文章目录
- 1、ShuffleNetV1
- 1.1、分组卷积
- 1.2、channel shuffle
- 1.3、ShuffleNet基本单元
- 1.4、整体结构
- 2、ShuffleNetV2
- 2.1、基本单元
- 2.2、整体结构
1、ShuffleNetV1
1.1、分组卷积
- Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
- 分组卷积的矛盾——计算量
使用group convolution的网络有很多,如Xception,MobileNet,ResNeXt等。其中Xception和MobileNet采用了depthwise convolution,这是一种比较特殊的group convolution,此时分组数恰好等于通道数,意味着每个组只有一个特征图。但这些网络存在一个很大的弊端:采用了密集的1x1 pointwise convolution。在RexNeXt结构中,其实3x3的组卷积只占据了很少的计算量,而93.4%的计算量都是1x1的卷积所占据的理论计算量。
这个问题可以解决:对1x1卷积采用channel sparse connection, 即分组卷积,那样计算量就可以降下来了,但这就涉及到下面一个问题。
- 分组卷积的矛盾——特征通信
group convolution层另一个问题是不同组之间的特征图需要通信,否则就好像分了几个互不相干的路,大家各走各的,会降低网络的特征提取能力,这也可以解释为什么Xception,MobileNet等网络采用密集的1x1 pointwise convolution,因为要保证group convolution之后不同组的特征图之间的信息交流。
1.2、channel shuffle
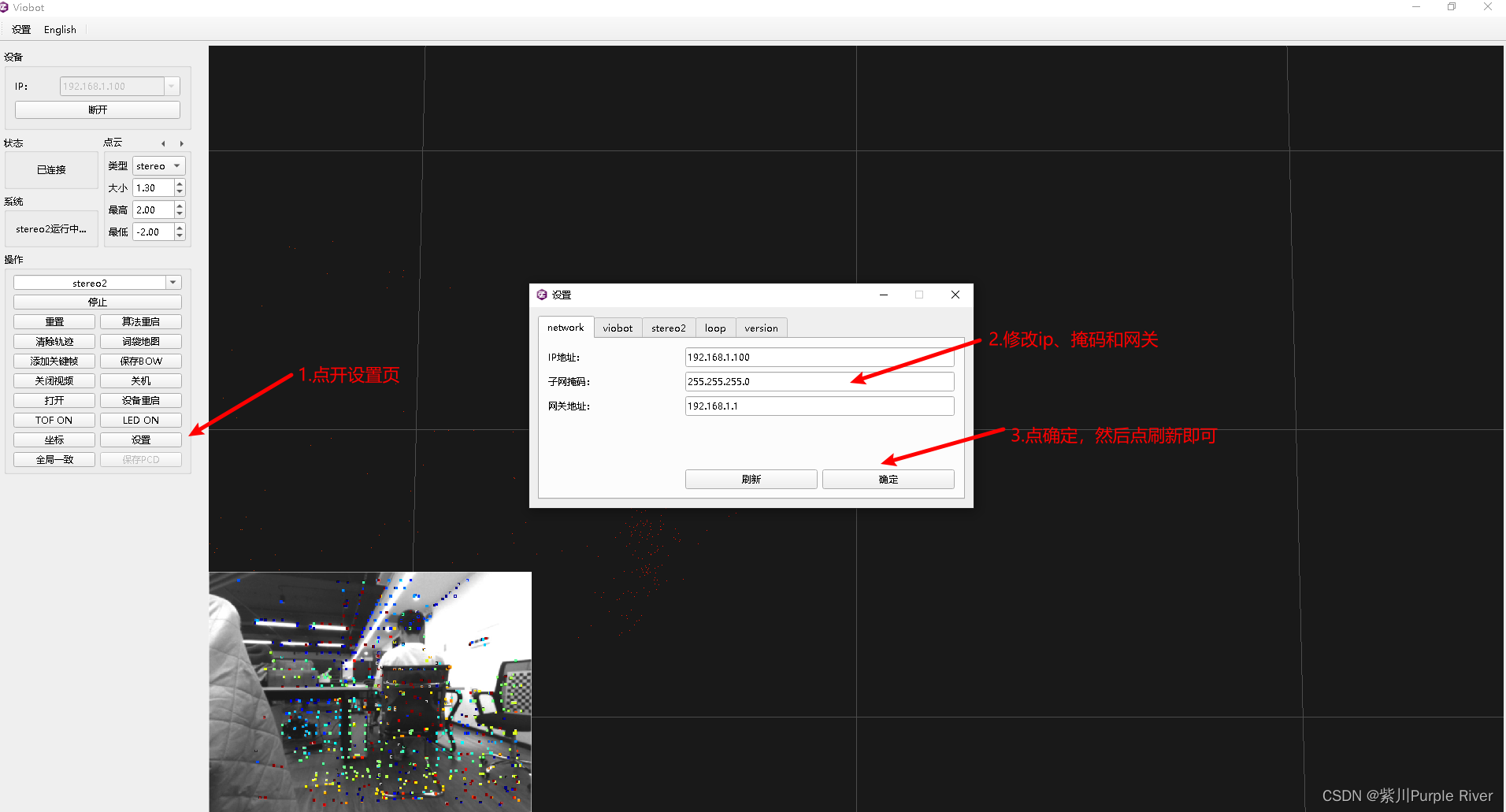
- 为达到特征通信目的,我们不采用dense pointwise convolution,考虑其他的思路:channel shuffle。其含义就是对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。进一步的展示了这一过程并随机,其实是“均匀地打乱”。

- 对于图a可以看见,特征矩阵会通过两个串行的组卷积操作计算。而对于普通的组卷积的计算可以发现,每次的卷积都是针对组内的一些特定的channel进行计卷积操作。也就是一直都是对同一个组进行卷积处理,各个组之间是没有进行交流的。
- GConv虽然能够减少参数与计算量,但GConv中不同组之间信息没有交流。所以基于这个问题,ShuffleNetV1提出了channels shuffle的思想。

- 如图b所示,对于输入的特征矩阵,通过了GConv卷积之后得到的特征矩阵,对这些G组的特征矩阵的内部同样划分为G组,也就是现在有原来的G份变成了G*G份。那么,对于每一个大组内的G组中的同样位置,来重新构成一个channel,也就是有第1组的第1个channel,第2组的第1个channel,第3组的第1个channel,重新拼接成一个新的组。
- 这样进行了Channel shuffle操作之后,再进行组卷积,那么现在就可以融合不同group之间的特征信息。这个就是ShuffleNetV1中的Channel shuffle思想。
1.3、ShuffleNet基本单元
- 下图a展示了基本ResNet轻量级结构,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
- 下图b展示了改进思路:将密集的1x1卷积替换成1x1的group convolution(因为前诉了主要计算量较大的地方就是这个密集的1x1的卷积操作),不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。这是针对stride为1的情况。
- 下图c的降采样版本,对原输入采用stride=2的3x3 avg pool,在depthwise convolution卷积处取stride=2保证两个通路shape相同,然后将得到特征图与输出进行连接concat操作而不是相加。极致的降低计算量与参数大小。

1.4、整体结构

- 可以看到开始使用的普通的3x3的卷积和max pool层。然后是三个阶段,每个阶段都是重复堆积了几个ShuffleNet的基本单元。对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍。后面的基本单元都是stride=1,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的。还有其中的g表示的是分组的数量,其中较多论文使用的是g=3的版本。
2、ShuffleNetV2
- ShuffleNet V2是旷视科技在ECCV2018上发表的最新研究成果,它在ShuffleNet[48]的基础上进一步考虑了内存访问开销(Memory Access Cost, MAC)对模型速度的影响,提出了模型加速的四项原则,并基于此提出了全新的轻量级网络架构。
- 经理论分析和实验证明,影响MAC指标的因素包括卷积层输入和输出特征图的通道数、分组卷积(Group Convolution)的数量、模型的分支数量以及元素级(element-wise)操作的数量,并得出相应的结论:
- 当卷积层输入输出通道数相等时,内存访问开销最小,模型计算效率越高;
- 内存访问开销随着分组卷积数量的增多而增大,减少分组卷积操作能提升模型速度;
- 模型的分支设计降低了可并行度,分支数越少模型速度越快;
- 元素级操作的对模型速度的影响较大,应尽可能减少该类型操作。
2.1、基本单元
- 回顾ShuffleNetV1的结构,其主要采用了两种技术:pointwise group convolutions与bottleneck-like structures。然后引入“channel shuffle”操作,以实现不同信道组之间的信息通信,提高准确性。
- both pointwise group convolutions与bottleneck structures均增加了MAC,与G1和G2不符合。这一成本是不可忽视的,特别是对于轻型机型。此外,使用太多group违反G3。shortcut connection中的元素element-wise add操作也是不可取的,违反了G4。因此,要实现高模型容量和高效率,关键问题是如何在不密集卷积和不过多分组的情况下,保持大量的、同样宽的信道。
- 其中图c对应stride=1的情况,图d对应stride=2的情况

- 为此,ShuffleNetV2做出了改进,如图( c )所示,在每个单元的开始,c特征通道的输入被分为两个分支(在ShuffleNetV2中这里是对channels均分成两半)。根据G3,不能使用太多的分支,所以其中一个分支不作改变,另外的一个分支由三个卷积组成,它们具有相同的输入和输出通道以满足G1。两个1 × 1卷积不再是组卷积,而改变为普通的1x1卷积操作,这是为了遵循G2(需要考虑组的代价)。卷积后,两个分支被连接起来,而不是相加(G4)。因此,通道的数量保持不变(G1)。然后使用与ShuffleNetV1中相同的“channels shuffle”操作来启用两个分支之间的信息通信。需要注意,ShuffleNet v1中的“Add”操作不再存在。像ReLU和depthwise convolutions 这样的元素操作只存在于一个分支中。
- 对于空间下采样,单元稍作修改,移除通道分离操作符。因此,输出通道的数量增加了一倍。具体结构见图(d)。所提出的构建块( c )( d )以及由此产生的网络称为ShuffleNet V2。基于上述分析,我们得出结论,该体系结构设计是高效的,因为它遵循了所有的指导原则。积木重复堆叠,构建整个网络。
2.2、整体结构
- 总体网络结构类似于ShuffleNet v1,如表所示。只有一个区别:在全局平均池之前增加了一个1 × 1的卷积层来混合特性,这在ShuffleNet v1中是没有的。与下图类似,每个block中的通道数量被缩放,生成不同复杂度的网络,标记为0.5x,1x,1.5x,2x

参考链接:
https://clichong.blog.csdn.net/article/details/118187759