目录
- 一、基本介绍
- 1、性能指标
- 2、JMeter
- 1、JMeter 安装
- 2、JMeter 压测示例
- 1、添加线程组
- 2、添加 HTTP 请求
- 3、添加监听器
- 4、启动压测&查看分析结果
- 3、JMeter Address Already in use 错误解决
- 二、性能监控
- 1、jvm 内存模型
- 2、堆
- 3、jconsole 与 jvisualvm
- 1、jvisualvm 能干什么
- 2、安装插件方便查看 gc
- 4、监控指标
- 1、中间件指标
- 2、数据库指标
- 5、JVM 分析&调优
- 1、几个常用工具
- 2、命令示例
- 3、调优项
- 三、nginx动静分离
- 四、模拟线上应用内存崩溃宕机情况
- 五、优化三级分类数据获取
- 六、缓存
- 1、本地缓存和分布式缓存
- 1、缓存使用
- 2、整合 redis 作为缓存
- 2、缓存失效问题
- 1、缓存穿透
- 2、缓存雪崩
- 3、缓存击穿
- 3、缓存数据一致性
- 1、保证一致性模式
- 1、双写模式
- 2、失效模式
- 3、改进方法 1-分布式读写锁
- 4、改进方法 2-使用 cananl
- 4、分布式锁
- 1、分布式锁与本地锁
- 2、分布式锁实现
- 3、Redisson 完成分布式锁
- 1、简介
- 2、配置
- 3、使用分布式锁
- 4、读写锁
- 5、闭锁
- 6、信号量
- 7、缓存一致性解决
- 8、缓存一致性-解决-canel
- 七、Spring cache
- 1、简介
- 2、基础概念
- 3、注解
- 4、表达式语法
- 5、缓存穿透问题解决
一、基本介绍
压力测试考察当前软硬件环境下系统所能承受的最大负荷并帮助找出系统瓶颈所在。压测都是为了系统在线上的处理能力和稳定性维持在一个标准范围内,做到心中有数。
使用压力测试,我们有希望找到很多种用其他测试方法更难发现的错误。有两种错误类型是:内存泄漏,并发与同步。
有效的压力测试系统将应用以下这些关键条件:重复,并发,量级,随机变化。
1、性能指标
响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。
HPS(Hits Per Second) :每秒点击次数,单位是次/秒。
TPS(Transaction per Second):系统每秒处理交易数,单位是笔/秒。
QPS(Query per Second):系统每秒处理查询次数,单位是次/秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,一般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表示对服务器单击请求。
无论 TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
金融行业:1000TPS~50000TPS,不包括互联网化的活动
保险行业:100TPS~100000TPS,不包括互联网化的活动
制造行业:10TPS~5000TPS
互联网电子商务:10000TPS~1000000TPS
互联网中型网站:1000TPS~50000TPS
互联网小型网站:500TPS~10000TPS
最大响应时间(Max Response Time) 指用户发出请求或者指令到系统做出反应(响应)的最大时间。
最少响应时间(Mininum ResponseTime) 指用户发出请求或者指令到系统做出反应(响应)的最少时间。
90%响应时间(90% Response Time) 是指所有用户的响应时间进行排序,第 90%的响应时间。
从外部看,性能测试主要关注如下三个指标
吞吐量:每秒钟系统能够处理的请求数、任务数。
响应时间:服务处理一个请求或一个任务的耗时。
错误率:一批请求中结果出错的请求所占比例。
2、JMeter
1、JMeter 安装
https://jmeter.apache.org/download_jmeter.cgi
下载对应的压缩包,解压运行 jmeter.bat 即可
2、JMeter 压测示例
1、添加线程组
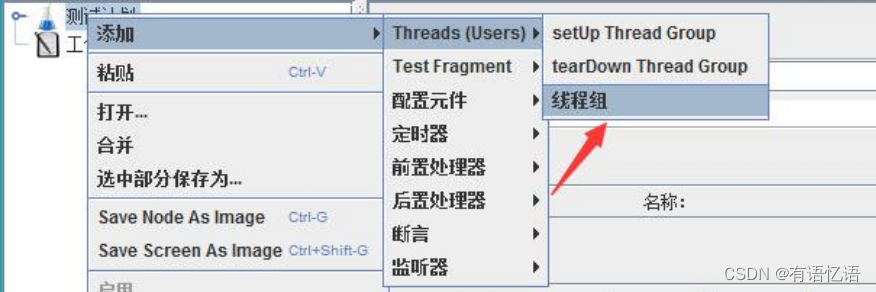
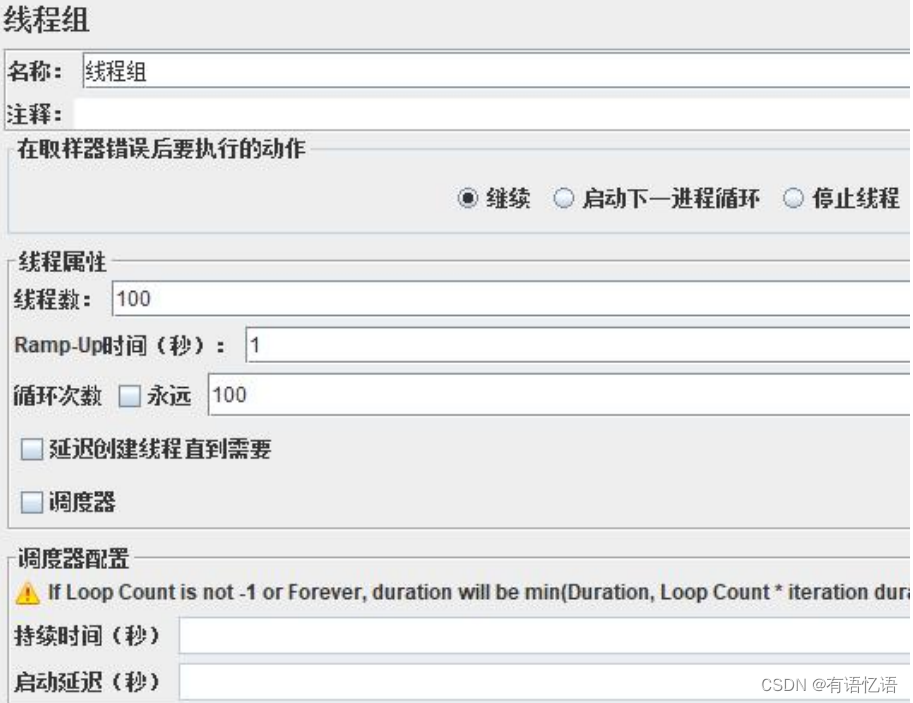
线程组参数详解:
线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
Ramp-Up Period(in seconds)准备时长:设置的虚拟用户数需要多长时间全部启动。如果线程数为 10,准备时长为 2,那么需要 2 秒钟启动 10 个线程,也就是每秒钟启动 5 个线程。
循环次数:每个线程发送请求的次数。如果线程数为 10,循环次数为 100,那么每个线程发送 100 次请求。总请求数为 10*100=1000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
Delay Thread creation until needed:直到需要时延迟线程的创建。
调度器:设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为永远)
持续时间(秒):测试持续时间,会覆盖结束时间
启动延迟(秒):测试延迟启动时间,会覆盖启动时间
启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
结束时间:测试结束时间,持续时间会覆盖它。
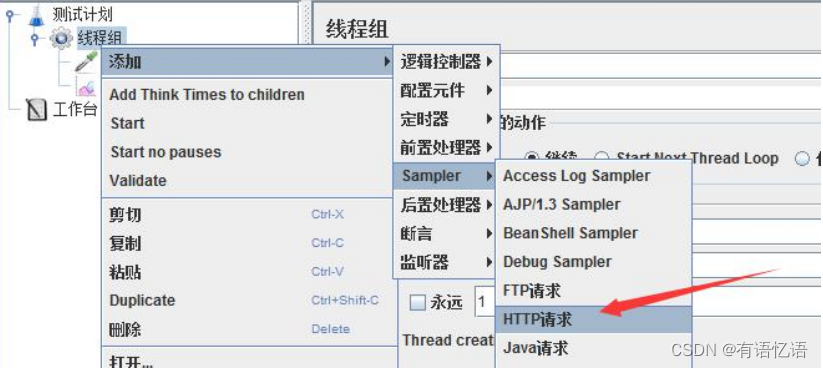
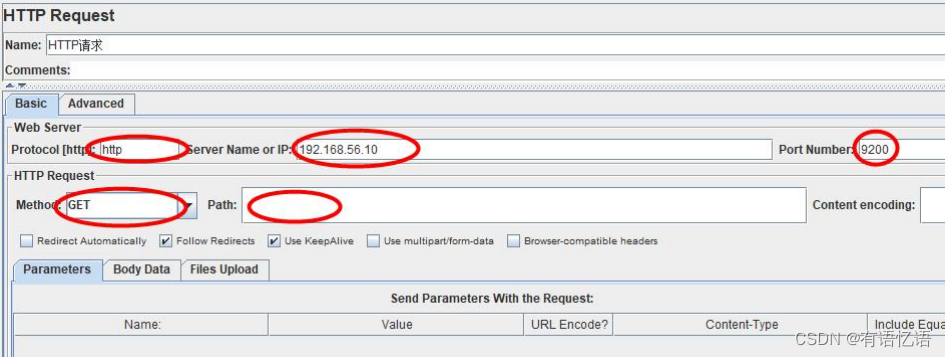
2、添加 HTTP 请求
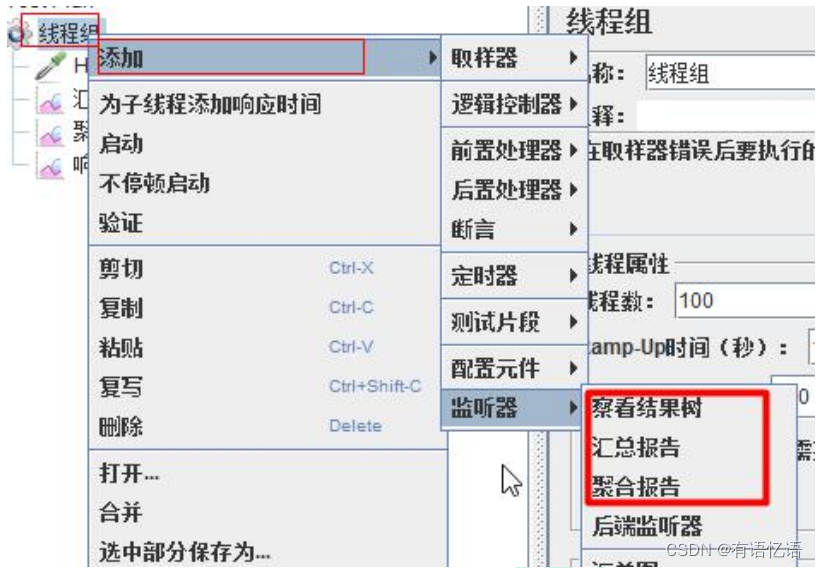
3、添加监听器
4、启动压测&查看分析结果
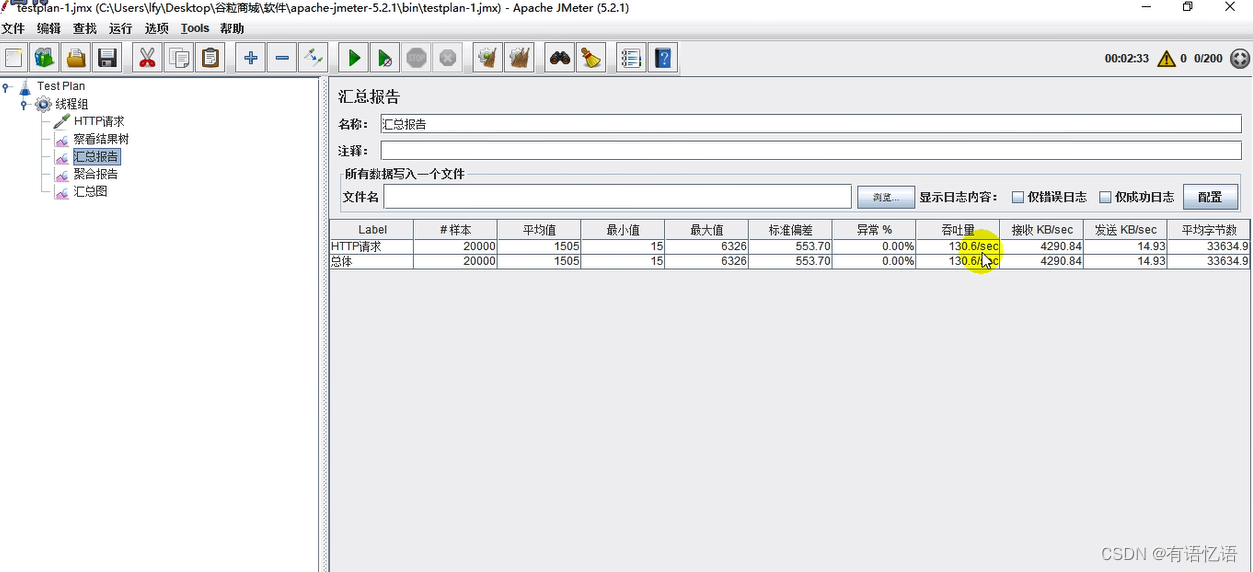
结果分析
有错误率同开发确认,确定是否允许错误的发生或者错误率允许在多大的范围内;
Throughput 吞吐量每秒请求的数大于并发数,则可以慢慢的往上面增加;若在压测的机器性能很好的情况下,出现吞吐量小于并发数,说明并发数不能再增加了,可以慢慢的往下减,找到最佳的并发数;
压测结束,登陆相应的 web 服务器查看 CPU 等性能指标,进行数据的分析;
最大的 tps,不断的增加并发数,加到 tps 达到一定值开始出现下降,那么那个值就是最大的 tps。
最大的并发数:最大的并发数和最大的 tps 是不同的概率,一般不断增加并发数,达到一个值后,服务器出现请求超时,则可认为该值为最大的并发数。
压测过程出现性能瓶颈,若压力机任务管理器查看到的 cpu、网络和 cpu 都正常,未达到 90%以上,则可以说明服务器有问题,压力机没有问题。
影响性能考虑点包括:数据库、应用程序、中间件(tomact、Nginx)、网络和操作系统等方面
首先考虑自己的应用属于 CPU 密集型还是 IO 密集型。
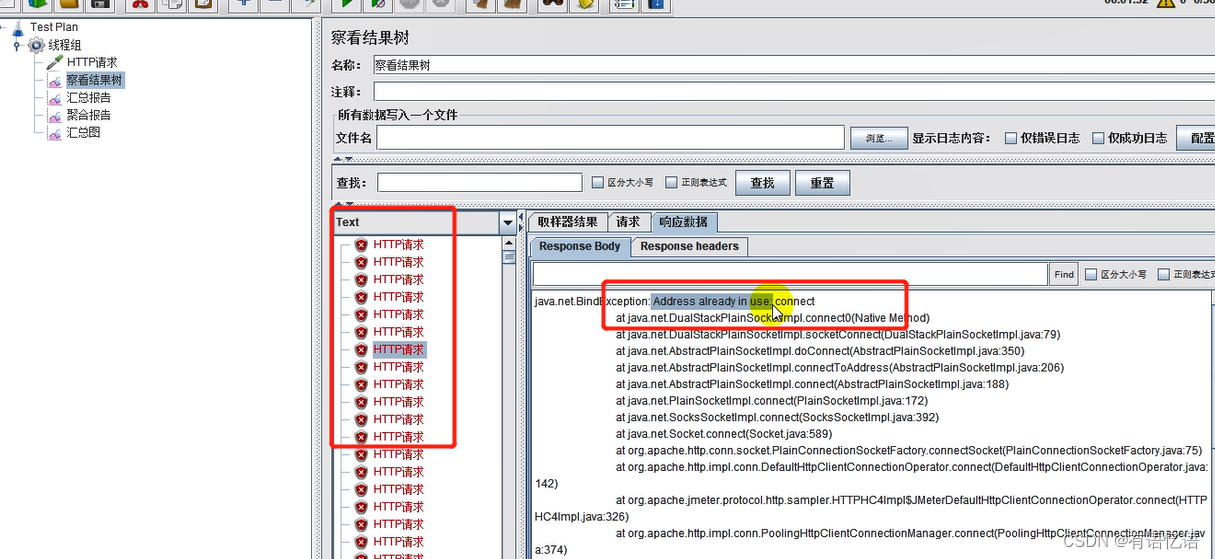
3、JMeter Address Already in use 错误解决
windows 本身提供的端口访问机制的问题。
Windows 提供给 TCP/IP 链接的端口为 1024-5000,并且要四分钟来循环回收他们。就导致我们在短时间内跑大量的请求时将端口占满了。
1.cmd 中,用 regedit 命令打开注册表
2.在 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters 下,
1 .右击 parameters,添加一个新的 DWORD,名字为 MaxUserPort
2 .然后双击 MaxUserPort,输入数值数据为 65534,基数选择十进制(如果是分布式运行的话,控制机器和负载机器都需要这样操作哦)
3. 修改配置完毕之后记得重启机器才会生效
https://support.microsoft.com/zh-cn/help/196271/when-you-try-to-connect-from-tcp-ports-greater-than-5000-you-receive-t
TCPTimedWaitDelay:30
二、性能监控
1、jvm 内存模型
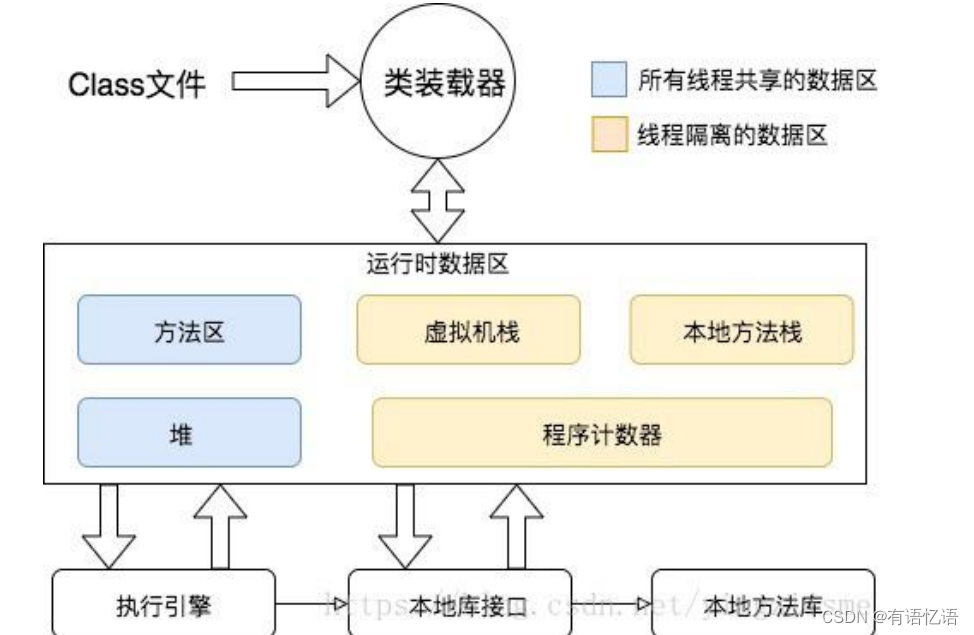
程序计数器 Program Counter Register:
记录的是正在执行的虚拟机字节码指令的地址,
此内存区域是唯一一个在JAVA虚拟机规范中没有规定任何OutOfMemoryError的区域
虚拟机:VM Stack
描述的是 JAVA 方法执行的内存模型,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法接口等信息
局部变量表存储了编译期可知的各种基本数据类型、对象引用
线程请求的栈深度不够会报 StackOverflowError 异常
栈动态扩展的容量不够会报 OutOfMemoryError 异常
虚拟机栈是线程隔离的,即每个线程都有自己独立的虚拟机栈
本地方法:Native Stack
本地方法栈类似于虚拟机栈,只不过本地方法栈使用的是本地方法
堆:Heap
几乎所有的对象实例都在堆上分配内存
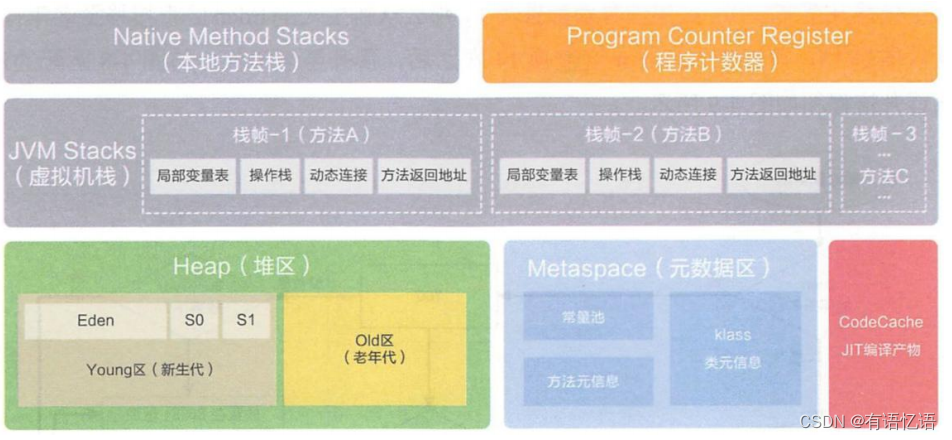
2、堆
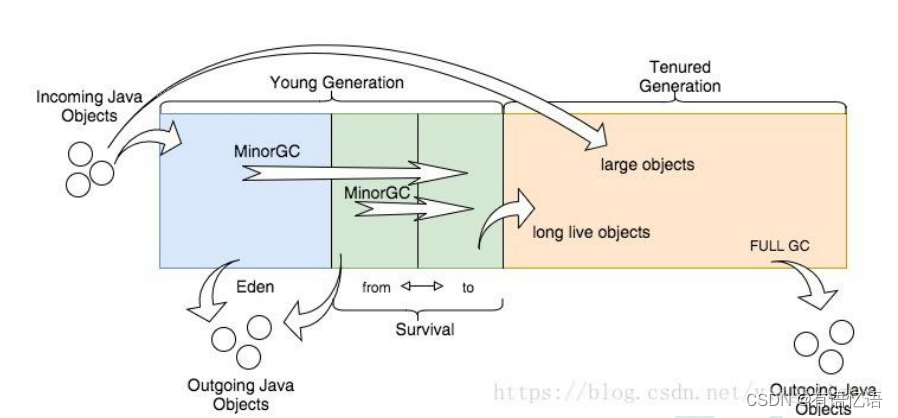
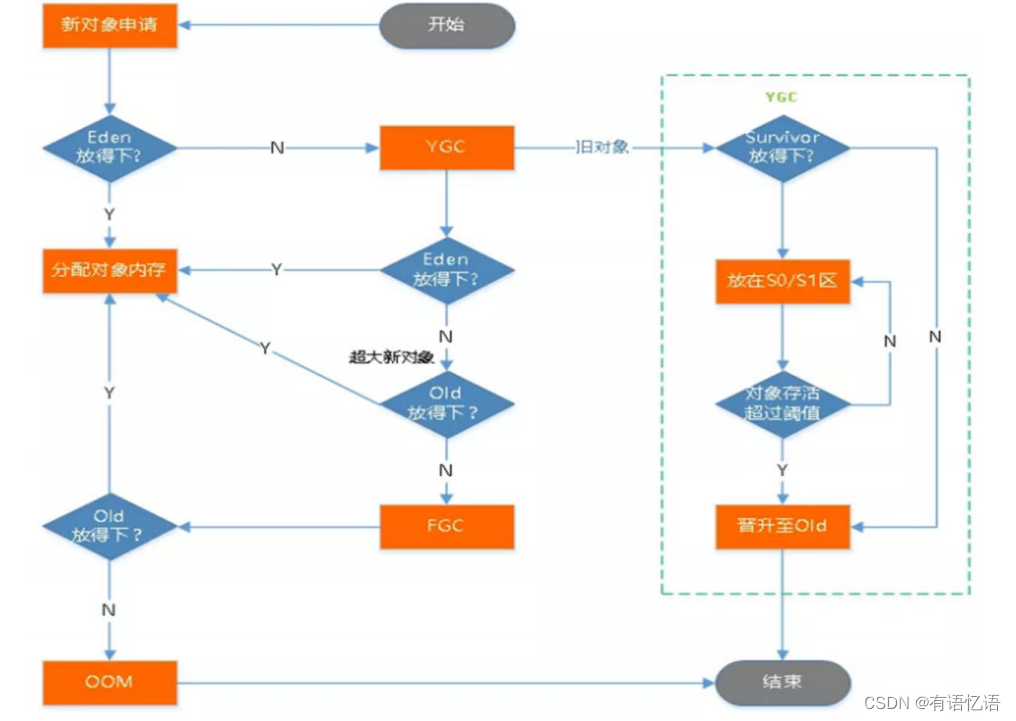
所有的对象实例以及数组都要在堆上分配。堆是垃圾收集器管理的主要区域,也被称为“GC堆”;也是我们优化最多考虑的地方。
堆可以细分为:
新生代
Eden 空间
From Survivor 空间
To Survivor 空间
老年代
永久代/元空间
Java8 以前永久代,受 jvm 管理,java8 以后元空间,直接使用物理内存。因此,默认情况下,元空间的大小仅受本地内存限制。
垃圾回收
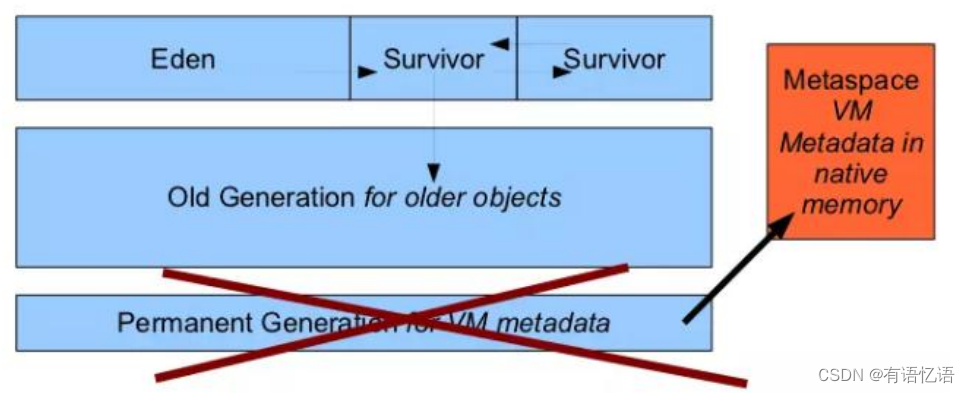
从 Java8 开始,HotSpot 已经完全将永久代(Permanent Generation)移除,取而代之的是一个新的区域—元空间(MetaSpace)。
3、jconsole 与 jvisualvm
Jdk 的两个小工具 jconsole、jvisualvm(升级版的 jconsole);通过命令行启动,可监控本地和远程应用。远程应用需要配置。
本机安装了jdk,因此可以直接使用。
双击即可连接本地的
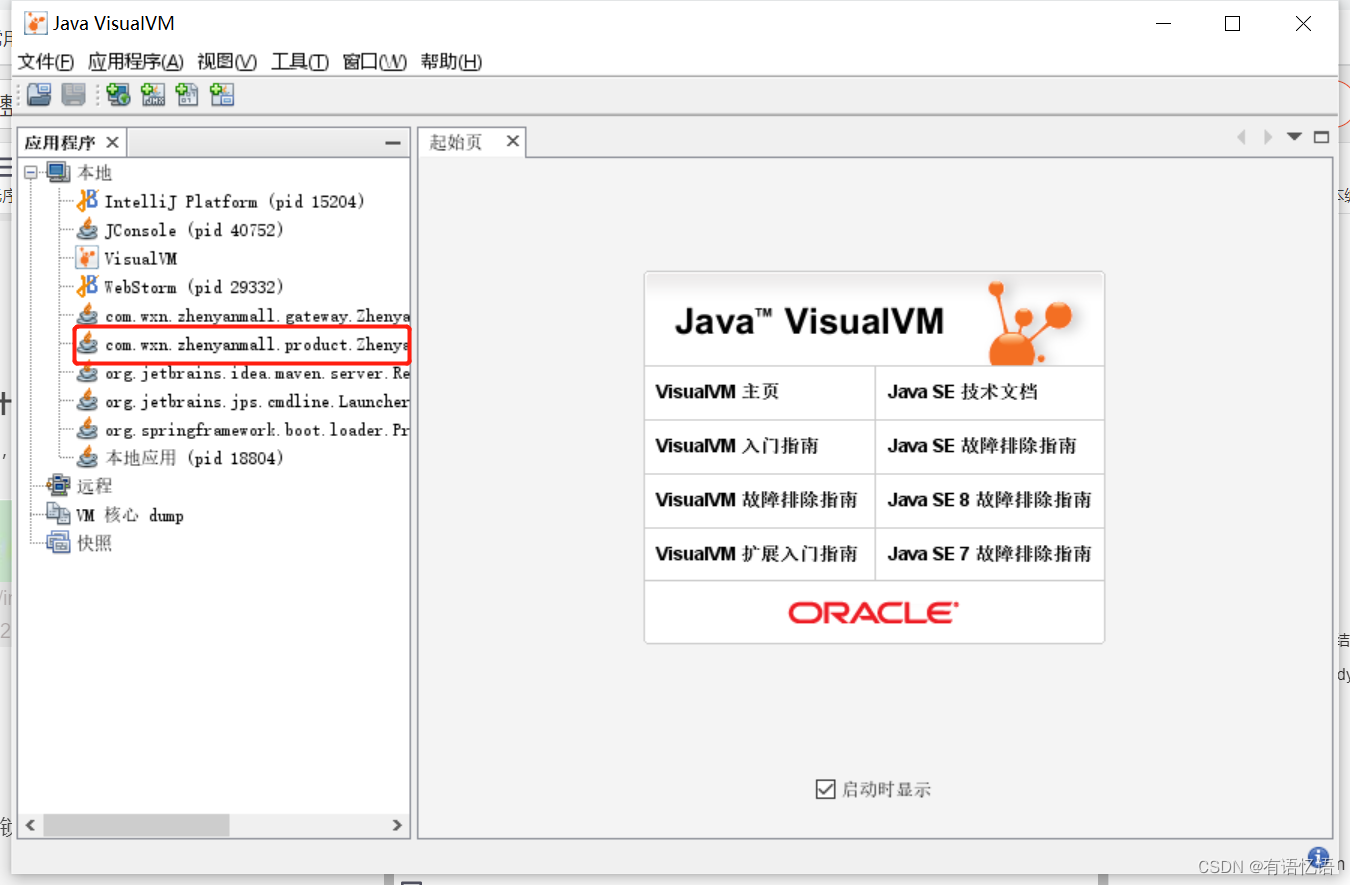
1、jvisualvm 能干什么
监控内存泄露,跟踪垃圾回收,执行时内存、cpu 分析,线程分析…

运行:正在运行的
休眠:sleep
等待:wait
驻留:线程池里面的空闲线程
监视:阻塞的线程,正在等待锁
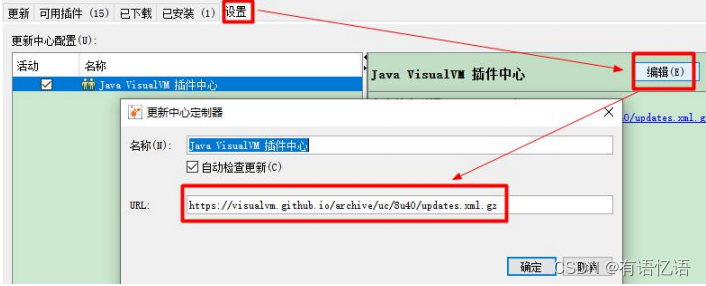
2、安装插件方便查看 gc
Cmd 启动 jvisualvm
工具->插件
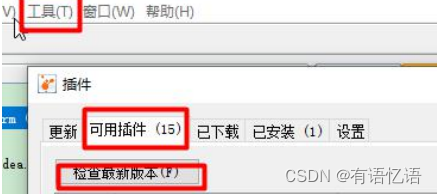

如果 503 错误解决:
打开网址 https://visualvm.github.io/pluginscenters.html
cmd 查看自己的 jdk
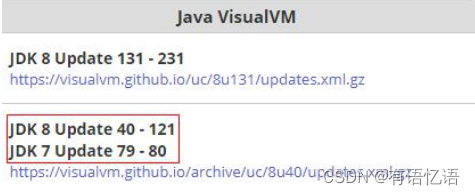
复制下面查询出来的链接。并重新设置上即可
4、监控指标
1、中间件指标
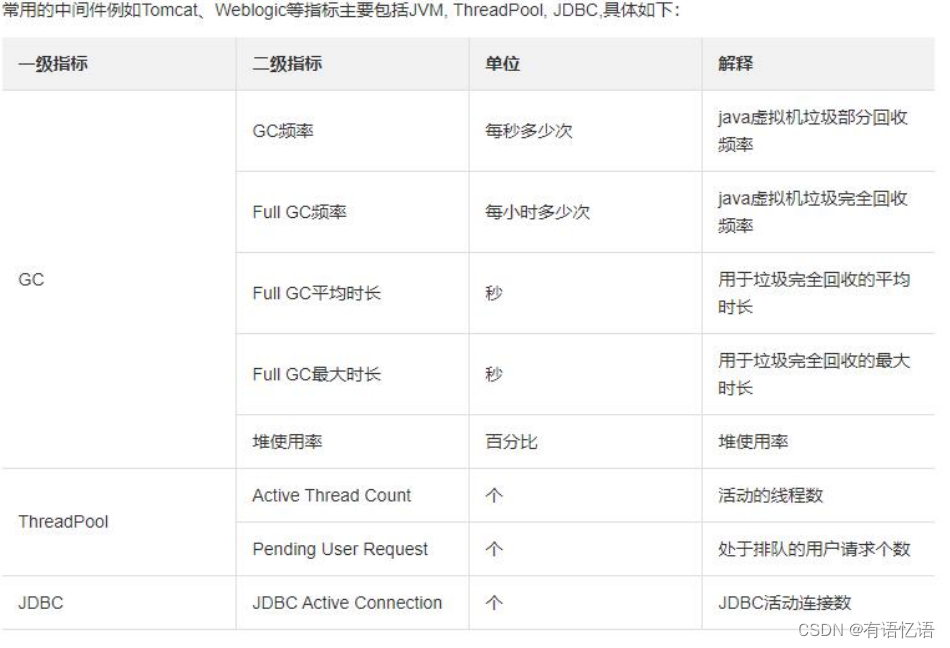
当前正在运行的线程数不能超过设定的最大值。一般情况下系统性能较好的情况下,线程数最小值设置 50 和最大值设置 200 比较合适。
当前运行的 JDBC 连接数不能超过设定的最大值。一般情况下系统性能较好的情况下,JDBC 最小值设置 50 和最大值设置 200 比较合适。
GC频率不能频繁,特别是 FULL GC 更不能频繁,一般情况下系统性能较好的情况下,JVM 最小堆大小和最大堆大小分别设置 1024M 比较合适。
2、数据库指标
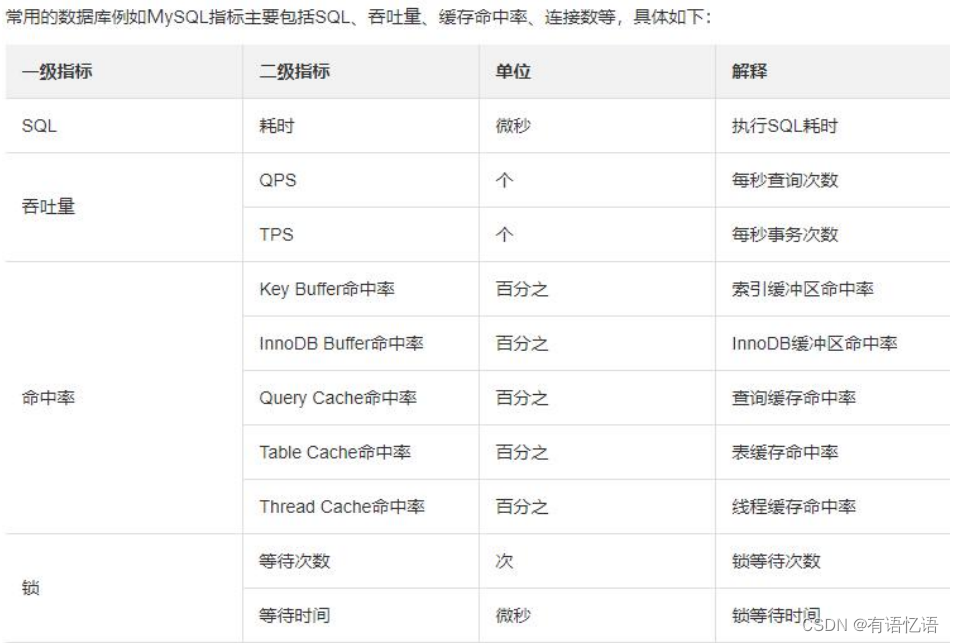
SQL 耗时越小越好,一般情况下微秒级别。
命中率越高越好,一般情况下不能低于 95%。
锁等待次数越低越好,等待时间越短越好。
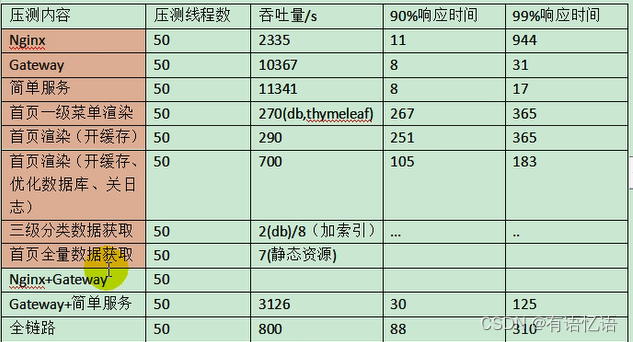
中间件越多,性能损失越大,大多都损失在网络交互了;
业务:
Db(MySQL 优化)
模板的渲染速度(缓存)
静态资源
5、JVM 分析&调优
jvm 调优,调的是稳定,并不能带给你性能的大幅提升。服务稳定的重要性就不用多说了,保证服务的稳定,gc 永远会是 Java 程序员需要考虑的不稳定因素之一。复杂和高并发下的服务,必须保证每次 gc 不会出现性能下降,各种性能指标不会出现波动,gc 回收规律而且
干净,找到合适的 jvm 设置。Full gc 最会影响性能,根据代码问题,避免 full gc 频率。可以适当调大年轻代容量,让大对象可以在年轻代触发 yong gc,调整大对象在年轻代的回收频次,尽可能保证大对象在年轻代回收,减小老年代缩短回收时间;
1、几个常用工具
jstack 查看 jvm 线程运行状态,是否有死锁现象等等信息
jinfo 可以输出并修改运行时的 java 进程的 opts。
jps 与 unix 上的 ps 类似,用来显示本地的 java 进程,可以查看本地运行着几个 java程序,并显示他们的进程号。
jstat 一个极强的监视 VM 内存工具。可以用来监视 VM 内存内的各种堆和非堆的大小及其内存使用量。
jmap 打印出某个 java 进程(使用 pid)内存内的所有’对象’的情况(如:产生那些对象,及其数量)
2、命令示例
jstat 工具特别强大,有众多的可选项,详细查看堆内各个部分的使用量,以及加载类的数量。使用时,需加上查看进程的进程 id,和所选参数。
jstat -class pid 显示加载 class 的数量,及所占空间等信息
jstat -compiler pid 显示 VM 实时编译的数量等信息。
jstat -gc pid 可以显示 gc 的信息,查看 gc 的次数,及时间
jstat -gccapacity pid 堆内存统计,三代(young,old,perm)内存使用和占用大小
jstat -gcnew pid 新生代垃圾回收统计
jstat -gcnewcapacity pid 新生代内存统计
jstat -gcold pid 老年代垃圾回收统计
除了以上一个参数外,还可以同时加上 两个数字,如:jstat -printcompilation 3024 250 6 是每 250 毫秒打印一次,一共打印 6 次,还可以加上-h3 每三行显示一下标题。
jstat -gcutil pid 1000 100 : 1000ms 统计一次 gc 情况统计 100 次;
在使用这些工具前,先用 JPS 命令获取当前的每个 JVM 进程号,然后选择要查看的 JVM。
jinfo 是 JDK 自带的命令,可以用来查看正在运行的 java 应用程序的扩展参数,包括 JavaSystem 属性和 JVM 命令行参数;也可以动态的修改正在运行的 JVM 一些参数。当系统崩溃时,jinfo 可以从 core 文件里面知道崩溃的 Java 应用程序的配置信息.
jinfo pid 输出当前 jvm 进程的全部参数和系统属性
jinfo -flag name pid 可以查看指定的 jvm 参数的值;打印结果:-无此参数,+有
jinfo -flag [+|-]name pid 开启或者关闭对应名称的参数(无需重启虚拟机)
jinfo -flag name=value pid 修改指定参数的值
jinfo -flags pid 输出全部的参数
jinfo -sysprops pid 输出当前 jvm 进行的全部的系统属性
jmap 可以生成 heap dump 文件,也可以查看堆内对象分析内存信息等,如果不使用这个命令,还可以使用-XX:+HeapDumpOnOutOfMemoryError 参数来让虚拟机出现 OOM 的时候自动生成 dump 文件。
jmap -dump:live,format=b,file=dump.hprof pid
dump 堆到文件,format 指定输出格式,live 指明是活着的对象,file 指定文件名。eclipse 可以打开这个文件
jmap -heap pid
打印 heap 的概要信息,GC 使用的算法,heap 的配置和使用情况,可以用此来判断内存目前的使用情况以及垃圾回收情况
jmap -finalizerinfo pid 打印等待回收的对象信息
jmap -histo:live pid 打印堆的对象统计,包括对象数、内存大小等。jmap -histo:live 这个命令执行,JVM 会先触发 gc,然后再统计信息
jmap -clstats pid
打印 Java 类加载器的智能统计信息,对于每个类加载器而言,对于每个类加载器而言,它的名称,活跃度,地址,父类加载器,它所加载的类的数量和大小都会被打印。此外,包含的字符串数量和大小也会被打印。
-F 强制模式。如果指定的 pid 没有响应,请使用 jmap -dump 或 jmap -histo 选项。此模式下,不支持 live 子选项。
jmap -F -histo pid
jstack 是 jdk 自带的线程堆栈分析工具,使用该命令可以查看或导出 Java 应用程序中线程堆栈信息。
jstack pid 输出当前 jvm 进程的全部参数和系统属性
3、调优项
官方文档:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html#BGBCIEFC
三、nginx动静分离
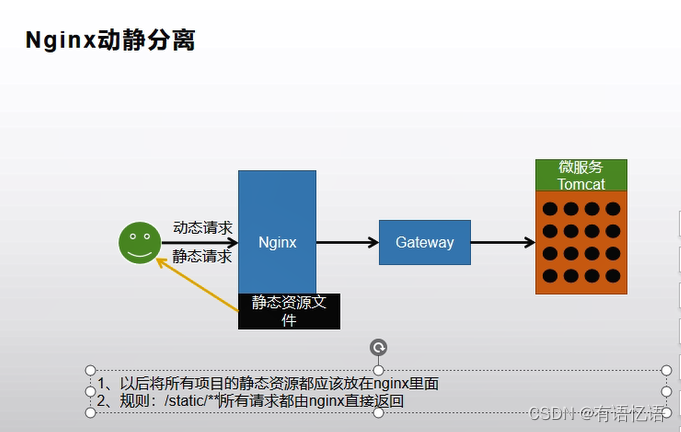
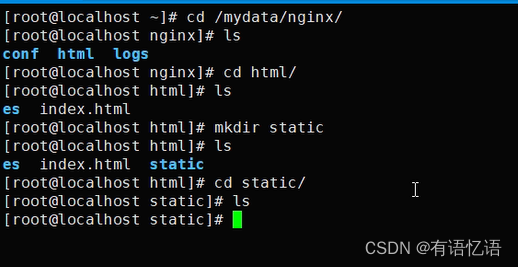
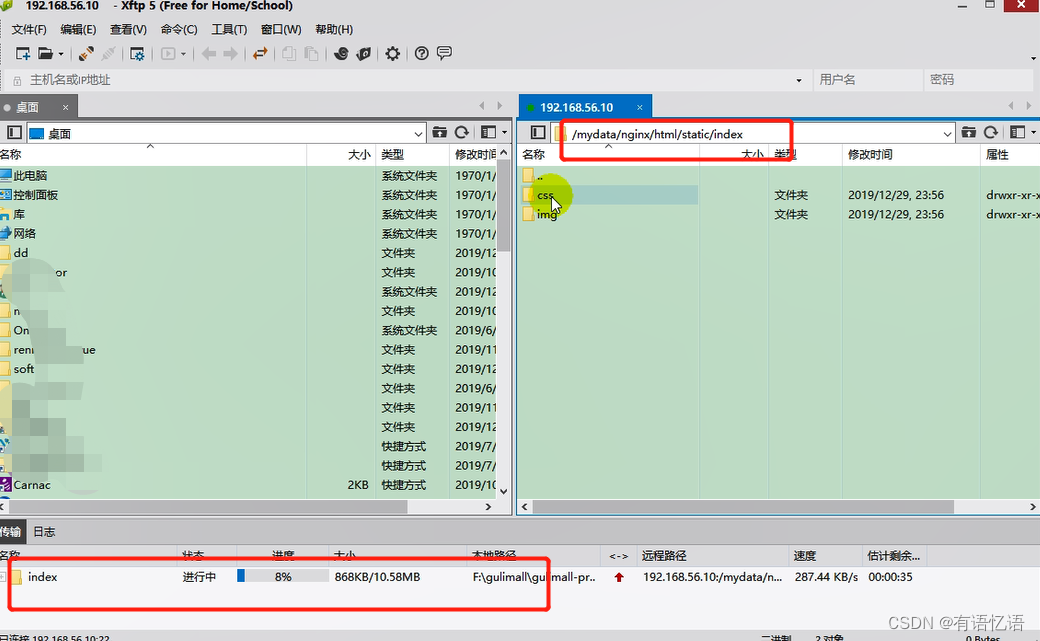
将自己项目里面的静态资源删除。
修改index.html的静态资源路径,加上/static/
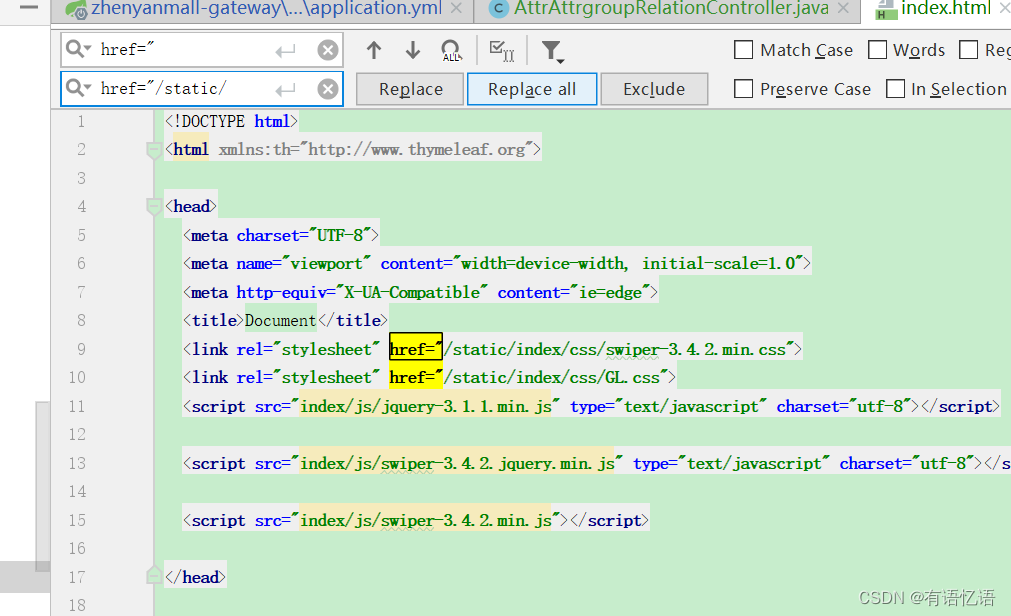
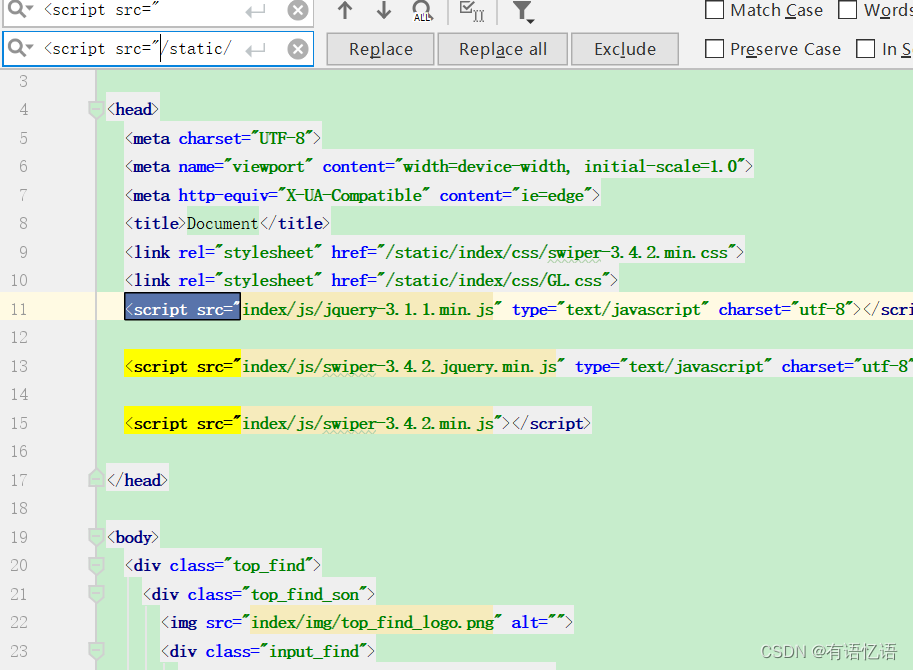
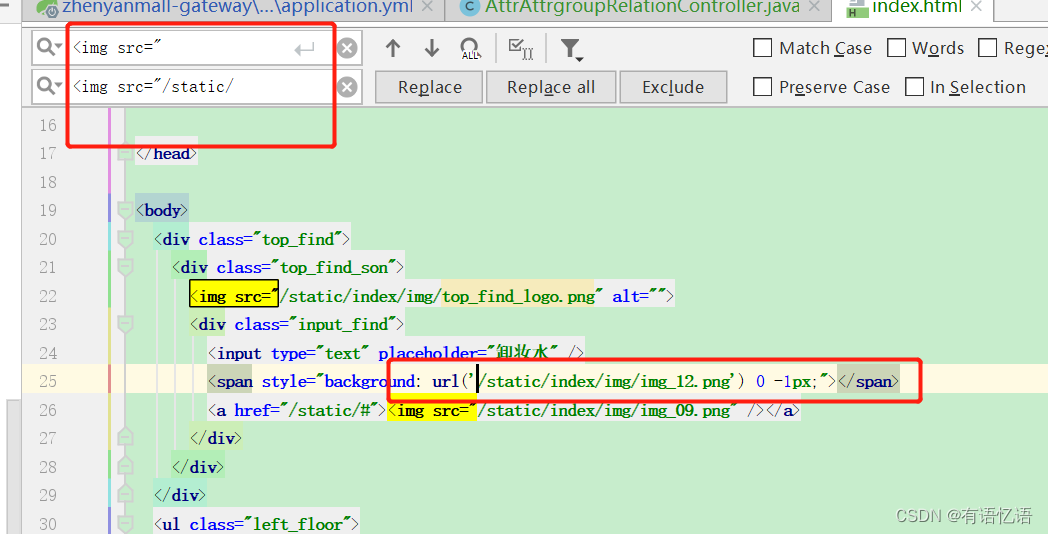
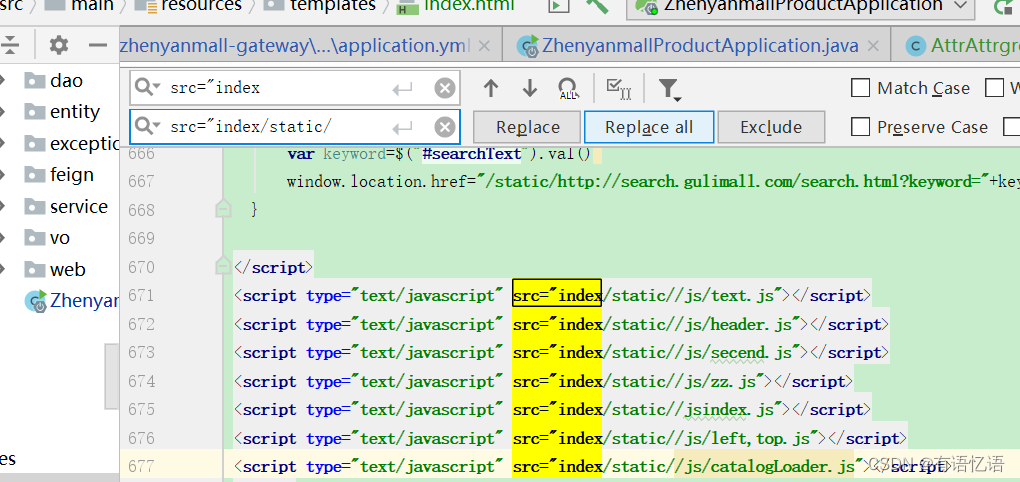
重启商品服务,访问首页,静态资源没有获取到。
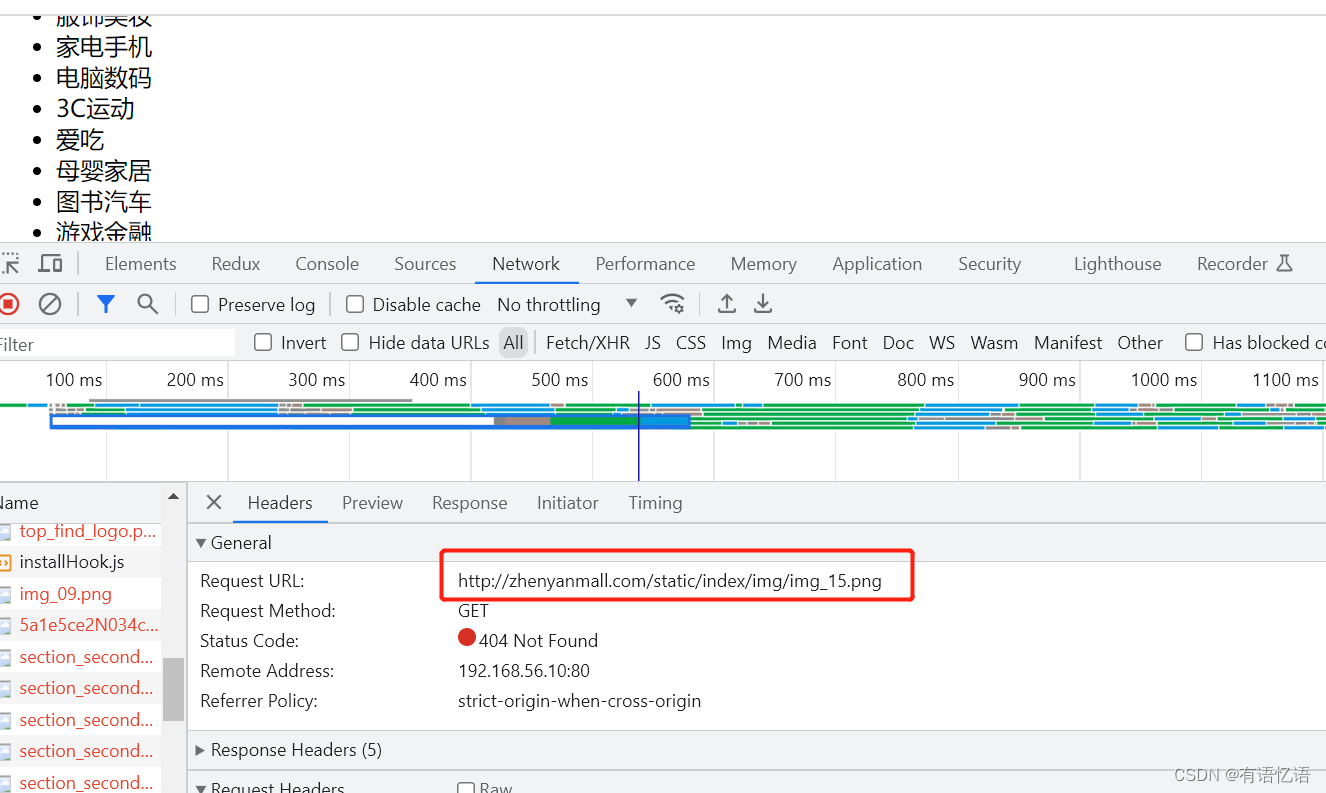
应该让nginx自己来找,因此需要修改nginx的配置。
根据之前配置的es中的分词器来看,从default.conf中可以看到,静态资源放到/usr/share/nginx/html,对应的挂载目录就是刚才index文件夹放的位置,因为所有的静态资源在static下,因此需要在zhenyanmall.conf中添加如下配置,即可找到静态资源。(刚才静态资源请求的路径是:http://zhenyanmall.com/static/index/img/img_15.png,根据域名解析,zhenyanmall.com到nginx服务器,当后面路径匹配到/static/时,使用根路径/use/share/nginx/html+/static/index/img/img_15.png 即可获取到图片)
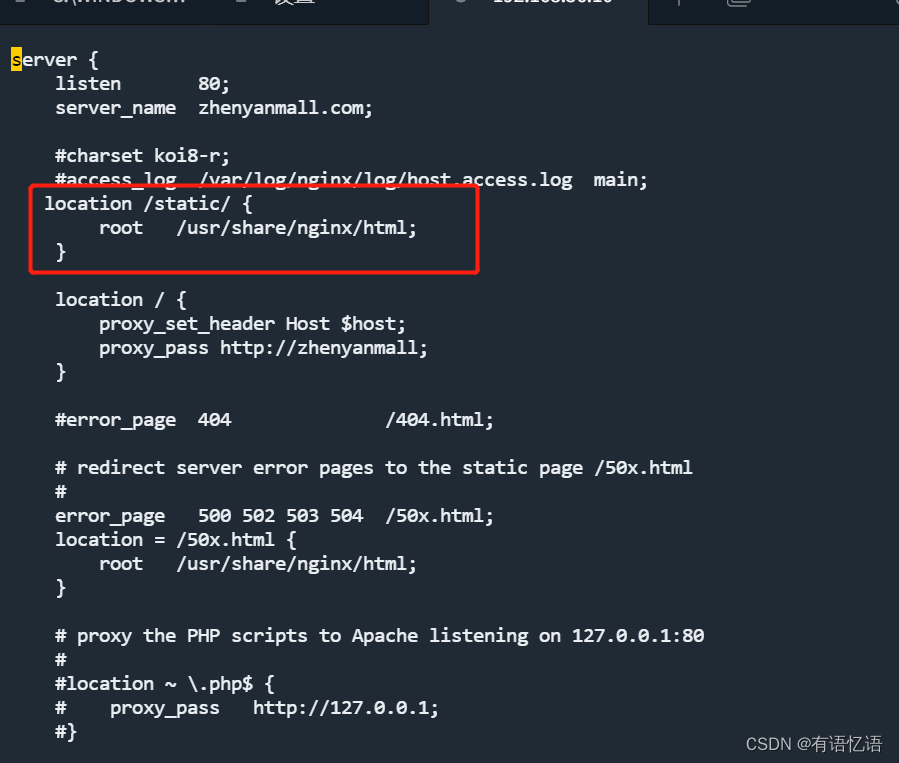
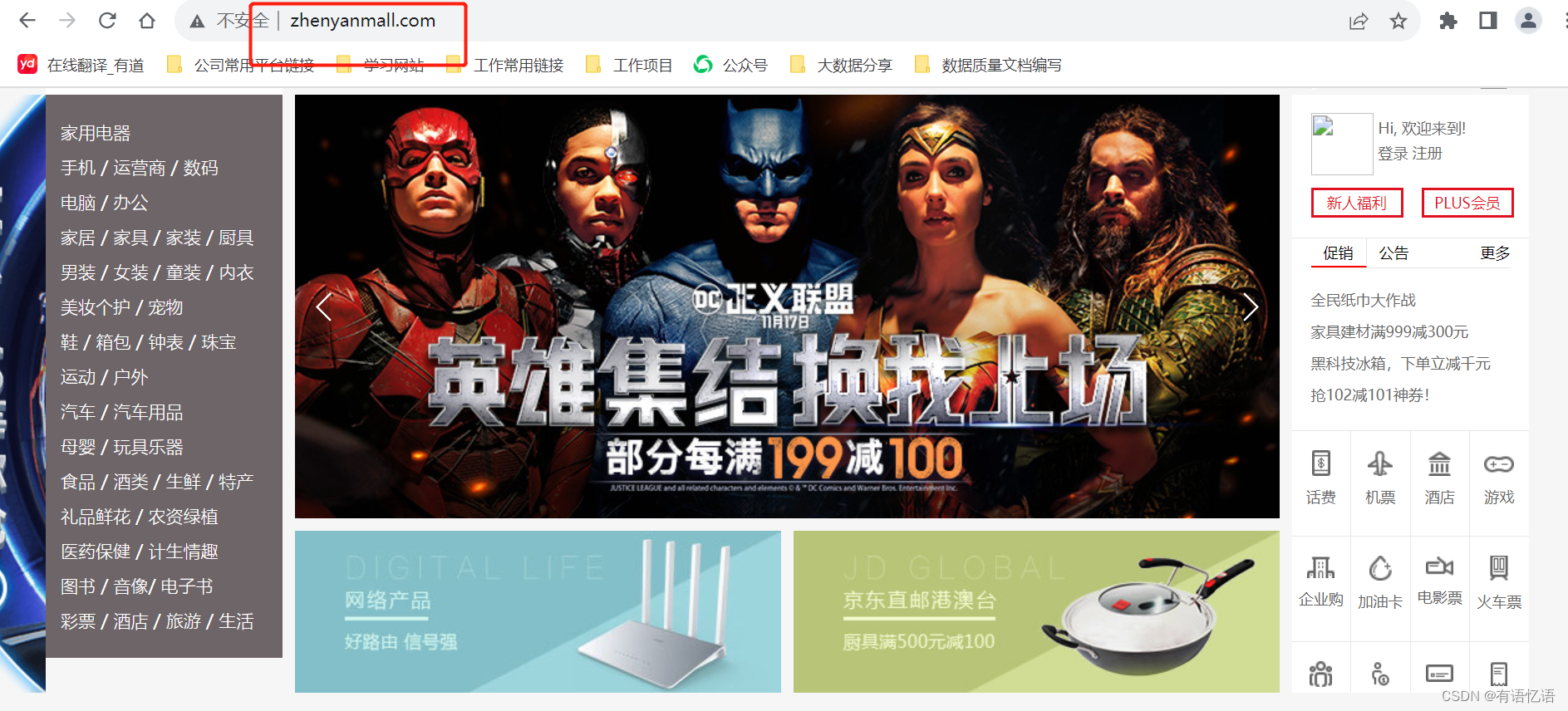
然后重新启动nginx,重新请求,即可访问静态资源。
四、模拟线上应用内存崩溃宕机情况
打开缓存
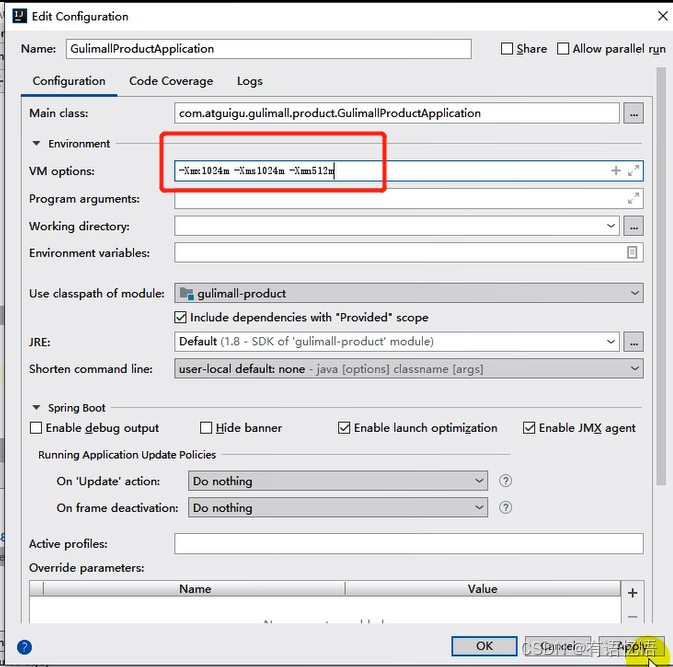
设置启动内存
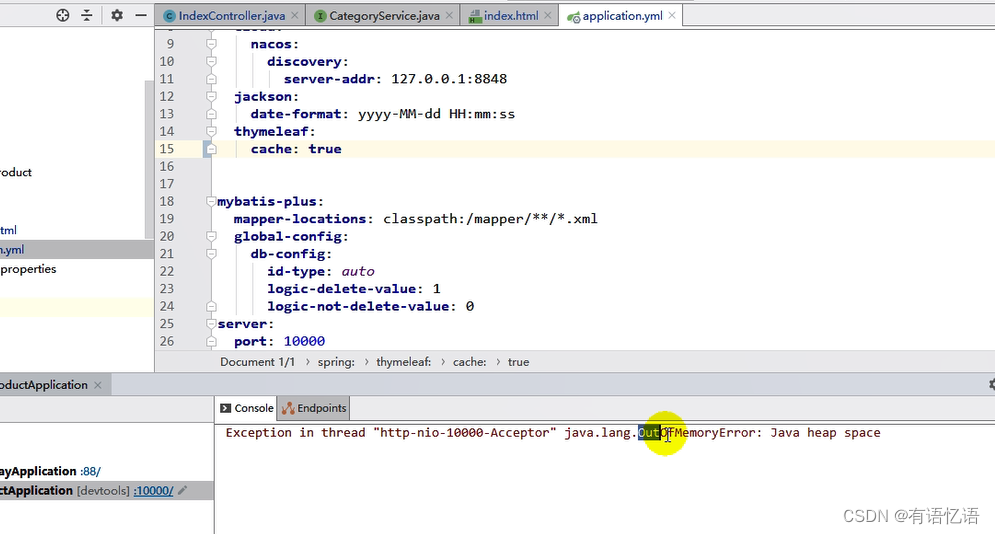
调用三级分类数据进行压力测试。

五、优化三级分类数据获取
1、将数据库多次查询变为一次
2、使用stream流
3、优化业务逻辑
4、也可以放到redis内存中查询的数据
六、缓存
1、本地缓存和分布式缓存
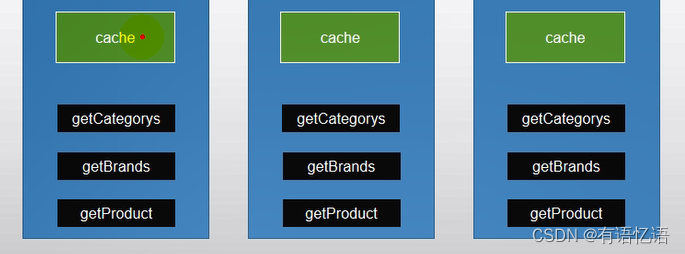
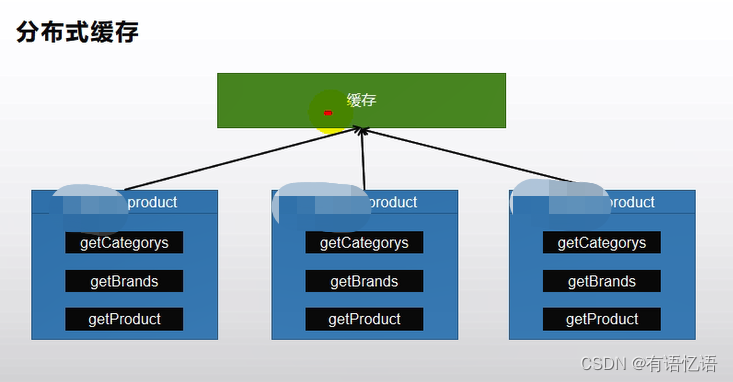
1、缓存使用
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落盘工作。
哪些数据适合放入缓存?
即时性、数据一致性要求不高的
访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
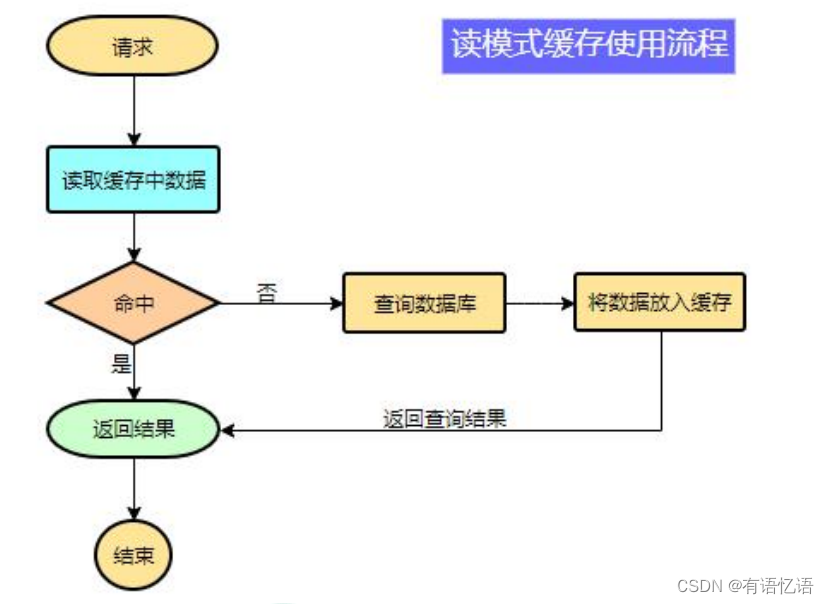
data = cache.load(id);//从缓存加载数据
If(data == null){
data = db.load(id);//从数据库加载数据
cache.put(id,data);//保存到 cache 中
}
return data;
注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。

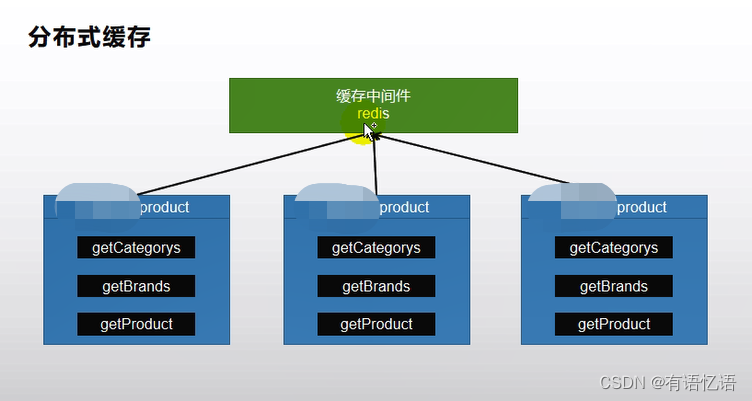
2、整合 redis 作为缓存
1、引入 redis-starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、配置 redis
spring:
redis:
host: 192.168.56.10
port: 6379
3、使用 RedisTemplate 操作 redis
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testStringRedisTemplate(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("hello","world_"+ UUID.randomUUID().toString());
String hello = ops.get("hello");
System.out.println(hello);
}
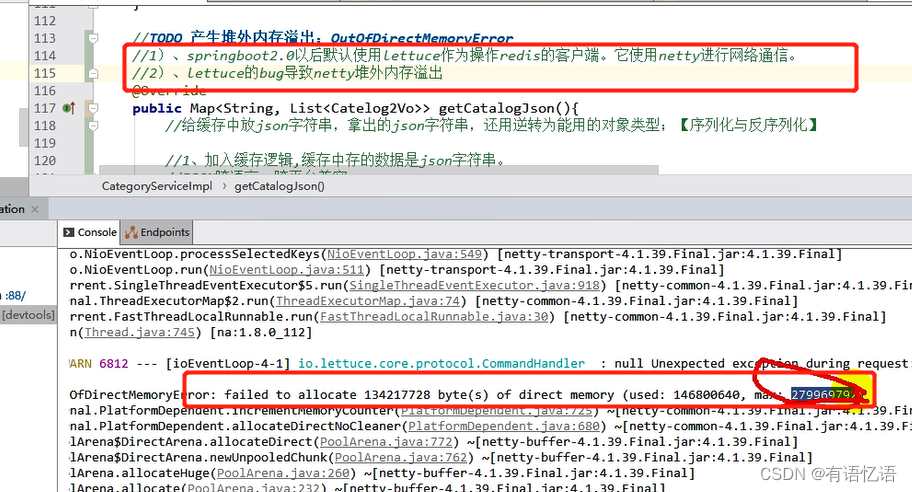
4、切换使用 jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
2、缓存失效问题
先来解决大并发读情况下的缓存失效问题;
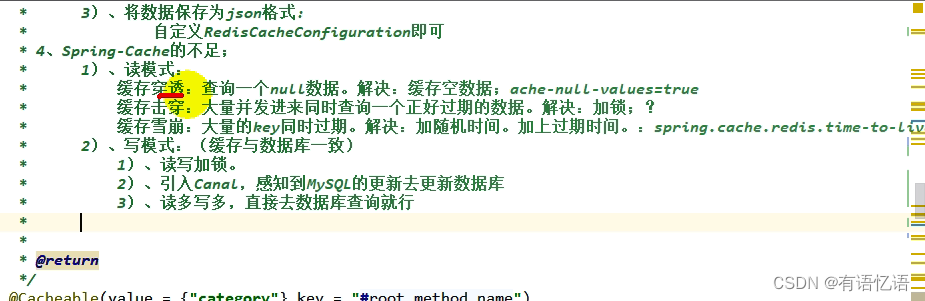
1、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决:
缓存空结果、并且设置短的过期时间。
2、缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决:
原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
3、缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决:
加锁
3、缓存数据一致性
1、保证一致性模式
1、双写模式
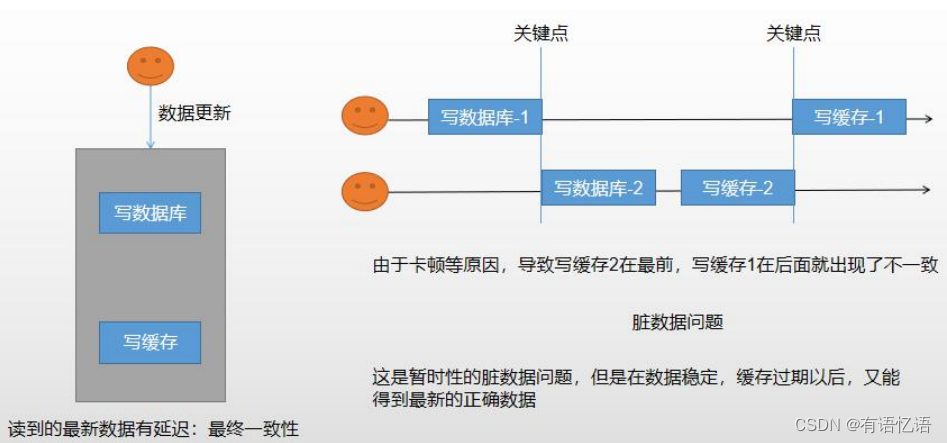
2、失效模式
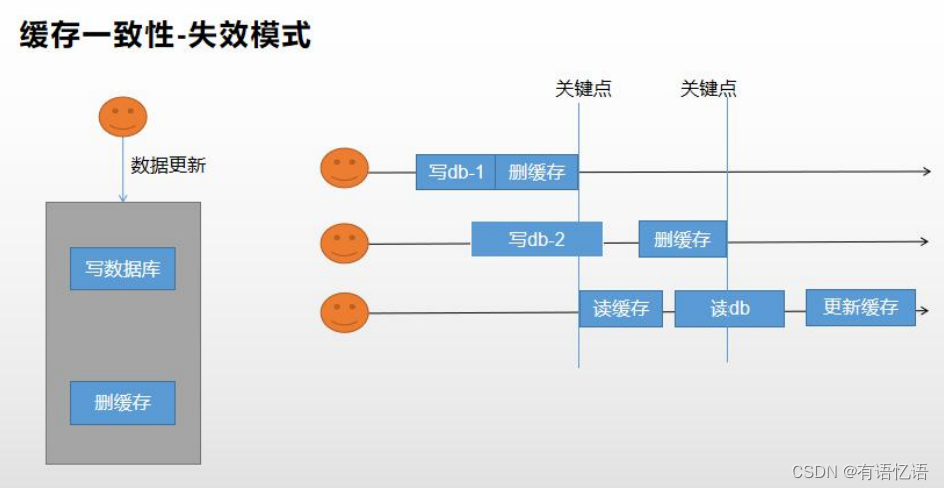
3、改进方法 1-分布式读写锁
分布式读写锁。读数据等待写数据整个操作完成
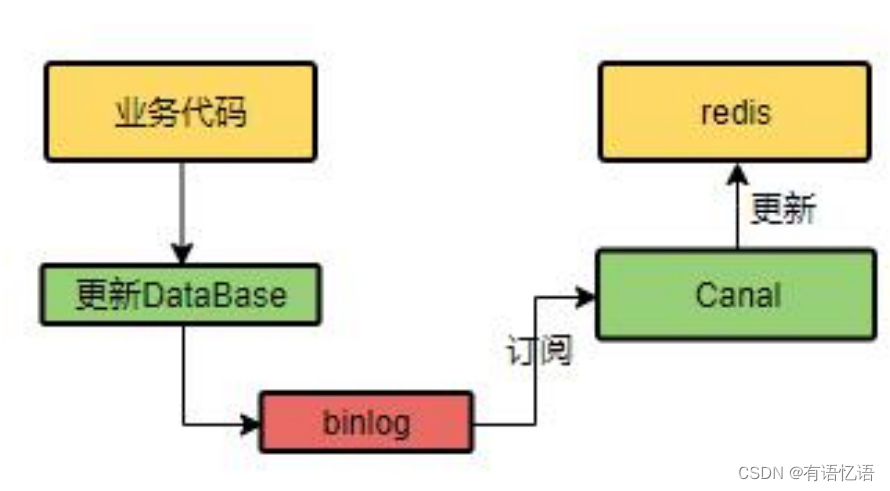
4、改进方法 2-使用 cananl
4、分布式锁
1、分布式锁与本地锁

2、分布式锁实现
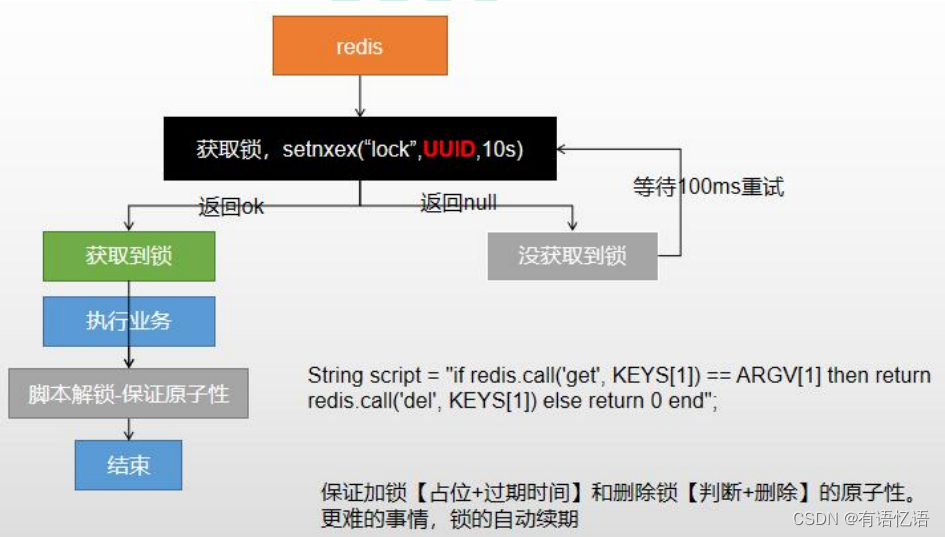
使用 RedisTemplate 操作分布式锁
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1、占分布式锁。去 redis 占坑
String uuid = UUID.randomUUID().toString();
Boolean lock =
redisTemplate.opsForValue().setIfAbsent("lock",uuid,300,TimeUnit.SECONDS);
if(lock){
System.out.println("获取分布式锁成功...");
//加锁成功... 执行业务
//2、设置过期时间,必须和加锁是同步的,原子的
//redisTemplate.expire("lock",30,TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDb;
try{
dataFromDb = getDataFromDb();
}finally {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1]) else return 0 end";
//删除锁
Long lock1 = redisTemplate.execute(new
DefaultRedisScript<Long>(script, Long.class)
, Arrays.asList("lock"), uuid);
}
//获取值对比+对比成功删除=原子操作 lua 脚本解锁
// String lockValue = redisTemplate.opsForValue().get("lock");
// if(uuid.equals(lockValue)){
// //删除我自己的锁
// redisTemplate.delete("lock");//删除锁
// }
return dataFromDb;
}else {
//加锁失败...重试。synchronized ()
//休眠 100ms 重试
System.out.println("获取分布式锁失败...等待重试");
try{
Thread.sleep(200);
}catch (Exception e){
}
return getCatalogJsonFromDbWithRedisLock();//自旋的方式
}
}

3、Redisson 完成分布式锁
1、简介
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。充分的利用了 Redis 键值数据库提供的一系列优势,基于 Java 实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
官方文档:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95
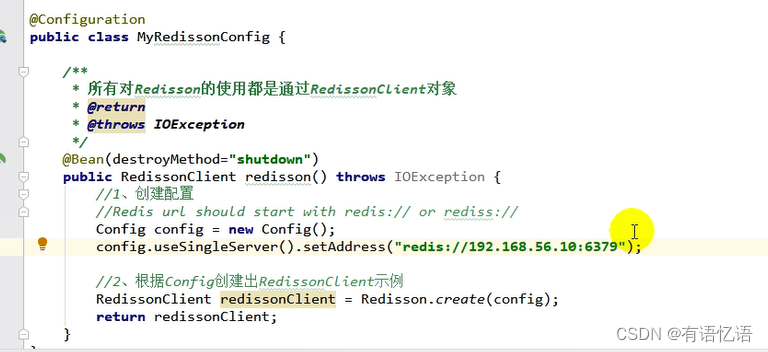
2、配置
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
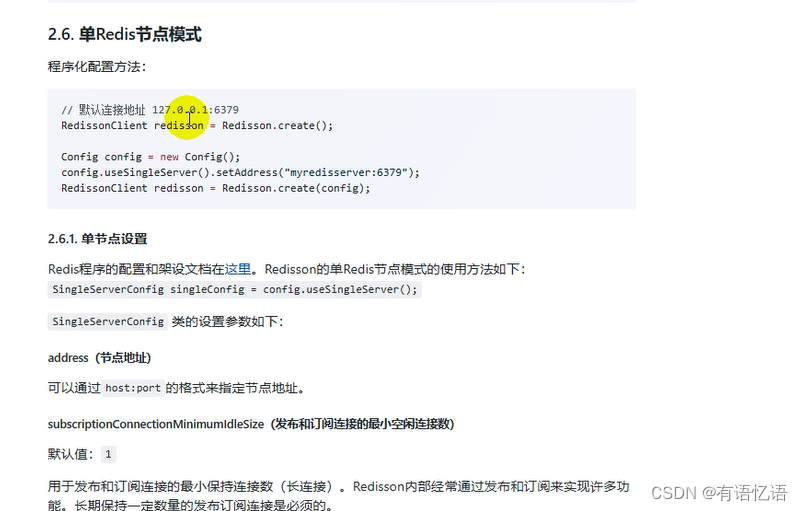
// 默认连接地址 127.0.0.1:6379
RedissonClient redisson = Redisson.create();
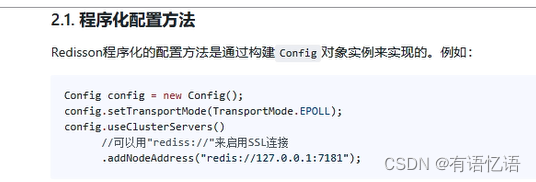
Config config = new Config();
//redis://127.0.0.1:7181
//可以用"rediss://"来启用 SSL 连接
config.useSingleServer().setAddress("redis://192.168.56.10:6379");
RedissonClient redisson = Redisson.create(config);
3、使用分布式锁
RLock lock = redisson.getLock("anyLock");// 最常见的使用方法
lock.lock();
// 加锁以后 10 秒钟自动解锁// 无需调用 unlock 方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待 100 秒,上锁以后 10 秒自动解锁 boolean res = lock.tryLock(100,
10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}

看门狗原理:1、业务运行期间,帮我们锁进行自动续期,2、为了防止死锁,加的锁默认30s过期时间,即使业务宕机,没有调用解锁代码,redis也会对他进行自动解锁。
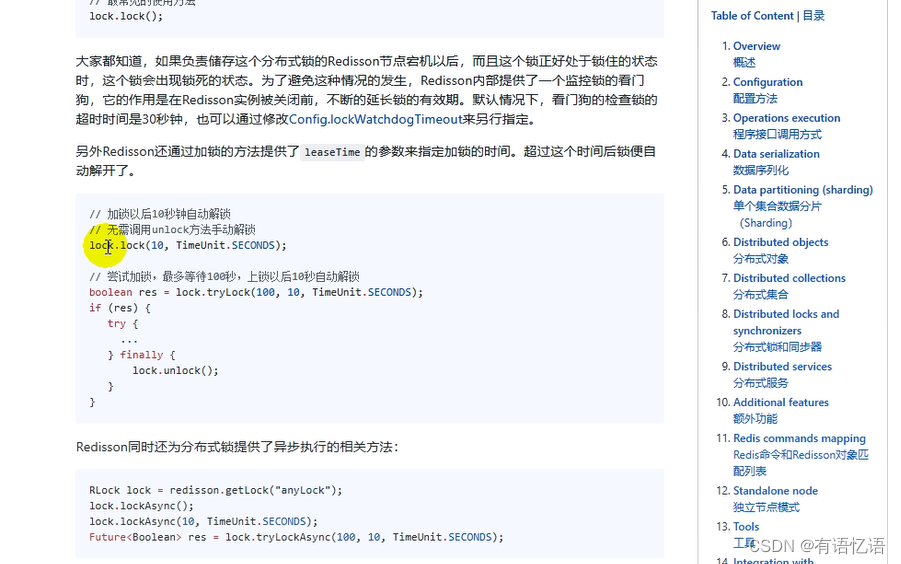
自动解锁时间,一定要大于业务的执行时间。

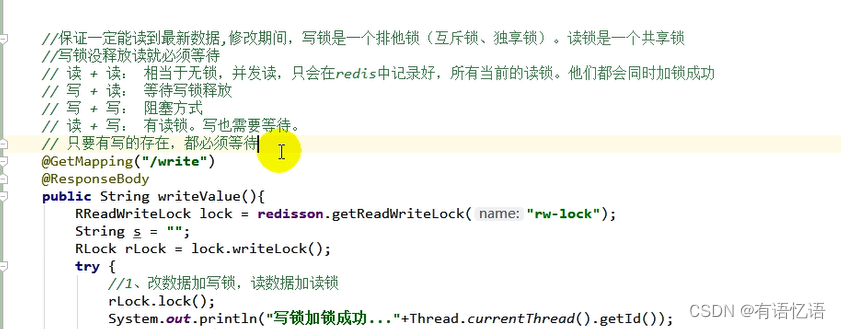
4、读写锁
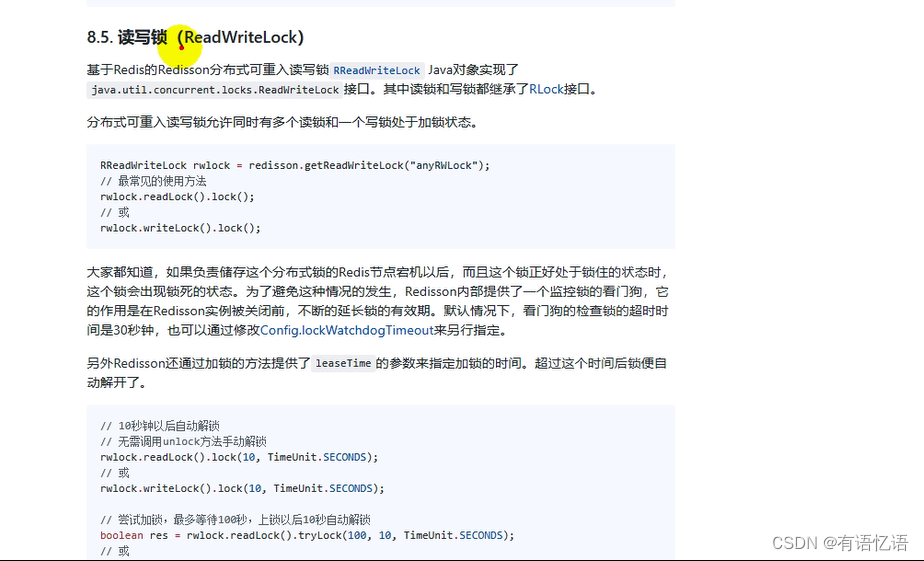
只要锁名一样就是同一把读写锁,业务要读的时候加读锁,业务要写的时候加写锁,如果别人正在修改数据,要读取最新数据,就要等待别人把写锁释放了,才可以读取数据,如果大家都是并发读,那么互不影响,并发写的话肯定需要一一排队,所以读写锁总是成对出现的。写锁控制了读锁,只要写锁存在,我的读锁就要等待。
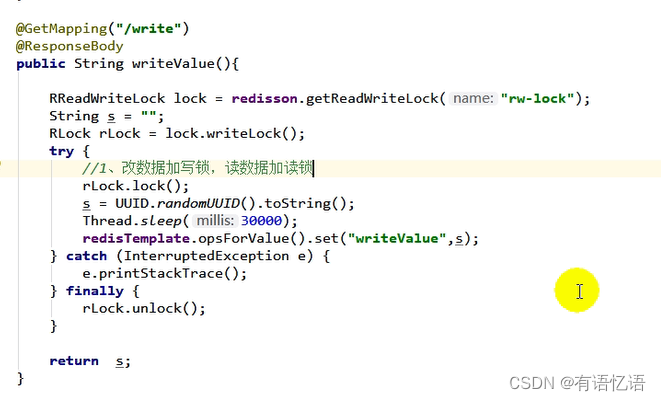
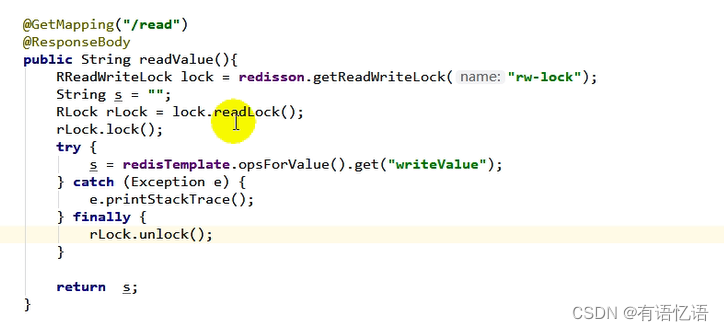
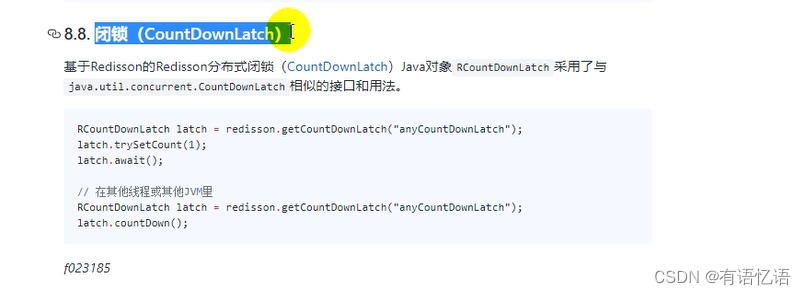
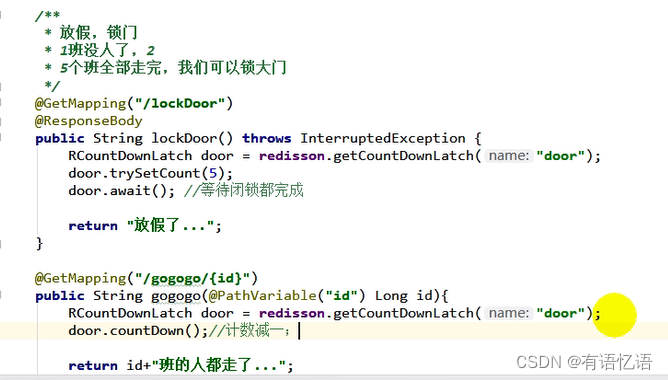
5、闭锁
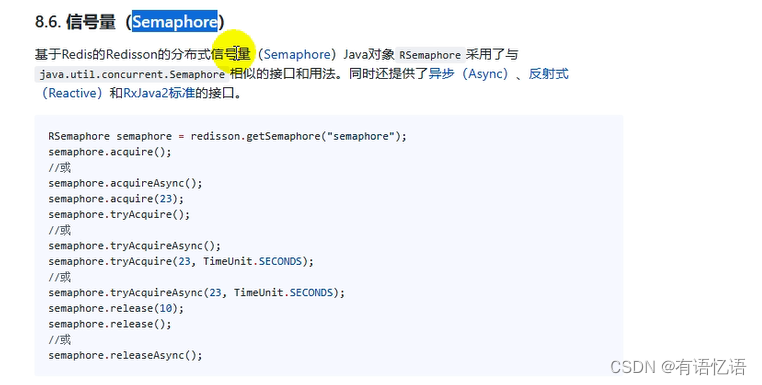
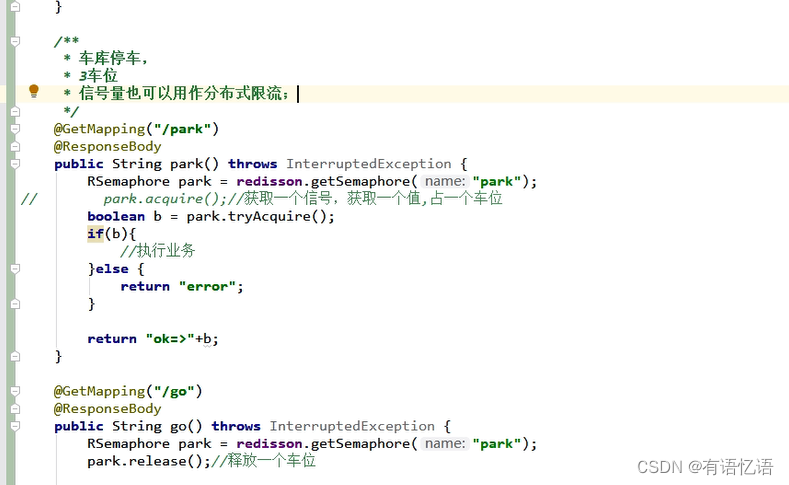
6、信号量

7、缓存一致性解决

最终一致性和强一致性:最终一致性就是今天修改了描述,明天看到结果也是一样的,实时性要求不搞。
强一致性,实时性要求比较高。
8、缓存一致性-解决-canel
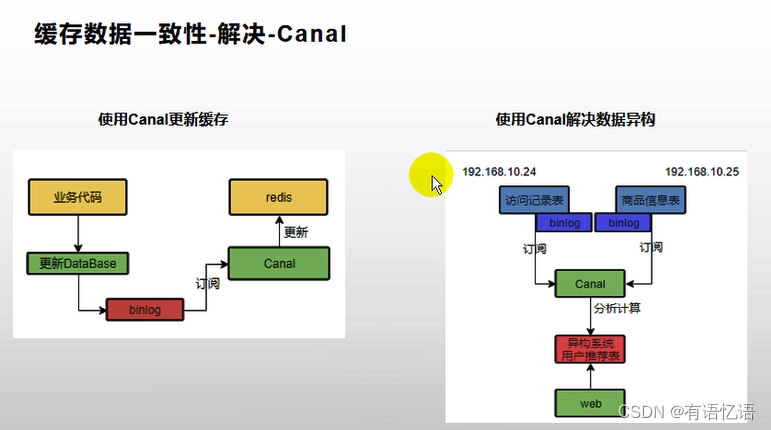
canel是阿里开源的一个中间件服务器,可以模拟是数据库的一个从服务器,从服务的特点就是,mysql里面有什么变化,从服务就会同步过去。
只要业务代码更新了数据库,我们的mysql数据库开启binlog,二进制日志,mysql什么东西更新了,canel就假装mysql的一个从库,mysql的每一更新都拿过去,然后再去redis更新对应的数据。这种好处,就是我们在编码期间,只需要改数据库就可以了,不用管缓存的任何操作,缺点就是又加了一个中间件,还要额外自定义一些功能,要对组件进行维护,好处就是一次开发成型,后面就不用管缓存这些事情了。
canel在大数据情况下,更是解决异构问题,大家去京东每一个人的首页都不同,首页推荐的商品都不一样,基于你的爱好,喜欢数码产品就推荐数码产品,喜欢衣服就推荐衣服。
比如数据库中,哪一个人浏览了哪些商品,有一个商品记录表,库里面也有一些商品信息表,购物车里面有购物车相关的表,只要给购物车里面添加了什么,我们都知道。
我们只要一进京东首页,推荐一些与我相关,感兴趣的商品:我们可以使用cannel,实时的订阅我们访问的记录表,也订阅一些商品信息表,这样cannel就知道有哪些商品,哪些访问记录,然后通过这些东西做一些分析计算,生成另外一张表,用户推荐表,canel把你每天的访问记录拿到,计算你喜欢的商品,因此只需要根据推荐表拿到当前感兴趣的商品即可。
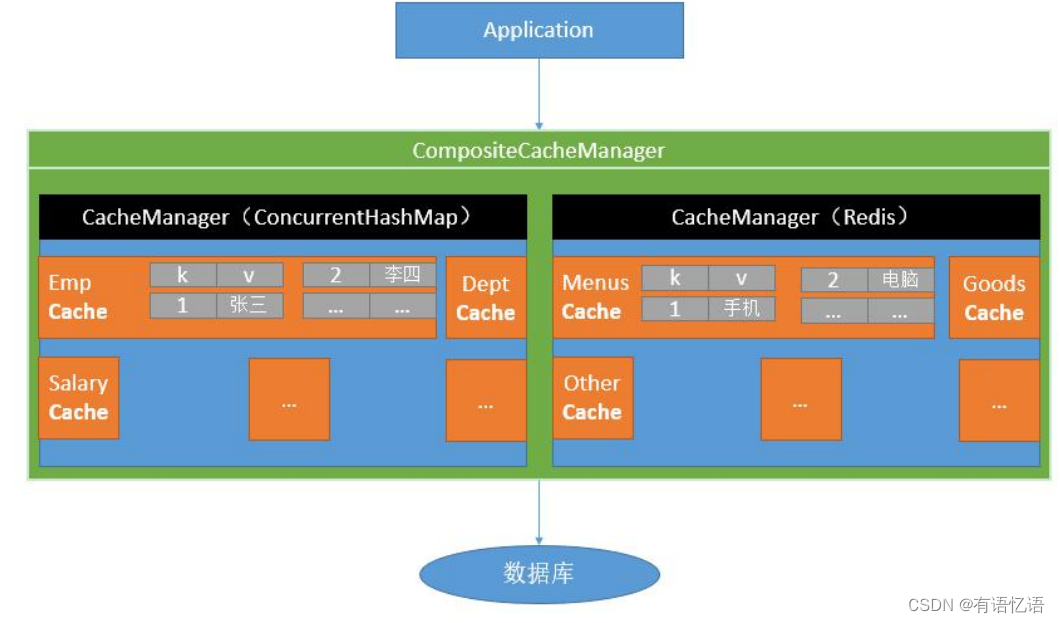
七、Spring cache
1、简介
Spring 从 3.1 开始定义了 org.springframework.cache.Cache
和 org.springframework.cache.CacheManager 接口来统一不同的缓存技术;
并支持使用 JCache(JSR-107)注解简化我们开发;
Cache 接口为缓存的组件规范定义,包含缓存的各种操作集合;
Cache 接 口 下 Spring 提 供 了 各 种 xxxCache 的 实 现 ; 如 RedisCache , EhCacheCache , ConcurrentMapCache 等;
每次调用需要缓存功能的方法时,Spring 会检查检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
使用 Spring 缓存抽象时我们需要关注以下两点;
1、确定方法需要被缓存以及他们的缓存策略
2、从缓存中读取之前缓存存储的数据
2、基础概念
3、注解
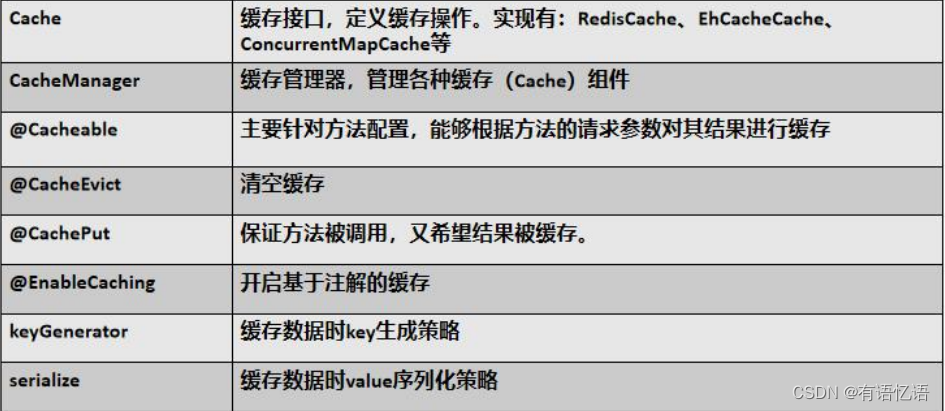

4、表达式语法

5、缓存穿透问题解决
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
允许 null 值缓存

@EnableCaching
只需要使用注解即可完成缓存操作。
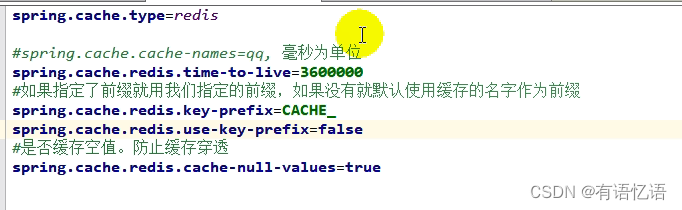
在application.properties中添加配置:spring.cache.type=redis

缓存自定义配置:








![[每周一更]-(第59期):31条MySQL数据库优化方案](https://img-blog.csdnimg.cn/ddb57fa0260a45d1b665b16321af3120.jpeg#pic_center)