概述
在上一节,我们介绍了Python的基础语法,包括:编码格式、标识符、关键字、注释、多行、空行、缩进、引号、输入输出、import、运算符、条件控制、循环等内容。Python是一种动态类型的编程语言,这意味着当你创建一个变量时,不需要提前声明它的数据类型。Python会自动处理这种情况,并在需要时进行类型转换。
Python提供了丰富多样的数据类型,以满足各种不同的编程需求。理解和掌握这些数据类型的特点、属性和用法,对于编写高效、可靠的Python代码至关重要。Python中的数据类型可以分为两种:基础类型和复杂类型。基础类型包括:数字、字符串等,复杂类型包括:列表、元组、集合、字典等。
Python的数据类型可以分为两个大类:不可变数据类型和可变数据类型。
不可变数据类型是指:当该数据类型对应变量的值发生了改变,它对应的内存地址也会发生改变。不可变数据类型包括:数字、字符串、元组。比如:变量a=66后,再赋值a=88,这里实际是新生成了一个数字对象88,再让 a指向它,而原来的数字对象66被丢弃;此时并没有改变a的值,相当于新生成了a。
可变数据类型是指:当该数据类型对应变量的值发生了改变,它对应的内存地址不会发生改变。可变数据类型包括:列表、集合、字典。比如:变量a=[98, 99, 100]后,再赋值a[1]=50,只是将a的第二个元素值更改,a本身没有修改。
Number(数字)
Python中的数字支持4种类型,分别为:int、float、bool和complex。
整型(int):用于表示正整数、负整数和0,其取值范围是无限的。
浮点型(float):用于表示带有小数点的数值,浮点型的大小也是无限的,可以表示很大的浮点数。
布尔型(bool):用于表示真、假两种状态,只有两个取值:True和False,常用于逻辑运算和控制语句。
复数型(complex):由实部和虚部组成,可以用a + bj的形式表示,其中,a为实部,b为虚部。在Python中,还可以使用complex函数来创建一个复数,比如:a = complex(66, 88)。
那么,如何区分这4种数字类型呢?可以使用type函数和isinstance函数。type函数用于获取某个变量的数据类型,isinstance函数用于判断某个变量是否为某个数据类型的实例(包括父类实例和子类实例)。
a = 10
b = 6.9
c = True
d = 25 + 36j
# 输出:<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
print(type(a), type(b), type(c), type(d))
# 以下均输出:True
print(isinstance(a, int))
print(isinstance(b, float))
print(isinstance(c, bool), isinstance(c, int))
print(isinstance(d, complex))另外,布尔型是整型的子类,这也就意味着,True和False可以与数字进行算数运算。True相当于1,False相当于0。
a = True + 5
b = 9 - False
# 输出:6 9 True True
print(a, b, True == 1, False == 0)String(字符串)
字符串是Python中的文本数据,用于表示一串字符。字符串是由单引号、双引号或三引号括起来的多个字符组成的序列,其长度(即字符数)可以是任意的。字符串从左边算起时,索引从0开始计数;从右边算起时,索引从-1开始计数。
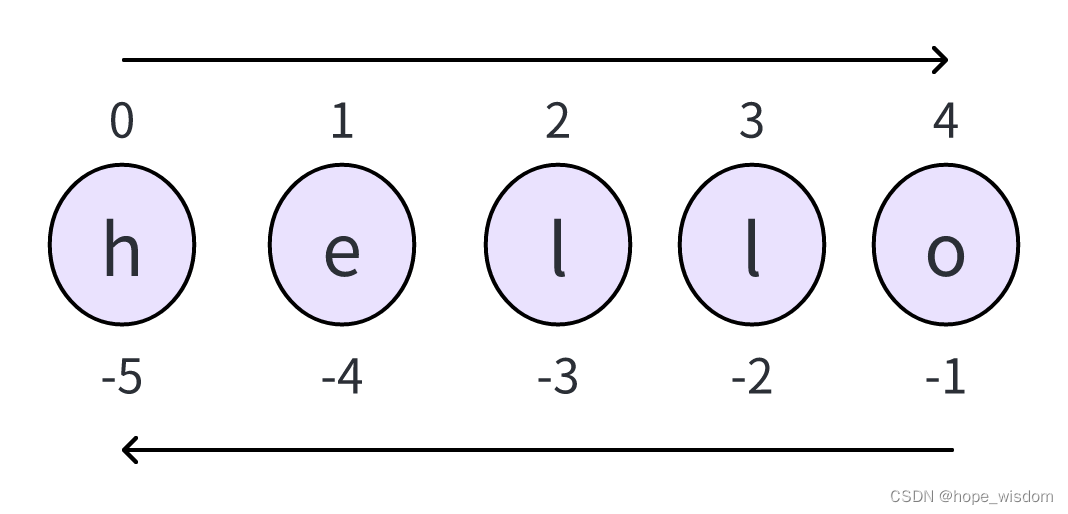
要获取字符串的子串,可以使用变量[下标]或变量[头下标:尾下标]的格式。变量[下标]只能获取包含单个字符的字符串,变量[头下标:尾下标]能获取头下标到尾下标之间(注意:包括头下标,不包括尾下标)的字符串。头下标不写时,默认为0;尾下标不写时,默认为到最右边的所有字符。字符串的下标可以超过索引范围,超过后,会自动被限制为可用的极限值。
a = 'hello'
# 输出:hello
print(a)
# 输出:e
print(a[1])
# 输出:hell
print(a[0:-1])
# 输出:hello
print(a[0:])
# 输出:hell
print(a[:-1])
# 输出:hello
print(a[:])
# 输出:el
print(a[1:-2])
# 输出:hel
print(a[-5:3])
# 输出:hello
print(a[-16:99])字符串还可以使用+符号进行拼接,使用*符号进行拷贝,使用\符号转义特殊字符。当然,如果不想让\符号发生转义,也是可以的:在字符串前面添加一个r或R即可,以表示后面的是一个原始字符串。
a = 'hello'
b = a + ' CSDN'
# 输出:hello CSDN
print(b)
c = a * 2
# 输出:hellohello
print(c)
d = 3 * a
# 输出:hellohellohello
print(d)
e = 'hello\nCSDN'
# 输出:hello
#CSDN
print(e)
f = r'hello\nCSDN'
# 输出:hello\nCSDN
print(f)与C/C++、Java等语言不同,Python中的字符串不能被改变。试图向字符串的索引位置赋值时,比如:a[1]='P',会提示类似下面的错误信息:'str' object does not support item assignment。Python也没有单独的字符类型(比如:C/C++中的char类型),一个字符就是长度为1的字符串。
List(列表)
列表是Python中的有序集合数据类型,可以包含任意类型的元素(同一个列表中的数据类型可以不同)。列表是通过方括号括起来,用逗号进行分隔的元素序列,支持各种操作,包括:元素的添加、删除、修改、查找等。
与字符串一样,列表也可以被索引和截取。列表被截取后,返回一个包含所需元素的新列表。
a = [10, 20, 30, 40, 50]
# 输出:20 50 [30, 40] [30, 40, 50]
print(a[1], a[-1], a[2:-1], a[2:])
# 输出:[10, 20, 30, 40, 50]
print(a[-10:10])列表还可以使用+符号进行拼接,使用*符号进行拷贝。如果要判断一个元素是否在列表中,可以使用in关键字。如果要遍历一个列表,则可以使用for in。反向遍历时,使用[::-1]。第一个冒号两边省略数字,表示所有元素;第二个冒号右边为-1,表示列表元素反向遍历。
a = [10, 20, 30]
# 输出:[10, 20, 30, 10, 20, 30]
print(a * 2)
# 输出:[10, 20, 30, 1, 2]
print(a + [1, 2])
# 输出:False True
print(66 in a, 20 in a)
# 正向遍历,依次输出:10 20 30
for item in a:
print(item)
# 反向遍历,依次输出:30 20 10
for item in a[::-1]:
print(item)Python中包含一些全局方法,用于获取列表的元素个数、列表元素的最大值、列表元素的最小值、列表元素的总和,分别为:len、max、min、sum。
a = [10, 20, 30]
# 输出:3
print(len(a))
# 输出:30
print(max(a))
# 输出:10
print(min(a))
# 输出:60
print(sum(a))除了全局方法,列表自身还有一些成员方法,用于对列表进行添加、插入、移除、统计、反转等操作,分别为:append、insert、remove、count、reverse等。
a = [10, 20, 30]
a.append(66)
a.append(20)
# 输出:[10, 20, 30, 66, 20]
print(a)
# 统计元素20的个数,输出:2
print(a.count(20))
# 查找第一个值匹配的元素的位置,输出:2
print(a.index(30))
# 100不在列表中,运行会报错:100 is not in list
# print(a.index(100))
# 移除最后一个元素并返回,输出:20
print(a.pop())
# 输出:[10, 20, 30, 66]
print(a)
# 在某个位置插入一个元素
a.insert(0, 99)
# 输出:[99, 10, 20, 30, 66]
print(a)
# 反转列表
a.reverse()
# 输出:[66, 30, 20, 10, 99]
print(a)
# 移除第一个值匹配的元素
a.remove(30)
# 输出:[66, 20, 10, 99]
print(a)
# 35不在列表中,运行会报错:x not in list
# a.remove(35)
# 追加另一个序列中的元素
a.extend(["hello", "CSDN"])
# 输出:[66, 20, 10, 99, 'hello', 'CSDN']
print(a)
# 清空列表
a.clear()
# 输出:[]
print(a)注意:列表的index和remove方法在找不到元素时,运行时会报错,而不是像其他语言一样返回-1,或者什么也不做。因此,使用index和remove方法,更好的方式是像下面这样。
a = [10, 20, 30]
index = a.index(66) if 66 in a else -1
# 输出:-1
print(index)
if 20 in a:
a.remove(20)
# 输出:[10, 30]
print(a)列表的比较可以直接使用>、<、==、!=等运算符。只有当两个列表的元素个数、每个位置上的元素的类型和值都相等时,两个列表才相等。注意:不同类型的列表不能比较,运行时会报类似下面的错误信息:'<' not supported between instances of 'int' and 'str'。
a = [10, 20, 30]
b = [20, 10, 30]
# 输出:False
print(a > b)
b = [10, 20, 30]
# 输出:True
print(a == b)
b = ['hello', 'CSDN']
# 不同类型的列表比较会报错,提示:'<' not supported between instances of 'int' and 'str'
# print(a < b)Tuple(元组)
元组与列表类似,是由小括号括起来的元素序列,通常用于表示一组固定的数据。与列表不同,元组是不可变的,也就是说,无法修改元组中的元素。
注意:当元组中只包含一个元素时,需要在该元素后面添加逗号。否则,小括号会被当作运算符使用,导致类型不正确。
a = ('hello', 'CSDN', 'Go')
# 输出:<class 'tuple'>
print(type(a))
a = ()
# 空元组,输出:<class 'tuple'>
print(type(a))
a = (66)
# 一个元素时,没有逗号,a被认为是整型,输出:<class 'int'>
print(type(a))
a = (66, )
# 一个元素时,有逗号,a被认为是元组,输出:<class 'tuple'>
print(type(a))与字符串、列表一样,元组也可以被索引和截取,并支持+符号拼接、*符号拷贝,以及len、max、min、sum等全局方法,这里就不再赘述了。元组中的元素是不允许被修改的,尝试给其赋值(比如:a[0] = 66)会提示类似下面的错误信息:'tuple' object does not support item assignment。
a = (10, 20, 30, 40, 50)
# 输出:20 50 (30, 40) (30, 40, 50)
print(a[1], a[-1], a[2:-1], a[2:])
# 输出:(10, 20, 30, 40, 50)
print(a[-10:10])
a = (10, 20, 30)
# 输出:(10, 20, 30, 10, 20, 30)
print(a * 2)
# 输出:(10, 20, 30, 1, 2)
print(a + (1, 2))
# 输出:False True
print(66 in a, 20 in a)
# 正向遍历,依次输出:10 20 30
for item in a:
print(item)
# 反向遍历,依次输出:30 20 10
for item in a[::-1]:
print(item)
a = (10, 20, 30)
# 输出:3
print(len(a))
# 输出:30
print(max(a))
# 输出:10
print(min(a))
# 输出:60
print(sum(a))Set(集合)
Python中的集合是由大括号括起来的无序的元素序列,不能包含重复的元素。集合支持数学中的集合运算,比如:并集、交集、差集等。要创建一个集合,可以使用大括号{}或者set函数。注意:创建一个空集合,必须使用set函数,而不能使用{},因为{}被用来创建下面将要介绍的空字典。
a = {66, 88, 99}
# 使用大括号创建集合,输出:{88, 66, 99}
print(a)
a = {66, 88, 99, 66, 88}
# 集合会自动移除重复元素,输出:{88, 66, 99}
print(a)
a = set(['a', 'b', 'c'])
# 使用set函数从列表创建集合,输出:{'a', 'c', 'b'}
print(a)
a = set('CSDN')
# 使用set函数从字符串创建集合,输出:{'S', 'N', 'D', 'C'}
print(a)
a = set()
# 使用set函数创建空集合,输出:set()
print(a)向集合中添加元素可以使用add函数,向集合中添加元素、列表、元组、字典可以使用update函数。如果元素在集合中已存在,则不进行任何操作。从集合中移除元素可以使用remove函数和discard函数,其区别在于:如果元素不存在,remove函数会报错,而discard函数则不会报错。pop函数可以随机移除集合中的一个元素,当集合为空时,pop函数会报错。clear函数用于清空集合中的所有元素。
a = {66, 88, 99}
# 输出:3
print(len(a))
a.add(100)
# 输出:{88, 66, 99, 100}
print(a)
a.update([1, 2, 3])
# 输出:{1, 66, 99, 100, 2, 3, 88}
print(a)
a.remove(1)
# 输出:{66, 99, 100, 2, 3, 88}
print(a)
a.discard(2)
a.discard(5)
# 输出:{66, 99, 100, 3, 88}
print(a)
a.pop()
# 输出:{99, 100, 3, 88}
print(a)
a.clear()
# 输出:set()
print(a)集合还支持数学中的集合运算,比如:并集、交集、差集等。运算符|、&、-、^分别用于计算两个集合的并集、交集、差集、异或集,对应函数union、intersection、difference、symmetric_difference。
a = set('hello')
b = set('hope')
# 计数集合a和b的并集,输出:{'e', 'p', 'h', 'o', 'l'}
print(a | b)
# 计数集合a和b的交集,输出:{'e', 'h', 'o'}
print(a & b)
# 计数在集合a,不在集合b的元素,输出:{'l'}
print(a - b)
# 计算不同时包含于集合a和b的元素,输出:{'l', 'p'}
print(a ^ b)
# 计数集合a和b的并集,输出:{'e', 'p', 'h', 'o', 'l'}
print(a.union(b))
# 计数集合a和b的交集,输出:{'e', 'h', 'o'}
print(a.intersection(b))
# 计数在集合a,不在集合b的元素,输出:{'l'}
print(a.difference(b))
# 计算不同时包含于集合a和b的元素,输出:{'l', 'p'}
print(a.symmetric_difference(b))Dictionary(字典)
字典是Python中的键值对数据类型,用于存储键值对映射关系。字典是由键值对组成的无序集合,键必须是唯一的,值可以不唯一。字典的内容在大括号{}内,键值对之间使用逗号进行分隔,键值之间使用冒号进行分隔。
a = {}
# 空字典,输出:{} 0 <class 'dict'>
print(a, len(a), type(a))
a = {'red': 6, 'blue': 9, 'green': 12}
# 输出:9
print(a['blue'])
# 键不存在时,运行会报错:KeyError: 'black'
# print(a['black'])
if 'white' not in a:
print('white not in a')
# 移除某个键,必须确保键存在,否则运行时会报错
del a['green']
# 输出:{'red': 6, 'blue': 9}
print(a)字典提供快速查找、访问键值对的功能和接口。
get(key, default=None):返回指定键的值,如果键不在字典中,则返回default设置的默认值。
setdefault(key, default=None):如果key在字典中,返回对应的值。如果不在字典中,则插入key及设置的默认值 default,并返回 default。
pop(key[,default]):删除字典key所对应的值,返回被删除的值。
popitem():返回并删除字典中的最后一对键和值。
items():返回一个键值对的视图对象。
keys():返回一个键的视图对象。
values():返回一个值的视图对象。
clear():删除字典内所有元素。
fromkeys(seq[, value]):创建一个新字典,以序列seq中的元素做字典的键,value为字典所有键对应的初始值。
a = {'red': 6, 'blue': 9, 'green': 12}
# 输出:9
print(a.get('blue'))
# 输出:100
print(a.get('black', 100))
# 输出:12
print(a.setdefault('green'))
# 输出:100
print(a.setdefault('white', 100))
# 输出:{'red': 6, 'blue': 9, 'green': 12, 'white': 100}
print(a)
a.pop('red')
# 输出:{'blue': 9, 'green': 12, 'white': 100}
print(a)
a.popitem()
# 输出:{'blue': 9, 'green': 12}
print(a)
# 依次输出:blue 9, green 12
for m, n in a.items():
print(m, n)
# 依次输出:blue, green
for k in a.keys():
print(k)
# 依次输出:9, 12
for v in a.values():
print(v)
a.clear()
# 输出:{}
print(a)
a = dict.fromkeys(['lemon', 'apple', 'banana'], 99)
# 输出:{'lemon': 99, 'apple': 99, 'banana': 99}
print(a)
![[SWPUCTF 2022 新生赛]ez_ez_php](https://img-blog.csdnimg.cn/862b4ad38c66404b9903333c40c05296.png)