文章目录
- 注意力机制:Attention
- Biased Competition Theory
- bottom-up和top-down注意力
- SE Block
- Squeeze操作
- Excitation操作
- scale操作
- 与原结构合并
- 计算复杂度评估
- 实验
- 与其他网络对比
- 数据集实验
- 内部参数对比实验
- 进一步评估
- Squeeze
- excitation
Squuze-and-Excitation网络是针对表达能力的改造,和前面两篇不一样,提出的是一个叫SE block的结构。这个结构可以灵活的集成到之前的网络结构中去,比如VGG,RESNet等,也可以自己组成一个自己的SENet。
更关键的是,这个SE block提到了深度学习中一个很重要的词:注意力机制。
我们先简单说说注意力机制。
注意力机制:Attention
在人感知周围世界的时候,其实是有注意力机制存在的,比如一副错综复杂的图像中,你会很主要关注其中的一些内容,而这些内容和你想看到,想感知到的东西有关,这个东西叫做"goal",目标。
你的注意力就会被这个目标来牵引着走,简单来说就是每个人从一幅图像中的关注点都会有不一样,在于你想通图像中看到什么。
在其他的领域也一样,比如NLP。
研究这个注意力机制也有很多,在论文中看到了比如DBN,RNN,LSTM等。这些后续有时间再细读,其中有一篇我觉得挺有启发性,在这里简单说一说:
论文:Look and think twice- Capturing top-down visual attention with feedback convolutional neural networks
Biased Competition Theory
论文中提到的一个叫做偏向竞争理论的东东。
基本逻辑是引入一个语义层面的标签,其实也就是为这个图像确定一个目标:“goal”。那么在进行反向传播的时候,对前面隐藏层的相应神经元节点进行权重的判断,如果和这个goal无关的神经元则进行抑制。突出目标相关的神经元,提高这些神经元的权重。
方式呢就是通过在卷积核的激活层后面再增加一个feedback layer,这个层的每个神经元节点取值在[0, 1]之间:
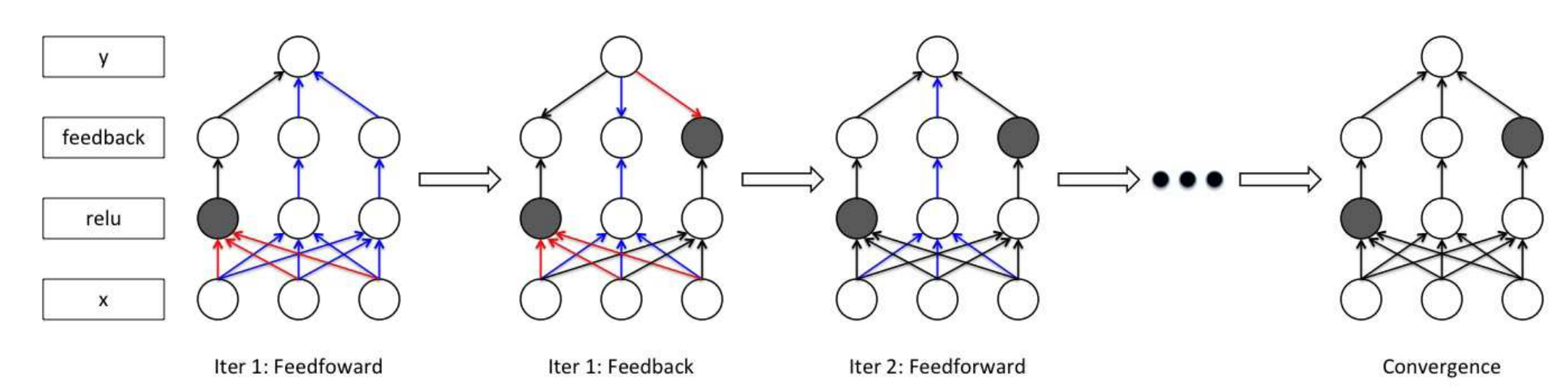
在传播的过程中,通过一个函数来计算哪些神经元需要被抑制。
基本逻辑是在语义标签的指导下,尽量让这个语义的那个class类得到高分,而且feedback layer中的神经元关闭的比较多。也就是这些神经元的权重值总和最低。
bottom-up和top-down注意力
- top-down的注意力机制可以理解先发现楼房,然后再看每一层,最后看每一间的细节特征。而这篇文章中提到的语义标签就是告诉你整幅图像最重要的特征,也就是最高,最top的东西,这个就是top-down的逻辑。
- 一般卷积网络,是从最大的感受野开始(整幅图像),用一些固定的卷积核慢慢的去卷积,逐渐减少感受野,也就是图像的H和W在变小。可以理解为首先获取图像的每个底层的特征,慢慢的对特征进行高层抽象,提取高层特征。这种方式就是bottom-up。
SE Block
上面提到了比较好理解的注意力机制,而SE block引入的是一种叫做通道注意力机制的东东,和上面提到的注意力机制不太一样。
大致意思呢是想提取每个卷积核通道中的特征,然后总和这些特征来获得一些通道之间的联系,可能这个就叫做通道注意力机制吧。
原文描述为:The channel relationships modelled by convolution are inherently implicit and local (except the ones at top-most layers).
We expect the learning of convolutional features to be enhanced by explicitly modelling channel interdependencies
这一篇就重点来说说这个东西。
SE block也是提出了一个branch,也就是一个分支结构,这个分支结构包含两个部分:
- Squeeze,压缩通道特征。
- Excitation,激励部分通道特征,我理解可能是激活某种特征吧。
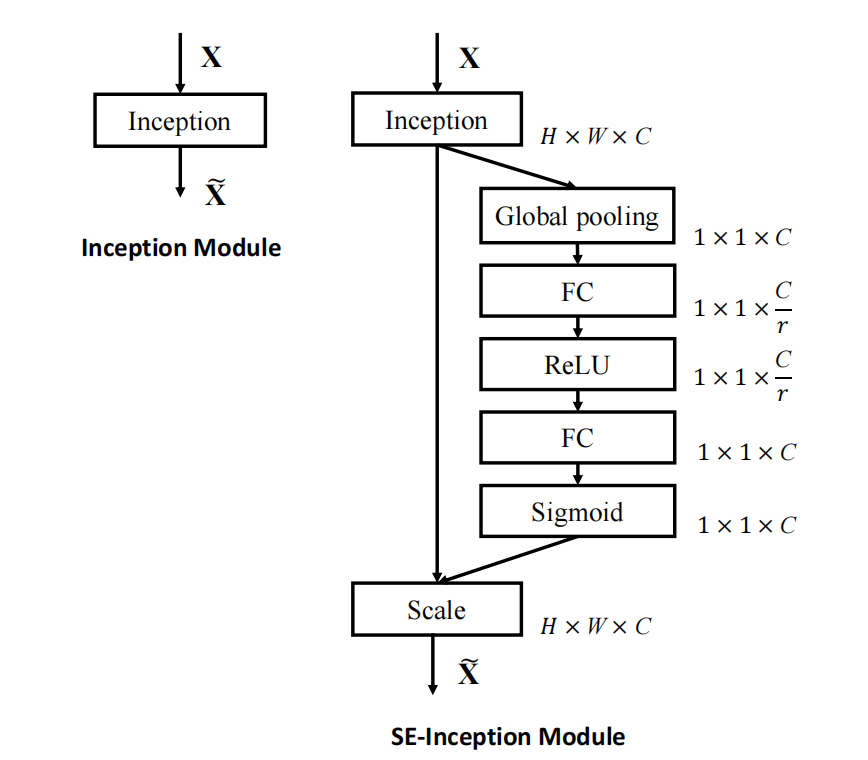
整体结构如下:
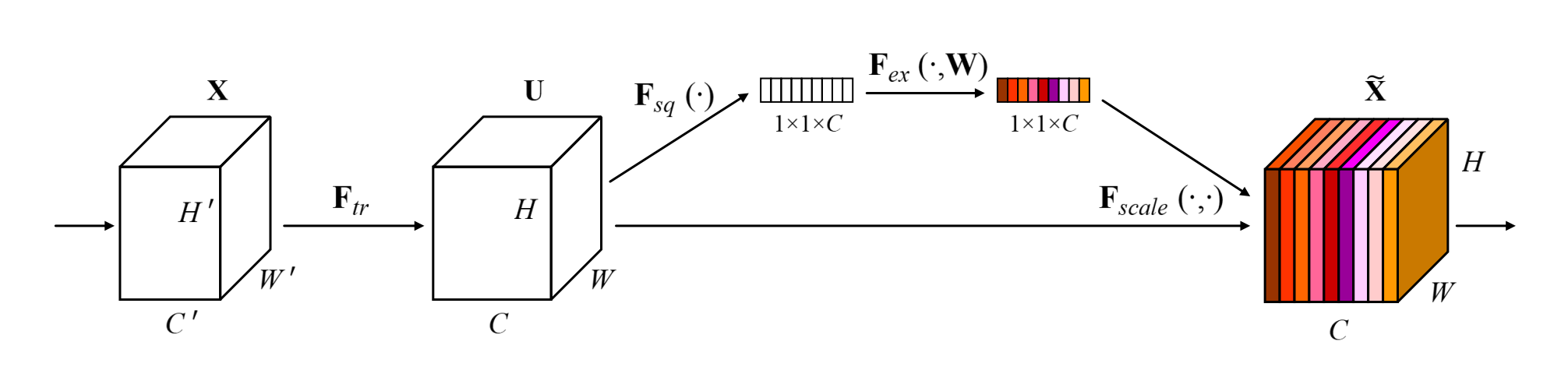
这两个结构是做了个什么事情呢?论文有这么一段描述:Consequently, we would like to provide it with access to global information and recalibrate filter responses in two steps,squeeze and excitation, before they are fed into the next transformation.
大意是说呢,在进入下一步之前,通过两个步骤:squeeze和excitatoin来重新校准filter response,我理解filter就是卷积核,request就是卷积核的输入,response就是卷积核的输出。
也就是说,通过squeeze和excitation两个操作提取通道之间的关系,然后用这个关系去重新校准卷积的输入。
也就是提取通道之间的卷积特征,然后用这个通道特征去修正原有网络输出的特征图。
- X为输入
- U为通过函数变换 F t r F_{tr} Ftr得到的特征图,也就是通过卷积得到的结果,在GoogleNet中就是Inception,在残差网络中就是Residual blcok。
U后面的上面那根线就是表示的SE block的操作,最后再和原输出U相结合。
Squeeze操作
这个操作对应上图中的函数
F
s
q
F_{sq}
Fsq。
在图1中:
- 输入X的通道数是 C ′ C^{'} C′
- 输出特征图U的通道数是C
上面提到了,要找到通道之间的关系,那就是要用到所有通道的信息。论文中简单起见,把每个通道都压缩成一个点,直接求平均,相当于就是这个通道的特征值。
这个求平均的过程就是所谓的Squeeze。
原文为:To mitigate this problem, we propose to squeeze global spatial information into a channel descriptor. This is achieved by using global average pooling to generate channel-wise statistics。
表达为公式就是:
z
c
=
F
s
q
(
u
c
)
=
1
H
∗
W
∑
i
=
1
H
s
u
m
j
=
1
W
u
c
(
i
,
j
)
z_c = F_{sq}(u_c) = \frac{1}{H * W} \sum_{i=1}^H \ sum_{j=1}^W u_c(i,j)
zc=Fsq(uc)=H∗W1i=1∑H sumj=1Wuc(i,j)
- u c u_c uc表示特征图U中的某个通道
- z c z_c zc表示经过压缩之后的向量Z
从公式中可以看出,每个尺寸为
H
∗
W
H * W
H∗W的featrue map通道,经过全局平均之后,就只剩一个像素点。
所以,一个
H
∗
W
∗
C
H * W * C
H∗W∗C的featrue map经过squeeze之后,就变成了一个
1
∗
1
∗
C
1 * 1 * C
1∗1∗C的vector,计作Z。
当然,这里是可以替换为各种更厉害的特征统计方法。这里是利用了一个最简单的,简单就是美。
Excitation操作
特征图经过压缩后,第二步就是综合这些通道的特征值。
论文提出,这个综合方法需要满足两个条件:
- 要可以表达非线性关系
- 要可以提取处非互斥的关系
所以,论文提出了一个计算方法:
s
=
F
e
x
(
z
,
W
)
=
σ
(
g
(
z
,
W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
s=F_{ex}(z, W) = \sigma(g(z,W)) = \sigma(W_2\delta(W_1z))
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
- δ \delta δ为ReLU。
- W 1 , W 1 ∈ R C r ∗ C W_1, W_1 \in R^{\frac{C}{r} * C} W1,W1∈RrC∗C为权重矩阵,
- W 2 , W 2 ∈ R C ∗ C r W_2, W_2 \in R^{C * \frac{C}{r}} W2,W2∈RC∗rC为权重矩阵
- 从后面的图来看, σ \sigma σ为Sigmod。
从上面可以看出,这个Excitation就是两个全联接层:
- 第一个连接层把 1 ∗ 1 ∗ C 1 * 1 * C 1∗1∗C的vector Z变成一个 1 ∗ 1 ∗ C r 1 * 1 * \frac{C}{r} 1∗1∗rC的向量。然后后面跟一个ReLU激活层。
- 第二个连接层把 1 ∗ 1 ∗ C r 1 * 1 * \frac{C}{r} 1∗1∗rC的vector重新恢复为一个 1 ∗ 1 ∗ C 1 * 1 * C 1∗1∗C的向量。然后后面跟一个Sigmod的激活层。
scale操作
最后,根据图1,作为Squeeze和Excitation操作之后,还需要和原特征图U进行合并,也就是上面提到的“重新校准特征图”。这个合并方法也特别简单,就是把这个向量直接原特征图相乘。
x ^ c = F s c a l e ( u c , s c ) = s c u c \hat{x}_c=F_{scale}(u_c, s_c)=s_cu_c x^c=Fscale(uc,sc)=scuc
从上面的excitation可以得知, s s s是一个 1 ∗ 1 ∗ C 1 * 1 * C 1∗1∗C的向量,与一个 H ∗ W ∗ C H * W * C H∗W∗C的特征图相乘的话,再从上面的公式可以看出,就是按通道数一个一个的去把 s s s中的每个元素拿出来与特征图的对应通道进行相乘,就是一个标量乘以矩阵,所以可以理解就是一个scale的操作,放大缩小而已。
讲到这里,感觉就是SE就是提取出了通道中某些特征,或者说某些注意力特征,通过这个 s s s,也就是表示通道的权重的向量,去把这个权重乘以对应的特征图通道,来放大或缩小这个通道的作用。从这个角度上来看,确实就叫做通道注意力机制。
与原结构合并
论文中提到了和两种经典结构合并的方式:
- Inception:
- ResNet
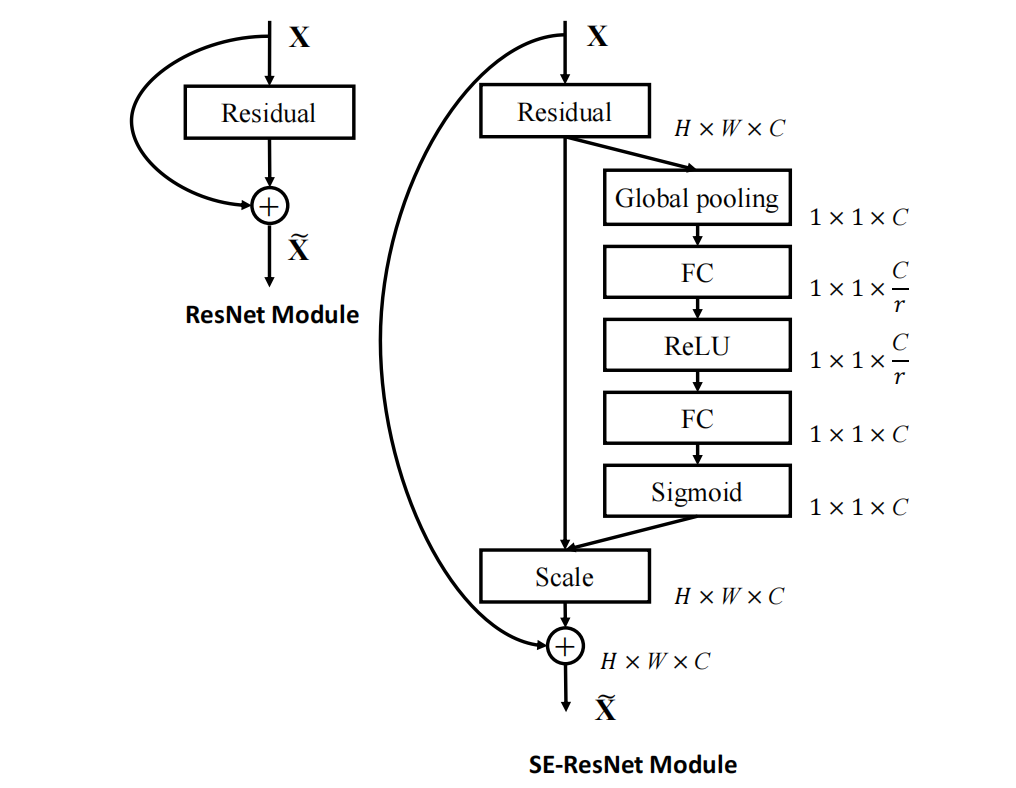
先把通道注意力的这个向量与残差结构中的U相乘之后再和恒等映射进行相加。
计算复杂度评估
通过上面的描述,很容易知道这个SE结构没有增加什么复杂的结构,所以论文中拿出来和ResNet-50做了个对比,ResNet-50的运算量为3.86 GFLOPs,增加了这个结构后的SE-ResNet-50大概为3.87 GFLOPs。
也就是增加了大约0.26%的运算量,但是可以达到ResNet-101的准确度。
时间上:
- GPU上,256的一个batch,从190ms增加到了209ms。
- CPU(嵌入式设备)上的运行时间从164ms增加到了167ms,忽略不计
参数增加量:增加了 2 r ∑ s = 1 S N s C s 2 \frac{2}{r} \sum_{s=1}^SN_sC_s^2 r2∑s=1SNsCs2。
- S为stage的个数
- N为每个stage中Residual block的个数
- C为通道数
大约是增加了2.5 million的参数,也就是大约增加了10%。
实验
这篇论文里有一句话,应该说适用于各种深度网络的论文:
A rigorous theoretical analysis of the representations learned by deep neural networks remains challenging, we therefore take an empirical approach to examining the role played by the SE block with the goal of attaining at least a primitive understanding of its practical function。
大意呢是一个严格理论证明有效性的网络是不太现实的,也就是深度网络一直说的黑盒子理论,只能从实验上去证明有效,经验主义着,或者说实践主义者。所以所有的深度学习论文都包含大量的对比实验,和其他的网络对比,不同数据集之间的对比,自己内部参数变化的对比等等。
这篇论文也是,主要是两部分,和其他网络的对比和自身参数变化的对比。
与其他网络对比
与其他网络对比主要挑选了VGG,Inception,ResNet及其各种变体,移动设备网络,具体的网络设置,训练方法,数据预处理等论文里写的很详细,这里不一一列举。
基本逻辑就是在这些经典结构里引入SE Block,引入方法上面有提到。
比较的双方就是引入了结构的和没引入结构的对比。
总结在了一张表里:
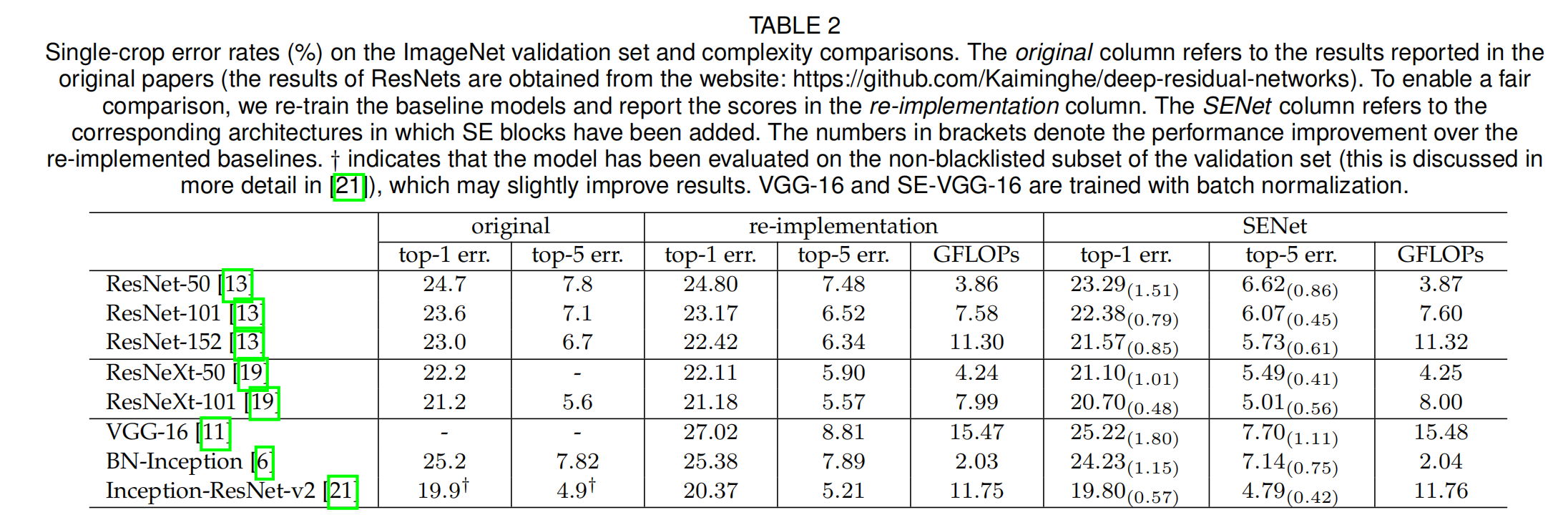

大致的结论如下:
- 在Network depth部分,也就是se block在网络深度这个维度上的比较。和resnet对比,resnet-50增加了se block后,准确率提高到6.62%,和resnet-101(6.52)差不多了,增加的计算量只有一点点,是101的一半
- 在101和152的对比更加,在101上增加se block后, 准确率比152还高,比152的还高出0.27个百分点。
- 还与VGG和Inception网络结构上进行了对比,基本上也是这个结论
- 与最新,最牛逼的网络:Inception resnet和resnet-Xnet两种结构进行对比,引入SE block也是有很好的效果。
- 给出了在各个结构中,在训练过程中,各个epoch的训练误差与验证误差走势图,整个走势稳得很,整个训练和验证集的过程,都是有提升的,而且每种结构都是这样,牛逼的很。

- 与移动网络,也就是相对较少的网络层数,较少的参数量,也是有效的。
数据集实验
使用了ImageNet,CIFAR-10,CIFAR-100,Places365-Challenge dataset场景识别的数据集,COCO目标检测数据集(增加Faster R-CNN模块)。
结果为:
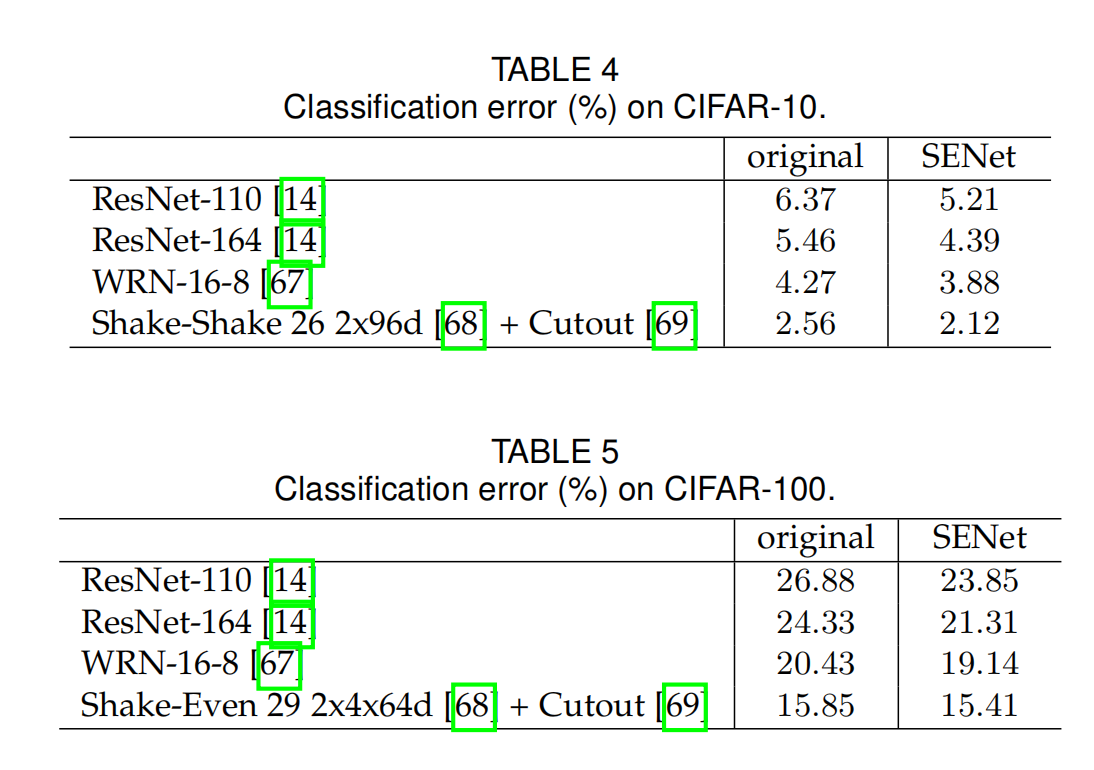
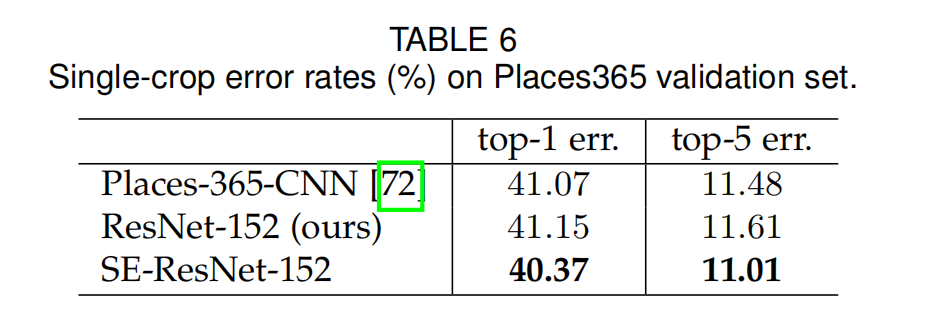
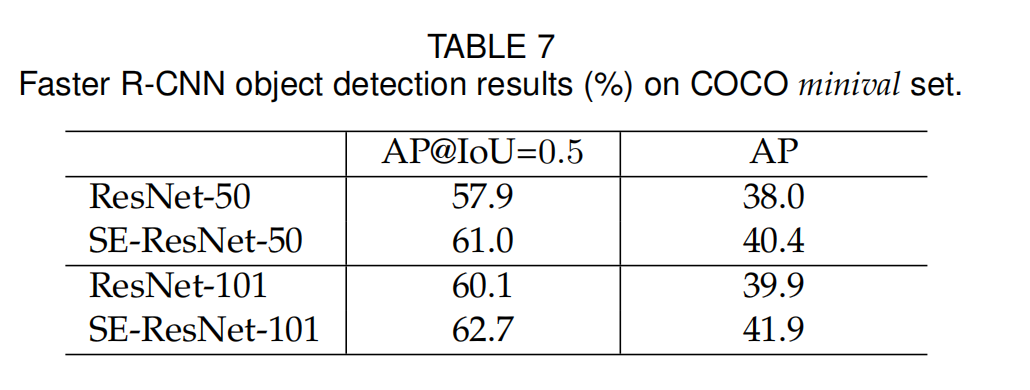
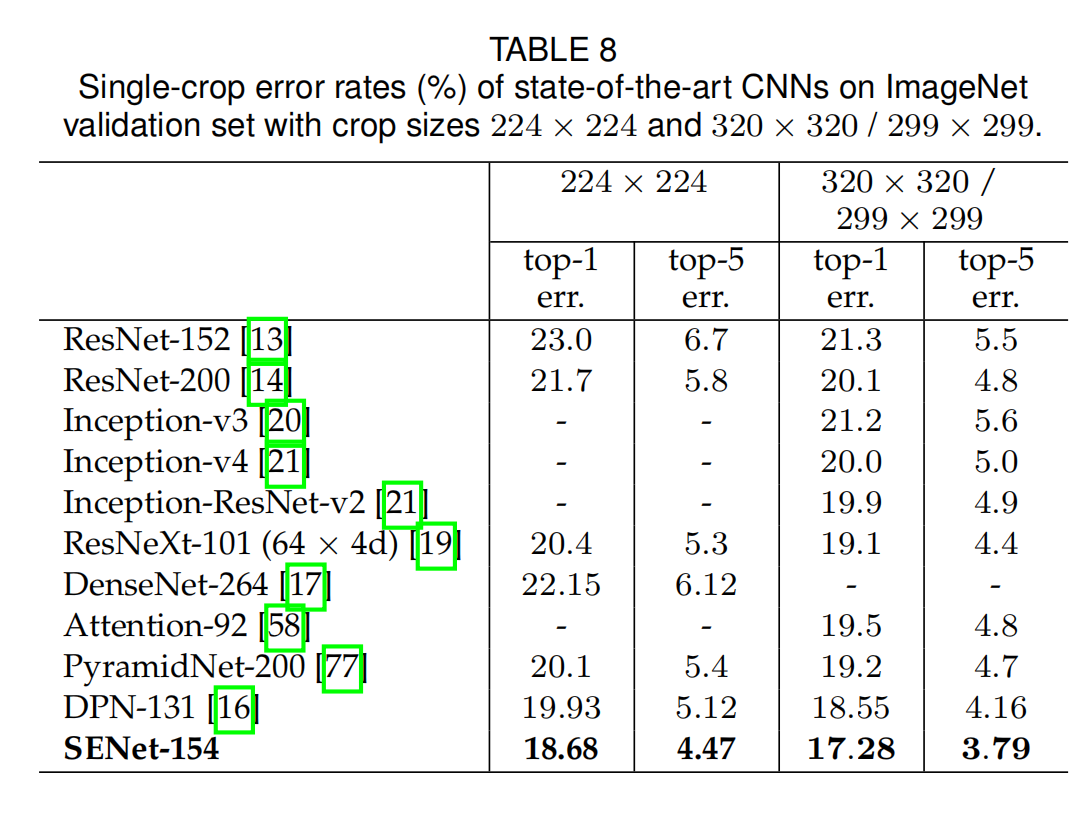
简单来说,SE block对不同的数据集也是同样有效。
内部参数对比实验
其实我理解就是对调整这个注意力机制的方式提供了一些tricks,也就是一些小技巧,可以从这些方面去调整。
-
第一个就是前面提到的参数 r r r,这个参数越大,中间的参数就越小,就是两个卷积层中间的那一层。文中给出了不同 r r r取值下,对准确率的影响:
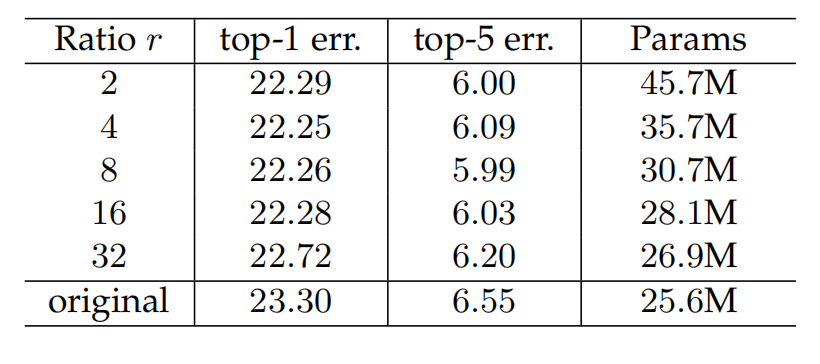
通过上图可以看出,r的大小和性能没有正比关系,在r=8的时候效果最好,r=16可以认为是一个平衡点。
值得关注的就是,每个residual block都可以用不同的r。 -
对比了Squeeze是最大池化和平均池化的效果,global max pooling和 avg pooling差别不大

-
excitation那里的激活层,对比了tanh,ReLU,Sigmond。Sigmond效果较好,所以之前介绍的结构里,excitation用的就是Sigmond
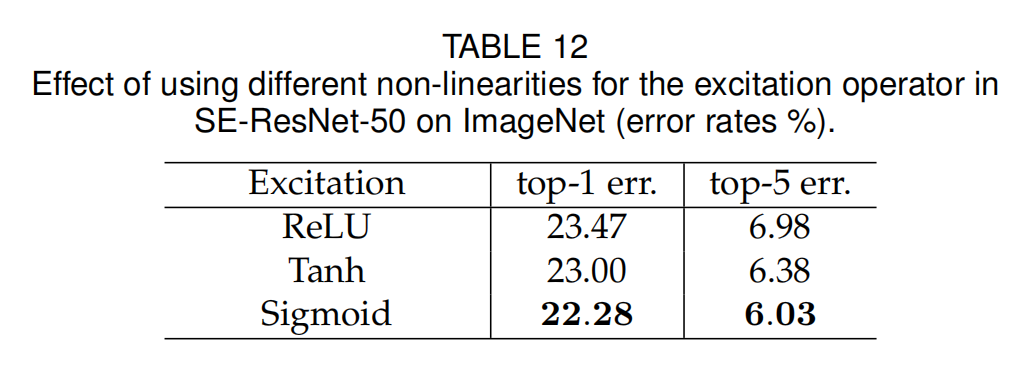
-
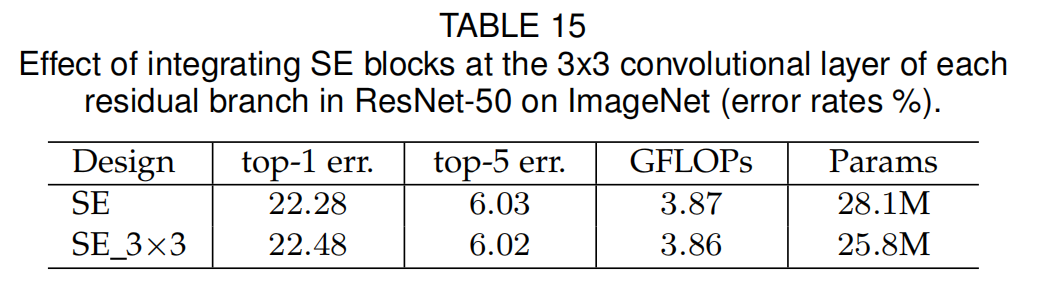
标准的ResNet-50总共是5个stage,也就是5个部分,论文还比较了单独在某个部分增加SE block的情况:
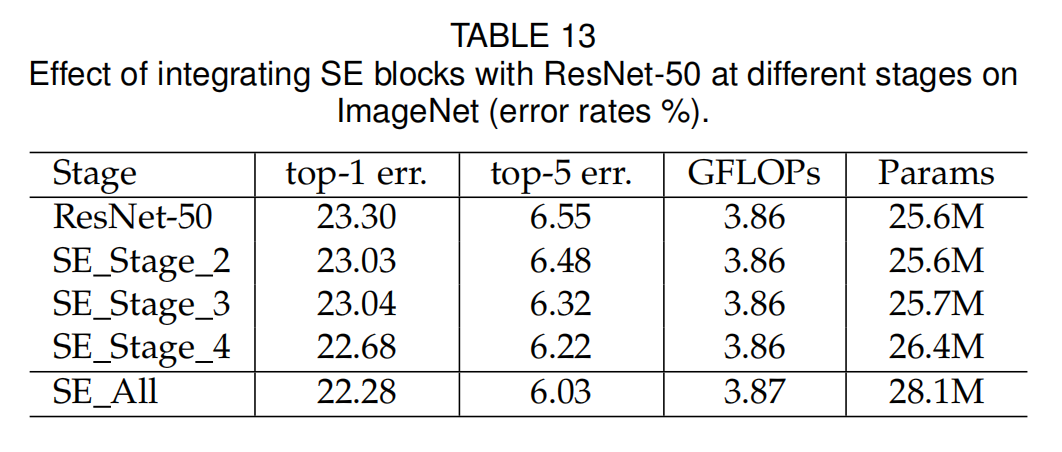
结论就是在ResNet中的每个stage中增加这个block,随便增加在哪个stage都有用,加在一起可以起到叠加的作用。
- 对于ResNet来说,这个SE Block增加在残差结构的哪个位置也是一个值得考量的变量:
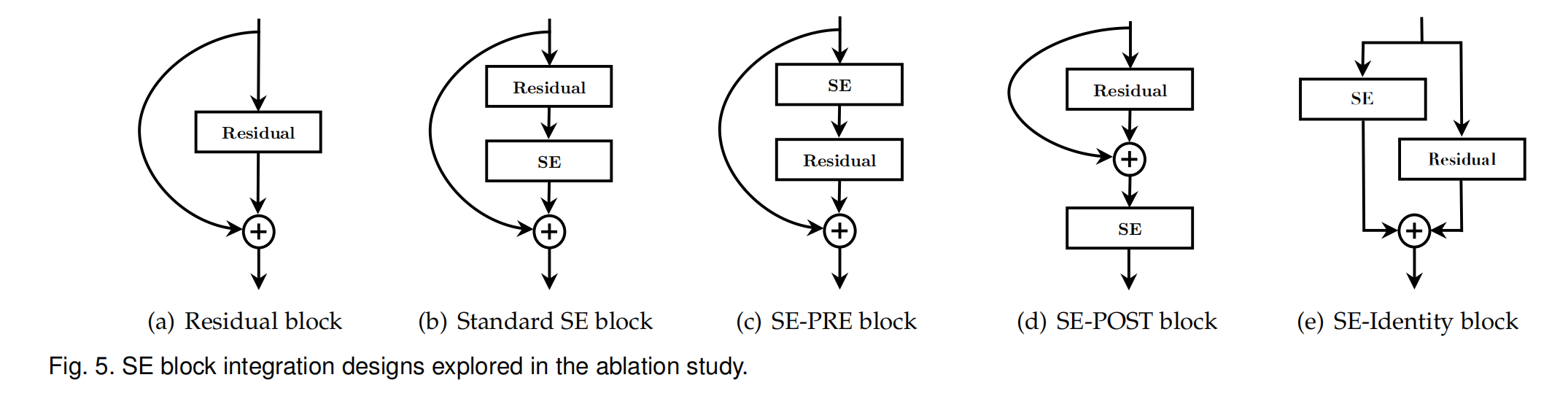
与标准的集成方法不一样,另外又提出了三种不同的集成方法,SE-PRE,SE-POST,SE-Identity。
结论是,标准的挺好,出了放后面不太好,不要放到残差的叠加动作之后:
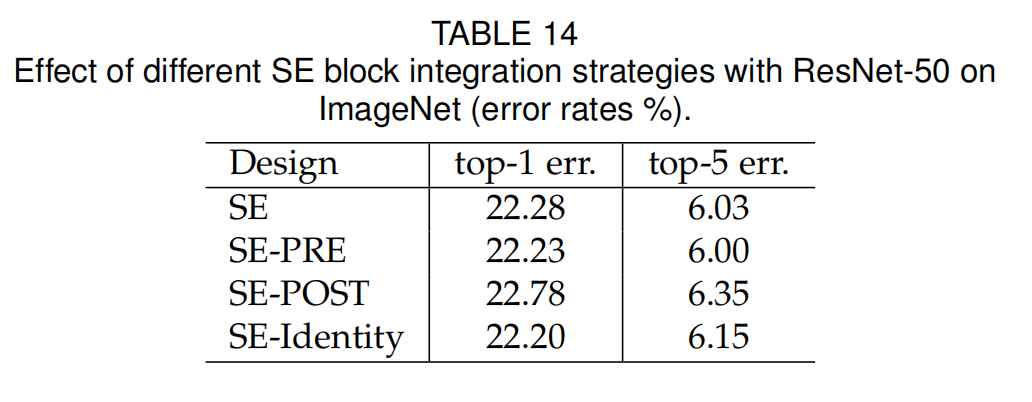
甚至还提出了集成到Residual Block中间去,为了节省一些参数量。
进一步评估
论文还进一步的评估了Squeeze和Excitation这两个步骤在SE block中的重要程度。
Squeeze
论文中做了一个实验,替换掉SE中的Squeeue,也就是max pooling,换成两个FC,都使用1 * 1的卷积层进行降维,从H和W两个方向上全部降成1。

从结果看:
- 全局信息对网络结果有帮助,就算是两个1 * 1的卷积层也是起到了这个作用,也能有效降低错误率。
- global max pooling的方式更有效
excitation
这一部分操作本质上是提取通道特征,把注意力放在有效的通道信息上,不重要的特征就会被忽略掉,通过激活层屏蔽。
所以论文这里提出了验证这个激活层有效性的实验,这个实验分成两部分:
- 第一部分是从整个数据集中抽样了4个类别的数据。然后输出通道的平均激活率(50个通道为一个样本求平均,compute the average activations for fifty uniformly sampled channels in the last SE block of each stage)。不同的stage要分开统计:
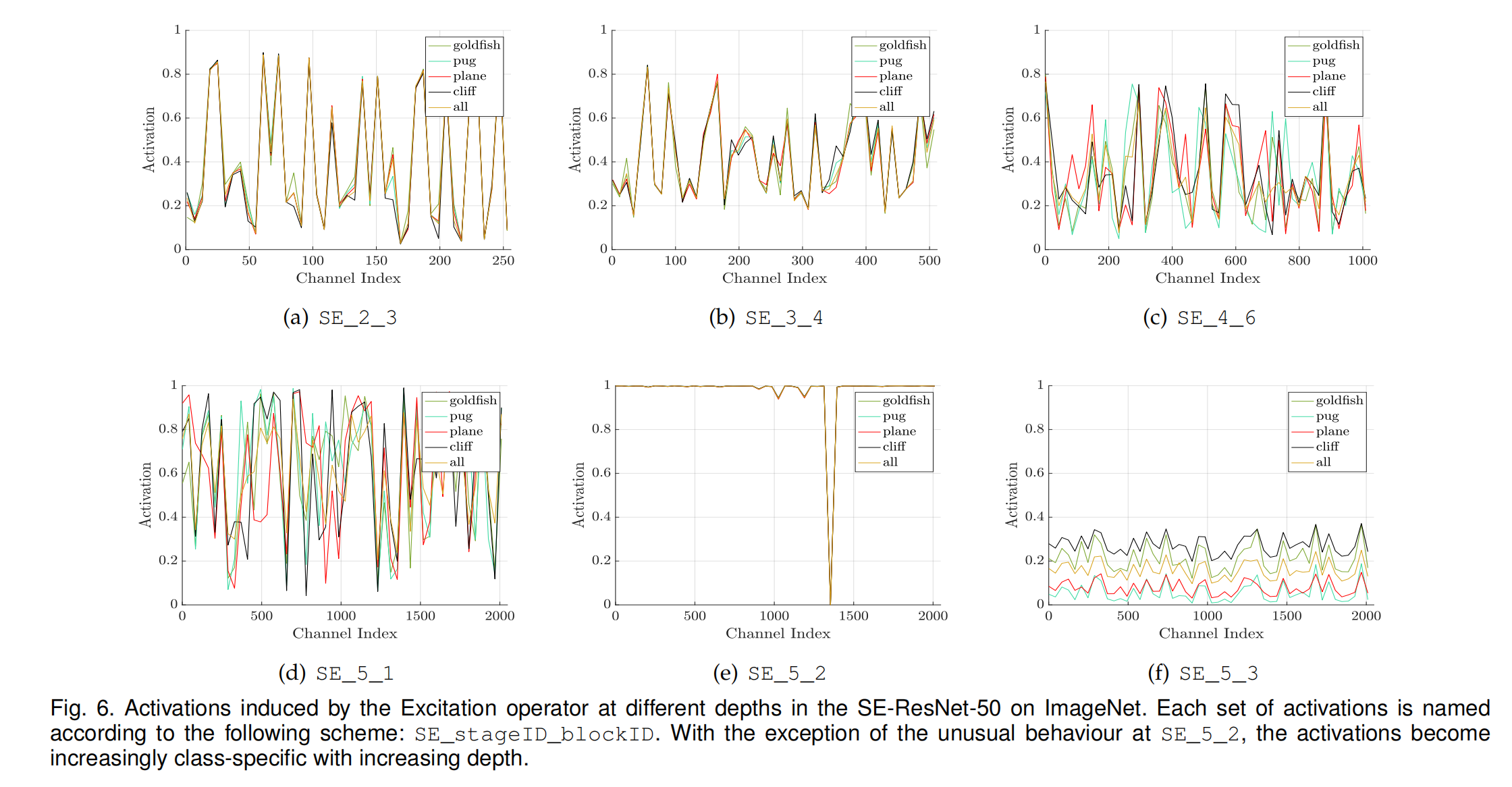
结论如下:
- 图的命名规则是SE+stageID+blockID
- 网络中靠前的层,每个类别的激活率差别基本不大。这个的解释是:前面的都是底层,一般性的特征,比如颜色,线条之类,后面的才会有高层特征,比如最后的语义特征这些(namely that earlier layer features are typically more general (e.g. class agnostic in the context of the classification task) while later layer features exhibit greater levels of specificity)。所以不管是什么类,提取到的东西很类似,所以激活率也没啥区别。
- SE-4-6和SE-5-1这两个图说明到了网络的中层,不同类别的激活率趋势就不一样了,呼应了上一条。也说明了这个激活是有效的,因为类别不一样,注意力是不一样的。
- 在SE-5-2这个位置,excitatioin基本退化成了一个恒等映射,所有的基本都是被激活的。而且SE-5-3这里,所有的类别基本上趋势是相同的,从这两个图可以看出,到了网络的后面,这个激活的作用基本不大了,所以才说到了网络的后面,这个参数 r r r可以设置的大一点。反正各个类别之间区别不大。
- 上面是对类别的注意力的实验,接下来测试了每个类别中,这个excitation对每张图像的作用。数据是用的两个类别,计算的是激活数的平均值和标准差。
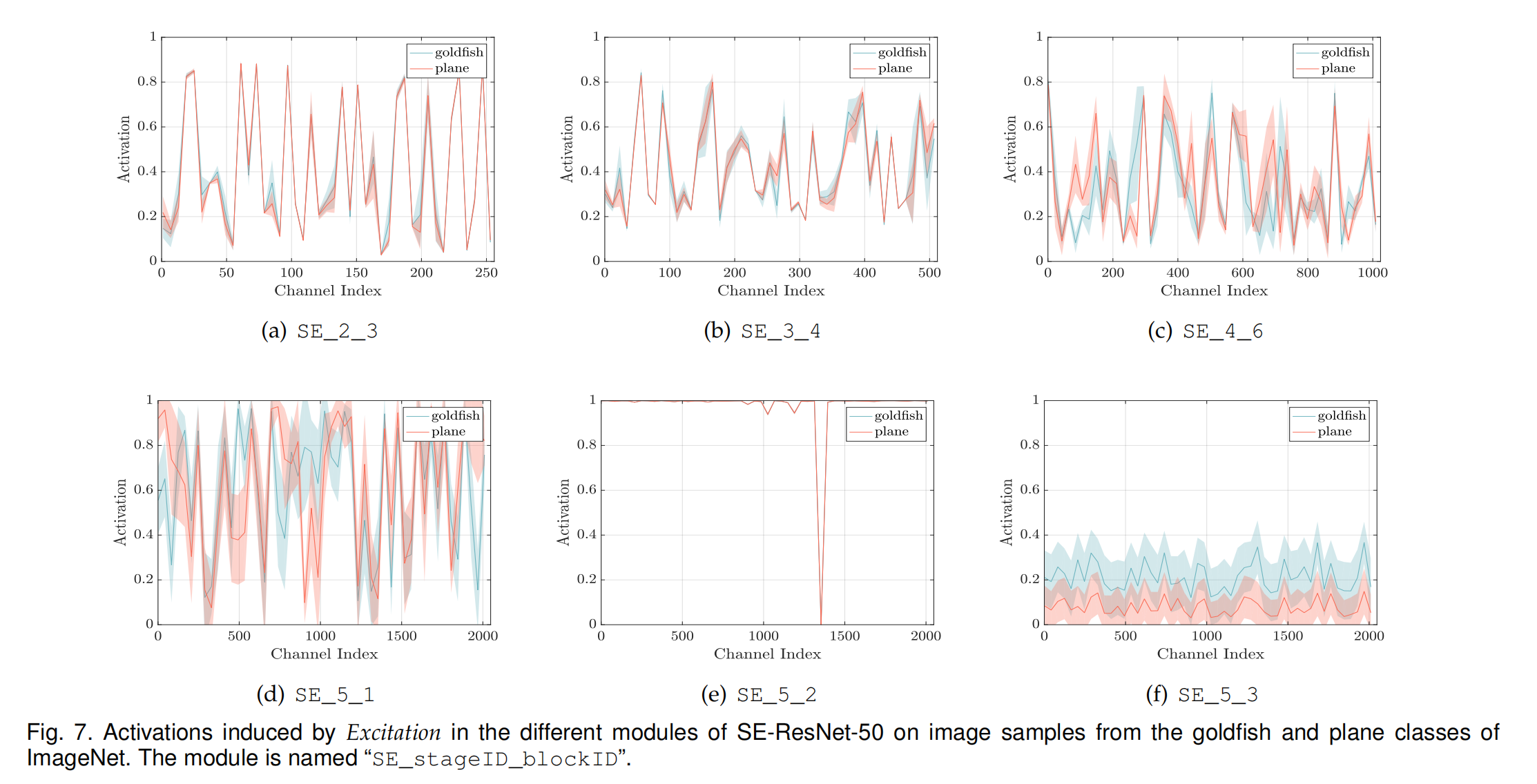
结论是:
- 不管是类别还是实例(instance,也就是image),注意力机制都是有效的。
- 类别和实例的趋势基本类似。