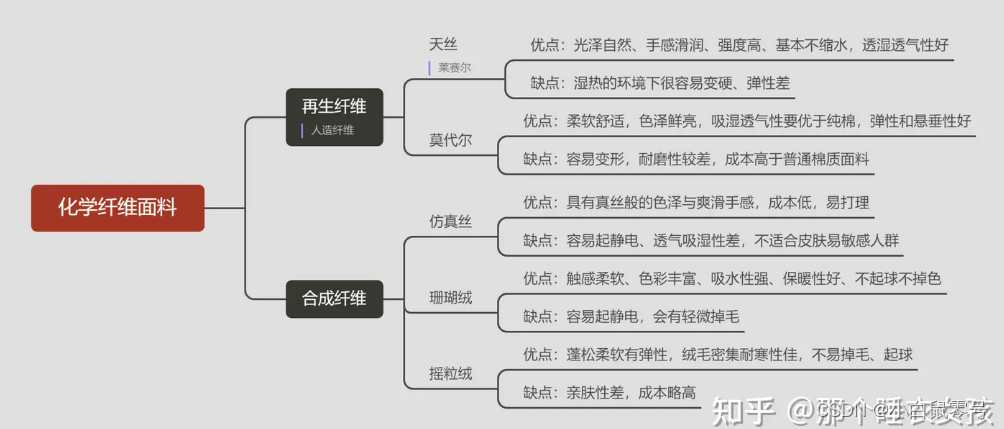
一、说明
我已经做了将近十年的数据分析。有时,我使用机器学习技术从数据中获取见解,并且我习惯于使用经典 ML。
虽然我已经通过了神经网络和深度学习的一些MOOC,但我从未在我的工作中使用过它们,这个领域对我来说似乎很有挑战性。我有所有这些偏见:
- 你需要学习很多东西才能开始使用深度学习:数学,不同的框架(我至少听说过其中的三个:和)和网络的架构。
PyTorchTensorFlowKeras - 需要庞大的数据集来拟合模型。
- 如果没有强大的计算机(它们还必须具有Nvidia GPU),就不可能获得像样的结果,因此很难进行设置。
- 启动并运行 ML 驱动的服务有很多样板文件:您需要处理前端和后端端。
我相信分析的主要目标是帮助产品团队根据数据做出正确的决策。如今,神经网络绝对可以改善我们的分析,即NLP有助于从文本中获得更多见解。因此,我决定再次尝试利用深度学习的力量对我有帮助。
这就是我开始 Fast.AI 课程的方式(它在 2022 年初更新,所以我想自之前对 TDS 的评论以来,内容已经发生了变化)。我已经意识到使用深度学习解决你的任务并不是那么困难。
本课程遵循自上而下的方法。因此,您从构建一个工作系统开始,然后才能更深入地了解所有必需的基础知识和细微差别。
我在第二周制作了我的第一个 ML 驱动的应用程序(你可以在这里尝试)。 这是一个图像分类模型,可以识别我最喜欢的狗品种。令人惊讶的是,即使我的数据集中只有几千张图像,它也能很好地工作。这让我感到鼓舞,我们现在可以轻松构建一项十年前完全神奇的服务。

因此,在本文中,您将找到有关构建和部署由机器学习提供支持的第一个服务的初学者级教程。
二、什么是深度学习?
当我们使用多层神经网络作为模型时,深度学习是机器学习的一个特定用例。
神经网络非常强大。根据通用近似定理,神经网络可以近似任何函数,这意味着它们能够解决任何任务。
现在,您可以将此模型视为一个黑盒,它接受输入(在我们的例子中 - 一个狗图像)并返回输出(在我们的例子中 - 一个标签)。

作者摄
三、构建模型
您可以在Kaggle上找到此阶段的完整代码。
我们将使用Kaggle笔记本来构建我们的深度学习模型。如果您还没有在 Kaggle 上拥有帐户,那么值得通过注册过程。Kaggle是数据科学家的流行平台,您可以在其中查找数据集,参加竞赛以及运行和共享代码。
您可以在 Kaggle 上创建一个笔记本,并在此处执行代码,就像在本地 Jupyter 笔记本中一样。Kaggle甚至提供了GPU,因此我们将能够非常快速地训练NN模型。

图片来源:作者
让我们从导入所有包开始,因为我们将使用许多 Fast.AI 工具。
from fastcore.all import *
from fastai.vision.all import *
from fastai.vision.widgets import *
from fastdownload import download_url四、加载数据
不言而喻,我们需要一个数据集来训练我们的模型。获取一组图像的最简单方法是使用搜索引擎。
DuckDuckGo搜索引擎有一个易于使用的API和方便的Python包(更多信息),所以我们将使用它。duckduckgo_search
让我们尝试搜索狗的图像。我们已指定仅使用具有知识共享许可的图像。license_image = any
from duckduckgo_search import DDGS
import itertools
with DDGS() as ddgs:
res = list(itertools.islice(ddgs.images('photo samoyed happy',
license_image = 'any'), 1))在输出中,我们获得了有关图像的所有信息:名称,URL和大小。
{
"title": "Happy Samoyed dog photo and wallpaper. Beautiful Happy Samoyed dog picture",
"image": "http://www.dogwallpapers.net/wallpapers/happy-samoyed-dog-wallpaper.jpg",
"thumbnail": "https://tse2.mm.bing.net/th?id=OIP.BqTE8dYqO-W9qcCXdGcF6QHaFL&pid=Api",
"url": "http://www.dogwallpapers.net/samoyed-dog/happy-samoyed-dog-wallpaper.html",
"height": 834, "width": 1193, "source": "Bing"
}现在我们可以使用 Fast.AI 工具下载图像并显示缩略图。

摄影:Barcs Tamás on Unsplash
我们看到一个快乐的萨摩耶德,这意味着它正在工作。因此,让我们加载更多照片。
我的目标是确定五种不同的狗品种(我最喜欢的品种)。我将为每个品种加载图片并将它们存储在单独的目录中。
breeds = ['siberian husky', 'corgi', 'pomeranian', 'retriever', 'samoyed']
path = Path('dogs_breeds') # defining path
for b in tqdm.tqdm(breeds):
dest = (path/b)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'photo {b}'))
sleep(10)
download_images(dest, urls=search_images(f'photo {b} puppy'))
sleep(10)
download_images(dest, urls=search_images(f'photo {b} sleep'))
sleep(10)
resize_images(path/b, max_size=400, dest=path/b)运行此代码后,您将在Kaggle的右侧面板上看到所有加载的照片。

图片来源:作者
下一步是将数据转换为适合 Fast.AI 模型的格式 — 。DataBlock
您需要为此对象指定一些参数,但我将只强调最重要的参数:
splitter=RandomSplitter(valid_pct=0.2, seed=18):Fast.AI 要求您选择一个验证集。验证集是将用于估计模型质量的保留数据。训练期间不会使用验证数据来防止过度拟合。在我们的例子中,验证集是数据集的随机 20%。我们指定了参数,以便下次能够重现完全相同的拆分。seeditem_tfms=[Resize(256, method=’squish’)]:神经网络批量处理图像。这就是为什么我们必须拥有相同大小的图片。图像大小调整有不同的方法,我们现在使用 squish,但我们稍后会更详细地讨论它。
我们已经定义了一个数据块。该函数可以向我们显示一组带有标签的随机图像。show_batch

摄影:Angel Luciano on Unsplash |摄影:Brigitta Botrágyi on Unsplash |摄影:Charlotte Freeman on Unsplash
数据看起来不错,所以让我们继续训练。
五、训练模型
您可能会感到惊讶,但下面的两行代码将完成所有工作。

我们使用了预训练模型(具有 18 个深层的卷积神经网络 — )。这就是为什么我们称该函数。Resnet18fine_tune
我们对模型进行了三个时期的训练,这意味着模型看到了整个数据集 3 次。
我们还指定了指标 — (正确标记的图片的份额)。您可以在每个纪元后的结果中看到此指标(仅使用验证集计算,以免扭曲结果)。但是,它不会在优化过程中使用,仅供您参考。accuracy
整个过程大约需要 30 分钟,现在我们的模型可以预测狗的品种,准确率为 94.45%。干得好!但是我们能改善这个结果吗?
六、改进模型:数据清理和扩充
如果希望看到第一个模型尽快工作,请随时将本部分留到以后,并转到模型的部署。
首先,让我们看看模型的错误:它是否无法区分柯基犬和哈士奇犬或博美犬和猎犬。我们可以使用它。请注意,混淆矩阵也仅使用验证集进行计算。confusion_matrix

Fast.AI 课程中分享的另一个生活技巧是可以使用模型来清理我们的数据。对于它,我们可以看到损失最高的图像:可能是模型错误但置信度高或正确但置信度低的情况。

摄影:Benjamin Vang在Unsplash |摄影:Xennie Moore on Unsplash |摄影:Alvan Nee on Unsplash
显然,第一张图片的标签不正确,而第二张图片同时包含哈士奇和柯基。所以有一些改进的余地。
幸运的是,Fast.AI 提供了一个方便的小部件,可以帮助我们快速解决数据问题。可以在笔记本中对其进行初始化,然后可以更改数据集中的标签。ImageClassifierCleaner
cleaner = ImageClassifierCleaner(learn)
cleaner 在每个类别之后,您可以运行以下代码来解决问题:删除图像或将其移动到正确的文件夹。
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
for idx,breed in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/breed)现在我们可以再次训练我们的模型,并看到准确率有所提高:95.4% vs 94.5%。

正确识别的柯基犬的比例从88%增加到96%。明!

改进模型的另一种方法是更改调整大小的方法。我们使用了挤压方法,但如您所见,它可以改变自然物体的比例。让我们尝试更具想象力并使用增强功能。
增强是对图像的更改(例如,对比度改进、旋转或裁剪)。它将为我们的模型提供更多可变数据,并有望提高其质量。
与 Fast.AI 一样,您只需更改几个参数即可添加增强功能。

照片由FLOUFFY在Unsplash上拍摄
此外,由于使用增强模型在每个时期都会看到略有不同的图片,因此我们可以增加时期的数量。经过六个时期,我们达到了 95.65% 的准确率——结果要好一些。整个过程花了大约一个小时。
七、下载模型
最后一步是下载我们的模型。这很简单。
learn.export('cuttest_dogs_model.pkl') 然后,您将保存一个标准文件(用于存储对象的常见Python格式)。只需选择Kaggle笔记本右侧面板中的文件旁边,您就可以在计算机上获得模型。pickleMore actions

现在我们有了经过训练的模型,让我们部署它,以便您可以与世界共享结果。
八、部署模型
我们将使用HuggingFace Spaces和Gradio来构建我们的Web应用程序。
8.1 设置HuggingFace空间
HuggingFace是一家为机器学习提供便捷工具的公司,例如,流行的转换器库或共享模型和数据集的工具。今天,我们将使用他们的空间来托管我们的应用程序。
首先,如果您尚未注册,则需要创建一个帐户。只需几分钟。点击此链接。
现在是时候创建一个新的空间了。前往“空间”选项卡,然后按“创建”按钮。您可以在文档中找到包含更多详细信息的说明。
然后,您需要指定以下参数:
- 名称(它将用于您的应用程序URL,因此请明智地选择),
- 许可证(我选择了开源 Apache 2.0 许可证)
- SDK(在本例中我将使用 Gradio)。

Then user-friendly HuggingFace shows you instructions. TL;DR now you have a Git repository, and you need to commit your code there.
Git 有一个细微差别。由于您的模型可能非常大,因此最好设置 Git LFS(大文件存储),然后 Git 不会跟踪此文件的所有更改。要进行安装,请按照站点上的说明进行操作。
-- cloning repo
git clone https://huggingface.co/spaces/<your_login>/<your_app_name>
cd <your_app_name>
-- setting up git-lfs
git lfs install
git lfs track "*.pkl"
git add .gitattributes
git commit -m "update gitattributes to use lfs for pkl files"8.2 Gradio
Gradio是一个框架,允许你只使用Python构建愉快和友好的Web应用程序。这就是为什么它是原型设计的宝贵工具(特别是对于像我这样没有深厚JavaScript知识的人来说)。
在 Gradio 中,我们将定义我们的接口,指定以下参数:
- 输入 — 图像,
- 输出 — 具有五个可能类的标签,
- 标题、描述和一组示例图像(我们还必须将它们提交到 repo),
enable_queue=True将帮助应用程序处理大量流量,如果它变得非常流行,- 要为输入图像执行的函数。
为了获取输入图像的标签,我们需要定义一个预测函数,该函数加载我们的模型并返回一个字典,其中包含每个类的概率。
最后,我们将有以下代码app.py
import gradio as gr
from fastai.vision.all import *
learn = load_learner('cuttest_dogs_model.pkl')
labels = learn.dls.vocab # list of model classes
def predict(img):
img = PILImage.create(img)
pred,pred_idx,probs = learn.predict(img)
return {labels[i]: float(probs[i]) for i in range(len(labels))}
gr.Interface(
fn=predict,
inputs=gr.inputs.Image(shape=(512, 512)),
outputs=gr.outputs.Label(num_top_classes=5),
title="The Cuttest Dogs Classifier 🐶🐕🦮🐕🦺",
description="Classifier trainded on images of huskies, retrievers, pomeranians, corgis and samoyeds. Created as a demo for Deep Learning app using HuggingFace Spaces & Gradio.",
examples=['husky.jpg', 'retriever.jpg', 'corgi.jpg', 'pomeranian.jpg', 'samoyed.jpg'],
enable_queue=True).launch()如果您想了解有关 Gradio 的更多信息,请阅读文档。
让我们也创建文件,然后这个库将安装在我们的服务器上。requirements.txtfastai
所以剩下的唯一一点就是将所有内容推送到 HuggingFace Git 存储库。
git add *
git commit -am 'First version of Cuttest Dogs app'
git push您可以在 GitHub 上找到完整的代码。
推送文件后,返回 HuggingFace 空间,你会看到一张类似的图片,展示了构建过程。如果一切正常,您的应用将在几分钟内运行。

如果有任何问题,您将看到堆栈跟踪。然后,您将不得不返回到代码,修复错误,推送新版本,然后再等待几分钟。
8.3 开始启动
现在我们可以使用这个模型和真实照片来验证我家的狗实际上是柯基犬。
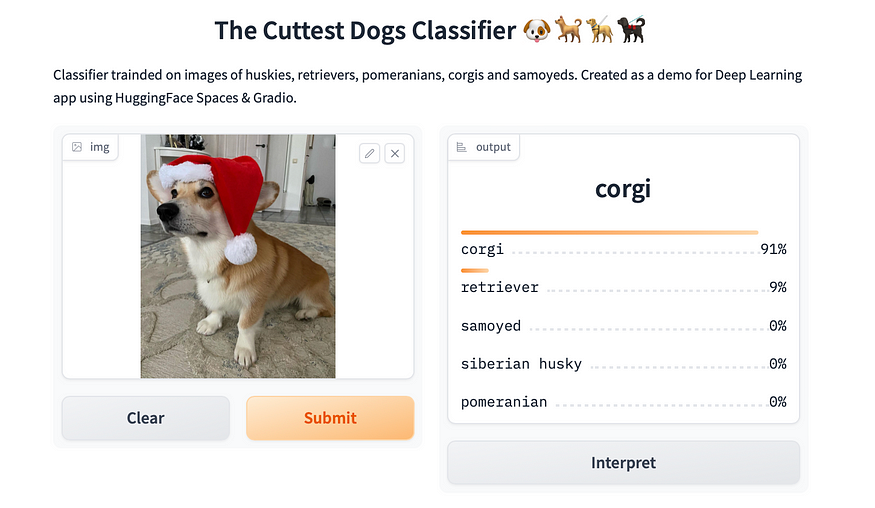
九 后记
今天,我们已经完成了构建深度学习应用程序的整个过程:从获取数据集和拟合模型到编写和部署 Web 应用程序。希望您能够完成本教程,现在您正在生产中测试您的出色模型。









![[python] 使用Jieba工具中文分词及文本聚类概念](https://img-blog.csdnimg.cn/66785b2936f24289b6a5c5a592e23666.png)