文章目录
- MySQL基本使用
- 安装
- RDBMS
- 使用Navicat
- 新建数据库
- 新建查询--即代码运行的地方
- 运行代码
- 表的操作
- 命令行连接
- 数据完整性
- 数据类型
- 约束
- SQL的基础语法特性:
- SQL语句的分类
- DDL库管理
- DDL表管理:
- DML(增删改)
- 新增
- 删除
- 更新
- DQL(查)
- DQL基础查询
- as 取别名
- 消除重复行 distinct
- where详解(比较运算符和逻辑运算符见删除)
- 模糊查询
- 范围查询
- 空判断
- 优先级
- DQL分组
- group by + 聚合函数
- group by + group_concat()
- group by + having
- group by + with rollup
- 窗口函数(8.0新增)
- 排序分页
- 连接查询
- 内连接
- 左连接-右连接
- 自连接
- 子查询
- 查询总结
- 备份
- 恢复
- 数据库设计--三范式
- 第一范式
- 第二范式
- 第三范式
- MySQL和Python的交互
- pymysql 下载
- 基础代码结构
- 增删改
- 查询
- 一行一行返回处理
- 多行数据
- SQL传参
- SQL语句参数化
MySQL基本使用
安装
链接
链接
远程连接的时候:

然后去对应的安全组把对应的端口号打开,即可
几步验证,命令行内输入mysql -u root -p 然后输入密码,接着,看一下远程连接是否打开:
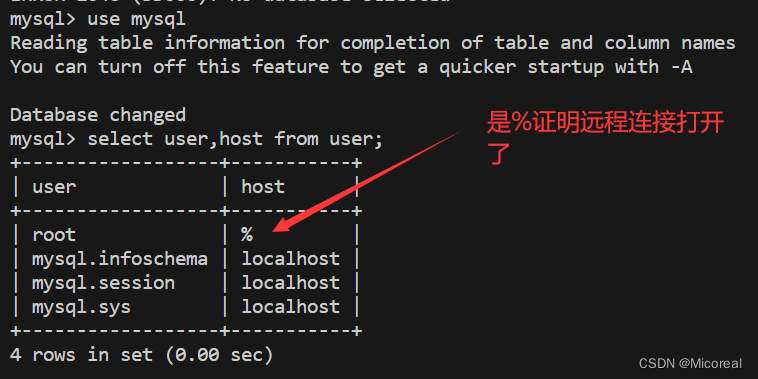
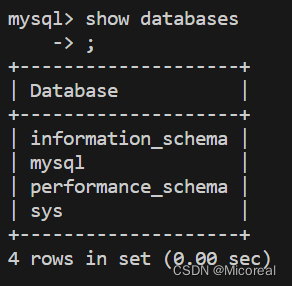
然后show databases 看一下最基本的数据库,那四个是不能删掉的
对于mysql来说默认监听的端口是3306号端口
RDBMS
Relational Database Management System
通过表来表示关系型
- 当前主要使用两种类型的数据库:关系型数据库、非关系型数据库,本部分
主要讨论关系型数据库,对于非关系型数据库会在后面学习 - 所谓的关系型数据库 RDBMS,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据
- 关系型数据库的主要产品:
– oracle:在以前的大型项目中使用,银行,电信等项目
– mysql:web 时代使用最广泛的关系型数据库
– ms sql server:在微软的项目中使用
– sqlite:轻量级数据库,主要应用在移动平台
使用Navicat
新建数据库
右键点击,然后选择新建数据库
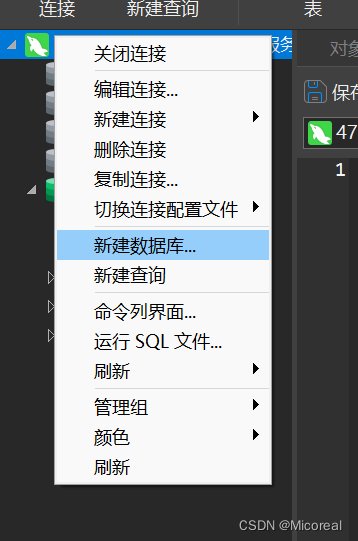
这是我自己需求的数据库的编码什么的,自行定义,一般这些不重要
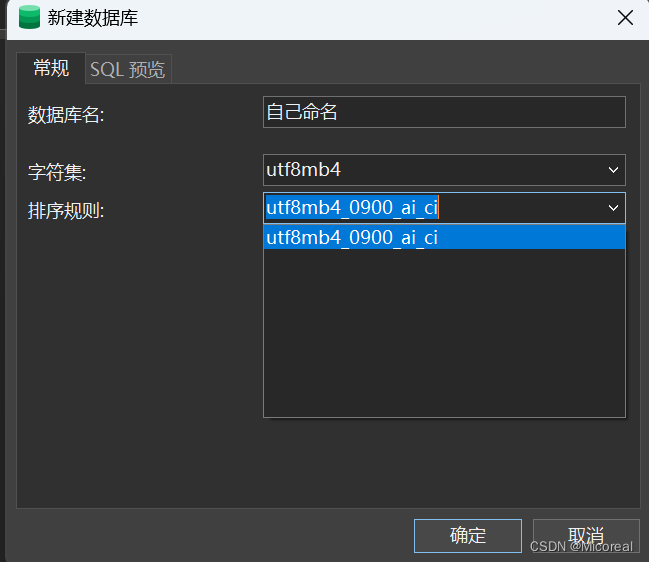
点击确定之后就创建成功。
新建查询–即代码运行的地方
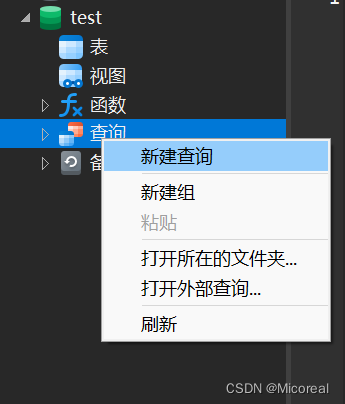
直接按ctrl-s保存,然后自己取个名字
然后之后代码就在这里面编写:

相同的也可以把文件拉进去
从你的window下可以直接拉进去,或者从服务器上拉出来进行浏览测试,不过每次操作之后需要进行刷新(跨服务器)。
运行代码
表的操作

等等都是比较可视化的操作,这里不赘述
当然很多都可以直接进行图形化操作,但是我们还是需要了解一下代码语句,有些公司,他的数据库是储存在内网之下的,自己访问数据需要通过web服务器传数据需求,然后再搬过来,就是他们的数据库储存的点你ping不通,就无法进行远程连接,此时对于这些代码的理解就十分重要了
命令行连接
登录
mysql -u root -p
输入你的密码
退出登录
quit 或 exit 或 ctrl+d
登录成功后,输入如下命令查看效果
查看版本:select version();
显示当前时间:select now();
后面绝大多数也会进行复用那篇文章,不过介绍更详细。
数据完整性
一个数据库就是一个完整的业务单元,可以包含多张表,数据被存储在表中,在表中为了更加准确的存储数据,保证数据的正确有效,可以在创建表的时候,为表添加一些强制性的验证,包括数据字段的类型、约束。
数据类型
常用数据类型如下:
– 整数:int,bit
– 小数:decimal
– 字符串:varchar,char
– 日期时间: date, time, datetime
– 枚举类型(enum)
补充链接
特别说明的类型如下:
- decimal 表示浮点数,如 decimal(5,2)表示共存 5 位数,小数占 2 位
- char 表示固定长度的字符串,如 char(3),如果填充’ab’时会补一个空格为’ab ’
- varchar 表示可变长度的字符串,如 varchar(3),填充’ab’时就会存储’ab’ – 字符串 text 表示存储大文本,当字符大于 4000 字节时推荐使用
- 对于图片、音频、视频等文件,不存储在数据库中,而是上传到某个服务器上,然后在表中存储这个文件的保存路径
约束
- 主键 primary key:物理上存储的顺序
- 非空 not null:此字段不允许填写空值
- 惟一 unique:此字段的值不允许重复
- 默认 default:当不填写此值时会使用默认值,如果填写时以此填写为准
- 外键foreign key:
对关系字段进行约束,当为关系字段填写值时,会到关联的表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并抛出异常 但是 虽然外键约束可以保证数据的有效性,但是在进行数据的 crud(增加、修改、删除、查询)时,都会降低数据库的性能,所以不推荐使用,那么数据的有效性怎么保证呢?答:可以在逻辑层进行控制 - auto_increment: 自动增加
补充:一般外键现在都是让用户在程序阶段进行排除,而非使用外键。
SQL的基础语法特性:
- SQL语言,大小写不敏感。
- SQL可以单行或者多行书写,最后以;结束
- SQL支持注释:
(1)单行注释:-- 注释内容(–之后需要有一个空格)
(2)单行注释:# 注释内容(#之后可加可不加空格,推荐加上)
(3)多行注释:/注释内容/
SQL语句的分类
数据定义:DDL(库的创建删除,表的创建删除等)
数据操纵:DML(新增数据,删除数据,修改数据等)
数据控制:DCL(新增用户,删除用户,密码修改,权限管理)
数据查询:DQL(基于需求查询和计算数据)
DDL库管理
| 管理函数 | 说明 |
|---|---|
| show databases; | 查看数据库 |
| use 数据库名称 | 使用数据库 |
| create database 数据库名称[charset UTF8] | 创建数据库 |
| drop database 数据库名称 | 删除数据库 |
| select database() | 查看当前使用的数据库 |
DDL表管理:
| 管理函数 | 说明 |
|---|---|
| show tables; | 查看有那些表,前提是先选择哪一个数据库 |
| drop table 表名称; | 删除表 |
| drop table if exists 表名称; | 删除表 |
| create 表名称(列名称 列类型 限制条件,列名称 列类型,限制条件······); | 创建一个新表 |
| desc 表名称 | 查询这个表的每个行名的属性(后面会使用) |
| alter table 表名 add 列名 类型 [约束] | 修改表添加字段 |
| alter table 表名 change 原名 新名 类型及约束; | 修改字段并且重命名,一般这种情况下,如果改变类型,此列原本所有的数据都会丢失。 |
| alter table 表名 modify 列名 类型及约束; | 修改字段不重命名版,同样注意数据丢失现象 |
| alter table 表名 drop 列名; | 删除字段 |
| show create table 表名; | 查看这个表创建时的语句,一般用于在公司的时候看看别人创建的规范是什么,然后学习一下 |
| 列的类型 | 说明 |
|---|---|
| int | 整数 |
| decimal | 浮点数 |
| varchar(长度) | 文本,长度为数字(最大255),做最大长度限制 |
| date | 日期类型 |
| timestamp | 时间戳类型 |
| 部分条件 | 说明 |
|---|---|
| auto_increment | 自动增长,一般用于id类的,就是我们再最开始设置一个id为1的数据,后面就会自动生成下一个 |
| Primary Key | 是数据库表中用于唯一标识每一行数据的列或一组列。它的特点是唯一性和非空性,即每个主键值必须是唯一的且不能为空。主键用于确保数据的完整性和一致性,同时也用于快速查找和访问数据。在创建表时,可以指定一个或多个列作为主键,或者使用自增长的整数作为主键。 |
| DEFAULT ’ ’ | 没有初始化的时候的默认值,如果enum需要默认值,直接填default ‘保密’即可 |
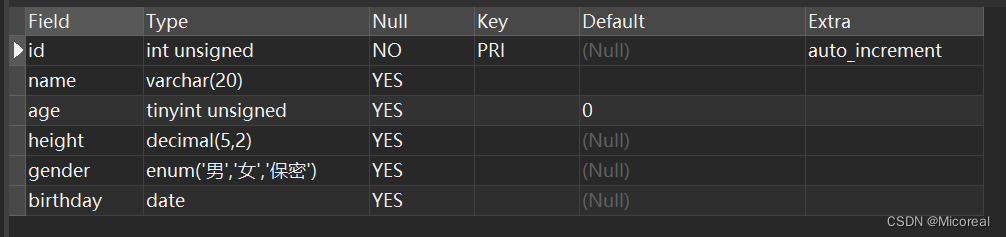
示例:
先创建一个表:
CREATE TABLE students(
`id` int unsigned primary KEY auto_increment NOT NULL,
`name` VARCHAR(20) DEFAULT '',
`age` TINYINT UNSIGNED DEFAULT 0,
`height` DECIMAL(5,2),
`gender` enum('男','女','保密'),
`birthday` DATE
);
此时使用:
desc students;
DML(增删改)
新增
# 数据插入
insert into 表名称[(列1,列2······)] values(值1,值2······)[,(值1,值2······),······];
# 解释
# 方式1:全列插入:值的顺序与表中字段的顺序对应,此种情况下,所有值都需要填写,只有含有default在最后面才不需要填写
insert into 表名 values(...)
例:
insert into students values(0,'郭靖',1,181,1,20,'2016-1-2')[(这边可以填写第二个新增的信息)];
# 方式2:部分列插入:值的顺序与给出的列顺序对应
insert into 表名(列 1(字段1),...) values(值 1,...)[(这边可以填写第二个新增的信息)];
例:
insert into students(name,birth) values('黄蓉','2016-3-2');
而对于新增的东西是一张别的表的内容的时候就不需要进行取value,这边看不懂可以先往后看,后面再回来看就懂了
insert into goods_cates (name) (select cate_name from goods group by cat
e_name);
删除
# 数据删除
# 条件判断操纵符:= 、!=(<>也表示不等于,不等于一般是全盘扫描极度低效,一般别用)、<、<=、>、>=
# 值得关注的是是 = 不是 ==。
# 相同的也有逻辑运算符 and or not(一般来说not别用)
# 如果不存在条件判断,则是将表当中的数据全部删除。
delete from 表名称[where 条件判断];
# 解释
delete from students where id=5;
#补充: 逻辑删除,本质就是修改操作
# 对于重要数据,并不希望物理删除,一旦删除,数据无法找回
# 删除方案:设置 isDelete 的列,类型为 bit,表示逻辑删除,默认值为 0
# 对于非重要数据,可以进行物理删除
# 数据的重要性,要根据实际开发决定
update students set isdelete=1 where id=1
更新
# 数据更新
# 如果不存在条件判断,则将整张表的所有列的值改变成相对应的修改值
updata 表名 set 列=值[where 条件判断];
例:
update students set gender=2 where id=5;
DQL(查)
DQL基础查询
# 基础查询
# *代表查询所有的内容
select 字段列表|* from 表 [where 条件判断]
# 解释
# 查询所有列
select * from 表名;
例:
select * from classes;
# 查询指定列
select 列 1,列 2,... from 表名;
例:
select id,name from classes
as 取别名
# 使用 as 给字段起别名,显示端讲name修改成名字字符串
select name as "名字" from students;
# 可以通过 as 给表起别名
-- 表名.字段名 代表的是哪张表的什么字段
select students.id,students.name,students.gender from students;
-- 可以通过 as 给表起别名
select s.id,s.name,s.gender from students as s;
消除重复行 distinct
# 在 select 后面列前使用 distinct 可以消除重复的行
select distinct 列 1,... from 表名;
例:
select distinct gender from students;
where详解(比较运算符和逻辑运算符见删除)
模糊查询
# like
# %表示零个或任意多个任意字符
# _表示一个 任意字符
例 7:查询姓黄的学生
select * from students where name like '黄%';
例 8:查询姓黄并且“名”是一个字的学生
select * from students where name like '黄_';
例 9:查询姓黄或叫靖的学生
select * from students where name like '黄%' or name like '%靖'
范围查询
in 和 between and
实际上使用不断的and也可以实现,只是太麻烦了OwO
# in 表示在一个非连续的范围内
例 10:查询编号是 1 或 3 或 8 的学生
select * from students where id in(1,3,8);
# between ... and ...表示在一个连续的范围内,闭区间
例 11:查询编号为 3 至 8 的学生
select * from students where id between 3 and 8;
例 12:查询编号是 3 至 8 的男生
select * from students where (id between 3 and 8) and gender=1;
空判断
# 注意:null 与''是不同的
# 判空 is null
例 13:查询没有填写身高的学生
select * from students where height is null;
# 判非空 is not null
例 14:查询填写了身高的学生
select * from students where height is not null;
例 15:查询填写了身高的男生
select * from students where height is not null and gender=1;
优先级
- 优先级由高到低的顺序为:小括号,not,比较运算符,逻辑运算符
- and 比 or 先运算,如果同时出现并希望先算 or,需要结合()使用。
DQL分组
group by + 聚合函数
# 分组聚合
# 聚合函数:
# sum(列) 求和
# avg(列) 求平均值
# min(列) 求最小值
# max(列) 求最大值
# count(列|*) 求数量
# 一个小的条件限制:字段仅能出现列出现的。
select 字段|聚合函数 from 表名称[where 判断条件] group by 列;
样例:
select gender,avg(age) from student group by gender;
输出:
| gender | group_concat(age) |
|---|---|
| 男 | 29,59,36,27,12 |
| 女 | 18,18,38,18,25,12,34 |
| 中性 | 33 |
| 保密 | 28 |
对于样例的理解:
- 按照gender分组,计算每一组的age的平均值。
- gender,avg(age) 代表输出的结果显示。
- 可以改成id,avg(age)吗?肯定是不行的,在select之后的列只能填组名列。
- count的理解 count(age)实际上是判断age是否为0,如果不为0,则加一,实际上我们count()当中写一个万能的即可,即count()。
group by + group_concat()
# group_concat(字段名) 将这一分组的所有字段名打印出来
样例:
select gender,group_concat(name) from students group by gender;
对于样例2的输出:
| gender | group_concat(name) |
|---|---|
| 男 | 张三 ,李四 |
| 女 | 小明,小月月,黄蓉,王祖贤,刘亦菲,静香,周杰 |
| 中性 | 金星 |
| 保密 | 凤姐 |
group by + having
# having 条件表达式:用来分组查询后指定一些条件来输出查询结果
# having 作用和 where 一样,但 having 只能用于 group by
select gender,count(*) from students group by gender having count(*)>2;
| gender | count(*) |
|---|---|
| 男 | 5 |
| 女 | 7 |
group by + with rollup
# with rollup 的作用是:在最后新增一行,来记录当前列里所有记录的总和,having 操作要放到 rollup 之后
# 样例1:
select gender,count(*) from students group by gender with rollup;
# 样例2:
select gender,group_concat(age) from students group by gender with rollup;
样例1输出:
| gender | count(*) |
|---|---|
| 男 | 5 |
| 女 | 7 |
| 中性 | 1 |
| 保密 | 1 |
| NULL | 14 |
样例2输出:
| gender | group_concat(age) |
|---|---|
| 男 | 29,59,36,27,12 |
| 女 | 18,18,38,18,25,12,34 |
| 中性 | 33 |
| 保密 | 28 |
| NULL | 29,59,36,27,12,18,18,38,18,25,12,34,33,28 |
窗口函数(8.0新增)
窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
# 窗口函数
<窗口函数> over (partition by <用于分组的列名>order by <用于排序的列名>)
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等
例子1(只加一列):
select *,
rank() over (partition by 班级 order by 成绩 desc) as ranking
from 班级表
例子2(增加多列):
select *,
rank() over (partition by cls_id order by age desc) as ranking,
dense_rank() over(partition by cls_id order by age desc) as dense_rank,
row_number() over(partition by cls_id order by age desc) as row_num from student
例子1出来的是按照班级分组,每个班级内按照成绩降序排列,并写出他的排名。
例子二(需要理解rank(),dense(),row_number()三种窗口函数之间的关系):
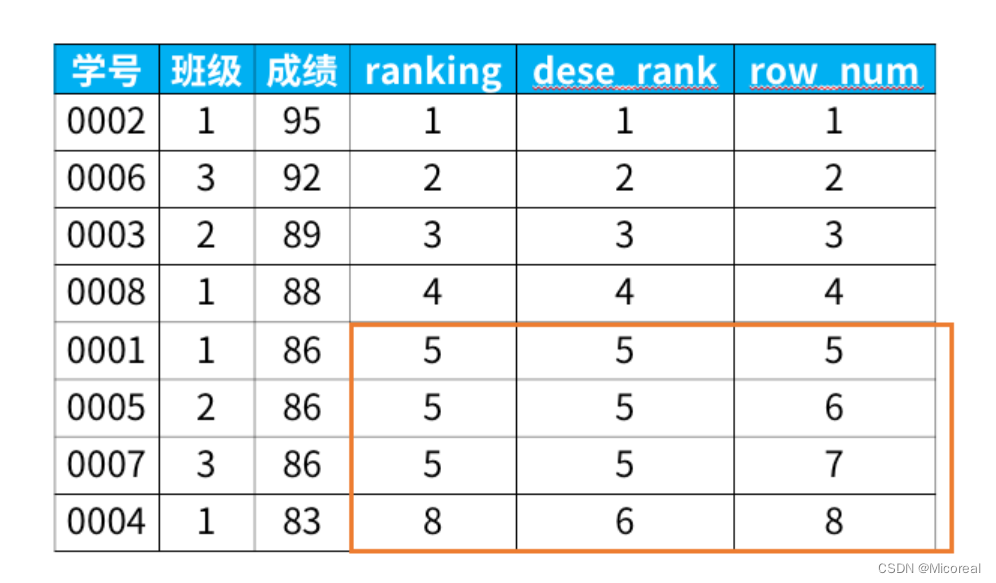
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
排序分页
# 排序
select 字段|聚合函数 from 表名称[where 判断条件] [group by 列] [order by ASC|DESC];
# 前面和正常的写法一样,爱怎么写,怎么写,最后面写上order by 标准[ASC|DESC]
# asc升序 ,DESC降序
select * from student order by age asc;
# 分页
# 再在后面加上limit n[,m]
# 如果是limit n代表仅从头取5条数据。
# 如果是limit n,m代表从n+1条开始取m条数据。
例子1:
select * from student order by age asc limit 2;
例子2:显示所有的学生信息,先按照年龄从大到小排序,当年龄相同时 按照身高从高到矮排序
select * from students order by age desc,height desc;
分页获取一般用于比如淘宝还是什么端获取信息。
求第 n 页的数据:
select * from students where is_delete=0 limit (n-1)*m,m
连接查询
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回。
mysql 支持三种类型的连接查询,分别为:
- 内连接查询:查询的结果为两个表匹配到的数据
- 右连接查询:查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用 null 填充
- 左连接查询:查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用 null填充
内连接
内连接拿到的是两个的交集部分
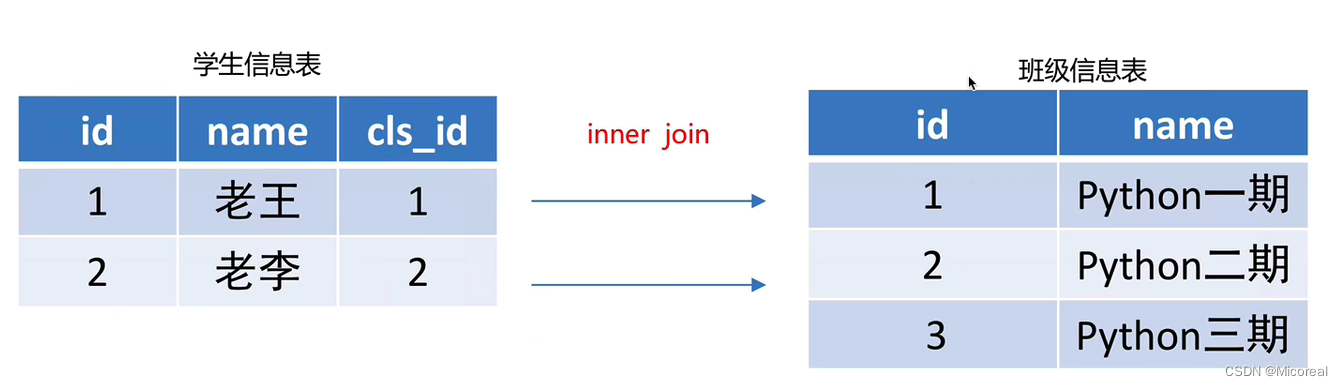
经过内连接之后:
| id | name | cls_id | id | name |
|---|---|---|---|---|
| 1 | 老王 | 1 | 1 | python一期 |
| 2 | 老李 | 2 | 2 | python二期 |
实际上做的事情就是在on的条件下,取相同的部分,不相同的舍弃
select 字段 from 表1 inner join 表2 on 表1.列 = 表2.列
例子1(不带别名):
select students.name,classes.name from students inner join classes on students.cls_id=classes.id;
例子2(带别名):
select s.name,c.name from classes as c inner join students as s on c.id=s.cls_id;
左连接-右连接
以左连接为例子:
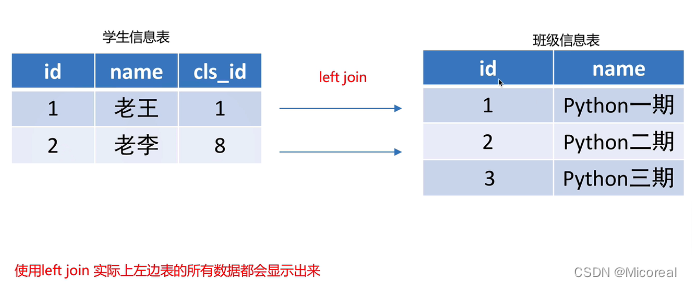
左连接实际上做的事情是以左边为主体,右边如果满足条件就连接起来,不满足显示null
| id | name | cls_id | id | name |
|---|---|---|---|---|
| 1 | 老王 | 1 | 1 | python一期 |
| 2 | 老李 | 8 | NULL | NULL |
左连接
select 字段 from 表1 left join 表2 on 表1.列 = 表2.列
右连接
select 字段 from 表1 right join 表2 on 表1.列 = 表2.列
自连接
自连接实际上使用的还是内连接的内容
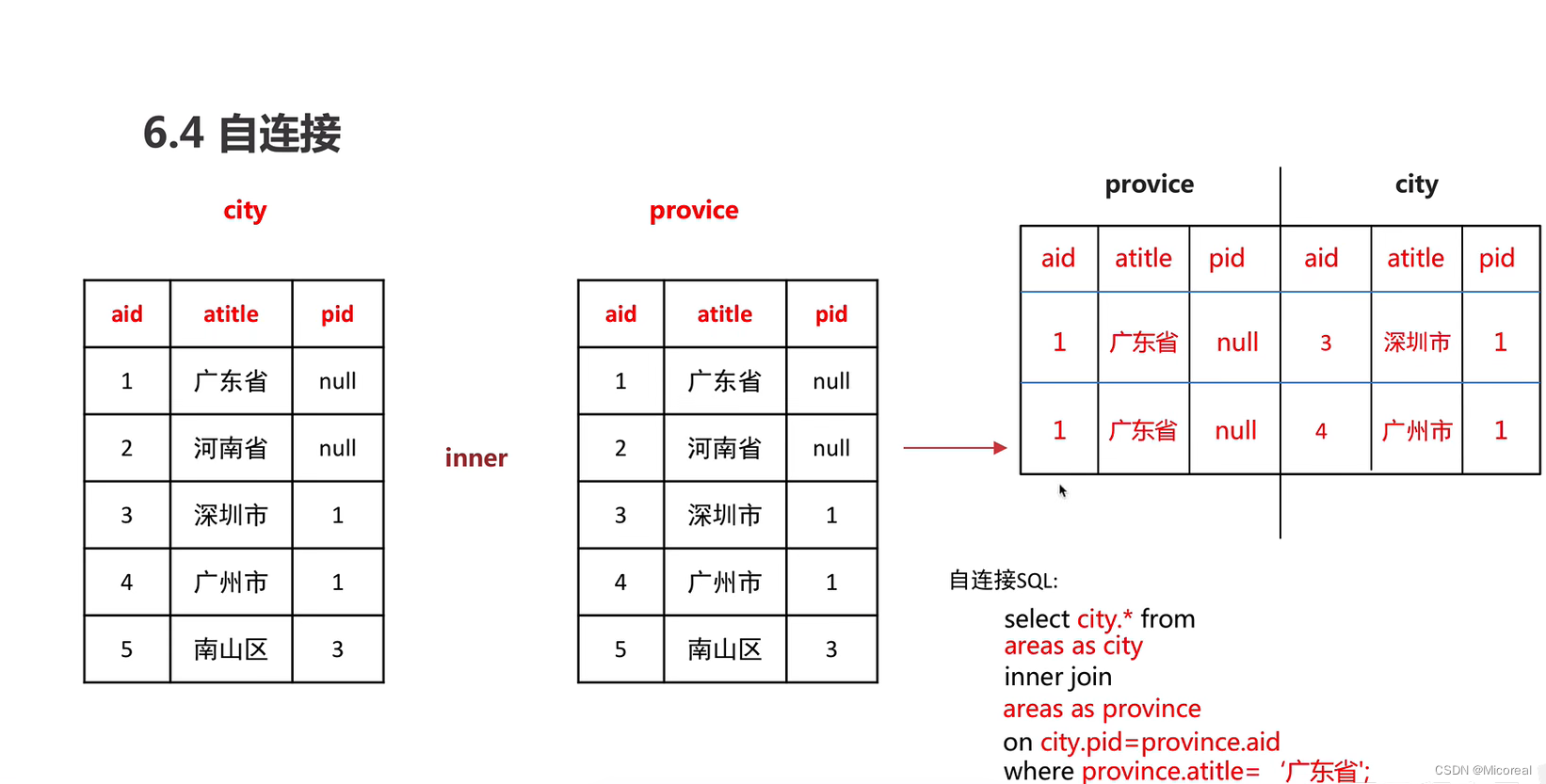
讲一下步骤流程(显示表中属于广东省的城市):
# 第一步:首先由于自连接,也就是自己连接自己,也就是说,我们表1表2都是自己,为了分辨,我们就需要取一个别名
areas as city inner join areas as province
# 第二步:其次判断条件,我们将两张表设置一张代表省份,一张代表城市,那么就需要城市的pid等于省份的aid
areas as city inner join areas as province on city.pid=province.aid
# 第三步:然后我们想要取出的是广东省的子城市,所以加上where
areas as city inner join areas as province on city.pid=province.aid where city.atitle='广东省'
# 最后补全想要显示的东西
select city.* areas as city inner join areas as province on city.pid=province.aid where city.atitle='广东省'
子查询
子查询:把一个查询的结果当作另一个查询的条件
子查询分为三类:
- 标量子查询:子查询返回的结果是一个数据(一行一列)
- 列子查询:返回的结果是一列(一列多行)
- 行子查询:返回的结果是一行(一行多列)
标量子查询 实际上就是把这个一行一列的东西当作一个值
1. 查询班级学生平均年龄
2. 查询大于平均年龄的学生
查询班级哪些学生的身高大于平均身高
select * from students where height > (select avg(height) fromstudents);
列级子查询 实际上就是把这个多行一列的东西当作一堆数据使用in进行包含即可
• 查询还有学生在班的所有班级名字
a. 找出学生表中所有的班级 id
b. 找出班级表中对应的名字
select name from classes where id in (select cls_id from students);
行级子查询 实际上就是把这个一行多列的东西当作一个元组
• 需求: 查找班级年龄最大,身高最高的学生
• 行元素: 将多个字段合成一个行元素,在行级子查询中会使用到行元素
select * from students where (height,age) = (select max(height),max(age)from students);
查询总结
SELECT select_expr [,select_expr,...] [FROM tb_name
[WHERE 条件判断]
[GROUP BY {col_name | postion} [ASC | DESC组也可以按照升序降序排列], ...]
[HAVING WHERE 条件判断]
[ORDER BY {col_name|expr|postion} [ASC | DESC], ...]
[LIMIT {[offset,]rowcount | row_count OFFSET offset}]
]
备份
事实上,对于厂家来说一般每个阶段(一天?两天,看数据用户量)都需要对于用户数据库进行一次备份,以免黑客强连造成损失数据,造成不可逆的影响。
在对应服务器上操作
# 第一步:运行 mysqldump 命令
mysqldump –u username -p dbname table1 table2 …>BackupName.sql
例如:
mysqldump -u root -p Python >python.sql
# 第二步
按提示输入 mysql的密码
其中,dbname参数表示数据库的名称;table1和table2参数表示表的名称,没有该参数时将备份整个数据库;BackupName.sql参数表示备份文件的名称,文件名前面可以加上一个绝对路径。通常将数据库备份成一个后缀名为.sql的文件。
恢复
# 第一步:连接 mysql,创建新的数据库
create database 数据库名称[charset UTF8]
# 第二步:退出连接
exit
# 第三步:
mysql -u root -p 新数据库名 < python.sql(注意数据库中必须存在对应的数据库名
称)
根据提示输入 mysql 密码
数据库设计–三范式
目前有迹可寻的共有 8 种范式,一般需要遵守 3 范式即可
第一范式
第一范式:强调的是列的原子性,即列不能够再分成其他几列。
例如:
考虑这样一个表:【联系人】(姓名,性别,电话) 如果在实际场景中,一个联系人有家庭电话和公司电话,那么这种表结构设计就没有达到 1NF。要符合 1NF 我们只需把列(电话)拆分,即:【联系人】(姓名,性别,家庭电话,公司电话)。
第二范式
第二范式:首先是满足第一范式的情况下,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
例如:
考虑一个订单明细表:【OrderDetail】(OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)。 因为我们知道在一个订单中可以订购多种产品,所以单单一个OrderID 是不足以成为主键的,主键应该(OrderID,ProductID)。显而易见 Discount(折扣),Quantity(数量)完全依赖(取决)于主键(OderID,ProductID),而 UnitPrice,ProductName 只依赖于 ProductID。所以 OrderDetail 表不符合 第二范式。不符合 第二范式 的设计容易产生冗余数据。
可以把【OrderDetail】表拆分为【OrderDetail】(OrderID,ProductID,Discount,Quantity)和【Product】(ProductID,UnitPrice,ProductName)来消除原订单表中 UnitPrice,ProductName 多次重复的情况。
第三范式
第三范式(第三范式):首先是 满足第二范式的情况下,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
例如:
考虑一个订单表【Order】(OrderID,OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity)主键是(OrderID)。 其中 OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity 等非主键列都完全依赖于主键(OrderID),所以符合 第二范式。不过问题是 CustomerName,CustomerAddr,CustomerCity 直接依赖的是CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 第三范式。
通过拆分【Order】为【Order】(OrderID,OrderDate,CustomerID)和【Customer】(CustomerID,CustomerName,CustomerAddr,CustomerCity)从而达到3NF。 *第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键点在于,第二范式:非主键列是否完全依赖于主键,还是依赖于主键的一部分;3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。
MySQL和Python的交互
前提:这边创建一个库仅供参考:
pymysql 下载
下载:
直接pip/conda install pymysql
基础代码结构
from pymysql import *
# 一般第一步都是创建一个连接
conn = connect(host='主机地址',user='root',password='密码',database='my_test',port=3306,charset='utf-8')
# 第二步创建cursor对象,之后都使用cursor进行操作
cs1 = conn.cursor()
# 传数据回去
str1 = cs1.execute('SQL语句')
# 提交之前的操作,如果之前已经之执行过多次的 execute,那么就都进行提交
conn.commit()
# 关闭 Cursor 对象
cs1.close()
# 关闭 Connection 对象
conn.close()
增删改
from pymysql import *
def main():
# 创建 Connection 连接
conn = connect(host='localhost',port=3306,database='jingdong',user='root',password='123',charset='utf8')
# 获得 Cursor 对象
cs1 = conn.cursor()
# 执行 insert 语句,并返回受影响的行数:添加一条数据
# 增加
count = cs1.execute('insert into goods_cates(name) values("硬盘")')
#打印受影响的行数
print(count)
count = cs1.execute('insert into goods_cates(name) values("光盘")')
print(count)
# # 更新
# count = cs1.execute('update goods_cates set name="机械硬盘" where name="硬盘"')
# # 删除
# count = cs1.execute('delete from goods_cates where id=6')
# 提交之前的操作,如果之前已经之执行过多次的 execute,那么就都进行提交
conn.commit()
# 关闭 Cursor 对象
cs1.close()
# 关闭 Connection 对象
conn.close()
if __name__ == '__main__':
main()
查询
一行一行返回处理
from pymysql import *
def main():
# 创建 Connection 连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='jing_dong',charset='utf8')
# 获得 Cursor 对象
cs1 = conn.cursor()
# 执行 select 语句,并返回受影响的行数:查询一条数据
count = cs1.execute('select id,name from goods where id>=4')
# 打印受影响的行数
print("查询到%d 条数据:" % count)
for i in range(count):
# 获取查询的结果
result = cs1.fetchone()
# 打印查询的结果
print(result)
# 获取查询的结果
# 关闭 Cursor 对象
cs1.close()
conn.close()
if __name__ == '__main__':
main()
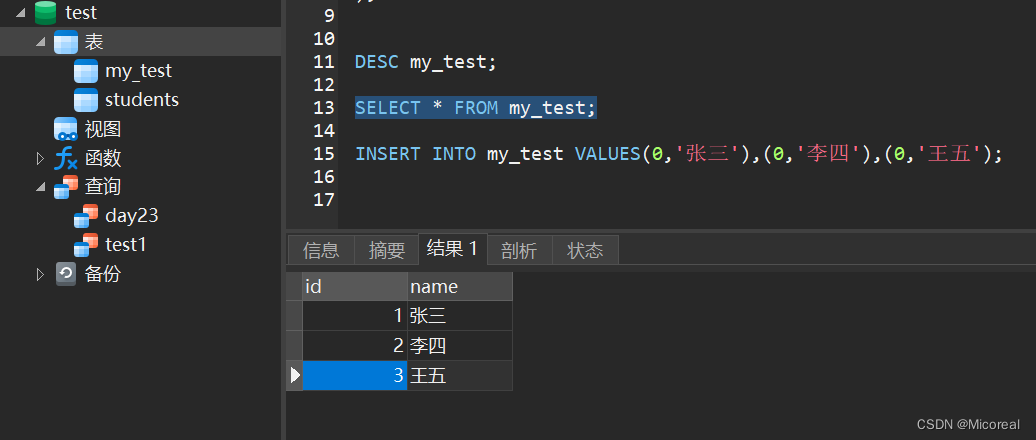
返回的数据:
3
(1, '张三')
(2, '李四')
(3, '王五')
多行数据
from pymysql import *
def main():
# 创建 Connection 连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='jing_dong',charset='utf8')
# 获得 Cursor 对象
cs1 = conn.cursor()
# 执行 select 语句,并返回受影响的行数:查询一条数据
count = cs1.execute('select id,name from goods where id>=4')
# 打印受影响的行数
print("查询到%d 条数据:" % count)
result = cs1.fetchall()
print(result)
# 关闭 Cursor 对象
cs1.close()
conn.close()
if __name__ == '__main__':
main()
输出的结果:
3
((1, '张三'), (2, '李四'), (3, '王五'))
当数据量非常多时,要用 fetchone,否则可能会造成溢出错误。
SQL传参
from pymysql import *
class Conn_Mysql:
def __init__(self, host, port, user, password, database):
self.host = host
self.port = port
self.user = user
self.password = password
self.database = database
self.config = {
"host": self.host,
"port": self.port,
"user": self.user,
"password": self.password,
"database": self.database,
"charset": "utf8"
}
self.conn = connect(**self.config)
self.cur = self.conn.cursor()
# self.con = connect(
# host = self.host,port=self.port,user=self.user,password=self.password,database=self.database,charset='utf8'
# )
def close(self):
self.conn.close()
self.cur.close()
def insert(self, table_name, *args):
"""
往指定的表中插入数据
:param table_name:表名称
:param args:要插入的数据
:return:None
"""
for item in args:
sql = "INSERT INTO {} VALUES{};".format(table_name, item)
flag = self.cur.execute(sql)
if flag == 1:
self.conn.commit()
print("插入成功!")
else:
print("插入失败!")
def delete(self, table_name, identify, *args):
"""
删除指定表的指定数据
:param table_name: 表名称
:param args: 要删除的数据
:return: None
"""
for item in args:
sql = "DELETE FROM {0} WHERE {1}={2};".format(table_name, identify, item)
print(sql)
flag = self.cur.execute(sql)
if flag == 1:
self.conn.commit()
print("删除成功!")
else:
print("删除失败!")
def select(self):
pass
def update(self):
pass
if __name__ == '__main__':
conn1 = Conn_Mysql("10.211.55.8", 3306, "root", "123", "jing_dong")
# 1代表笔记本,1代表华硕,2代表联想
# conn1.insert('goods', (0, 'r510vc 15.6 英寸笔记本', 1, 1, '3399 ',0,1),
# (0, 'y400n 14.0 英寸笔记本电脑', 1, 2, '4999',1,0))
conn1.delete('goods','cate_id',1)
conn1.close()
SQL语句参数化
主要防止的是SQL注入,SQL注入是通过字符串拼接带来的SQL导致不同的运算结果而至于数据库泄露
from pymysql import *
def main():
find_name = input("请输入物品名称:")
# 创建 Connection 连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='jing_dong',charset='utf8')
# 获得 Cursor 对象
cs1 = conn.cursor()
# # 非安全的方式
# # 输入 " or 1=1 or " (双引号也要输入)
# sql = 'select * from goods where name=%s' % find_name
# print("""sql===>%s<====""" % sql)
# # 执行 select 语句,并返回受影响的行数:查询所有数据
# count = cs1.execute(sql)
# 安全的方式
# 构造参数列表
params = [find_name]
# 执行 select 语句,并返回受影响的行数:查询所有数据
count = cs1.execute('select * from goods where name=%s', params)
# 注意:
# 如果要是有多个参数,需要进行参数化
# 那么 params = [数值 1, 数值 2....],此时 sql 语句中有多个%s 即可
# 打印受影响的行数
print(count)
# 获取查询的结果
# result = cs1.fetchone()
result = cs1.fetchall()
# 打印查询的结果
print(result)
# 关闭 Cursor 对象
cs1.close()
# 关闭 Connection 对象
conn.close()
if __name__ == '__main__':
main()