🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
感知器 (Perceptron) & MLP-BP神经网络
阅读参考文献:
一个非常有趣的讲解 (感知器是一种单层神经网络,而多层感知器则称为神经网络。): https://towardsdatascience.com/what-the-hell-is-perceptron-626217814f53
感知器
感知器是神经网络的 Fundamentals
在1977年由Frank Roseblatt 所发明的感知器是最简单的ANN架构之一(线性函数加上硬阈值,这里阈值不一定是0),受在一开始的生物神经元模型启发(XOR问题逻辑问题),称之为阈值逻辑单元(TLU,threshold logistic unit) 或线性阈值单元(LTU,linear threshold unit),其是一个使用阶跃函数的神经元来计算,可被用于线性可分二分类任务,也可设置多个感知器输出实现多输出分类以输出n个二进制结果(缺点是各种类别关系无法学习),一般来说还会添加一个偏置特征1来增加模型灵活性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tq1dFdVw-1692271552392)(core algorithm.assets/FXo8u7JaQAANoNm.png)]](https://img-blog.csdnimg.cn/d065418f9d7d478bbf799be99bdabd5d.png)
在感知器中引入一个偏置特征神经元1的目的是为了增加模型的灵活性和表达能力。这个偏置特征对应于一个固定且始终为1的输入,其对应的权重称为偏置项(bias)。通过调整偏置项的权重,我们可以控制 TLU 的决策边界在特征空间中平移或倾斜。(正常来说的话,这个偏置项都是在每个神经元当中所存在,而不是作为单独一个输入存在,能更灵活)
在感知器中,将偏置特征固定为1的选择是为了方便计算和表示。
当我们引入一个偏置特征时,可以将其视为与其他输入特征一样的维度,并赋予它一个固定的值1。这样做有以下几个好处:
- 方便计算:将偏置项乘以1相当于直接使用权重来表示该偏置项。在进行加权求和并应用阈值函数时,不需要额外操作或考虑。
- 参数统一性:通过将偏置项作为一个独立的权重进行处理,使得所有输入特征(包括原始输入和偏置)具有相同的形式和统一性。
- 简洁明了:固定为1的偏置特征能够简化模型参数表示,并使其更易理解和解释。
请注意,在实际应用中,对于某些任务可能需要调整默认值1以适应数据分布或优化模型性能。但基本原则仍然是保持一个常数值作为额外输入特征,并且通常会根据具体情况对其进行学习或调整。
具体来说,引入偏置特征1有以下几个原因:
平移决策边界:通过调整偏置项的权重,可以使得决策边界沿着不同方向平移。如果没有偏置项,则决策边界将必须过原点(0, 0)。
控制输出截距:当所有其他输入都为零时,只有存在偏置项才能使感知器产生非零输出。
增强模型表达能力:引入一个额外维度后,在某些情况下会更容易找到合适分割样本空间线性超平面位置。
总之,在感知器中引入偏置特征1可以使模型更加灵活,能够适应不同的决策边界位置,并增加了模型对输入数据的表达能力。
其中,Siegrid Lowel非常著名的一句话“一同激活的神经元联系在一起”(Hebb的思想,一个生物元经常触发另外一个神经元,二者关系增强),故此Rosenblatt基于该规则提出一种感知器训练算法,其加强了有助于减少错误的连接,如果预测错了,比如预测目标是1,预测到0,就会增强对应神经元权重和偏置,如果预测目标是0,预测到1,就会减小。(根据阶跃函数性质值越大为1,值小为0)
以下是感知器训练算法的步骤(只有一层神经网络):
- 初始化参数:初始化权重向量 w 和偏置 b 为零或者随机小数。(一般来说感知器个数不多情况下,个数多则可以使用如神经网络的初始化如He初始化等)
- 对每个训练样本进行迭代:
- 计算预测输出 y_hat = sign(w * x + b),其中 w 是权重向量,x 是输入特征向量,b 是偏置项,并且 sign() 函数表示取符号(正负,二分类为例)。
- 更新权重和偏置:
- 如果 y_hat 等于实际标签 y,则无需更新参数。
- 如果 y_hat 不等于实际标签 y,则根据下面的规则更新参数:
- 权重更新规则:w = w + η * (y - y_hat) * x,其中 η 是学习率(控制每次更新的步长)。
- 偏置更新规则:b = b + η * (y - y_hat)。(偏移)
这个过程会不断迭代直到所有样本被正确分类或达到预定的停止条件(如达到最大迭代次数)。从以下我们就可以看到线性可分的感知机训练过程和线性不可分的感知机训练过程,在线性不可分的情况下,泛化能力较差。
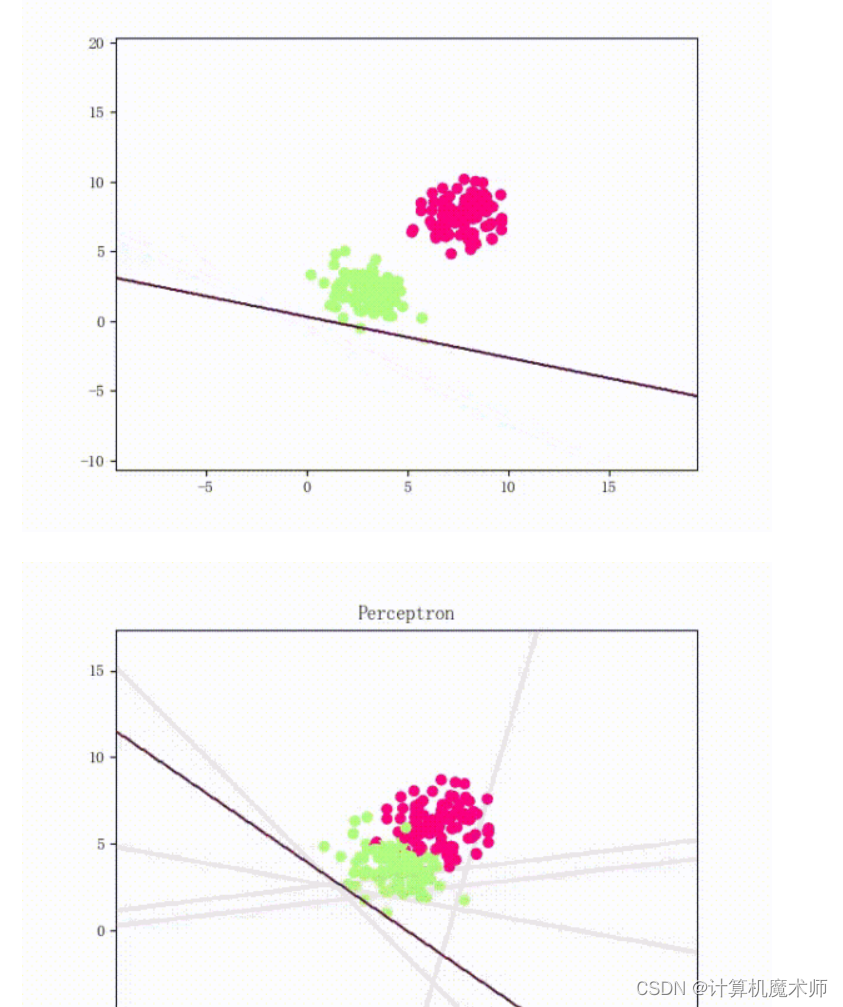
鸢尾花多分类案例
Sci-learn: https://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html`
Wikipedia: https://en.wikipedia.org/wiki/Iris_flower_data_set
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LvR9TPcr-1692271552393)(core algorithm.assets/image-20230817123141139.png)]](https://img-blog.csdnimg.cn/79d3404f9b354f7e998eecfa1bd6decd.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5KYWMoyw-1692271552394)(core algorithm.assets/image-20230817123152718.png)]](https://img-blog.csdnimg.cn/89674dc37762413e97afdbda0affa500.png)
我们从以上的可视化就可以知道,用Perceptorn分类必然效果不好,因为其线性不可分。
不使用库实现感知器一对多策略多分类鸢尾花数据集任务的代码:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class Perceptron:
"""设计架构
1. 初始化基本超参数
2. 根据算法模型抽象化权重训练流程
3. 训练中细分单个样本训练和预测中细分单个样本预测以实现多样本训练和预测"""
def __init__(self, learning_rate=0.1, num_epochs=20):
self.learning_rate = learning_rate
self.num_epochs = num_epochs
def train(self, X, y):
# 添加偏置项到输入数据中
X = np.insert(X, 0, 1, axis=1)
# 初始化权重为随机值
np.random.seed(42)
self.weights = []
# 训练模型(每个类别都有自己独立的感知器)
for class_label in set(y): # 集合去重
binary_labels = np.where(y == class_label, 1, -1) # True is 1 or False is -1
# print(binary_labels)
weights_class = self.train_single_perceptron(X, binary_labels)
self.weights.append(weights_class)
def train_single_perceptron(self, X, y):
weights = np.random.rand(X.shape[1]) # 随机初始化后训练(每个样本的特征数)
for _ in range(self.num_epochs): #轮次
for i in range(len(X)):
prediction = self.predict_single_sample(X[i], weights) # 数据和权重求解
error = y[i]-prediction
# 更新权重
update = self.learning_rate*error*X[i]
weights += update
return weights
def predict_single_sample(self, x, weights):
"""receive x and weights return step function"""
activation_value = np.dot(x, weights)
return 1 if activation_value >= 0 else -1 # step function (corressponds to the previous binary_labels)
def predict(self, X_test):
X_test = np.insert(X_test, 0, 1, axis=1) # 同样需要插入偏置神经元1
predictions = []
for i in range(len(X_test)):
class_predictions = []
for perceptron_weights in self.weights:
class_predictions.append(self.predict_single_sample(X_test[i], perceptron_weights))
predicted_class = np.argmax(class_predictions) # 如果一样大返回最先的下标
# print(class_predictions)
# print(predicted_class)
predictions.append(predicted_class)
return predictions
# 加载鸢尾花数据集(数据顺序排列,一定要打乱,泛化能力)
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42) #
# X_train, X_test, y_train, y_test = data.data[:120,:],data.data[120:,:],data.target[:120],data.target[120:] # , random_state=42
# 创建感知器对象并训练模型
perceptron = Perceptron()
perceptron.train(X_train, y_train)
# 使用测试数据集进行预测
predictions = perceptron.predict(X_test)
print(np.array(predictions))
print(y_test)
# print(type(y_test))
accuary = sum(predictions == y_test)/len(y_test)
accuary = accuracy_score(y_test,predictions)
print(accuary)
输出
[1 0 1 0 1 0 0 2 1 1 2 0 0 0 0 0 2 1 1 2 0 2 0 2 2 2 1 2 0 0]
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
0.8333333333333334
使用库实现感知器分类鸢尾花数据集任务的代码:
from sklearn.linear_model import Perceptron
# 加载鸢尾花数据集
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42) # 随机数一样的话,随机结果是一样的
# data.data[:120,:],data.data[120:,:],data.target[:120],data.target[120:] #
# 创建并训练感知器模型
perceptron = Perceptron(eta0=0.1, max_iter=100)
perceptron.fit(X_train, y_train)
# 使用测试数据集进行预测
predictions = perceptron.predict(X_test)
print(predictions)
print(y_test)
accuary = sum(predictions == y_test)/len(y_test)
print(accuary)
输出:
[1 0 2 0 1 0 0 2 1 0 2 0 0 0 0 0 2 0 0 2 0 2 0 2 2 2 2 2 0 0]
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
0.8
sklearn.linear_model.Perceptron的参数:
penalty: 惩罚项(默认值:None)。可以选择"l1"或"l2"来应用L1或L2正则化,也可以选择None不应用任何惩罚项。
alpha: 正则化强度(默认值:0.0001)。较大的alpha表示更强的正则化。
fit_intercept: 是否拟合截距(默认值:True)。如果设置为False,则模型将不会拟合截距。
max_iter: 最大迭代次数(默认值:1000)。指定在达到收敛之前要执行的最大迭代次数。
tol: 收敛容忍度(默认值:1e-3)。指定停止训练时目标函数改善小于该阈值时的容忍程度。
shuffle: 是否在每个周期重新打乱数据顺序(默认值:True)。
eta0: 初始学习率(默认值:1.0)。控制权重更新速度的学习率。较低的初始学习率可能有助于稳定模型收敛过程,但训练时间可能变长。
random_state: 随机种子。提供一个整数以保证结果可重复性,或者设置为None以使用随机状态。
verbose: 是否打印详细输出(默认值:0)。设置为1时,会定期打印出损失函数的值。
在这两个例子中,我们都使用了鸢尾花数据集,并将其分为训练和测试数据。然后,我们创建了一个感知器对象(自定义或Scikit-Learn提供的),并使用train()方法(自定义)或fit()方法(Scikit-Learn)来训练模型。最后,在测试数据上使用predict()方法来生成预测结果。(其中我们还可以设置一些超参数达到优化的目的)
扩展:
MLPClassifier和Keras中的Dense层都用于实现多层感知器(Multi-Layer Perceptron)模型。在Scikit-Learn库中,
MLPClassifier是一个基于神经网络的分类器,它使用反向传播算法进行训练,并可以处理多类别分类问题。你可以通过指定不同的参数来配置隐藏层、激活函数、优化算法等。而在Keras库中,
Dense层也被用作构建神经网络模型的一部分。它定义了全连接层(fully connected layer),其中每个输入节点与输出节点之间都有权重连接。你可以通过设置不同的参数来调整该层的大小、激活函数等。虽然两者具有相似的功能,但由于框架和接口不同,它们在代码编写上可能会有所差异。因此,在使用时需要根据所选框架来适当调整代码。
总体上说,“MLPClassifier”和Keras中“Dense”层都是为了实现多层感知器模型而设计的工具,在不同框架下提供了类似功能但语法略有差异。
应用场景
相比其他机器学习算法,感知器具有以下优势:
- 简单而高效:感知器算法非常简单且易于实现,计算速度快。
- 对噪声数据鲁棒:由于其使用了阶跃函数作为激活函数,在处理带有噪声数据时表现较好。
- 支持在线学习:感知器是一种在线学习算法,可以逐步更新权重和阈值,并在每次迭代中对新样本进行训练。
然而,感知器也存在一些局限性:
- 仅适用于线性可分问题:由于其基于线性模型,在处理非线性可分问题时无法取得良好的结果。
- 只能进行二分类:感知器只能用于二分类任务,并不能直接扩展到多类别分类问题上。
- 对输入特征缩放敏感:感知器对输入特征的缩放比较敏感,如果特征之间的尺度差异较大(因为结果是根据值的大小决定的,所以在使用前需要数据特征归一化或者标准化),可能会影响算法的性能。
在实际应用中,当面对非线性可分问题时,可以考虑使用其他更复杂的模型,如支持向量机、神经网络等。这些模型具有更强大的表示能力,并且能够处理更为复杂和抽象的关系。然而,在某些简单问题上,感知器仍然是一个有效且高效的选择。
总结起来就是,感知器适用于解决线性可分二分类问题,并且具有简单、高效和鲁棒等优点。但它无法处理非线性可分问题,并且只能进行二分类任务。对于不同类型或更复杂的问题,可以考虑使用其他更适合的方法。
BP神经网络
BP神经网络,指的是用了**“BP算法”进行训练的“多层感知器模型”(MLP)。**并为了TLU感知机算法正常工 作,对MLP的架构进行了修改,即将阶跃函数替换成其他激活函数,如tanh,Relu。这里之所以用反向传播是因为多层的感知机无法再用感知机学习规则来训练.
🤞到这里,如果还有什么疑问🤞
🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩
🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳