资料收集于网络,仅供学习使用
TALKS: A systematic framework for resolving model-data discrepancies
https://doi.org/10.1016/j.envsoft.2023.105668

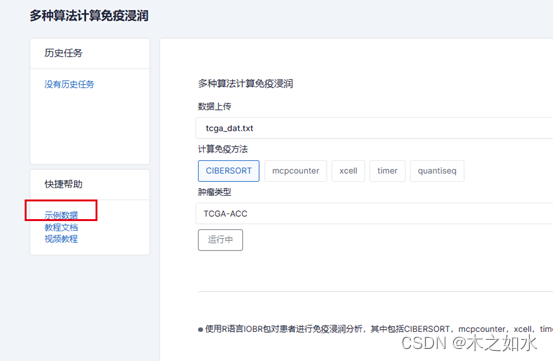
问题现状
TALKS框架
TALKS(Trigger, Articulate, List, Knowledge elicitation, Solve),作为解决模型数据差异的一种方法。该框架强调,数据与模型输出之间的不匹配可能是由于模型、数据或两者都存在问题。
模型与数据不一致
模型和数据在环境系统的决策中发挥着重要作用,提供了不同且互补的信息。已经开发了多个框架来解决模型的局限性,并且有大量的研究专注于提高数据的质量。然而,当模型和数据不一致时,通常的关注点是修复模型,而不是数据。在这项研究中,我们引入了TALKS框架作为解决模型数据差异的一种方法。通过三个案例研究,我们展示了模型如何用于识别和改进数据问题,从而更好地利用模型和数据。该框架可以更广泛地应用于更好地将模型和数据整合到环境决策中。
模型开发和评估框架
模型的开发旨在通过支持对环境系统的健全科学理解,为决策者和管理者提供指导 (Aumann, 2011; McIntosh et al., 2011; Pohjola et al., 2013; Schuwirth et al., 2019)。环境系统在本质上是复杂且时空变化多样的,为确保其输出的相关性、准确性和精确性,必须对模型进行严格评估(Jakeman et al., 2006; Power, 1993)。已经提出了几种框架来指导科学合理的模型开发(Ascough et al., 2008; Bennett et al., 2013; Hipsey et al., 2020; Jakeman et al., 2006; Pohjola et al., 2013; Refsgaard et al., 2007; Walker et al., 2010)。这些框架通常针对以下一个或多个领域:(1)质量保证/质量控制(QA/QC)方法,(2)不确定性评估,(3)对模型的技术评估,(4)评估模型在研究社区以外的有效性,和/或(5)其他观点,如沟通和参与式建模的评估(Pohjola et al., 2013)。总的来说,模型开发和评估的框架的目标是确保模型准确地描述了真实系统的动态,并且/或在决策中有用((Pohjola et al., 2013)。
数据是至关重要的
模型开发和评估的框架(Bennett et al., 2013; Hipsey et al., 2020; Jakeman et al., 2006) 通常对模型开发和评估过程提供不同的观点,但也存在一些共同之处。模型应该与独立数据集一起开发和评估((see Guo et al., 2020; Hipsey et al., 2020; Zheng et al., 2022 for examples) and be continuously refined by exposing them to new datasets (Gibbs et al., 2018; Keating, 2020),并通过将其暴露给新数据集不断进行优化 (Gibbs et al., 2018; Keating, 2020)。模型评估应该理想地使用在不同层次获取的数据 (e.g., process and system, Robson et al., 2020),并依赖于专家理解 (Holzworth et al., 2011; Keating, 2020)。因此,数据是开发和评估模型的关键。模型对数据的依赖程度因所使用的模型类型而异(Mount et al., 2016。数据驱动模型(e.g., machine learning)主要以数据为基础构建,而基于理论的模型( (e.g. process based)更多地基于机制性假设或理论 (Jakeman et al., 2006; Thornley, 1976),但始终在某种程度上融入经验性表达式(e.g., 解释光对初级生产的影响的光合-辐照度曲线),因此需要数据进行严格的校准和性能评估(Mount et al., 2016; Robson, 2014)。过程表示的抽象级别各异:应用于宏观量应用科学的实用模型,例如不会模拟物理或化学反应的亚原子过程。在没有数据的情况下,基于理论的模型仍然是需要测试的假设 (Silberstein, 2006)。无论是使用数据驱动方法还是机制方法开发环境模型,模型都需要在广泛的数据集上进行评估以确保可信度(Aumann, 2007, 2011; Hamilton et al., 2022; Harper et al., 2021; Humphrey et al., 2017)。
数据与模型的关系(数据是某时空的快照)
建模者拥有多种框架,可以帮助他们开发可信的模型。然而,大多数框架都基于一个假设,即用于模型开发或评估的数据精确且准确地代表了所涉及的系统,为测试模型性能提供客观标准 (Hipsey et al., 2020)。然而,正如数学模型只是真实系统的简化表示一样,数据只是时间和空间中系统的一个快照。更通俗地说,就像“所有模型都是错误的,但有些是有用的”(Box, 1979)一样,我们类比地认为“所有数据都是不完整的,但大多数都是有洞察力的”。环境数据很少在与系统变异匹配的空间和时间尺度上进行收集(Oreskes et al., 1994)。此外,数据就像模型一样,会受到来自各种来源的误差(e.g., 采样过程、实验室分析和/或数据处理;参见Batley,1999)。从根本上讲,测量需要存在一个“数据模型”:对实际测量内容 (e.g., 不同波长下的光子通量强度)与该测量应该代表的内容(例如,光合作用活跃辐射)之间关系的概念性理解。正如Gitelman (2013)中所讨论的,数据绝不是原始的,应该被视为一个文化资源,需要生成、保护和解释。因此,客观地解决测量数据与模型预测之间差异的原因意味着要认识到这些差异可能源于模型、数据和/或基础数据模型的问题。
利用模型预测的实际差异:模型局限性
预测与观测之间的差异通常源自模型的局限性。例如,有报告称模型捕捉了状态变量的季节性趋势,但未能表示偶发事件(Elliott et al., 2000)。这种差异是模型完善和发展过程中的预期部分。通常的响应要么是改进模型的概念化、结构和参数,要么是使用模型与数据的比较来限定不确定性,或者更好地约束模型被视为适用的范围。因此,解决这些差异的关键步骤是明确模型的目的,并回答诸如(Jakeman et al., 2006):模型的目的是什么?是表示平均行为吗?是偶发事件还是两者兼而有之?
模型评估框架:缺乏模型预测与数据质量联系
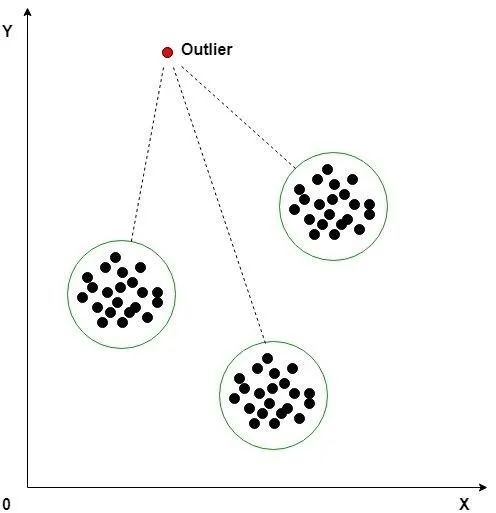
模型评估框架(e.g. Bennett et al., 2013; Hipsey et al., 2020; Jakeman et al., 2006; Pohjola et al., 2013)强调了模型的局限性。然而,在文献中缺乏关于模型预测如何为数据质量提供洞察的具体指导。理想情况下,对模型的评估应该旨在了解模型和数据中所包含的信息(Gupta et al., 2008)。数据可以揭示模型改进的方向。相反,模型可以引起对数据不足之处的注意,这可以通过进一步的调查来解决。数据的局限性存在可以显著影响模型开发过程,导致对系统结构和功能的不准确描述,以及在使用错误数据对模型进行改进时浪费时间和资源(Fig. 1)。目前,数据质量主要通过专家判断或异常检测算法来评估(Foorthuis, 2021; Leigh et al., 2019),这些方法完全依赖于数据。然而,数据中的问题可能会逃脱专家或算法的审查。
图:模型开发中数据错误潜在的影响

模型识别数据问题的价值
模型在识别数据问题方面的价值,作为平衡两种可能性的方法之一 - 要么模型,要么数据可能是导致模型数据差异的原因 - 从而避免陷入暗含模型“错误”和数据“正确”的陷阱。我们引入了TALKS框架(触发 - 阐述 - 列出 - 知识 - 解决)来帮助模型开发者解决模型数据差异。与其他框架相反,TALKS框架对模型和数据都应用了同样水平的批判性分析,并强调了专家知识引探在解决模型数据差异中的重要性。由于建模框架往往侧重于基于数据(以及其他因素,e.g. Hipsey et al., 2020)来改进模型,我们提出了三个案例研究,展示了如何利用模型来改进从数据中获得的洞察力。这些案例研究涵盖了以下领域:(1)现场建模,(2)流域建模和(3)保育科学。
TALKS framework 概述
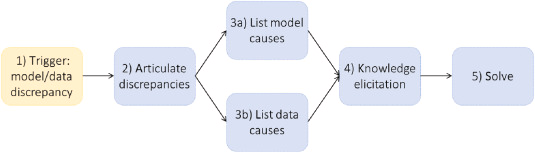
TALKS的五步
Trigger
框架的第一步和入口是识别存在差异。触发可以采用多种形式。例如,在基于理论的模型中,参数具有物理解释,触发可以是仅通过使用不切实际的参数或不太可能的参数组合才能实现满意的模型性能(Robson et al., 2018)。无论参数是否具有物理解释,当存在新数据时,可能需要使用非常不同的参数来实现充分的模型数据拟合。
Articulate discrepancies
第二步是阐述模型与数据之间的不一致之处。这一步的目标是表征差异。因此,明确的第一步是将不一致可视化,并估计整体模型性能。进一步的分析可以为下一步提供见解(列出差异的潜在原因)。例如,可以使用绘制残差图和观察模型残差与输入/系统组成部分之间的交叉相关性等技术来检测模型结构问题和模型参数化、输入和初始条件问题。
List potential causes
第三步是考虑差异的潜在原因。重要的是要区分由模型可能问题引起的差异和由数据可能问题引起的差异。
Knowledge elicitation
第四步是与专家咨询,并对差异的潜在原因进行批判性评估。这一步涉及借助现场知识,并与数据提供者和/或测量技术专家(例如传感器开发人员)进行咨询,以及应用团队内的可用专业知识。这是一个迭代的过程,需要应用和咨询专业知识,直到确定差异的原因。
Solve
最后一步是制定解决差异的策略。这可能涉及更新模型结构、应用不同的模型或更新/丢弃数据。
各部分详细解释
触发 Trigger
触发的例子包括:
- 在最佳校准尝试之后,模型输出与测量结果不匹配。
- 为了进行充分的校准需要不现实的(或接近现实界限的)参数值(或参数组合)。
- 参数的不确定性大于参数值。
- 模型行为与之前对被建模系统的理解不符(可能包括专家知识)。
- 模型与数据之间的拟合不一致,或时间、空间和数据集之间的参数范围不一致。
阐述差异:Articulate discrepancies
简洁而准确地传达差异是什么,以及为何解决这些差异可能很重要:
- 通过可视化或使用一系列度量标准来表征差异,以评估模型性能的不同方面(例如,预测是否始终高于或低于测量值;Bennett等,2013)
- 传达与系统预期动态的偏离(例如,通过可视化)
- 绘制模型与数据拟合的残差,以检查是否存在系统性模式
- 分析随时间变化的残差分布。这可以表明缺失的模型过程、随时间变化的过程,或模型的初始条件和/或驱动变量存在问题
- 查看模型残差与输入之间的交叉相关性,以了解模型输入或结构中缺少的内容(例如,低风期间叶绿素-a系统性低估可能指示模型对浮游植物的垂直迁移的处理存在错误,如Soontiens等,2019所描述)
- 查看系统不同组分的模型残差之间的交叉相关性(例如,氨的一致过度预测,但硝酸盐的预测不足,可能指示硝化过程的表示存在问题)
- 检查模型参数的敏感性随时间如何变化(例如,动态可辨识性分析,例如Wagener等,2002)
- 检查经过校准的参数值如何分布在其预期范围或概率分布内(例如,如果校准的参数值接近预期分布的外部限制,这可能暗示模型存在结构性错误或观测数据中的系统性错误,Robson等,2018)
- 确定差异是否影响模型的可靠性(例如,Hamilton等,2022)
- 确定差异是否会对建模目标产生影响。
列出潜在因素 List potential causes
a. 列出模型引起的原因
多项研究已经对模型的原因进行了表征,并强调了在模型预测中引入不确定性的重要性 (e.g., Jakeman et al., 2018)。模型原因可以分为以下几类:
- 模型概念化错误
- 模型结构、初始条件和/或参数化错误
- 模型实现中的错误(包括代码错误、数值/离散化问题等)
b. 列出数据引起的原因
数据受到多个来源的错误影响(e.g., Fu et al., 2021):
- 数据收集/测量、传输、存储和分析中的错误(例如,设备故障或校准误差、抽样偏差)
- 用于测量数据的方法和空间/时间频率的改变
- 数据收集的空间和/或时间尺度未捕获所需的变异性(例如,采样频率未捕获一次性事件)
- 导入数据时出现错误(包括清理)
- 导出数据时出现错误
- 数据处理和处理错误(例如,将原始测量转换为等效建模变量时的错误)
- 数据模型中的错误(例如,过时或不适当使用的流量比曲线,见Potter和Walker,1982;或由于水体成分变化导致浊度与光合有效辐射之间的关系变化)
知识引探 Knowledge elicitation
寻求专家建议是解决差异的关键步骤:
- 利用现场知识(例如,农民、护林员、原住民、社区团体)
- 与数据和技术专家进行沟通(例如,监测团队、分析服务提供商以及测量技术专家,如传感器开发人员)
- 寻求模型开发者的建议
- 向领域中的其他专家寻求建议
解决 Solve
可以采取一个或多个行动,包括但不限于以下几种:
- 修订和/或重新考虑模型结构和参数化
- 修订模型实现
- 更新和/或丢弃数据
- 重新测量数据
- 说明模型和数据的限制
案例
见原论文