. put ( a, aa) ;
}
public void insertEdge ( String a, String b, int c) {
Vertex vertex = map. get ( a) ;
if ( vertex == null ) {
vertex = new Vertex ( a, null ) ;
map. put ( a, vertex) ;
}
if ( vertex. next == null ) {
vertex. next = new Edge ( b, c, null ) ;
} else {
Edge temp = vertex. next;
while ( true ) {
if ( temp. next == null ) {
temp. next = new Edge ( b, c, null ) ;
return ;
}
temp = temp. next;
}
}
}
public void Select ( ) {
Set < Map. Entry < String , Vertex > > = map. entrySet ( ) ;
Iterator < Map. Entry < String , Vertex > > = entries. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
Map. Entry < String , Vertex > = iterator. next ( ) ;
Vertex vertex = entry. getValue ( ) ;
Edge edge = vertex. next;
while ( edge != null ) {
System . out. println ( vertex. name + " 指向 " + edge. name + " 权值为:" + edge. weight) ;
edge = edge. next;
}
}
}
public static void main ( String [ ] args) {
test77 graph = new test77 ( ) ;
graph. insertNode ( "A" ) ;
graph. insertNode ( "B" ) ;
graph. insertNode ( "C" ) ;
graph. insertNode ( "D" ) ;
graph. insertNode ( "E" ) ;
graph. insertNode ( "F" ) ;
graph. insertEdge ( "C" , "A" , 1 ) ;
graph. insertEdge ( "F" , "C" , 2 ) ;
graph. insertEdge ( "A" , "B" , 4 ) ;
graph. insertEdge ( "E" , "B" , 2 ) ;
graph. insertEdge ( "A" , "D" , 5 ) ;
graph. insertEdge ( "D" , "F" , 4 ) ;
graph. insertEdge ( "D" , "E" , 3 ) ;
graph. Select( ) ;
}
}
package com. lagou ;
import java. util. * ;
public class test88 {
public class Vertex {
String name;
Edge next;
boolean b = false ;
public Vertex ( String name, Edge next) {
this . name = name;
this . next = next;
}
}
public class Edge {
String name;
int weight;
Edge next;
public Edge ( String name, int weight, Edge next) {
this . name = name;
this . weight = weight;
this . next = next;
}
}
Map < String , Vertex > ;
public test88 ( ) {
map = new HashMap < > ( ) ;
}
public void insertNode ( String a) {
if ( map. get ( a) == null ) {
Vertex aa = new Vertex ( a, null ) ;
map. put ( a, aa) ;
}
}
public void insertEdge ( String a, String b, int c) {
Vertex vertex = map. get ( a) ;
if ( vertex == null ) {
vertex = new Vertex ( a, null ) ;
map. put ( a, vertex) ;
}
if ( vertex. next == null ) {
vertex. next = new Edge ( b, c, null ) ;
} else {
Edge temp = vertex. next;
Edge temp2 = vertex. next;
while ( true ) {
if ( temp. name == b) {
temp. weight = c;
return ;
}
if ( temp. name. hashCode ( ) > b. hashCode ( ) ) {
if ( temp2 != vertex. next) {
Edge j = new Edge ( b, c, null ) ;
temp2. next = j;
j. next = temp;
} else {
Edge j = new Edge ( b, c, null ) ;
vertex. next = j;
j. next = temp2;
}
return ;
}
if ( temp. next == null ) {
temp. next = new Edge ( b, c, null ) ;
return ;
}
temp2 = temp;
temp = temp. next;
}
}
}
public void Select ( ) {
Set < Map. Entry < String , Vertex > > = map. entrySet ( ) ;
Iterator < Map. Entry < String , Vertex > > = entries. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
Map. Entry < String , Vertex > = iterator. next ( ) ;
Vertex vertex = entry. getValue ( ) ;
Edge edge = vertex. next;
while ( edge != null ) {
System . out. println ( vertex. name + " 指向 " + edge. name + " 权值为:" + edge. weight) ;
edge = edge. next;
}
}
}
public void Select1 ( String a) {
Set < String > = map. keySet ( ) ;
Iterator < String > = strings. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
String next = iterator. next ( ) ;
map. get ( next) . b = false ;
}
String [ ] array = new String [ map. size ( ) ] ;
int i = 0 ;
Vertex vertex = map. get ( a) ;
array[ i] = vertex. name;
i++ ;
Stack < Object > = new Stack < > ( ) ;
stack. push ( vertex. name) ;
vertex. b = true ;
while ( true ) {
String na = null ;
Edge edge = vertex. next;
if ( edge != null ) {
while ( edge != null ) {
if ( map. get ( edge. name) . b == false ) {
na = edge. name;
break ;
}
edge = edge. next;
}
if ( na != null ) {
stack. push ( na) ;
array[ i] = na;
i++ ;
map. get ( na) . b = true ;
} else {
stack. pop ( ) ;
}
} else {
stack. pop ( ) ;
}
if ( stack. isEmpty ( ) ) {
break ;
}
String peek = ( String ) stack. peek ( ) ;
vertex = map. get ( peek) ;
}
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < array. length; ii++ ) {
if ( ii == array. length - 1 ) {
System . out. print ( array[ ii] ) ;
} else {
System . out. print ( array[ ii] + "," ) ;
}
}
System . out. println ( "]" ) ;
}
public void Select2 ( String a) {
Set < String > = map. keySet ( ) ;
Iterator < String > = strings. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
String next = iterator. next ( ) ;
map. get ( next) . b = false ;
}
String [ ] array = new String [ map. size ( ) ] ;
int i = 0 ;
Vertex vertex = map. get ( a) ;
Queue < String > = new LinkedList < > ( ) ;
queue. offer ( vertex. name) ;
vertex. b = true ;
String poll = queue. poll ( ) ;
array[ i] = poll;
i++ ;
while ( true ) {
Edge edge = vertex. next;
if ( edge != null ) {
while ( edge != null ) {
if ( map. get ( edge. name) . b == false ) {
queue. offer ( edge. name) ;
map. get ( edge. name) . b = true ;
}
edge = edge. next;
}
}
if ( queue. isEmpty ( ) ) {
break ;
}
String poll1 = queue. poll ( ) ;
array[ i] = poll1;
i++ ;
vertex = map. get ( poll1) ;
edge = vertex. next;
}
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < array. length; ii++ ) {
if ( ii == array. length - 1 ) {
System . out. print ( array[ ii] ) ;
} else {
System . out. print ( array[ ii] + "," ) ;
}
}
System . out. println ( "]" ) ;
}
public static void main ( String [ ] args) {
test88 graph = new test88 ( ) ;
graph. insertNode ( "A" ) ;
graph. insertNode ( "B" ) ;
graph. insertNode ( "C" ) ;
graph. insertNode ( "D" ) ;
graph. insertNode ( "E" ) ;
graph. insertNode ( "F" ) ;
graph. insertEdge ( "C" , "A" , 1 ) ;
graph. insertEdge ( "F" , "C" , 2 ) ;
graph. insertEdge ( "A" , "D" , 5 ) ;
graph. insertEdge ( "A" , "B" , 4 ) ;
graph. insertEdge ( "E" , "B" , 2 ) ;
graph. insertEdge ( "D" , "F" , 4 ) ;
graph. insertEdge ( "D" , "E" , 3 ) ;
graph. Select( ) ;
graph. Select1( "A" ) ;
graph. Select2( "A" ) ;
test88 aa = new test88 ( ) ;
aa. insertNode ( "A" ) ;
aa. insertNode ( "B" ) ;
aa. insertNode ( "C" ) ;
aa. insertNode ( "D" ) ;
aa. insertNode ( "E" ) ;
aa. insertNode ( "F" ) ;
aa. insertNode ( "G" ) ;
aa. insertNode ( "H" ) ;
aa. insertEdge ( "A" , "D" , 3 ) ;
aa. insertEdge ( "A" , "G" , 3 ) ;
aa. insertEdge ( "B" , "A" , 3 ) ;
aa. insertEdge ( "B" , "F" , 3 ) ;
aa. insertEdge ( "C" , "H" , 3 ) ;
aa. insertEdge ( "D" , "F" , 3 ) ;
aa. insertEdge ( "E" , "B" , 3 ) ;
aa. insertEdge ( "F" , "C" , 3 ) ;
aa. insertEdge ( "G" , "E" , 3 ) ;
aa. Select( ) ;
aa. Select1( "A" ) ;
aa. Select2( "A" ) ;
}
}
package com. lagou ;
import java. util. * ;
public class test99 {
public class Vertex {
String name;
Edge next;
Vertex prev;
boolean b = false ;
public Vertex ( String name, Edge next) {
this . name = name;
this . next = next;
}
}
public class Edge {
String name;
int weight;
Edge next;
public Edge ( String name, int weight, Edge next) {
this . name = name;
this . weight = weight;
this . next = next;
}
}
Map < String , Vertex > ;
public test99 ( ) {
map = new HashMap < > ( ) ;
}
public void insertNode ( String a) {
if ( map. get ( a) == null ) {
Vertex aa = new Vertex ( a, null ) ;
map. put ( a, aa) ;
}
}
public void insertEdge ( String a, String b, int c) {
Vertex vertex = map. get ( a) ;
if ( vertex == null ) {
vertex = new Vertex ( a, null ) ;
map. put ( a, vertex) ;
}
if ( vertex. next == null ) {
vertex. next = new Edge ( b, c, null ) ;
} else {
Edge temp = vertex. next;
Edge temp2 = vertex. next;
while ( true ) {
if ( temp. name == b) {
temp. weight = c;
return ;
}
if ( temp. name. hashCode ( ) > b. hashCode ( ) ) {
if ( temp2 != vertex. next) {
Edge j = new Edge ( b, c, null ) ;
temp2. next = j;
j. next = temp;
} else {
Edge j = new Edge ( b, c, null ) ;
vertex. next = j;
j. next = temp2;
}
return ;
}
if ( temp. next == null ) {
temp. next = new Edge ( b, c, null ) ;
return ;
}
temp2 = temp;
temp = temp. next;
}
}
}
public void Select ( ) {
Set < Map. Entry < String , Vertex > > = map. entrySet ( ) ;
Iterator < Map. Entry < String , Vertex > > = entries. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
Map. Entry < String , Vertex > = iterator. next ( ) ;
Vertex vertex = entry. getValue ( ) ;
Edge edge = vertex. next;
while ( edge != null ) {
System . out. println ( vertex. name + " 指向 " + edge. name + " 权值为:" + edge. weight) ;
edge = edge. next;
}
}
}
public void Select2 ( String a) {
Set < String > = map. keySet ( ) ;
Iterator < String > = strings. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
String next = iterator. next ( ) ;
map. get ( next) . b = false ;
}
String [ ] array = new String [ map. size ( ) ] ;
int i = 0 ;
Vertex vertex = map. get ( a) ;
Queue < String > = new LinkedList < > ( ) ;
queue. offer ( vertex. name) ;
vertex. b = true ;
String poll = queue. poll ( ) ;
array[ i] = poll;
i++ ;
while ( true ) {
Edge edge = vertex. next;
if ( edge != null ) {
while ( edge != null ) {
if ( map. get ( edge. name) . b == false ) {
queue. offer ( edge. name) ;
map. get ( edge. name) . b = true ;
}
edge = edge. next;
}
}
if ( queue. isEmpty ( ) ) {
break ;
}
String poll1 = queue. poll ( ) ;
array[ i] = poll1;
i++ ;
vertex = map. get ( poll1) ;
edge = vertex. next;
}
System . out. print ( "[" ) ;
for ( int ii = 0 ; ii < array. length; ii++ ) {
if ( ii == array. length - 1 ) {
System . out. print ( array[ ii] ) ;
} else {
System . out. print ( array[ ii] + "," ) ;
}
}
System . out. println ( "]" ) ;
}
public void Select3 ( String a, String b) {
Set < String > = map. keySet ( ) ;
Iterator < String > = strings. iterator ( ) ;
while ( iterator. hasNext ( ) ) {
String next = iterator. next ( ) ;
map. get ( next) . b = false ;
}
String [ ] array = new String [ map. size ( ) ] ;
int i = 0 ;
Vertex vertex = map. get ( a) ;
Queue < String > = new LinkedList < > ( ) ;
queue. offer ( vertex. name) ;
vertex. b = true ;
String poll = queue. poll ( ) ;
array[ i] = poll;
i++ ;
Vertex l = null ;
while ( true ) {
Edge edge = vertex. next;
if ( edge != null ) {
int o = 0 ;
while ( edge != null ) {
if ( map. get ( edge. name) . b == false ) {
queue. offer ( edge. name) ;
map. get ( edge. name) . b = true ;
}
map. get ( edge. name) . prev = vertex;
if ( edge. name == b) {
l = map. get ( edge. name) ;
o = 1 ;
break ;
}
edge = edge. next;
}
if ( o == 1 ) {
break ;
}
}
if ( queue. isEmpty ( ) ) {
break ;
}
String poll1 = queue. poll ( ) ;
array[ i] = poll1;
i++ ;
vertex = map. get ( poll1) ;
edge = vertex. next;
}
String [ ] aaa = new String [ map. size ( ) ] ;
int oo = 0 ;
for ( int ii = 0 ; ii < aaa. length; ii++ ) {
aaa[ ii] = l. name;
oo++ ;
l = l. prev;
if ( l == null ) {
break ;
}
}
System . out. println ( Arrays . toString ( aaa) ) ;
String [ ] bbb = new String [ oo] ;
for ( int pp = 0 ; pp < bbb. length; pp++ ) {
bbb[ pp] = aaa[ pp] ;
}
String [ ] ccc = new String [ bbb. length] ;
for ( int pp = 0 , ss = ccc. length - 1 ; pp < ccc. length; pp++ , ss-- ) {
ccc[ pp] = bbb[ ss] ;
}
System . out. println ( "路径如下:" + Arrays . toString ( ccc) ) ;
}
public static void main ( String [ ] args) {
test99 graph = new test99 ( ) ;
graph. insertNode ( "A" ) ;
graph. insertNode ( "B" ) ;
graph. insertNode ( "C" ) ;
graph. insertNode ( "D" ) ;
graph. insertNode ( "E" ) ;
graph. insertNode ( "F" ) ;
graph. insertEdge ( "C" , "A" , 1 ) ;
graph. insertEdge ( "F" , "C" , 2 ) ;
graph. insertEdge ( "A" , "D" , 5 ) ;
graph. insertEdge ( "A" , "B" , 4 ) ;
graph. insertEdge ( "E" , "B" , 2 ) ;
graph. insertEdge ( "D" , "F" , 4 ) ;
graph. insertEdge ( "D" , "E" , 3 ) ;
graph. Select( ) ;
graph. Select2( "A" ) ;
graph. Select3( "A" , "E" ) ;
}
}
贪心算法的关键是贪心策略的选择或者思考 ,比如如下策略的思考:package test ;
public class test1 {
public static class Goods {
String name;
double weight;
double price;
String k = "" ;
public Goods ( String name, double weight, double price) {
this . name = name;
this . weight = weight;
this . price = price;
}
}
public void take ( Goods [ ] goods, double a) {
Goods [ ] sort = sort ( goods) ;
double j = 0 ;
for ( int i = 0 ; i < sort. length; i++ ) {
if ( a >= sort[ i] . weight) {
a -= sort[ i] . weight;
System . out. println ( sort[ i] . name + "全部拿走,总共:" + sort[ i] . weight + "kg,总价值" + sort[ i] . price) ;
j += sort[ i] . price;
} else {
System . out. println ( sort[ i] . name + "部分拿走,总共:" + a + "kg,总价值" + a * sort[ i] . price / sort[ i] . weight) ;
j += a * sort[ i] . price / sort[ i] . weight;
a -= a;
break ;
}
}
System . out. println ( "总共得到" + j + "元" ) ;
System . out. println ( "背包剩余容量:" + a + "kg" ) ;
}
public void take1 ( Goods [ ] sort, double a) {
double j = 0 ;
for ( int i = 0 ; i < sort. length; i++ ) {
int ii = 0 ;
Goods g = sort[ ii] ;
while ( true ) {
if ( ii + 1 >= sort. length) {
break ;
}
if ( g. k. equals ( "不存在" ) ) {
g = sort[ ii + 1 ] ;
ii++ ;
continue ;
}
if ( g. price / g. weight < sort[ ii + 1 ] . price / sort[ ii + 1 ] . weight) {
g = sort[ ii + 1 ] ;
}
ii++ ;
}
if ( a >= g. weight) {
a -= g. weight;
System . out. println ( g. name + "全部拿走,总共:" + g. weight + "kg,总价值" + g. price) ;
j += g. price;
} else {
System . out. println ( g. name + "部分拿走,总共:" + a + "kg,总价值" + a * g. price / g. weight) ;
j += a * g. price / g. weight;
a -= a;
break ;
}
g. k = "不存在" ;
}
System . out. println ( "总共得到" + j + "元" ) ;
System . out. println ( "背包剩余容量:" + a + "kg" ) ;
}
public Goods [ ] sort ( Goods [ ] a) {
for ( int i = 0 ; i < a. length - 1 ; i++ ) {
boolean is = true ;
for ( int j = 0 ; j < a. length - 1 - i; j++ ) {
Goods tmp = null ;
if ( ( a[ j] . price / a[ j] . weight) < ( a[ j + 1 ] . price / a[ j + 1 ] . weight) ) {
is = false ;
tmp = a[ j] ;
a[ j] = a[ j + 1 ] ;
a[ j + 1 ] = tmp;
}
}
if ( is) {
break ;
}
}
return a;
}
public static void main ( String [ ] args) {
test1 bd = new test1 ( ) ;
Goods goods1 = new Goods ( "A" , 10 , 60 ) ;
Goods goods2 = new Goods ( "B" , 20 , 100 ) ;
Goods goods3 = new Goods ( "C" , 30 , 120 ) ;
Goods [ ] goodslist = { goods1, goods2, goods3} ;
bd. take ( goodslist, 50 ) ;
bd. take1 ( goodslist, 50 ) ;
}
}
package test ;
public class test2 {
public static char toUpCaseUnit ( char c) {
int n = c;
if ( n < 97 || n > 122 ) {
return ' ' ;
}
return ( char ) ( n - 32 ) ;
}
public static char [ ] toUpCase ( char [ ] chs, int i) {
if ( i >= chs. length) return chs;
chs[ i] = toUpCaseUnit ( chs[ i] ) ;
return toUpCase ( chs, i + 1 ) ;
}
public static char [ ] toUpCase1 ( char [ ] chs, int i) {
for ( int a = i; a < chs. length; a++ ) {
chs[ a] = toUpCaseUnit ( chs[ a] ) ;
}
return chs;
}
public static void main ( String [ ] args) {
String ss = "abcde" ;
System . out. println ( test2. toUpCase ( ss. toCharArray ( ) , 0 ) ) ;
System . out. println ( test2. toUpCase1 ( ss. toCharArray ( ) , 0 ) ) ;
}
}
package test ;
public class test3 {
public static int commpow ( int x, int n) {
int s = 1 ;
while ( n >= 1 ) {
s *= x;
n-- ;
}
return s;
}
public static void main ( String [ ] args) {
System . out. println ( commpow ( 2 , 10 ) ) ;
}
}
package test ;
public class test4 {
public static int dividpow ( int x, int n) {
if ( n == 1 ) {
return x;
}
int half = dividpow ( x, n / 2 ) ;
if ( n % 2 == 0 ) {
return half * half;
} else {
return half * half * x;
}
}
public static void main ( String [ ] args) {
System . out. println ( dividpow ( 2 , 10 ) ) ;
}
}
package test ;
public class test5 {
static int QUEENS = 8 ;
int [ ] result = new int [ QUEENS ] ;
int aa = 0 ;
int jj = 0 ;
public void insert ( int a) {
if ( a >= QUEENS ) {
printQueens ( ) ;
aa++ ;
return ;
}
for ( int i = 0 ; i < QUEENS ; i++ ) {
if ( isOK ( a, i) ) {
result[ a] = i;
insert ( a + 1 ) ;
}
}
}
public void printQueens ( ) {
for ( int i = 0 ; i < QUEENS ; i++ ) {
System . out. print ( "|" ) ;
for ( int j = 0 ; j < QUEENS ; j++ ) {
if ( result[ i] == j) {
System . out. print ( "Q|" ) ;
} else {
System . out. print ( "*|" ) ;
}
}
System . out. println ( ) ;
}
System . out. println ( "-----------------------" ) ;
}
public boolean isOK ( int a, int b) {
int left = b - 1 ;
int right = b + 1 ;
int o = jj;
for ( int i = a - 1 ; i >= 0 ; i-- ) {
++ jj;
if ( result[ i] == b) {
return false ;
}
if ( left >= 0 ) {
if ( result[ i] == left) {
return false ;
}
}
if ( right < QUEENS ) {
if ( result[ i] == right) {
return false ;
}
}
left-- ;
right++ ;
}
if ( o== jj) {
jj++ ;
}
return true ;
}
public static void main ( String [ ] args) {
test5 queens = new test5 ( ) ;
queens. insert ( 0 ) ;
System . out. println ( "有" + queens. aa + "个可能" ) ;
System . out. println ( "执行了" + queens. jj + "次循环" ) ;
}
}
3=6,你在再怎么操作,2 * 3=6就是最优解的,可能有与他同级,但基本不会超过(因为是自己的),比如3 2=6,当然,这个最优解是自己的最优解,不是别人的,因为6也可以是1 *6=6,这里以自己的最优解来说明)
package test ;
public class test6 {
static long [ ] sub = new long [ 100 ] ;
public static long fib ( int n) {
if ( n <= 1 ) return n;
if ( sub[ n] == 0 ) {
sub[ n] = fib ( n - 1 ) + fib ( n - 2 ) ;
}
return sub[ n] ;
}
public static long fa ( int n) {
if ( n <= 1 ) return n;
return fa ( n - 1 ) + fa ( n - 2 ) ;
}
public static void main ( String [ ] args) {
System . out. println ( fib ( 50 ) ) ;
System . out. println ( fa ( 50 ) ) ;
}
}
package test ;
public class test7 {
public static int fib ( int n) {
int a[ ] = new int [ n + 1 ] ;
a[ 0 ] = 0 ;
a[ 1 ] = 1 ;
int i;
for ( i = 2 ; i <= n; i++ ) {
a[ i] = a[ i - 1 ] + a[ i - 2 ] ;
}
return a[ i - 1 ] ;
}
public static int fa ( int i) {
if ( i <= 1 ) return i;
int a = 0 ;
int b = 1 ;
for ( int j = 2 ; j <= i; j++ ) {
b = b + a;
a = b - a;
}
return b;
}
public static void main ( String [ ] args) {
System . out. println ( fib ( 9 ) ) ;
System . out. println ( fa ( 9 ) ) ;
}
}
package test ;
public class test8 {
public static class Node {
int key;
String name;
Node next;
public Node ( int key, String name) {
this . key = key;
this . name = name;
}
}
public static boolean isRing ( Node head) {
if ( head == null ) {
System . out. println ( "没有头节点" ) ;
return false ;
}
Node slow = head;
Node fast = head. next;
while ( fast != null && fast. next != null ) {
if ( slow == fast) {
return true ;
}
fast = fast. next. next;
slow = slow. next;
}
return false ;
}
public static void main ( String [ ] args) {
Node n1 = new Node ( 1 , "张飞" ) ;
Node n2 = new Node ( 2 , "关羽" ) ;
Node n3 = new Node ( 3 , "赵云" ) ;
Node n4 = new Node ( 4 , "黄忠" ) ;
Node n5 = new Node ( 5 , "马超" ) ;
n1. next = n2;
n2. next = n3;
n3. next = n4;
n4. next = n5;
n5. next = n1;
System . out. println ( isRing ( n1) ) ;
}
}
那么中间的值呢,他代表是该承重最大的价值是多少
package test ;
public class test9 {
public static int maxValue ( int [ ] values, int [ ] weights, int max) {
if ( values == null || values. length == 0 ) return 0 ;
if ( weights == null || weights. length == 0 ) return 0 ;
if ( values. length != weights. length || max <= 0 ) return 0 ;
int [ ] [ ] dp = new int [ values. length + 1 ] [ max + 1 ] ;
for ( int i = 1 ; i <= values. length; i++ ) {
for ( int j = 1 ; j <= max; j++ ) {
if ( j < weights[ i - 1 ] ) {
dp[ i] [ j] = dp[ i - 1 ] [ j] ;
}
else {
dp[ i] [ j] = Math . max ( ( dp[ i - 1 ] [ j] ) , values[ i - 1 ] + dp[ i - 1 ] [ j - weights[ i - 1 ] ] ) ;
}
}
}
return dp[ values. length] [ max] ;
}
public static void main ( String [ ] args) {
int [ ] values = { 6 , 3 , 5 , 4 , 6 } ;
int [ ] weights = { 2 , 2 , 6 , 5 , 4 } ;
int max = 10 ;
System . out. println ( maxValue ( values, weights, max) ) ;
}
}
package test ;
public class test9 {
public static int maxValue ( int [ ] values, int [ ] weights, int max) {
if ( values == null || values. length == 0 ) return 0 ;
if ( weights == null || weights. length == 0 ) return 0 ;
if ( values. length != weights. length || max <= 0 )
return 0 ;
int [ ] [ ] dp = new int [ values. length] [ max] ;
for ( int i = 0 ; i < values. length; i++ ) {
for ( int j = 0 ; j < max; j++ ) {
if ( j + 1 < weights[ i] ) {
int l = 0 ;
if ( i != 0 ) {
l = dp[ i - 1 ] [ j] ;
}
dp[ i] [ j] = l;
} else {
int ii = 0 ;
int oo = 0 ;
if ( i != 0 ) {
ii = dp[ i - 1 ] [ j] ;
int uu = j - weights[ i] ;
if ( uu < 0 ) {
uu = 0 ;
}
oo = dp[ i - 1 ] [ uu] ;
}
dp[ i] [ j] = Math . max ( ii, values[ i] + oo) ;
}
}
}
return dp[ values. length - 1 ] [ max - 1 ] ;
}
public static void main ( String [ ] args) {
int [ ] values = { 6 , 3 , 5 , 4 , 6 } ;
int [ ] weights = { 2 , 2 , 6 , 5 , 4 } ;
int max = 10 ;
System . out. println ( maxValue ( values, weights, max) ) ;
}
}































































































![[阶段4 企业开发进阶] 6. Dubbo](https://img-blog.csdnimg.cn/a1d2fefb1b4441e1b3534078b21a604e.jpeg#pic_center)





![[附源码]计算机毕业设计第三方游戏零售平台Springboot程序](https://img-blog.csdnimg.cn/afa34da8270f4f0ca8dabf1ead4291d6.png)