一、说明

摄影:Charlotte Karlsen on Unsplash
二、什么是 EDA?
EDA是 exploratory data analysis (探索性数据分析 )的缩写。那么什么叫探索性数据分析?就是在进行正式分析前,将一些先验性信息探索出来。比如,数据分布属于哪个类型。
EDA是我们需要做的最重要的事情之一,作为更好地理解数据集的方法。几乎所有数据分析或数据科学专业人员在生成见解或进行数据建模之前都会执行此过程。在现实生活中,这个过程花费了很多时间,这取决于我们拥有的数据集的复杂性和完整性。当然,更多的变量会让我们在执行后续步骤之前进行更多探索,以获得所需的摘要。
这就是为什么使用R或Python(最常见的编程语言)进行数据分析的原因,一些包有助于更快,更轻松地完成该过程,但不是更好。为什么不更好?因为它只向我们展示了一个摘要,在我们专注于更深入地探索我们认为“有趣”的任何变量之前。
“80/20法则”适用:数据分析师或科学家80%的宝贵时间都花在查找、清理和组织数据上,只剩下20%用于执行分析。
三、在R语言中处理
2.1使用哪些库?
在 R 中,我们可以使用以下库:
dataMaidDataExplorerSmartEDA
在 Python 中,我们可以使用这些库:
ydata-profilingdtalesweetvizautoviz
让我们尝试上面列出的每个库,以了解它们的外观以及它们如何帮助我们进行探索性数据分析!在这篇文章中,我将使用通常用于学习如何在R或Python中编码的数据集。iris
在 R 中,可以使用以下代码加载数据集:iris
# iris is part of R's default, no need to load any packages
df = iris
# use "head()" to show the first 6 rows
head(df)
在 Python 中,您可以使用以下代码加载数据集:iris
# need to import these things first
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# use load_iris
iris = load_iris()
# convert into a pandas data frame
df = pd.DataFrame(
data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['species']
)
# set manually the species column as a categorical variable
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# use ".head()" to show the first 5 rows
df.head()
图像 2.在 Python 中加载“鸢尾花”数据集
2.2 R:datamaid
首先,我们需要执行下面的简单代码:
# install the dataMaid library
install.packages("dataMaid")
# load the dataMaid library
library(dataMaid)
# use makeDataReport with HTML as output
makeDataReport(df, output = "html", replace = TRUE) 从第一个快照(图 3)中,我们已经获得了有关数据集的大量信息:iris
- 观测值数为 150。
- 变量数为 5。
- 根据每个变量的数据类型执行变量检查,例如识别错误编码的缺失值、具有 6 个 obs <的水平和异常值。

图像 3.使用鸢尾花数据集的“dataMaid”创建的报表的第一个快照
从第二个快照(图 4):
- 变量的汇总表包括变量类、唯一值、缺失观测值以及检测到的任何问题。我们可以看到,变量检测到了问题。
Sepal.WidthPetal.Length Sepal.Length提供了包括直方图在内的中心测量值,为我们提供了单变量分布。Sepal.Width具有列出的可能异常值。这就是摘要表显示检测到问题的原因。

图像 4.使用鸢尾花数据集的“dataMaid”创建的报表的第二个快照
从第三个快照(图 5):
Petal.Length具有列出的可能异常值。Petal.Width提供了包括直方图在内的中心测量值,为我们提供了单变量分布。Species作为目标变量检测为 a,并且每种类型的数据计数相等,即 50。factor

图像 5.使用鸢尾花数据集的“dataMaid”创建的报表的第三个快照
基于上面在 R 中创建的数据报告,我们已经通过执行一行代码获得了有关数据集的大量信息。😃dataMaidiris
2.3 R:数据资源管理器
首先,我们需要执行下面的简单代码:
# install the DataExplorer library
install.packages("DataExplorer")
# load the DataExplorer library
library(DataExplorer)
# use create_report
create_report(df)从第一个到第六个快照(图像 6、7、8、9、10、11),我们得到的信息与以前的包没有太大区别。

图像 6.使用鸢尾花数据集的“数据资源管理器”创建的报表的第一个快照

图像 7.使用鸢尾花数据集的“数据资源管理器”创建的报表的第二个快照

图像 8.使用鸢尾花数据集的“数据资源管理器”创建的报表的第三个快照

图像 9.使用鸢尾花数据集的“数据资源管理器”创建的报表的第四个快照

图像 10.使用鸢尾花数据集的“数据资源管理器”创建的报表的第五个快照

图像 11.使用鸢尾花数据集的“数据资源管理器”创建的报表的第六个快照
从第七个快照(图 12)中,我们得到了数据集中每个数值变量的 QQ 图。iris

图像 12.使用鸢尾花数据集的“数据资源管理器”创建的报表的第七个快照
从第八张快照(图 13)中,我们得到了数据集中每个变量的相关矩阵。我们可以看到一些信息,例如:iris
Petal.Width并且具有0.96的强正相关性,这意味着在数据集中,花瓣宽度越宽,花瓣长度越长。Petal.LengthirisSpecies_setosa并且具有-0.92的强负相关,这意味着在数据集中,花瓣长度越短,该物种是setosa的可能性就越高。Petal.Lengthiris- 使用上述示例,请使用此相关矩阵提供您的发现。

图像 13.使用鸢尾花数据集的“数据资源管理器”创建的报表的第八个快照
从第九个快照(图14)开始,使用主成分分析(PCA),提供了解释的方差百分比,它显示62%,越高越好。对于PCA的解释,我想我需要另一篇文章。😆

图像 14.使用鸢尾花数据集的“数据资源管理器”创建的报表的第九个快照
从第十个快照(图15)开始,仍然使用主成分分析(PCA),提供了每个变量的相对重要性,它显示具有最高百分比,几乎为0.5。Petal.Length

图像 15.使用鸢尾花数据集的“数据资源管理器”创建的报表的第十个快照
2.4 R: 智能EDA
首先,我们需要执行下面的简单代码:
# install the SmartEDA library
install.packages("SmartEDA")
# load the SmartEDA library
library(SmartEDA)
# use ExpReport
ExpReport(df, op_file = 'SmartEDA_df.html')从图 16、17、18、23 和 24 中,我们得到的信息与之前的包没有太大区别。
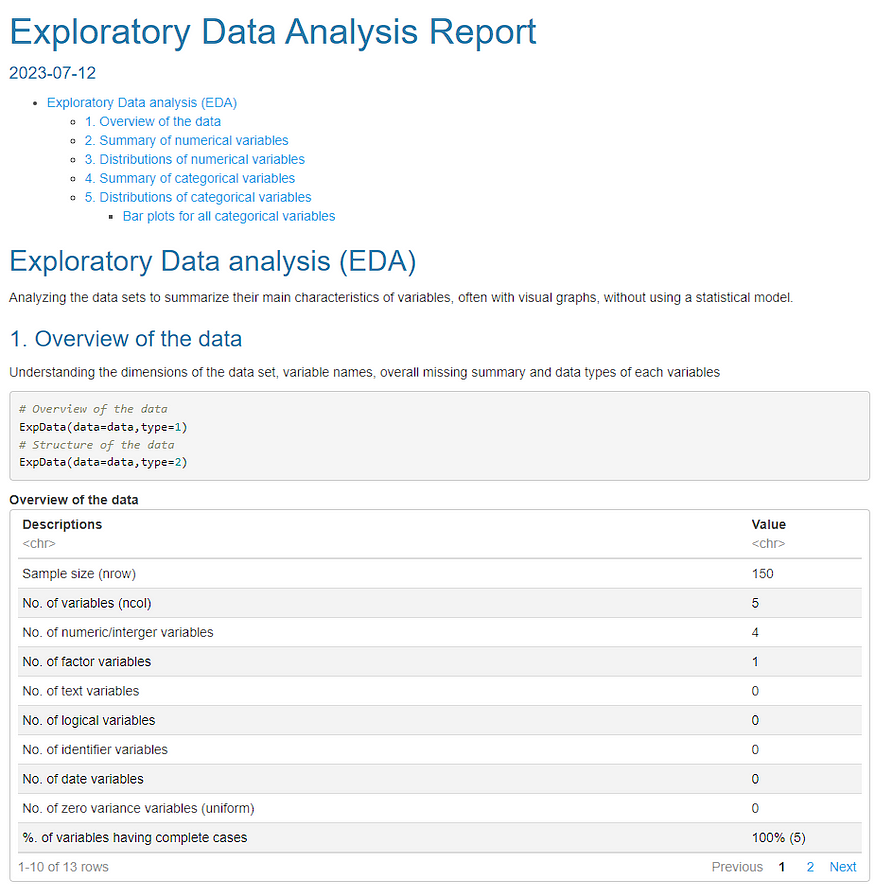
图像 16。使用鸢尾花数据集的“SmartEDA”创建的报告的第一个快照

图像 17.使用虹膜数据集的“SmartEDA”创建的报告的第二个快照

图片 18.使用虹膜数据集的“SmartEDA”创建的报告的第三个快照
从图 19 中,向我们展示了每个变量的密度图,包括偏度和峰度测量值,用于告诉我们数据是否呈正态分布。偏度和峰度的解释也需要另一篇文章,我猜 😅

图片 19.使用虹膜数据集的“SmartEDA”创建的报告的第四个快照
从图 20、21 和 22 中,向我们展示了数据集中可用的数值变量之间的散点图,直观地告诉我们相关性。它为我们提供了与数字格式的相关矩阵类似的信息。iris

图像 20.使用虹膜数据集的“SmartEDA”创建的报告的第五个快照

图像 21.使用虹膜数据集的“SmartEDA”创建的报告的第六个快照

图像 22.使用虹膜数据集的“SmartEDA”创建的报告的第七个快照

图像 23。使用鸢尾花数据集的“SmartEDA”创建的报告的第九个快照
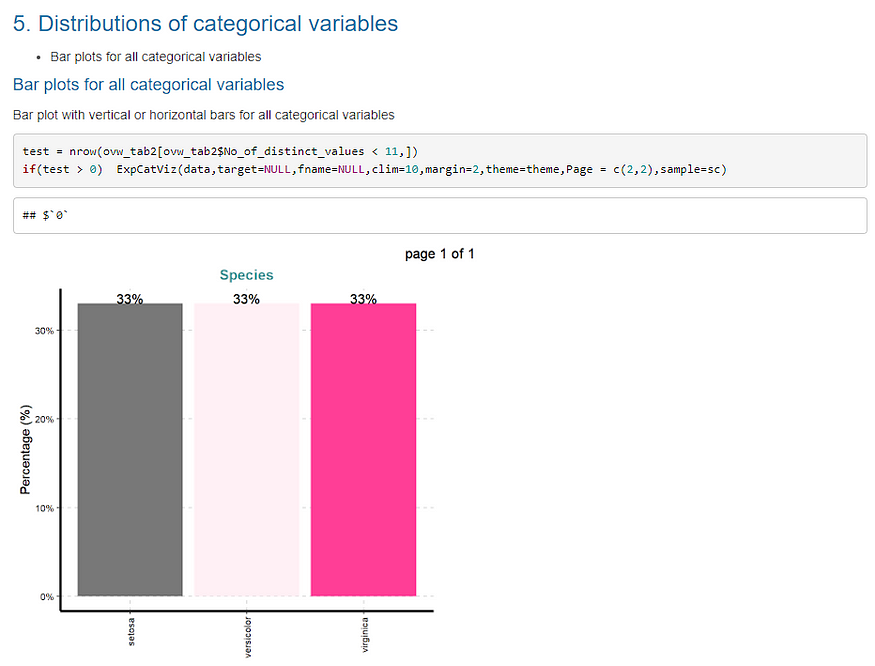
图片 24.使用虹膜数据集的“SmartEDA”创建的报告的第十个快照
2.5 R:结论
使用上面的三个包,我们获得了有关数据集的大量信息,比我们尝试手动创建数据集要快得多,但这还不够,这就是为什么我在标题中说“......更快、更容易...“,因为它只能让我们一瞥数据集,但至少它给了我们可以开始处理哪些事情,而不是寻找起点,例如:irisiris
- 没有缺失的变量/没有错误编码的变量,我们可以跳过这些步骤。
- 在某些变量中检测到异常值,我们可以通过使用任何适当的方法来开始清理数据来处理异常值,而不是手动逐个查找哪些变量具有异常值。
- 如果需要,我们可以开始处理非正态分布的变量。
- 根据相关矩阵和散点图,我们瞥见了哪些变量具有强相关性或弱相关性。
- 使用 PCA,我们知道解释的变量百分比和数据集的相对重要性。
iris
四、Python语言的处理
4.1 Python:ydata-profiling
首先,我们需要执行下面的简单代码:
# install the ydata-profiling package
pip install ydata-profiling
# load the ydata_profiling package
from ydata_profiling import ProfileReport
# use ProfileReport
pr_df = ProfileReport(df)
# show pr_df
pr_df大多数情况下,它显示类似的信息。我将尝试提及一些与以前的软件包完全不同的信息:
- 在图 26 中,我们得到了关于哪些变量具有高度相关性的句子摘要。
- 总体而言,与以前的包相比,输出更具交互性,因为我们可以单击以移动到其他选项卡,并选择要显示的特定列。
图片 25.使用鸢尾花数据集的“ydata_profiling”创建的报表的第一个快照

图像 26。使用鸢尾花数据集的“ydata_profiling”创建的报表的第二个快照

图像 27.使用鸢尾花数据集的“ydata_profiling”创建的报表的第三个快照

图像 28.使用鸢尾花数据集的“ydata_profiling”创建的报表的第四个快照

图像 29.使用鸢尾花数据集的“ydata_profiling”创建的报表的第五个快照

图像 30.使用鸢尾花数据集的“ydata_profiling”创建的报表的第六个快照
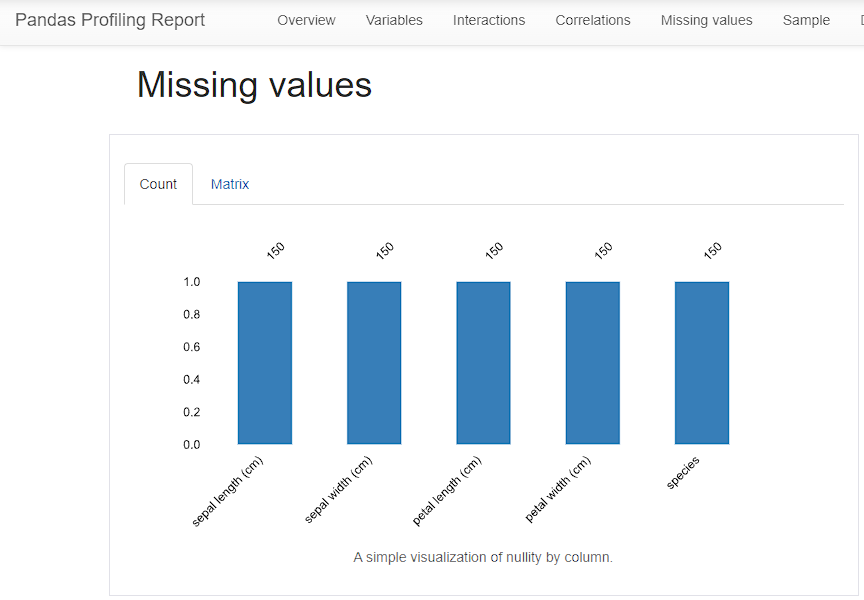
图片 31.使用鸢尾花数据集的“ydata_profiling”创建的报表的第七个快照

图像 32.使用鸢尾花数据集的“ydata_profiling”创建的报表的第八个快照

图像 33.使用鸢尾花数据集的“ydata_profiling”创建的报表的第九个快照
4.2 Python: dtale
首先,我们需要执行下面的简单代码:
# install the dtale package
pip install dtale
# load the dtale
import dtale
# use show
dtale.show(df)这个包的输出和以前的包有很大的不同,在如何使用方面,内容也差不多,但是让我们可以更好地探索。

图像 34.使用鸢尾花数据集的“dtale”创建的报表的第一个快照

图像 35。使用鸢尾花数据集的“dtale”创建的报表的第二个快照

图像 36.使用鸢尾花数据集的“dtale”创建的报表的第三个快照

图像 37.使用鸢尾花数据集的“dtale”创建的报表的第四个快照
4.3 Python: sweetviz
首先,我们需要执行下面的简单代码:
# install the sweetviz package
pip install sweetviz
# load the sweetviz
import sweetviz
# use analyze
analyze_df = sweetviz.analyze([df, "df"], target_feat = 'species')
# then show
analyze_df.show_html('analyze.html')使用这个包,UI和UX有很大的不同,请欣赏表演!

图像 38.使用鸢尾花数据集的“甜可视化”创建的报表的第一个快照

图像 39.使用鸢尾花数据集的“甜美可视化”创建的报表的第二个快照
人类是视觉生物,这意味着人脑处理图像的速度比文本快60万倍,传输到大脑的信息中有000%是视觉的。可视化信息使协作变得更加容易,并产生影响组织绩效的新想法。这是数据分析师将最大时间花在数据可视化上的唯一原因。
4.4 Python: autoviz
首先,我们需要执行下面的简单代码:
# install the dtale package
pip install autoviz
# load the autoviz
from autoviz import AutoViz_Class
# set AutoViz_Class()
av = AutoViz_Class()
# produce AutoVize_Class of df
avt = av.AutoViz(
"",
sep = ",",
depVar = "",
dfte = df,
header = 0,
verbose = 1,
lowess = False,
chart_format = "server",
max_rows_analyzed = 10000,
max_cols_analyzed = 10,
save_plot_dir=None
)使用上面的代码,在浏览器中生成一些选项卡。我们可以使用此包看到的新内容:
- 输出在浏览器中的多个选项卡中生成,以前的包在一个选项卡中显示所有输出。
- 每个变量的小提琴图。它是箱线图和核密度图的混合版本。与以前的包相比,仍然显示类似的信息。

图像 40.使用鸢尾花数据集的“autoviz”创建的报表的第一个快照

图像 41.使用鸢尾花数据集的“autoviz”创建的报表的第二个快照

图像 41.使用鸢尾花数据集的“autoviz”创建的报表的第三个快照

图像 42.使用鸢尾花数据集的“autoviz”创建的报表的第四个快照
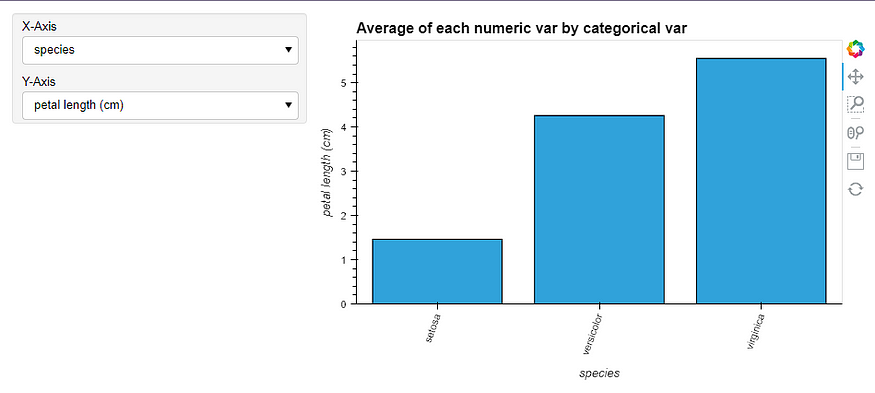
图像 43.使用鸢尾花数据集的“autoviz”创建的报表的第五个快照
4.5 Python:结论
使用上面的四个包,我们得到了很多关于数据集的信息,与R包相比没有太大的区别,但是当有更多的视角通常比拥有更少的视角更好时。一些注意事项:iris
- 与 R 包相比,Python 包的输出大多更具交互性。
- 安装软件包时,可能会出现一些错误。对于 ,常见的错误是 about 和 。您可以通过参考这篇文章来获得解决方案。
dtalejinjaescape - 在某些包中,代码不像在R包中那么简单,但我认为这不是一个大问题,只要我们不懒惰地阅读手动指令,我认为一切都很好。
五、结论
我必须使用哪一个?哪一个是最好的?哪一个与我的数据集最兼容?
这要看情况。我认为我们可以减少我们需要做EDA的时间已经是一件好事了。让我们尝试探索上面解释的每个包并明智地使用它,而不是作为主要解决方案。 以我的拙见,探索数据应该是数据分析的“有趣”部分,所以不要害怕通过手动进行EDA来“弄脏”,有时非自动化方法仍然是最好的。