在当今信息化高速发展的时代,推荐系统是一个热门的话题和技术领域,一些云厂商也提供了推荐系统的SaaS服务比如亚马逊云科技的 Amazon Personalize 来解决客户从无到有迅速构建推荐系统的痛点和难点。在我们的日常生活中,推荐系统随处可见,比如我们经常使用的亚马逊电商购物,爱奇艺视频,美团外卖,抖音短视频以及今日头条新闻,主播直播平台等等。我根据这几年参与的推荐系统和计算广告项目总结了一些实践经验并以推荐系统系列文章的形式分享给大家,希望大家看后对推荐系统有更全新更深刻的理解。这个系列文章包括:推荐系统概览,推荐系统中的召回阶段深入探讨,排序任务的样本工程,排序模型调优实践。更多细节以及更详细的内容可以参考我的 github repo。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
我们先介绍推荐系统概览,大致内容如下:
- 推荐系统简介
- 推荐系统中常见概念
- 推荐系统中常用的评价指标
- 首页推荐场景的通用召回策略
- 详情页推荐场景的召回策略
- 排序阶段常用的排序模型
- 重排阶段
- 推荐系统的冷启动问题
- 推荐系统架构
推荐系统简介
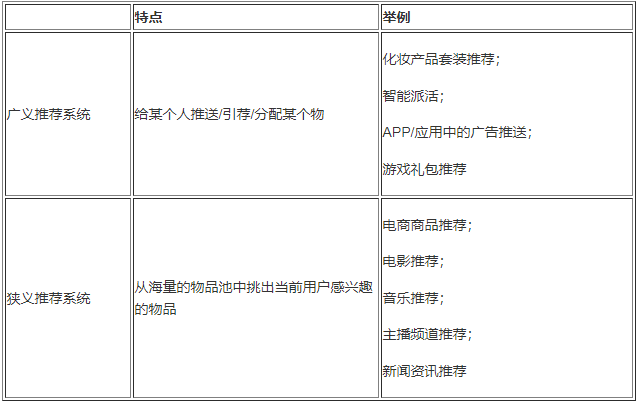
推荐系统可以分为广义推荐系统和狭义推荐系统(我们在今后的讨论只是关注狭义的推荐系统),参考下表:
推荐系统就是根据用户的历史行为、社交关系、兴趣点、所处上下文环境等信息去判断用户当前需要或感兴趣的物品/服务的一类应用。推荐系统本身是一种信息过滤的方法,与搜索和类目导航组成三大主流的信息过滤方法。我们可以从不同的角度看推荐系统的用处:对用户而言,推荐系统能帮助用户找到喜欢的物品/服务,帮忙进行决策;对服务提供方而言,推荐系统可以给用户提供个性化的服务,提高用户信任度和粘性,增加营收。据说,Netflix有2/3 被观看的电影来自推荐系统,Google 新闻有38%的点击量来自推荐系统;Amazon 电商有35%的销量来自推荐系统的推荐。
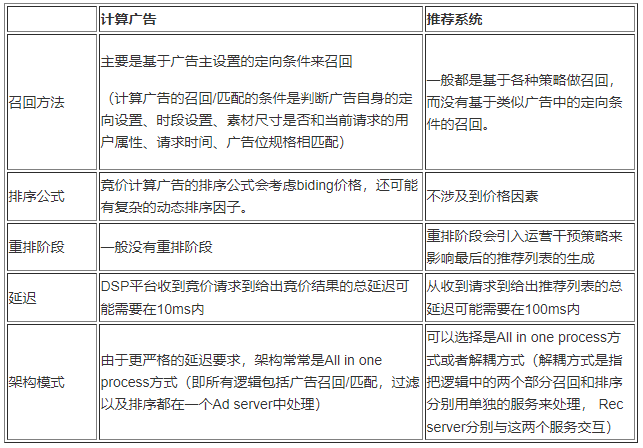
对于很多人(包括曾经的我)常犯的一个观念错误是,推荐系统的工程实现与计算广告的工程实现是类似的,其实两者的实现差别很大,见下表:
推荐系统中常见概念
推荐系统常见的场景:首页推荐(更强调以用户为中心)和详情页推荐(更强调以物品为中心)。
个性化推荐与非个性化推荐: 个性化推荐几乎是当前主流的,是针对每个用户做不同的推荐即千人千面。首页推荐都会考虑个性化,详情页推荐也越来越考虑个性化了。非个性化推荐的常见方法有:整个大盘历史排行榜推荐(比如1年内的,1个月内的,1个星期内的);每个类目历史排行榜推荐(比如1年内的,1个月内的,1个星期内的);周期性与节日有关的推荐(比如国庆黄金周和圣诞假期的物品推荐);突发事件相关的推荐(比如与突发传染疾病相关的物品推荐);最新发布的物品的推荐(比如1周内)。
推荐系统的产品形态:物品即 item 的曝光形式(比如上下翻页,左右翻页以及他们的混合方法);曝光分区的编排(就一种推荐方法,比如个性化TOP-N推荐,可以考虑把其他方法作为召回策略纳入个性化TOP-N推荐的召回阶段;多种推荐方法,Netflix的首页推荐每一行对应一个推荐方法(它的每一行都可以左右翻页来浏览电影item),这个也叫分区混合推荐。比如一行是独家播放推荐,一行是热门推荐,一行是新品推荐,一行是个性化TOP-N推荐)。为了行文方便,我们对后面的讨论做个假设:只用个性化推荐方法,其他方法都作为个性化推荐的召回策略。
召回阶段,排序阶段和重排阶段:他们是个性化Top-N推荐整个流程的三个细分阶段。不同的场景下(比如是首页推荐还是详情页推荐),针对不同种类的用户(即是否是长尾和冷启动用户)并不是三个阶段都需要,具体讨论我们会在这个系列文章的另一篇《推荐系统中的召回阶段深入探讨》中涉及。重排阶段有很多叫法,比如模型后处理阶段或者业务运营干预阶段。
探索与利用:探索指的是想挖掘用户的一些从行为上无法反应的一些爱好相关的物品;利用指的是推荐系统根据用户历史行为学习到的知识并预测出概率高的用户可能感兴趣的物品。对于冷启动的物品和长尾的物品,在重排阶段做探索是一种常见的方法。实践中,经常会有一些固定的曝光位置专门留给冷启动的物品和长尾的物品。
离线推荐与线上推荐:所谓的离线推荐,指的是推荐的结果列表是离线的时候就预计算好并存储在某个 memory-based 的 NoSQL(比如 Amazon ElastiCache for Redis)中,当用户请求来的时候直接从NoSQL中取出;所谓的线上推荐,指的是当用户请求来的时候系统根据规则,策略或者模型的组合来临时生成推荐列表。
离线召回与线上实时召回:所谓的离线召回,指的是离线的时候提前把需要召回的item候选集合预计算好并存储在某个 memory-based 的NoSQL中;所谓的线上实时召回,指的是当用户请求来的时候,召回服务临时根据某种逻辑(比如走模型得到一个实时的用户兴趣向量,然后用这个用户兴趣向量去向量检索库找到 topK 相似的 item 向量)来得到的召回候选集。
电商付费类推荐系统与新闻/电影/视频等内容消费类推荐系统的召回策略是有区别的。对于首页推荐的场景,他们的召回策略或者推荐方法可能区别不大。对于详情页推荐的场景,他们的召回策略有很大区别,新闻/电影/视频等内容消费类推荐系统,可能把基于物品表示向量相似度的推荐方法得到的列表放在更有利的曝光位置或者给予基于物品表示向量相似度的召回策略最高优先级会更好(因为对于内容消费类的场景,用户更偏好的是物品内容本身的相似);而对于电商付费类推荐系统来说,可能需要比内容消费类推荐系统更多的推荐方法或者召回策略,比如基于物品的关联推荐方法或者召回策略可能在电商详情页推荐中就是必须有的,但是在内容消费类推荐系统中就是可选项,比如“经常一起购买的商品”的关联推荐,和/或者“浏览此物品的用户也同时浏览”的关联推荐(因为在这个场景下,当前用户除了关注详情页物品,接下来可能还感兴趣与该物品经常一起出现的其他物品)。
电商付费类推荐系统,可能还会有购物车页面推荐以及付费完成页面推荐这样的场景。对于这样的场景,可能把用关联推荐方法得到的列表放在更有利的曝光位置或者给予关联推荐召回策略最高优先级会更好,而基于物品 item 表示向量相似度的召回策略或者推荐方法可能在这个场景下就不太合适了,也就是说在当前购买意图很确定的情况下,用户更偏好的是物品之间的共现,因为用户很可能并不想马上再买一个物品内容很相似的物品。
推荐系统中常用的评价指标
评价指标主要分两种: 线上业务评价指标和离线评价指标。一般来讲, 线上业务评价指标更重要(经常需要多个指标一起看),它包括转化类指标(比如转化率,点击率, GMV成交总额等等)和内容消费满意度指标(比如留存率,停留时长,观看时长等等)
离线评价指标中,最常用的指标是 AUC 以及 GAUC ,尤其是 AUC。AUC 细分为 AUC-ROC 和 AUC-PR,AUC-ROC 可能更常用。AUC-ROC 是指随机给定一个正样本和一个负样本,分类器输出该正样本为正的那个概率值比分类器输出该负样本为正的那个概率值要大的可能性。GAUC (Group AUC)是计算每个用户的 AUC,然后加权平均,最后得到 Group AUC,实际处理时权重一般可以设为每个用户 view 或 click 的次数,而且需要过滤掉单个用户全是正样本或负样本的情况,具体公式参考如下:
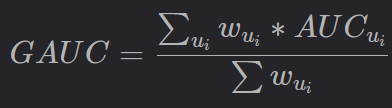
离线的时候,AUC 和 GAUC 两个指标最好都关注。实践中,不要太刻意追求离线验证集的很高的 AUC,太高的验证集的 AUC 可能表示模型过拟合到这个验证集了,线上效果可能会很差。一般离线的 AUC 可能在0.7~0.85之间就可以上线。
首页推荐场景的通用召回策略
基于热度/流行度/排行榜的召回策略
可以从两个维度来组合:统计周期和物品 item 的顶级类目。比如统计一段时间内同类目的所有 Item 的评价次数以及该 Item 的平均评分,根据评分来进行排序,由于不同 Item 的评价次数可能差别很大,直接基于平均评分来排序效果不好。为了公平起见,采用加权的评分更合理,可以参考如下的公式:
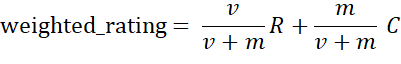
v是某 Item 参与评分的用户的个数,m 是筛选的评分用户个数阈值,即如果某个 item 评分的用户个数低于阈值则该 item 将被忽略(比如采用评分用户个数的20%分位数来决定该阈值),R 是该 item 的评分均分,C是所有 item 的平均分。
基于物品画像的召回策略
所谓的物品画像指的是对物品本身的某一方面的刻画。比如物品的品牌,物品的价格,物品所属的类目等这些都称为物品的画像,这些画像有明显的物理含义,我们把它们称作显式画像;如果通过某个模型把物品 item id 的“黑知识”学习到,这个黑知识我们称为 embedding,这个 embedding 是不可解释的,我们把它称作隐式画像。从显式画像和隐式画像角度来看,基于物品画像的召回策略自然而然分为:基于物品内容的召回和基于物品的整体 embedding 的召回。

在首页推荐场景中的基于物品画像的召回是基于当前用户的稠密行为(稠密行为的意思就是用户对很多物品而不只是3,4个物品都有过行为)来做的,这个与后面将要介绍的详情页推荐场景中常见的基于物品 item 表示向量相似度的召回不用考虑当前用户的稠密行为有很大区别。对于基于物品内容的召回过程,物品 item 的结构化表示和非结构化表示不要直接拼接并用来计算向量间的相似度,因为它们不是来自同一个空间的表达。如果要计算表示向量的相似度的话,最好作为 item 的两个不同的表示并作为两路不同的召回策略;如果是基于监督模型来对用户喜好进行分类建模,结构化表示和非结构化表示可以一起作为特征建模到模型中。
基于协同过滤的召回策略
这个方法是仅仅基于用户行为数据设计的,即基于 User-Item 矩阵或者由 user 和 item 构成的图,不包括任何的其他特征。本质上是矩阵补全的思路,也正是因为基于矩阵的处理,只要用户或者 Item 有变化,甚至 action 有变化,可能需要重新计算或者重新训练(业界当前有一些方法做增量协同过滤或者近实时协同过滤)。基于协同过滤的召回策略,细分为如下三种方式:基于用户的协同过滤 /UserCF;基于物品的协同过滤 /ItemCF;基于模型的协同过滤。
- 基于用户(user-based)的协同过滤,核心思想是首先根据相似度计算出目标用户的邻居集合,然后用邻居用户评分/交互的加权组合来为目标用户作推荐。 通常分为三步:首先使用所有用户的 item 评分/交互矩阵来计算目标用户与其他用户之间的相似度(利用 Pearson 相关系数、余弦相似度等方法);然后选择与目标用户相似度最高的K个用户;最后通过对邻居用户的评分/交互的加权求和来预测目标用户对每个他自己没有评过分/交互的 Item 的评分/感兴趣程度。这里的加权指的是用用户之间的相似度作为评分/交互的权重,如下图公式中的 sim(u,ui)。
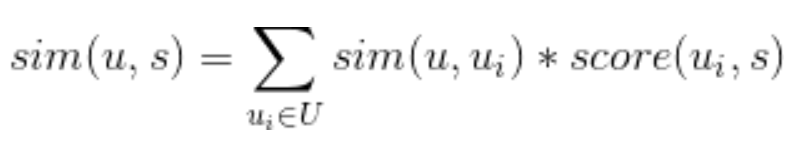
上面公式中的 U 表示的是目标用户u的邻居用户集合(即 topK 相似的用户集合),s 表示的是用户-物品交互矩阵中出现过的item并且被邻居用户交互过且没被目标用户交互过的 item。score(ui,s)是用户 ui 对物品 s 的喜好度, 对于隐式反馈为1( 只要不是用户直接评分的操作行为都算隐式反馈,包括浏览、点击、播放、收藏、评论、点赞、转发等等 ),而对于非隐式反馈,该值为用户对物品的评分。
UserCF 的主要缺点是随着网站的用户数目越来越大,其运算的时间复杂度和空间复杂度随着用户的增长而爆炸性增长。新闻/资讯/知识类网站一般会使用 user-based 的 CF 来召回,由于这些类网站的文章更新太快太多,可能不适合用 item-based的CF。
- 基于物品( item-based )的协同过滤,核心是基于 Item-Item 共现矩阵通过某种相似度度量来计算两个Item的相似度,区别于基于内容的推荐方法,这里不需要对 Item 的特征本身建模,完全是基于用户对 Item 的行为历史数据。方法主要分三步:首先需要构造 item-item 共现矩阵,遍历训练数据,计算出喜欢两两物品的用户数,填入矩阵中。然后计算物品之间的相似度,需要惩罚热门物品以及惩罚活跃用户,公式如下:
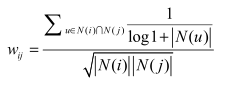
根据物品的相似度和用户的历史行为给用户生成推荐列表:
![]()
上式中的 S 表示的是训练集中出现的物品集合;i是用户u发生过行为且出现在训练集中的物品;
![]()
指的是目标用户 u 对物品i的评分(显式反馈就是用户的具体评分,隐式反馈的话这个值就是1)。
ItemCF 它可能是目前业界应用最多的一种召回策略。比如 Amazon 电商,Netflix 在线视频等网站,他们的首页推荐中经常会使用 ItemCF 作为其中一路召回。
- 基于模型( model-based )的协同过滤,区别于上面两种基于邻域的方法,基于模型的 CF 使用传统机器学习进行建模。比如 SVD 及其变体,图模型比如 SimRank 等。SVD 及其变体是基于 user-item 矩阵来进行矩阵分解的, 它们把 User-Item 评分矩阵分解为两个低秩矩阵的乘积,这两个低秩矩阵分别为 User 和 Item 的隐向量集合,通过 User 和 Item 隐向量的点积来预测用户对未见过的物品的兴趣,从这个角度来说,矩阵分解也是生成 embedding 表示的一种方法。
基于用户画像的召回策略
简单讲,用户画像就是为用户打标签 tag。打标签的重要目的之一是为了让人能够理解并且方便计算机处理。基于用户画像的召回是个性化推荐中的精髓,因为个性化就是通过用户画像来体现的。用户画像包括如下的三大类:
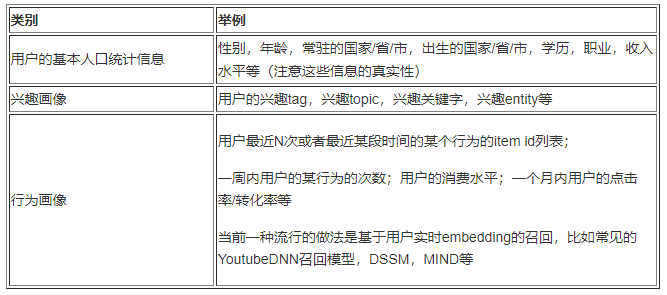
用户画像的大致实现思路参考如下:
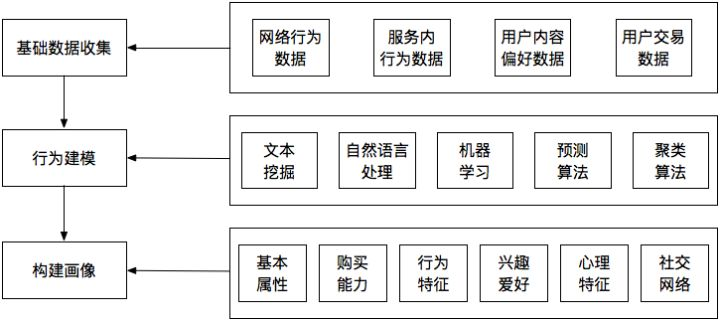
总结
推荐系统概览的第一讲到此结束。本文首先介绍了推荐系统的常见概念和常用的评价指标,接着详细介绍了首页推荐场景的四种通用召回策略即基于热度/流行度/排行榜的召回策略,基于物品画像的召回策略,基于协同过滤的召回策略和基于用户画像的召回策略。相信现在大家对推荐系统有了更深刻理解,接下来第二讲我们会继续介绍推荐系统概览的其余内容,感谢大家的阅读。

梁宇辉 亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实客户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。
文章来源:https://dev.amazoncloud.cn/column/article/630b3545269604139cb5e9e8?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN