编译预处理
编译阶段会做如下几件事:
(1)预处理。
(2)编译。包括词法分析、语法分析、目标代码生成、优化等。
(3)汇编。产生.o(.obj)目标文件。
C语言一般提供三种预处理功能:宏定义、 文件包含、条件编译。这三种预处理功能也是通过在源程序文件写入代码来实现的,只不过这些代码比较特殊,都是以“#”开头。
宏定义
不带参数的宏定义
有几点说明:
①宏名一般用大写字母表示,这是一种习惯,建议遵照这个习惯。
②宏定义其实并不是C语言语句(虽然有时候会称其为语句),不必在行末加分号,如果加分号则连分号一起被替换了。
③#define命令出现在程序中函数的外面,宏名的有效范围是#define之后到本源程序文件结束,不能跨文件使用,如果在另外一个源程序文件中使用,则需要在另外一个源程序文件中也做相同定义,或者把这些#define定义统一放到一个公共文件(如.h头文件)里,并用#include把这个公共文件包含到每个源程序文件中去。一般来说,#define命令都写在源程序文件开头部分,函数之前。
④可以用#undef命令终止宏定义的作用域,不过#undef命令用得比较少。
⑤用#define进行宏定义时,还可以引用已定义的宏,可以层层置换。
⑥字符串内的字符即便与宏名相同,也不进行替换。
带参数的宏定义
带参数的宏定义,就不仅是进行简单的内容替换,还要进行参数替换。其一般形式为:

作用:用右边的“被替换的内容”代替“宏名(参数表)”,在被替换的内容中,一般都会包含参数表中所指定的参数。看看如下范例:
#define S(a,b) a*b
.....
int Area = S(3,2);
在上面的范例中,用了宏S(3,2),系统是怎样替换的呢?把3、2分别代替宏定义中的形参a、b,最终用32替换了S(3,2)。所以程序代码“intArea=S(3,2);”就等价于“int Area=32;”。
带参数的宏定义展开置换的总结:对一般形式中提到的“被替换的内容”,要从左到右处理。如果“被替换的内容”中有“宏名”后列出的形参,如a、b,则将程序代码中相应的实参(可以是常量、变量或者表达式)代替形参,如果“被替换的内容”中的项并不是“宏名”后列出的形参,则保留,如上面ab中的“”就会被保留。看看如下范例:
#define PI 3.1415926
#define S(r) PI*r*r
int main() //主函数
{
float area;
area S(3.6);
......
}
有几点说明:(1)如果代码中出现“area=S(1+5);”,替换后会变成3.14159261+51+5,这肯定不对,程序代码的原意是替换后变成3.1415926*(1+5)*(1+5)。为了解决这个问题,要在形参外面加一个括号。如下所示:
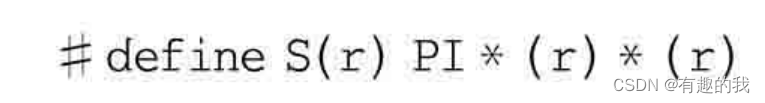
总结一下:
(1)函数调用是先求出实参表达式的值,然后传递给形参,带参数的宏只进行简单的内容替换,宏展开时并不求值,如上面的S(1+5),宏展开时并不求1+5的值,只是原样用实参替换掉形参。
(2)函数调用是在程序运行阶段执行到该函数时才执行其中的代码,这涉及比如为所调用的函数分配临时内存等一系列工作。但宏展开是在编译阶段进行的,而且展开时也并不分配内存,当然也不存在“值传递”“返回值”等只有在函数调用中才存在的说法。
(3)宏的参数没有类型这个说法,只是一个符号,展开时用指定内容替换。例如#defineS(r)PI*(r)(r),其中的r是没有类型这种概念和说法的。
(4)宏展开每进行一次,源程序代码都会有所增多,如“area=S(1+5);”,在宏展开时会被替换成“area=3.1415926(1+5)*(1+5);”,显然代码变多了,所以使用宏的次数如果增多,源程序代码就会增多,但函数调用不会使源程序代码增多。
(5)宏展开只占用编译时间,不占用运行时间,而函数调用占用运行时间(分配内存、传递参数、执行函数体、返回值等)。
文件包含
所谓“文件包含”,是指一个文件可以将另外一个文件的全部内容包含进来,也就是将另外的文件包含到本文件中。C语言中,通过#include命令来实现。其一般形式如下:
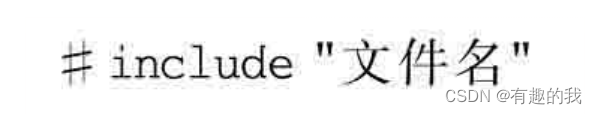
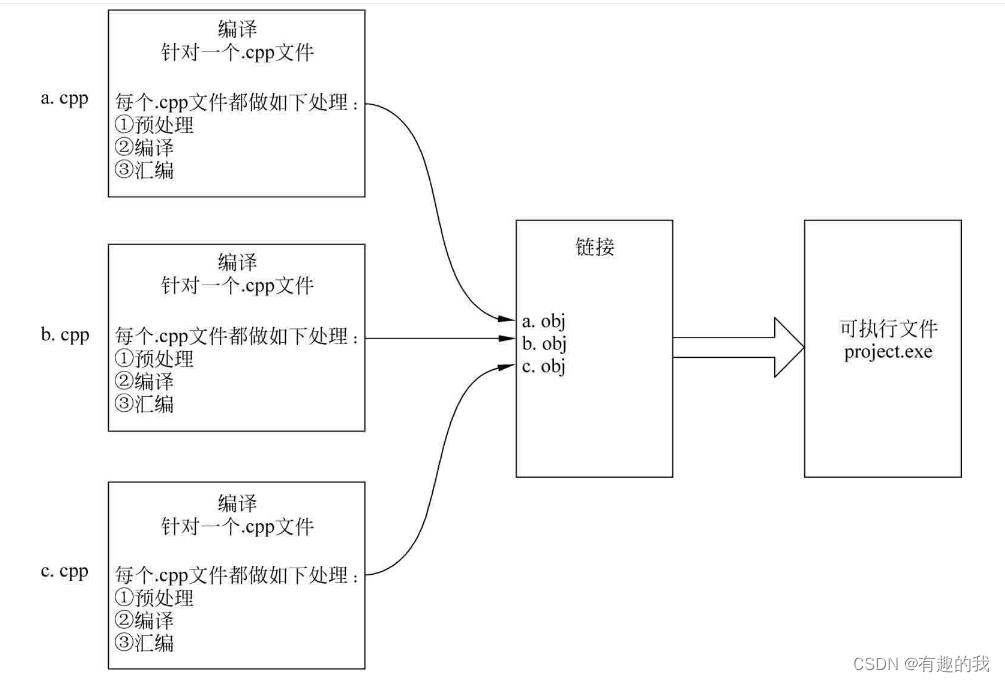
虽然可以用#include把任何一个其他文件的内容包含到当前文件中,但是在C语言中,最常见的做法还是一些源程序文件(扩展名为.c或者.cpp等)用#include把一些头文件(扩展名为.h或者.hpp等)包含进来,这种包含的感觉如图8.2所示。
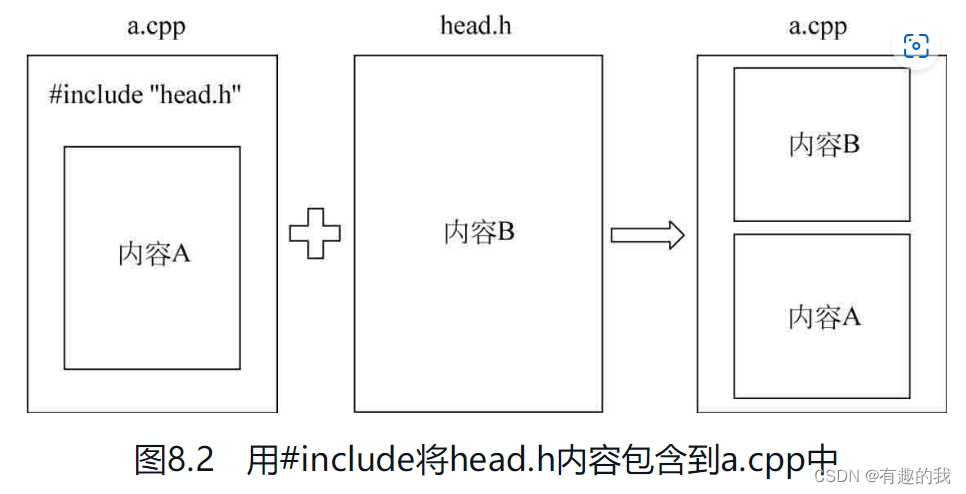
在图8.2中,a.cpp源程序文件中原有的内容为A,最上面有一个#include “head.h”,这意味着head.h文件中的内容B也属于a.cpp,所以最终a.cpp的完整内容应该是内容B在上面(因为#include语句在上面),内容A在下面,要认识到,使用了#include之后,就等价于把其他文件的内容包含到当前文件中来,所以当前文件的程序代码长度增加了。
#include命令非常有用,可以节省大量的重复劳动,可以把一些公用的内容写成一个文件,如前面讲过的宏定义,就可以写成一个公用文件(一般是一个.h头文件),然后每个其他的源程序文件都通过#include命令将这个公用文件包含进来。
一般来说,#include都是#include一个.h文件,很少出现#include一个.cpp(源程序文件)的情形。
,.h文件一般称为头文件,因为h代表head(头)的意思。常把一些宏定义、函数说明,甚至一些公共的#include命令、外部变量说明(extern)等,都写在一个.h头文件里,然后在源程序文件中#include这个.h文件即可。
#include所包含的文件名可以用"",也可以用<>,它们有什么区别吗?回忆一下:
· <>是去系统目录(Visual Studio知道系统目录在哪儿)中找所包含的文件,所以诸如要包含标准的stdio.h头文件(系统提供的)就用<>,如#include<stdio.h>。
· "“的含义是首先在当前目录查找要包含的文件,如果找不到,再到系统目录中查找。所以”"常用于自己写的一些想被其他文件#include的文件,让系统优先到当前目录中寻找所要包含的文件(因为自己写的这些被包含文件往往会放到当前目录)。
条件编译
一般情况下,在生成可执行文件的过程中,源程序文件中的所有代码行都参加编译,但有时候希望对其中的一部分内容只在满足一定的条件下才进行编译,也就是对一部分内容指定编译的条件,也有的时候,希望当满足某条件时对一组语句进行编译,而当条件不满足时编译另外一组语句,这都叫条件编译。
条件编译用得也比较频繁,尤其是写一些跨操作系统平台的代码,例如这个代码既要求能在Windows下编译运行,也能在Linux下编译运行,但程序代码中有些特殊的系统调用函数只能在Windows下编译运行或者只能在Linux下编译运行,此时,就有必要使用条件编译。
条件编译用得也比较频繁,尤其是写一些跨操作系统平台的代码,例如这个代码既要求能在Windows下编译运行,也能在Linux下编译运行,但程序代码中有些特殊的系统调用函数只能在Windows下编译运行或者只能在Linux下编译运行,此时,就有必要使用条件编译:

作用:当标识符被定义过(#define来定义),则对程序段1进行编译,否则对程序段2进行编译。当然,“#else程序段2”这部分可以没有,此时的形式就变成:

在进行程序调试的时候,常常需要输出一些信息,调试完毕后,不再输出这些信息。看看如下范例:

然后在其他一些需要输出调试信息的地方(如main函数中),可以写类似如下代码:

(2)形式2。

作用:若标识符未被定义(未用#define来定义),则编译程序段1,否则编译程序段2。与形式1正好相反,看看如下范例:

然后在其他一些需要输出调试信息的地方(如main函数中),可以写类似如下代码:

(3)形式3。

作用:当指定的表达式值为真(非0)时就编译程序段1,否则编译程序段2,所以,事先给出一定的条件,就可以使程序代码在不同条件下进行不同程序段的编译。当然可以将上述形式扩展一下,引入#elif。如下:

作用:当表达式1值为真(非0)时就编译程序段1,否则当表达式2的值为真(非0)则编译程序段2,否则编译程序段3。
看看如下范例:
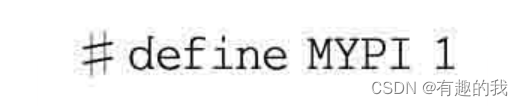
然后在其他一些需要输出调试信息的地方(如main函数中),可以写类似如下的代码:

从以上范例看起来,如果不用条件编译,似乎用if语句也可以做这些事情,那么用条件编译的好处是什么呢?
(1)最明显,条件编译可以减少目标程序长度。因为上面5行程序代码只相当于一行:

(2)项目开发也许会面临跨平台的问题,为了增加程序代码在各平台之间的可移植性,往往采用条件编译,如果不用条件编译,就很难解决同一套程序代码在Windows平台下和Linux平台下都能够在不修改源代码的情况下编译通过并生成可执行文件的问题。看看如下跨平台代码范例: