k8s 部署全程在超级用户下进行
sudo su
本文请根据大纲顺序阅读!
一、配置基础环境(在全部节点执行)
1、安装docker 使用apt安装containerd
新版k8s已经弃用docker转为containerd,如果要将docker改为containerd详见:将节点上的容器运行时从 Docker Engine 改为 containerd))
官网文档 : Install Docker Engine on Ubuntu | Docker Documentation
- 卸载旧版本docker安装包
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done
- 更新
apt包索引并安装包以允许apt通过 HTTPS 使用存储库:
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
- 添加Docker官方GPG密钥:
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
- 使用以下命令设置存储库(清华源):
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
- 更新
apt包索引:
sudo apt-get update
- 安装 Docker 引擎、containerd 和 Docker Compose。
旧版 k8s:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
新版k8s:只需要安装containerd即可,到这一步就可以结束了
sudo apt-get install containerd.io
- 通过运行镜像来验证Docker Engine安装是否成功
hello-world。
sudo docker run hello-world
- 配置docker 阿里云镜像
加速器地址在阿里云控制台申请:
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://i848vj4w.mirror.aliyuncs.com"] } EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
#查看是否配置成功
docker info
1、安装容器运行时
- 安装containerd
如果你已经执行了上面的教程安装了最新版的docker,实际上containerd也已经被安装,无需重新安装。如果你想单独安装containerd,而不安装docker,请按1、安装docker 使用apt安装containerd 步骤执行并在apt-get install时只执行containerd.io即可,或使用二进制安装
- 配置 containerd
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
- 配置阿里云镜像
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://bqr1dr1n.mirror.aliyuncs.com"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.aliyuncs.com/google_containers"]
endpoint = ["https://registry.aliyuncs.com/k8sxio"]
- 重启 containerd
sudo systemctl restart containerd
2、配置 systemd cgroup驱动
- 结合
runc使用systemdcgroup 驱动,在/etc/containerd/config.toml中设置:
sudo vim config.toml
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
- 重启containerd:
sudo systemctl restart containerd
3、禁用Swap分区: Kubernetes不建议在节点上启用Swap分区,因此需要禁用它。可以使用以下命令禁用Swap分区:
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
4、在各节点添加hosts配置
vim /etc/hosts
192.168.16.200 k8s-master
192.168.16.201 k8s-node1
192.168.16.202 k8s-node2
5、转发 IPv4 并让 iptables 看到桥接流量
执行下述指令:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
通过运行以下指令确认 br_netfilter 和 overlay 模块被加载:
lsmod | grep br_netfilter
lsmod | grep overlay
通过运行以下指令确认 net.bridge.bridge-nf-call-iptables、net.bridge.bridge-nf-call-ip6tables 和 net.ipv4.ip_forward 系统变量在你的 sysctl 配置中被设置为 1:
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
6、关闭SELinux(ubuntu默认没有安装)
sudo setenforce 0
vim /etc/selinux/config
SELINUX=disabled
7、安装 kubeadm、kubelet 和 kubectl
- 更新
apt包索引并安装使用 Kubernetesapt仓库所需要的包:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl
- 下载 Google Cloud 公开签名秘钥(阿里云镜像)
curl -fsSL https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-archive-keyring.gpg
- 添加 Kubernetes apt 仓库(阿里云镜像):
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
- 更新
apt包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本:
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
#锁定版本
sudo apt-mark hold kubelet kubeadm kubectl
8、时间同步
# 安装 NTP
sudo apt update
sudo apt install -y ntp
# 配置 NTP 服务器
sudo vim /etc/ntp.conf
#添加ntp服务器 中国开源免费NTP服务器
server cn.pool.ntp.org
#重新启动 NTP 服务:
sudo systemctl restart ntp
#验证时间同步状态:
#查看 NTP 服务器状态
ntpq -p
#查看系统时间
date
9、关闭防火墙
不建议直接关闭防火墙,而是放行要用的端口(但不关闭防火墙容易遇到很多问题)
ufw disable
systemctl disable firewalld #如果是已经启动的pod被防火墙拦截了,有时候需要重启服务器才生效
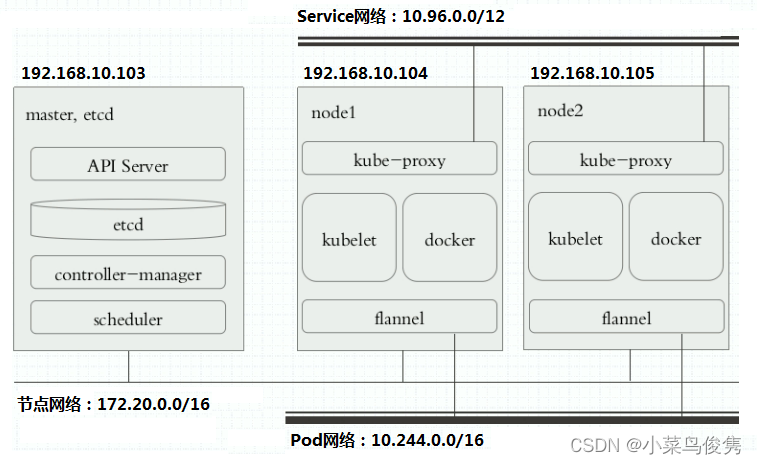
二、使用kubeadm部署工具安装kubernetes
- k8s架构示意图
1、初始化平面控制器 (control-plane node)
docker提前拉取初始化需要的镜像(新版已不使用docker,请跳过… )
#查看镜像版本
kubeadm config images list
命令返回值如下:
registry.k8s.io/kube-apiserver:v1.27.4
registry.k8s.io/kube-controller-manager:v1.27.4
registry.k8s.io/kube-scheduler:v1.27.4
registry.k8s.io/kube-proxy:v1.27.4
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.7-0
registry.k8s.io/coredns/coredns:v1.10.1
这些镜像是 Kubernetes 集群的核心组件,每个组件都扮演着不同的角色,负责集群的不同功能。以下是这些镜像的作用简介:
registry.k8s.io/kube-apiserver:v1.27.4:
Kube API Server 是 Kubernetes 控制平面的核心组件之一,它提供了 Kubernetes API 的接入点,用于管理集群的操作和资源。它是集群中的主要入口,负责接收 API 请求、身份验证和授权,以及将请求转发到其他控制平面组件。
registry.k8s.io/kube-controller-manager:v1.27.4:
Kube Controller Manager 是 Kubernetes 控制平面的组件之一,它负责管理控制循环,处理不同的控制器任务,例如 ReplicaSet、Deployment、NodeController 等。它持续监控集群状态,并确保期望状态与实际状态一致。
registry.k8s.io/kube-scheduler:v1.27.4:
Kube Scheduler 负责将新创建的 Pod 调度到集群中的节点上。它基于资源需求、亲和性、反亲和性等策略,选择适合的节点来运行 Pod。
registry.k8s.io/kube-proxy:v1.27.4:
Kube Proxy 是 Kubernetes 集群中的网络代理,负责维护节点上的网络规则,以便正确路由到相应的 Pod。它支持负载均衡和服务发现功能。
registry.k8s.io/pause:3.9:
Pause 镜像是一个微型容器,每个 Pod 都会运行一个 Pause 容器作为网络命名空间的初始化进程。它充当了所有容器的父进程,帮助容器共享网络命名空间和存储卷。
registry.k8s.io/etcd:3.5.7-0:
Etcd 是 Kubernetes 集群的分布式键值存储,用于存储集群状态和配置信息。它支持高可用性和一致性,是集群的重要组成部分。
registry.k8s.io/coredns/coredns:v1.10.1:
CoreDNS 是 Kubernetes 集群的默认 DNS 服务,用于处理 Pod 和服务名称解析。它支持插件机制,可以扩展到不同的 DNS 后端和功能。
这些组件一起协同工作,构成了 Kubernetes 集群的核心基础架构,支持容器编排和管理。
-
由于国内有墙,这里应该是拉不到的,得修改k8s.gcr.io/为国内的镜像registry.aliyuncs.com/google_containers/
-
编写拉取镜像的脚本
vim kube-init-image-pull.sh
#!/bin/bash
# Get the image list with versions from kubeadm
image_list=$(kubeadm config images list)
# Loop through the images, pull them, rename them, and delete aliased images
for oldimage in $image_list; do
echo "old image: $oldimage"
#替换为国内镜像名称
image=$(echo "$oldimage" | sed 's|registry.k8s.io/|registry.aliyuncs.com/google_containers/|')
echo "Pulling image: $image"
docker pull $image
#拉取后要修改回原来的名称
docker tag $image $oldimage
docker rmi $image
done
chmod 777 kube-init-image-pull.sh
./kube-init-image-pull.sh
coredns如果拉不到 可能是因为名称命名规则不太一样
docker pull registry.aliyuncs.com/google_containers/coredns/coredns:v1.10.1 改为
docker pull registry.aliyuncs.com/google_containers/coredns:v1.10.1
手动拉一下并tag修改名称
1)、使用配置文件初始化master
- 生成初始化配置文件到kube的目录
kubeadm config print init-defaults > /home/kube/master/init-default.yaml
想了解更多配置 请参阅:kubeadm 配置 (v1beta3) | Kubernetes (p2hp.com)
sudo vim init-default.yaml
- 需要关注或修改的配置:
kubernetesVersion: 1.27.4
kubeadm version 命令查看控制面的目标版本。
advertiseAddress: 192.168.16.200
bindPort: 6443
表示控制面的稳定ip和端口,填当前节点的ip,端口可以默认6443,这两个值可以使 controlPlaneEndpoint 代替。
imageRepository :registry.aliyuncs.com/google_containers (上面使用脚本提前拉镜像的跳过,因为已经重命名过镜像了,所以这里不需要改!!!改了反而报错。)
设置用来拉取镜像的容器仓库。如果此字段为空,默认使用registry.k8s.io。 当 Kubernetes 用来执行 CI 构造时(Kubernetes 版本以 ci/ 开头), 将默认使用gcr.io/k8s-staging-ci-images 来拉取控制面组件镜像,而使用registry.k8s.io来拉取所有其他镜像。
这里修改为阿里云的源,上面脚本的作用是跟这个配置修改的作用是一样的。
imagePullPolicy:IfNotPresent
设定 "kubeadm init" 和 "kubeadm join" 操作期间的镜像拉取策略。此字段的取值可以是 "Always"、"IfNotPresent" 或 "Never" 之一。 若此字段未设置,则 kubeadm 使用 "IfNotPresent" 作为其默认值,换言之, 当镜像在主机上不存在时才执行拉取操作。
podSubnet:10.244.0.0/16
podSubnet 为 Pod 所使用的子网。 默认配置没有该选项,在Network选项下给其增加该配置
配置驱动为systemd:
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
参考配置如下:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.16.200
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: node
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.27.4
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
- 初始化master
sudo kubeadm init --config=init-default.yaml --ignore-preflight-errors=all
可能会遇到此错误:
错误1:CRI插件被关闭
ERROR CRI]: container runtime is not running: output: time="2023-08-09T21:57:06+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
官网上的解释是:配置 systemd cgroup 驱动
说明:
如果你从软件包(例如,RPM 或者 .deb)中安装 containerd,你可能会发现其中默认禁止了 CRI 集成插件。
你需要启用 CRI 支持才能在 Kubernetes 集群中使用 containerd。 要确保 cri 没有出现在 /etc/containerd/config.toml 文件中 disabled_plugins 列表内。如果你更改了这个文件,也请记得要重启 containerd。
如果你在初次安装集群后或安装 CNI 后遇到容器崩溃循环,则随软件包提供的 containerd 配置可能包含不兼容的配置参数。考虑按照 getting-started.md 中指定的 containerd config default > /etc/containerd/config.toml 重置 containerd 配置,然后相应地设置上述配置参数。
vim /etc/containerd/config.toml
#修改这行为[]
#disabled_plugins = ["cri"]
disabled_plugins = []
#重新启动
sudo systemctl restart containerd
#重新初始化master
sudo kubeadm reset
sudo kubeadm init --config=init-default.yaml --ignore-preflight-errors=all
错误2:
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
- 查看详细报错
journalctl -xeu kubelet
- 显示的错误 (failed to get sandbox image “registry.k8s.io/pause:3.6”) 跟 pause镜像版本对不上,我用的是3.9但是初始化的时候是3.6
#查看镜像版本
kubeadm config images list
#查看containerd拉取的镜像
crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock images
在你的 containerd 配置中, 你可以通过设置以下选项重载沙箱镜像:
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
systemctl restart containerd
Your Kubernetes control-plane has initialized successfully!
初始化完成后 会输出这样一段话:
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.16.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:438c87675185beeb9a495fc0b51d0993fb810340b5d793aa2b6b915cade42776
最后两行记得拷贝记录一下,后面初始化node的时候会用到
如果是root用户,要运行
export KUBECONFIG=/etc/kubernetes/admin.conf
然后运行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
这段话提示我们需要部署一个pod network,在以下网址里面有很多种不同的插件,这里我们选择flannel
wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
使用以下命令查看镜像拉取状态,pending可能是还在下载镜像
kubectl get pods -n kube-system -o wide
等全部镜像变成RUNNING状态后,master状态也会变成Ready
kubectl get nodes
2)、使用配置文件初始化node
node的初始化和master的初始化步骤基本一致,除了初始化master的步骤(但要包括那错误例子中pause的配置)不需要做,其他的参考上面步骤重新做一遍即可,不同的是init命令换成了join命令
kubeadm join 192.168.16.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:438c87675185beeb9a495fc0b51d0993fb810340b5d793aa2b6b915cade42776
就是让你们拷贝的那段,如果忘记了,可以使用以下命令重新获取
kubeadm token create --print-join-command
查看nodes的状态
kubectl get nodes
如果报以下错误
couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp 127.0.0.1:8080: connect: connection refused
查看/etc/kubernetes/kubelet.conf文件是否存在
不存在就先执行
kubeadm reset 后重新 kubeadm join
然后添加到环境变量中
echo "export KUBECONFIG=/etc/kubernetes/kubelet.conf" >> /etc/profile
source /etc/profile
再执行就正常了
kubectl get nodes
看到node和master的状态都是Ready就没问题了!
三、 部署Kuboard控制台
1、搭建Kuboard
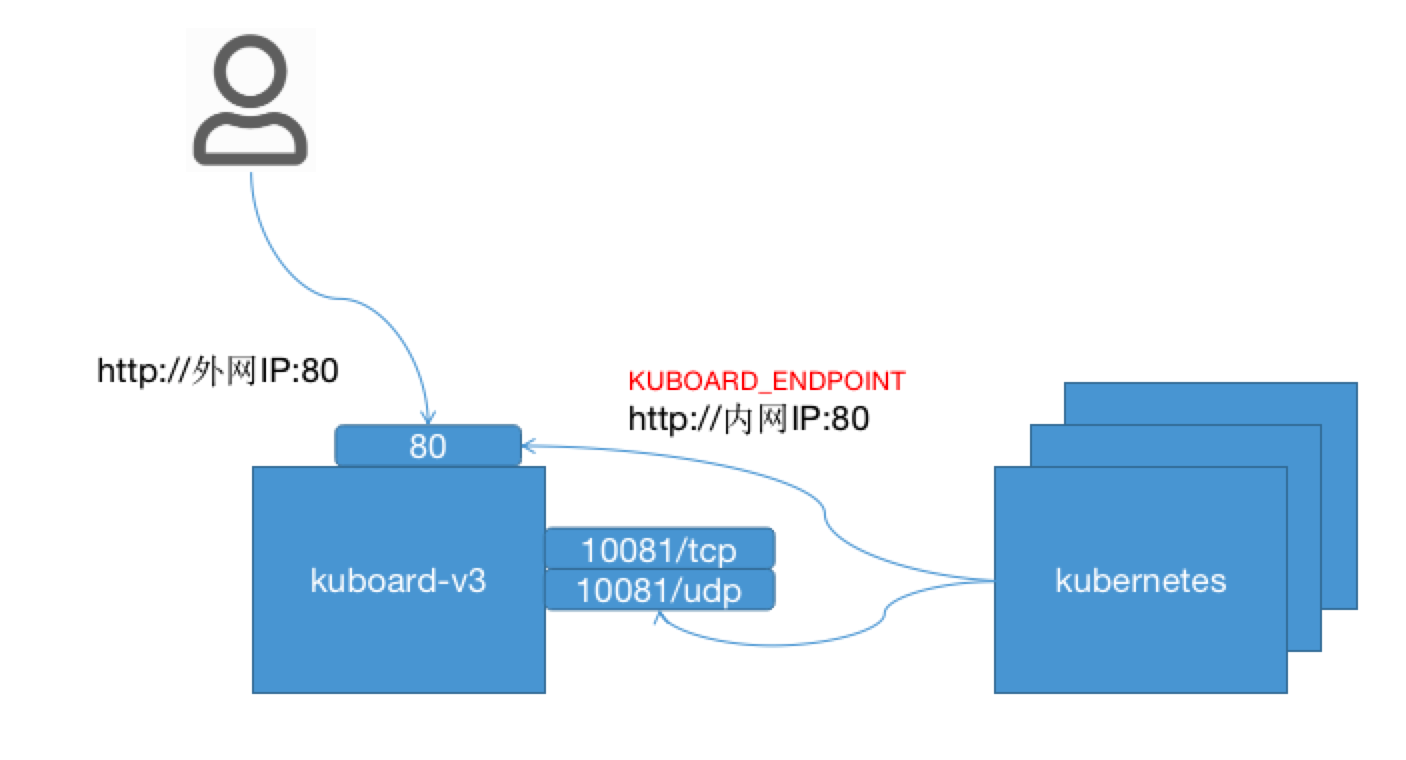
在正式安装 kuboard v3 之前,需做好一个简单的部署计划的设计,在本例中,各组件之间的连接方式,如下图所示:
- 假设用户通过 http://外网IP:80 访问 Kuboard v3;
- 安装在 Kubernetes 中的 Kuboard Agent 通过
内网IP访问 Kuboard 的 Web 服务端口 80 和 Kuboard Agent Server 端口 10081。
- 拉取Kuboard镜像
sudo docker pull eipwork/kuboard:v3
- 启动kuboard容器
sudo docker run -d \
--restart=unless-stopped \
--name=kuboard \
-p 8080:80/tcp \
-p 10081:10081/tcp \
-e KUBOARD_ENDPOINT="http://内网IP:80" \
-e KUBOARD_AGENT_SERVER_TCP_PORT="10081" \
-v ./kuboard-data:/data \
eipwork/kuboard:v3
# 也可以使用镜像 swr.cn-east-2.myhuaweicloud.com/kuboard/kuboard:v3 ,可以更快地完成镜像下载。
# 请不要使用 127.0.0.1 或者 localhost 作为内网 IP \
# Kuboard 不需要和 K8S 在同一个网段,Kuboard Agent 甚至可以通过代理访问 Kuboard Server \
参数解释
- 建议将此命令保存为一个 shell 脚本,例如
start-kuboard.sh,后续升级 Kuboard 或恢复 Kuboard 时,需要通过此命令了解到最初安装 Kuboard 时所使用的参数; - 第 4 行,将 Kuboard Web 端口 80 映射到宿主机的
8080端口(您可以根据自己的情况选择宿主机的其他端口); - 第 5 行,将 Kuboard Agent Server 的端口
10081/tcp映射到宿主机的10081端口(您可以根据自己的情况选择宿主机的其他端口); - 第 6 行,指定 KUBOARD_ENDPOINT 为
http://内网IP,如果后续修改此参数,需要将已导入的 Kubernetes 集群从 Kuboard 中删除,再重新导入; - 第 7 行,指定 KUBOARD_AGENT_SERVER 的端口为
10081,此参数与第 5 行中的宿主机端口应保持一致,修改此参数不会改变容器内监听的端口10081,例如,如果第 5 行为-p 30081:10081/tcp则第 7 行应该修改为-e KUBOARD_AGENT_SERVER_TCP_PORT="30081"; - 第 8 行,将持久化数据
/data目录映射到脚本文件夹下的kuboard-data` 路径,请根据您自己的情况调整宿主机路径;
其他参数
- 在启动命令行中增加环境变量
KUBOARD_ADMIN_DERAULT_PASSWORD,可以设置admin用户的初始默认密码。
2、 访问 Kuboard v3.x
在浏览器输入 http://your-host-ip:8080 即可访问 Kuboard v3.x 的界面,登录方式:
- 用户名:
admin - 密 码:
Kuboard123
3、添加K8s集群到Kuboard
-
选择以agent方式添加k8s集群

-
选择第二个Agent镜像

-
拷贝命令并在master上执行
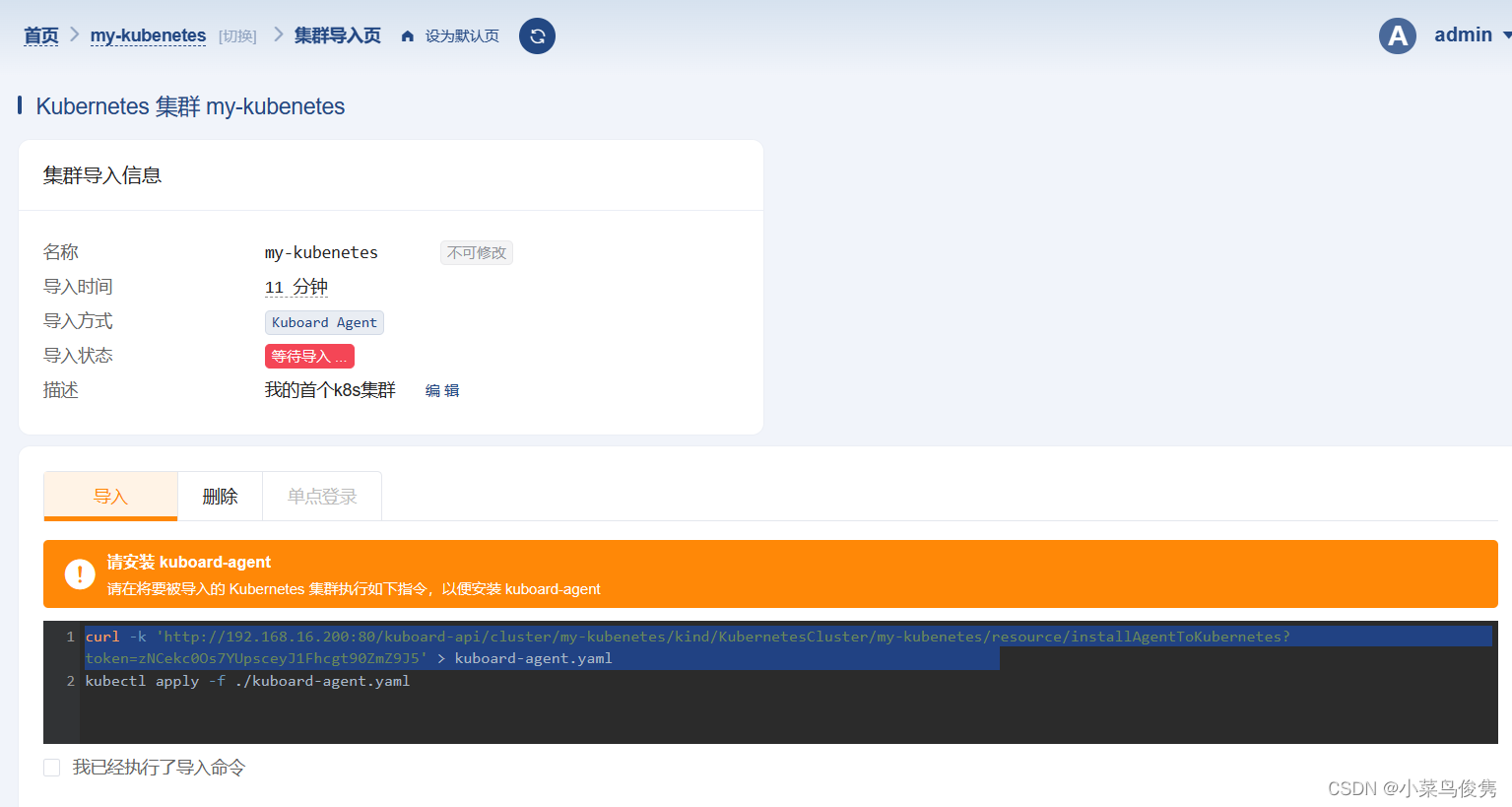
注意这里的80端口要更换成你映射到宿主机的端口,比如我设置的是8080
curl -k 'http://192.168.16.200:8080/kuboard-api/cluster/my-kubenetes/kind/KubernetesCluster/my-kubenetes/resource/installAgentToKubernetes?token=zNCekc0Os7YUpsceyJ1Fhcgt90ZmZ9J5' > kuboard-agent.yaml
- yaml里面的80端口也改成8080
vim kuboard-agent.yaml
- 启动pods
kubectl apply -f ./kuboard-agent.yaml
- 查看日志,确保都是RUNNING状态
kubectl get pods -n kuboard -o wide -l "k8s.kuboard.cn/name in (kuboard-agent-25i3sy, kuboard-agent-25i3sy-2)"
- 集群导入成功

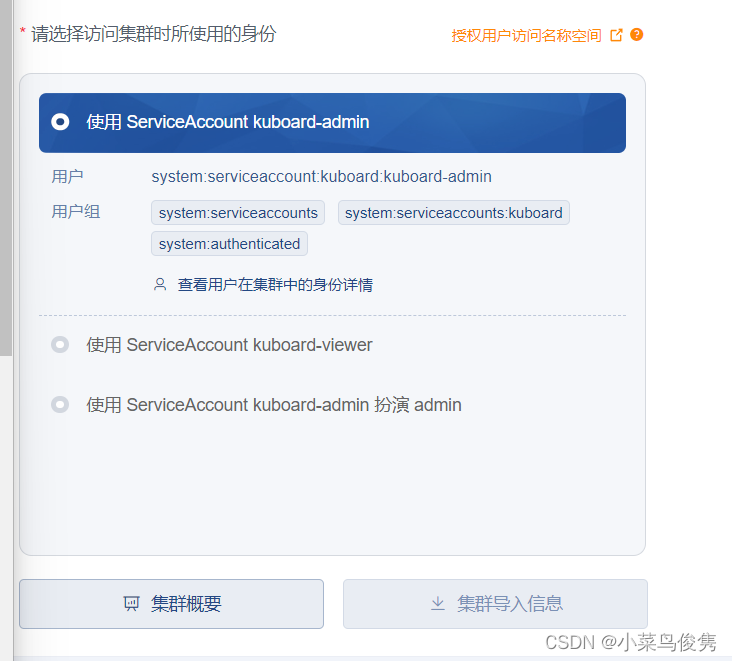
- 选择管理员角色登录
- 至此整个k8s环境就部署好啦
![![[Pasted image 20230817200026.png]]](https://img-blog.csdnimg.cn/a3afe7fe4a0946f3868e795aa434dd8a.png)